
作者:娜米
資源的剛性交付,不是雲上天生就具備的能力。當選擇自建或自管理一個 Kubernetes/ECS 資源池時,就必須直面一個殘酷的現實:所依賴的底層 IaaS 資源本身就是非剛性的。
阿里雲上 ECS 有多代實例規格(如 g6、c7i、r8y 等),基於 Intel、AMD 及自研倚天 ARM 芯片,但這並不保證在任何時刻、任何地域、任何可用區,所需要的那款機型就一定有庫存。這種底層資源的“不確定性”,會像幽靈一樣擴散到自建的上層系統中。
剛性交付的本質,是將“不確定性”從系統中排除的關鍵機制。它通過可控的資源成本,換取了業務的穩定性、高性能和可預測性。 對於任何嚴肅的線上業務而言,這種確定性並非錦上添花,而是維繫其商業信譽和核心價值的生命線。
以下幾個案例,闡述非剛性交付”帶來的典型困境。
案例一:遊戲行業 —— 新品發佈日的“容量災難”
- 行業:在線遊戲、元宇宙
- 故障:
- 場景:一家遊戲公司萬眾期待的新遊戲正式公測。運營團隊基於壓測,制定了雄心勃勃的擴容計劃,需要在開服瞬間將遊戲服務器(通常需要高性能計算或 GPU 優化的特定 ECS 機型)的規模擴大 10 倍。他們管理着一個基於 K8s 的自建集羣。
- 觸發:開服鈴聲敲響,CI/CD 流水線觸發了大規模的橫向擴容。然而,K8s 的節點自動伸縮器 Cluster Autoscaler 在向阿里雲申請創建新的 ECS 節點時,API 返回了“Insufficient stock”庫存不足的錯誤。他們所依賴的特定高性能機型,在該可用區已無庫存。
- 現象:應用的 Pod 因為沒有足夠的節點資源而大量處於
Pending狀態,無法被調度。新玩家的登錄請求雪片般涌入,但服務器容量遠未達到預期。
- 業務影響:
- 上線即失敗:大量玩家無法登錄,遊戲入口處大排長龍,社交媒體和遊戲社區瞬間被負面評價淹沒,精心策劃的發佈會變成了公關災難。
- 真金白銀的損失:高額的市場推廣費用付諸東流,首日充值流水遠低於預期。
- 玩家永久流失:糟糕的首日體驗會導致大量核心玩家永久流失至競品。
案例二:電商行業 —— 大促活動中的“性能懸崖”
- 行業:電商與在線零售
- 故障:
- 場景:一家電商平台為了應對大促,提前“預留”了大量 ECS 節點。為了“提高資源利用率”,他們在核心的交易應用 Pod 所在的節點上,混部了一些非核心的數據分析和日誌處理 Pod,並配置了非剛性的 CPU 交付。
- 觸發:大促零點開啓,交易量飆升,交易應用需要全部申請的 CPU。同時,數據分析任務也開始高強度運行,搶佔 CPU 資源。
- 現象:交易應用的實際可用 CPU 被嚴重擠壓,響應時間急劇惡化,大量請求超時。
- 業務影響:
- 訂單大量流失:支付和下單環節的堵塞,直接導致 GMV 損失。
- 品牌信譽受損:用户在關鍵時刻掉鏈子,嚴重損害品牌可靠性。
案例三:金融科技行業 —— 交易時段的“隨機掉線”
- 行業:金融科技 (FinTech),尤其是證券交易
- 故障:
- 場景:一個核心的行情推送 Java 服務,以內存非剛性交付的方式運行在一個自管理的 K8s 集羣上。
- 觸發:交易時段,訂閲量激增,服務實際內存使用遠超其申請值。此時節點內存壓力增大,觸發 OOM Killer。
- 現象:行情服務 Pod 被系統判定為“劣質進程”而隨機殺死,導致客户端行情刷新中斷。
- 業務影響:
- 交易決策失誤:用户因行情中斷而做出錯誤決策或錯失交易時機,造成直接經濟損失。
- 合規與監管風險:核心系統頻繁中斷,可能觸犯金融行業的高可用性監管要求。
案例四:企業軟件行業 —— 核心 ERP 系統的“性能抽獎”
- 行業:企業軟件 (ERP, CRM),尤其是大型單體應用
- 故障:
- 場景:一家企業將其龐大的、無法輕易水平擴展的單體 ERP 系統容器化後,部署在一個資源非剛性交付的自建集羣上,以期“節約成本”。
- 觸發:在月末財務結算等高峯期,ERP 系統需要大量 CPU 和內存。但它必須和節點上其他應用“共享”資源。
- 現象:ERP 系統的性能變得極不穩定,時快時慢,如同“抽獎”。有時一個報表生成需要 2 分鐘,有時需要 20 分鐘。
- 業務影響:
- 工作效率低下:員工的核心工作流程被頻繁打斷,財務、供應鏈等部門的月末結算工作無法按時完成。
- 決策延遲:管理者無法及時獲取準確的業務報表,影響了商業決策的時效性。
資源剛性交付困境
資源供給的不確定性
困境本質:“承諾的資源” ≠ “可即時獲取的資源”。
- 庫存波動:熱門規格 ECS,在大促或行業高峯期容易出現“秒光”,導致擴容失敗。
- 區域/可用區差異:某些 AZ 因物理機房容量限制,無法提供特定資源類型,跨 AZ 調度又需額外網絡與配置成本。
- 代際斷層:舊代實例停售或庫存枯竭,但應用尚未適配新架構,造成剛性承諾無法兑現。
性能隔離難以真正實現
困境本質:“邏輯隔離”不等於“物理隔離”,剛性性能難以 100% 保障。
- 虛擬化開銷與干擾:即使使用 Cgroups、CPU 綁核等技術,共享 NUMA 節點、內存帶寬、磁盤 I/O 隊列仍可能被“嘈雜鄰居”搶佔。
- 突發流量衝擊:同節點上其他租户突發高負載(如備份、掃描),導致本應“獨佔”的實例出現延遲毛刺。
- 存儲性能抖動:存儲在多租户爭搶下 IOPS 和吞吐不穩定,影響核心業務等關鍵應用。
彈性與剛性的內在矛盾
困境本質:剛性要求確定性,彈性依賴不確定性,二者天然張力。
- 預佔 vs 按需:為保障剛性需提前預留資源,但業務負載波動大時造成浪費;若完全按需,則無法應對突發高峯。
- 冷啓動延遲:首次啓動需拉鏡像、初始化,往往無法滿足業務的剛性響應要求。
異構資源管理複雜度高
困境本質:“資源剛性”需端到端棧協同,任一環節短板即導致整體失效。
- 專用硬件:驅動版本、CUDA 兼容性、拓撲感知調度、故障恢復機制各異,難以標準化交付。
- 混合架構支持難:x86 與 ARM(如倚天710)指令集不同,應用需重新編譯測試,剛性交付需維護多套鏡像與部署流程。
- 網絡與存儲耦合:高性能計算需 RDMA、NVMe over Fabric 等底層能力,但這些能力在虛擬化層常被削弱或不可用。
傳統架構與雲原生理念割裂
困境本質:剛性交付不僅是技術問題,更是組織與認知轉型問題。
- 缺乏彈性設計:應用未做無狀態改造,無法橫向擴展,只能縱向升級(Scale-Up),而大規格實例更稀缺、更昂貴。
- 運維慣性阻力:企業習慣“買服務器、裝系統、長期運行”,對“按需申請、用完即棄”的剛性交付模式接受度低。
成本模型與剛性目標衝突
困境本質:財務約束常迫使技術理想向現實低頭。
- 剛性 = 高成本:獨佔物理機、專用集羣、多AZ冗餘等方案顯著推高 TCO。
- 企業被迫妥協:為控制預算,用户常選擇共享資源池+監控告警“事後補救”,而非事前剛性保障。
- 計費模式滯後:傳統按小時計費無法匹配秒級彈性需求,導致“為不用的資源付費”或“關鍵時刻無資源可用”。
SAE 在剛性交付上做的工作
作為阿里雲面向應用層的全託管 Serverless PaaS 平台,針對資源剛性交付的系統性困境,從資源供給、性能隔離、彈性模型、異構調度、成本結構、容災能力、可觀測性與架構演進等多個維度進行了設計。
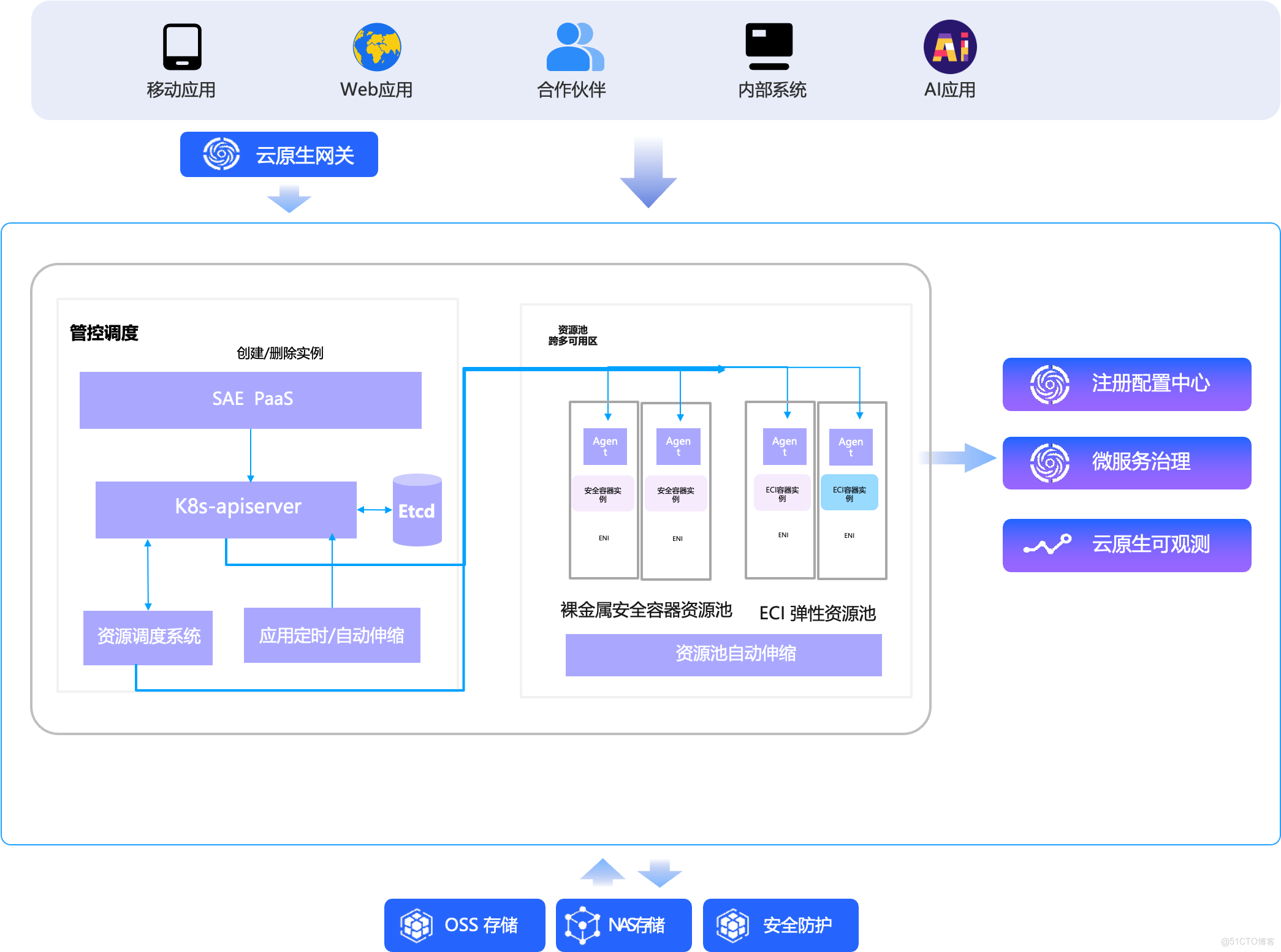
1. 破除“資源供給不確定性” → 構建無限彈性資源池
- 多源異構資源整合: SAE 背後打通神龍裸金屬服務器、彈性容器實例(ECI)支持各代 x86/ARM等海量資源,形成統一調度池。
- 智能跨機型調度: 當用户指定規格庫存不足時,調度器自動選擇性能相當、兼容性一致的替代資源(如 g7 缺貨 → 自動調度 g8i),全程對用户透明。
- 結果: 交付的是“計算能力”,而非“特定機型”,徹底規避因庫存波動導致的擴容失敗。
2. 解決“性能隔離難” → 天然沙箱化 + 獨佔資源
- 默認運行在 ECI 沙箱中: 每個應用實例運行在輕量級安全容器,實現內核級隔離,杜絕“嘈雜鄰居”干擾。
- 資源 100% 獨佔: 用户申請的 CPU、內存、網絡帶寬均由 runD 底層安全沙箱保障,無超分、無爭搶,性能穩定可預期。
- 結果: 剛性性能不再是“盡力而為”,而是確定性交付,尤其適合金融交易、實時推薦等敏感場景。
3. 調和“彈性與剛性矛盾” → 按實際用量計費 + 縮容至零
- 閒置不計費: 應用縮容到 0 實例時,CPU/內存資源完全釋放,不產生費用(僅保留配置元數據)。
- 秒級冷啓動優化: 結合鏡像預熱、快照加速、本地緩存等技術,大幅縮短首次啓動延遲,逼近“即時剛性響應”。
- 結果: 用户無需為“以防萬一”長期預留資源,剛性保障與極致成本兼得,替代高風險混部策略。
4. 簡化“異構資源管理” → 屏蔽底層複雜性
- ARM/x86 無縫兼容: 如支持海光國產芯片,用户只需提供兼容鏡像,SAE 自動完成調度與運行時適配。
- 結果: 開發者只需關注“我要多少算力”,無需關心“卡在哪台機器上、驅動是否匹配”。
5. 重構“成本模型” → 從“買資源”到“買能力”
- 按實際 CPU/內存使用量秒級計費: 不再按整機小時付費,避免資源閒置浪費。
- 免運維成本: 無需管理節點、打補丁、編寫擴縮容腳本,人力成本大幅降低。
- 結果: 剛性交付不再昂貴,中小企業也能享受企業級可靠性。
6. 強化“容災與高可用” → 多可用區剛性容災
- 一鍵開啓多 AZ 部署: SAE 自動將應用實例分散到多個可用區,跨機房冗餘。
- AZ 故障自動恢復: 若某 AZ 整體不可用,SAE 在其他 AZ 剛性拉起新實例,RTO控制在分鐘級。
- 結果: 剛性交付從“單點穩定”升級為“應用級連續性保障”。
7. 提升“可觀測性與可信度” → 內置全鏈路監控
- 集成 ARMS + SLS + Prometheus: 提供應用性能監控(APM)、日誌、指標、鏈路追蹤一體化視圖。
- 資源使用透明化: 用户可清晰看到 CPU 使用率、內存水位、網絡吞吐是否達到承諾值。
- 結果: 剛性 SLA 可驗證、可審計,告別“黑盒交付”。
8. 支持“傳統應用平滑演進” → 兼顧穩定與未來
- 支持 WAR/JAR/鏡像直接部署: ERP、OA 等單體應用無需改造即可運行在 SAE 上,享受剛性資源保障。
- 內置診斷能力: 通過性能剖析定位瓶頸(如數據庫慢查詢、線程阻塞),為後續微服務拆分提供數據依據。
- 結果: SAE 不僅是“運行平台”,更是企業雲原生轉型的跳板。
瞭解 Serverless 應用引擎 SAE
阿里雲 Serverless 應用引擎 SAE 是面向 AI 時代的一站式容器化應用託管平台,以“託底傳統應用、加速 AI 創新”為核心理念。它簡化運維、保障穩定、閒置特性降低 75% 成本,並通過 AI 智能助手提升運維效率。

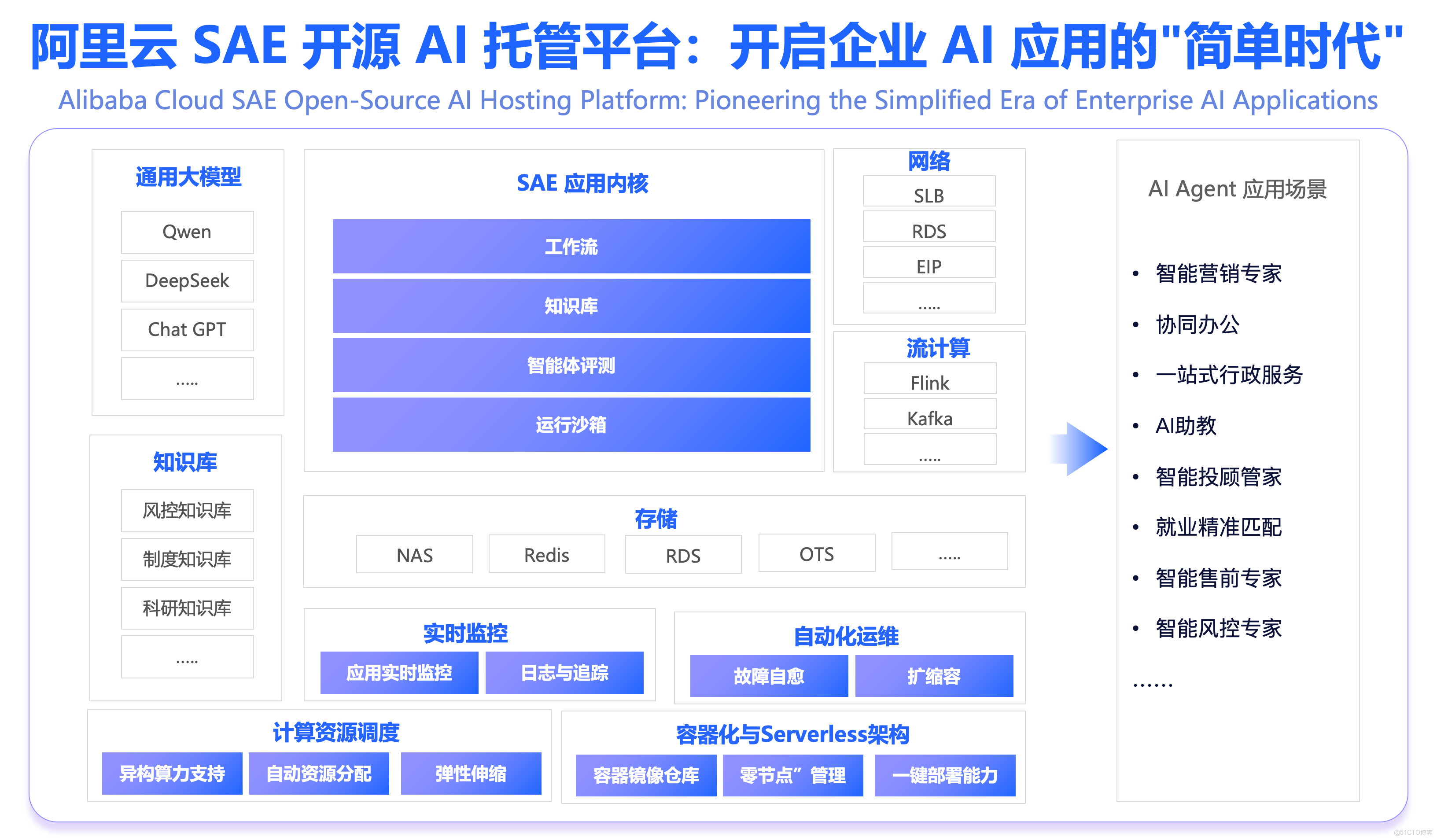
產品優勢
憑藉八年技術沉澱,SAE 入選 2025 年 Gartner 雲原生魔力象限全球領導者,亞洲第一,助力企業零節點管理、專注業務創新。SAE 既是傳統應用現代化的“託舉平台”,也是 AI 應用規模化落地的“加速引擎”。
- 傳統應用運維的“簡、穩、省”優化之道
- 簡:零運維心智,專注業務創新
- 穩:企業級高可用,內置全方位保障
- 省:極致彈性,將成本降至可度量
2.加速 AI 創新:從快速探索到高效落地
- 快探索:內置 Dify、RAGFlow、OpenManus 等 熱門 AI 應用模板,開箱即用,分鐘級啓動 POC;
- 穩落地:提供生產級 AI 運行時,性能優化(如 Dify 性能提升 50 倍)、無感升級、多版本管理,確保企業級可靠交付;
- 易集成:深度打通網關、ARMS、計量、審計等能力,助力傳統應用智能化升級。
適合誰?
✅ 創業團隊:沒有專職運維,需要快速上線 ✅ 中小企業:想降本增效,擁抱雲原生 ✅ 大型企業:需要企業級穩定性和合規性 ✅ 出海企業:需要中國區 + 全球部署 ✅ AI 創新團隊:想快速落地AI應用
瞭解更多
產品詳情頁地址:https://www.aliyun.com/product/sae
SAE 客户服務羣
