
開發調試到生產上線,全流程僅需一個工作區——DevPod重新定義AI工程化標準,當開發與部署不再割裂,模型價值才真正釋放。
簡介
告別碎片化開發體驗,DevPod 打造從代碼到服務的一站式閉環。本文手把手演示在函數計算 Funmodel 上完成 DeepSeek-OCR 模型從雲端開發、本地調試到生產部署的完整工作流,讓模型真正走出實驗室,實現分鐘級服務化,重塑 AI 模型從開發到落地的高效路徑。
回顧:為何 DevPod 讓 DeepSeek-OCR 啓動如此簡單?
在系列第一篇《為什麼別人用 DevPod 秒啓 DeepSeek-OCR,你還在裝環境?》中,我們見證了 DevPod 如何將原本繁瑣的環境配置、依賴安裝、硬件適配等過程壓縮至 60 秒內完成。無需再為 CUDA 版本衝突、Python 環境隔離、模型權重下載緩慢而煩惱,DevPod 通過雲端預置環境,讓開發者一進入工作區就能立即與 DeepSeek-OCR 大模型進行交互,真正實現了"開箱即用"的 AI 開發體驗。
DevPod 是一款雲原生 AI 開發工具,提供統一工作空間與預置環境,實現開發、測試、生產環境一致性,徹底消除“環境漂移”問題。
它能一鍵調用 GPU 資源,支持代碼編寫、調試、模型調優、鏡像封裝與生產部署全流程操作,無需切換多平台工具。
還可與 FunModel 深度集成,提供性能監控、日誌分析、在線調試與快速迭代能力,讓 AI 模型從實驗室到服務化落地更高效。
從開發到生產:DevPod 全流程閉環工作流
然而,啓動模型僅僅是開始。在實際業務場景中,我們還需要完成模型調優、代碼調試、性能測試、服務封裝、生產部署等一系列環節。傳統方式下,這些步驟往往涉及多個平台和工具的切換,數據和代碼在不同環境間流轉,極易出現"在我機器上能運行"的尷尬局面。
DevPod 通過統一的工作空間和無縫銜接的部署能力,打通了從代碼到服務的最後一公里。下面,我們將通過 DeepSeek-OCR 模型的實戰案例,完整演示這一工作流。
1. 開發調試階段:VSCode + GPU 加速的雲端實驗室
在 DevPod 中啓動 DeepSeek-OCR 環境實例後,我們立即獲得一個配備 GPU 的雲端 VSCode 開發環境。這不僅是一個模型運行的容器,更是一個完整的端到端研究與開發平台。基於 DeepSeek-OCR-vLLM 提供的代碼推理示例,我們構建了 server.py 作為推理服務的核心入口,實現了高效、可擴展的推理接口(完整代碼詳見附錄)。
/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/server.py
import os
import io
import torch
import uvicorn
import requests
from PIL import Image
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional, Dict, Any, List
import tempfile
import fitz
from concurrent.futures import ThreadPoolExecutor
import asyncio
# Set environment variables
if torch.version.cuda == '11.8':
os.environ["TRITON_PTXAS_PATH"] = "/usr/local/cuda-11.8/bin/ptxas"
os.environ['VLLM_USE_V1'] = '0'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
from config import MODEL_PATH, CROP_MODE, MAX_CONCURRENCY, NUM_WORKERS
from vllm import LLM, SamplingParams
from vllm.model_executor.models.registry import ModelRegistry
from deepseek_ocr import DeepseekOCRForCausalLM
from process.ngram_norepeat import NoRepeatNGramLogitsProcessor
from process.image_process import DeepseekOCRProcessor
# Register model
ModelRegistry.register_model("DeepseekOCRForCausalLM", DeepseekOCRForCausalLM)
# Initialize model
print("Loading model...")
...
# Initialize FastAPI app
app = FastAPI(title="DeepSeek-OCR API", version="1.0.0")
...
@app.post("/ocr_batch", response_model=ResponseData)
async def ocr_batch_inference(request: RequestData):
"""
Main OCR batch processing endpoint
Accepts a list of image URLs and/or PDF URLs for OCR processing
Returns a list of OCR results corresponding to each input document
Supports both individual image processing and PDF-to-image conversion
"""
print(f"Received request data: {request}")
try:
input_data = request.input
prompt = request.prompt # Get the prompt from the request
if not input_data.images and not input_data.pdfs:
raise HTTPException(status_code=400, detail="Either 'images' or 'pdfs' (or both) must be provided as lists.")
all_batch_inputs = []
final_output_parts = []
# Process images if provided
if input_data.images:
batch_inputs_images, counts_images = await process_items_async(input_data.images, is_pdf=False, prompt=prompt)
all_batch_inputs.extend(batch_inputs_images)
final_output_parts.append(counts_images)
# Process PDFs if provided
if input_data.pdfs:
batch_inputs_pdfs, counts_pdfs = await process_items_async(input_data.pdfs, is_pdf=True, prompt=prompt)
all_batch_inputs.extend(batch_inputs_pdfs)
final_output_parts.append(counts_pdfs)
if not all_batch_inputs:
raise HTTPException(status_code=400, detail="No valid images or PDF pages were processed from the input URLs.")
# Run inference on the combined batch
outputs_list = await run_inference(all_batch_inputs)
# Reconstruct final output list based on counts
final_outputs = []
output_idx = 0
# Flatten the counts list
all_counts = [count for sublist in final_output_parts for count in sublist]
for count in all_counts:
# Get 'count' number of outputs for this input
input_outputs = outputs_list[output_idx : output_idx + count]
output_texts = []
for output in input_outputs:
content = output.outputs[0].text
if '<|end▁of▁sentence|>' in content:
content = content.replace('<|end▁of▁sentence|>', '')
output_texts.append(content)
# Combine pages if it was a multi-page PDF input (or image treated as PDF)
if count > 1:
combined_text = "\n<--- Page Split --->\n".join(output_texts)
final_outputs.append(combined_text)
else:
# Single image or single-page PDF
final_outputs.append(output_texts[0] if output_texts else "")
output_idx += count # Move to the next set of outputs
return ResponseData(output=final_outputs)
except HTTPException:
raise
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal server error: {str(e)}")
...
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, workers=1)
local 測試
# 終端啓動推理服務
$ python /workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/server.py
# 開啓另外一個終端
$ curl -X POST \
-H "Content-Type: application/json" \
-d '{
"input": {
"pdfs": [
"https://images.devsapp.cn/test/ocr-test.pdf"
]
},
"prompt": "<image>\nFree OCR."
}' \
http://127.0.0.1:8000/ocr_batch
也可以通過快速訪問 tab 獲取代理路徑,比如: https://devpod-dbbeddba-ngywxigepn.cn-hangzhou.ide.fc.aliyun.com/proxy/8000/, 並通過外部的 Postman 等客户端工具直接調用調試。
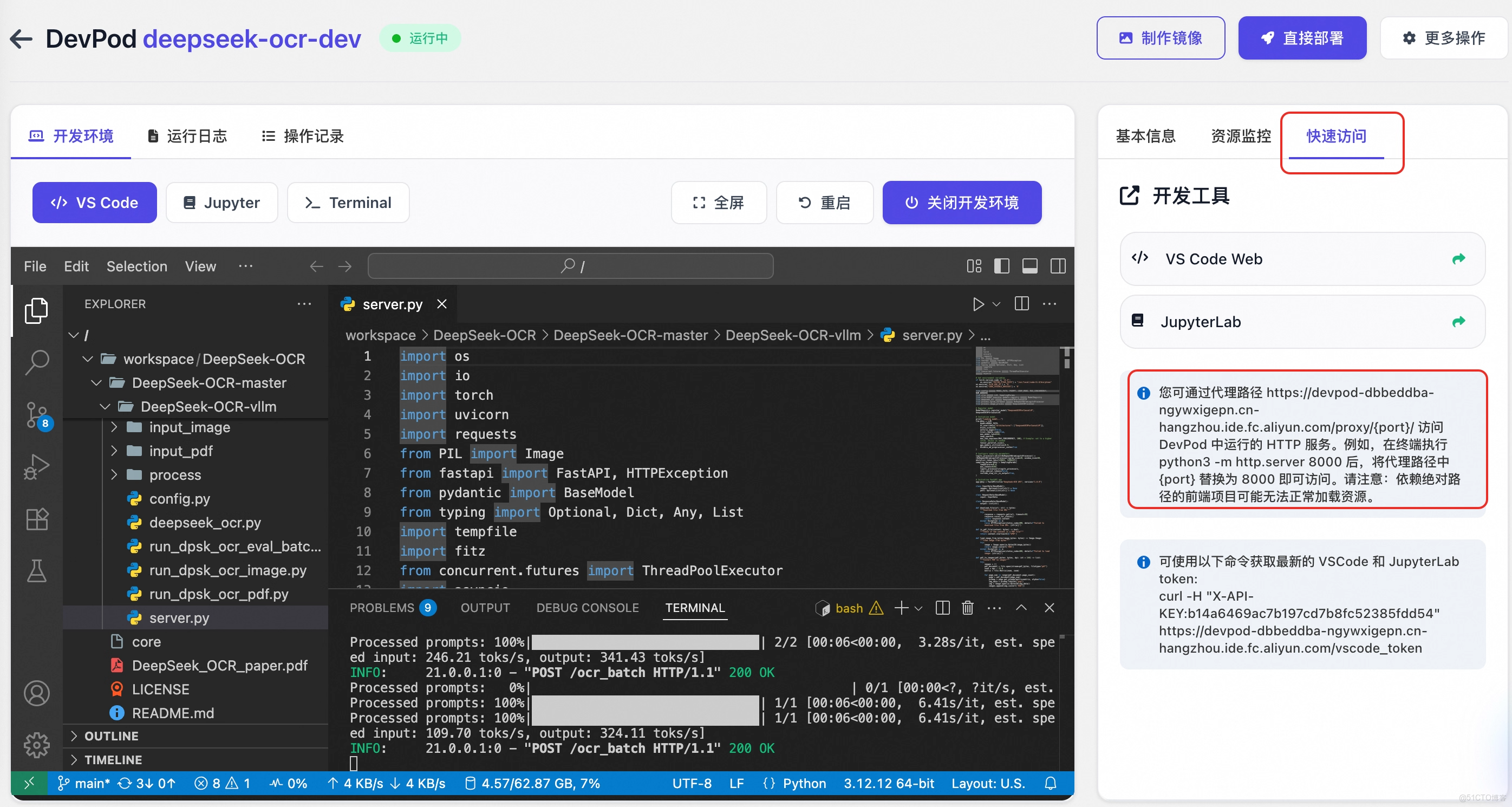
測試 image
$ curl -X POST \
-H "Content-Type: application/json" \
-d '{
"input": {
"images": [
"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png"
]
},
"prompt": "<image>\n<|grounding|>Convert the document to markdown."
}' \
"https://devpod-dbbeddba-ngywxigepn.cn-hangzhou.ide.fc.aliyun.com/proxy/8000/ocr_batch"
測試 pdf
$ curl -X POST \
-H "Content-Type: application/json" \
-d '{
"input": {
"pdfs": [
"https://images.devsapp.cn/test/ocr-test.pdf"
]
},
"prompt": "<image>\nFree OCR."
}' \
"https://devpod-dbbeddba-ngywxigepn.cn-hangzhou.ide.fc.aliyun.com/proxy/8000/ocr_batch"
示例:

混合
$ curl -X POST \
-H "Content-Type: application/json" \
-d '{
"input": {
"pdfs": [
"https://images.devsapp.cn/test/ocr-test.pdf"
],
"images": [
"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png"
]
},
"prompt": "<image>\nFree OCR."
}' \
"https://devpod-dbbeddba-ngywxigepn.cn-hangzhou.ide.fc.aliyun.com/proxy/8000/ocr_batch"
DevPod 的優勢在於:所有依賴已預裝,GPU 資源即開即用,開發者可以專注於算法優化和業務邏輯,而非環境問題。
2. 服務封裝階段:一鍵轉換為鏡像交付物
當模型在開發環境中驗證通過後,下一步是將其封裝為鏡像交付物。在 FunModel 的 DevPod 中,這僅需如下操作:
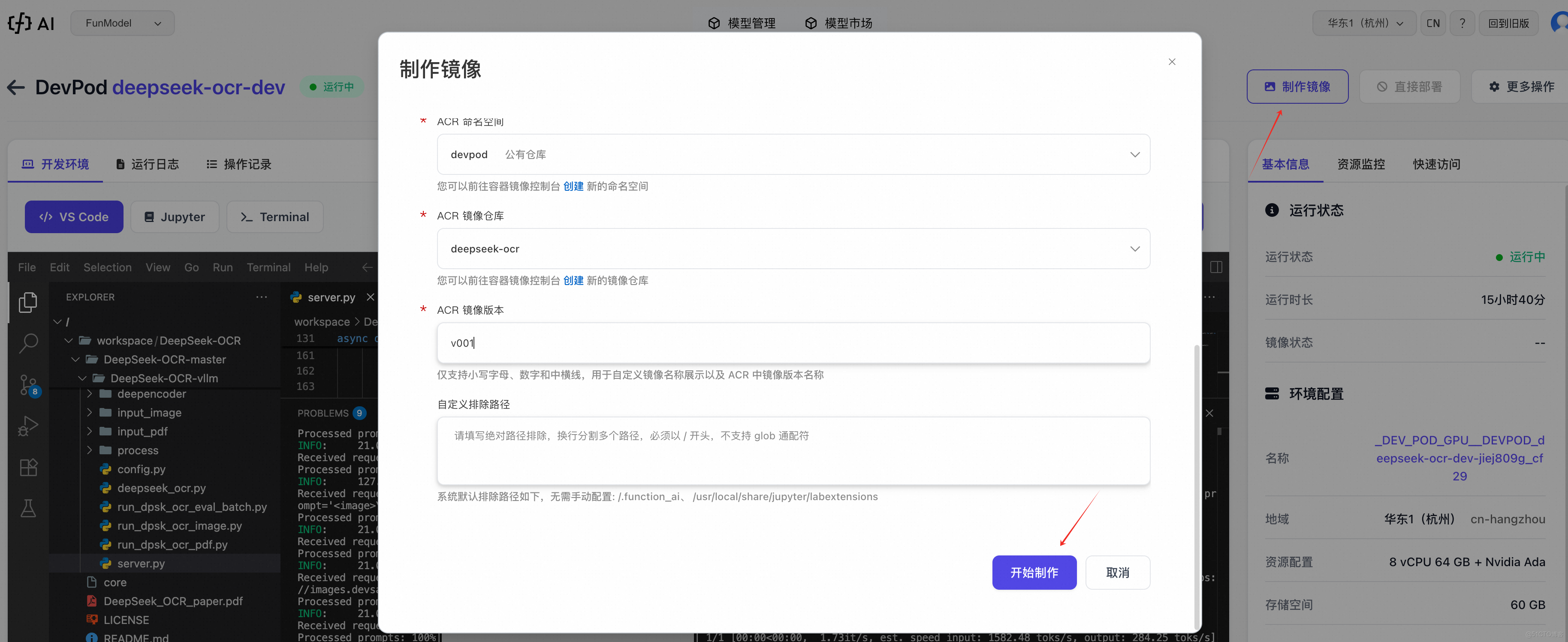
詳情請參考 DevPod 鏡像構建與ACR集成
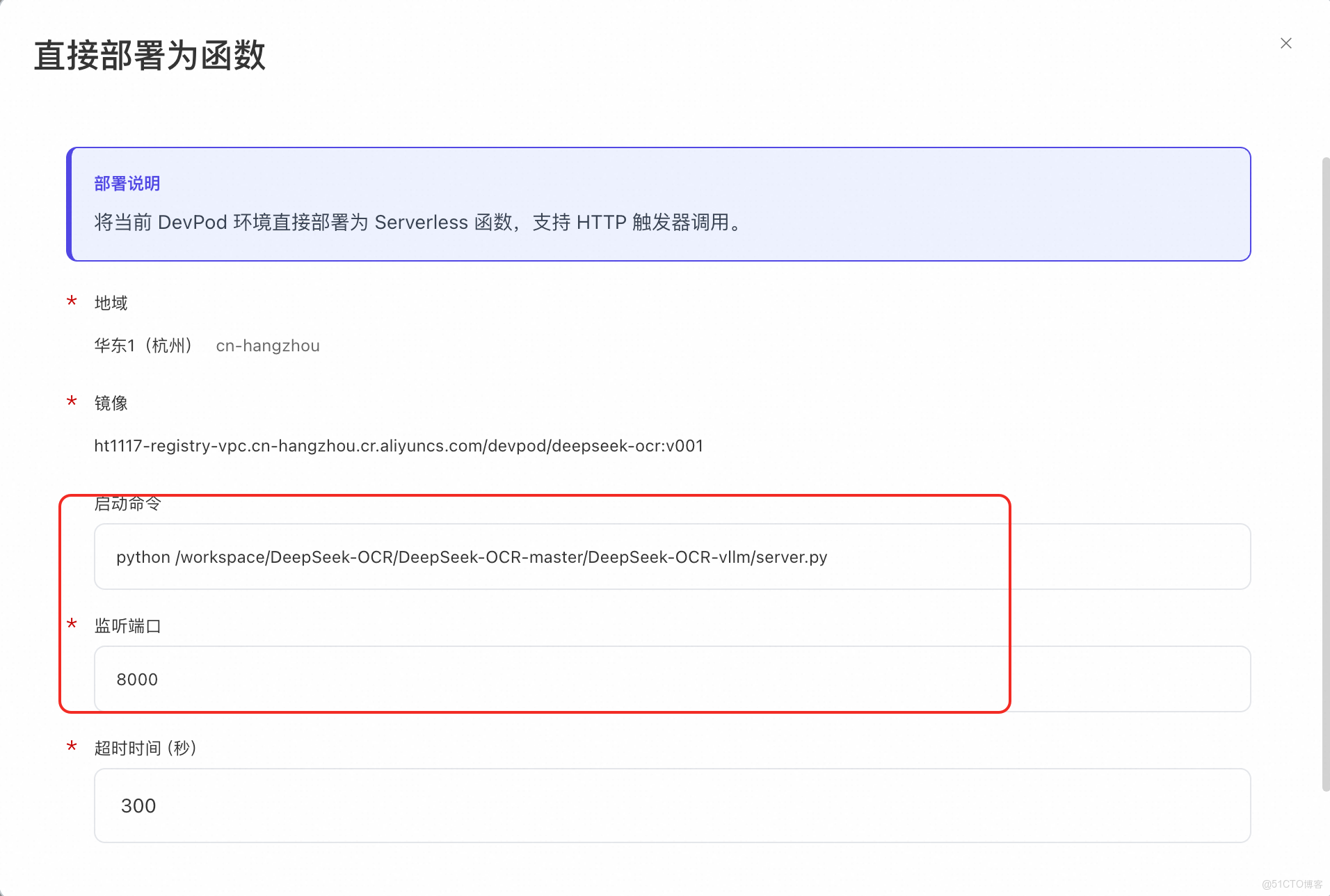
3. 一鍵部署:從工作區到生產環境
鏡像構建推送完畢後,鏡像已經存儲到 ACR,此時可以一鍵部署為 FunModel 模型服務。

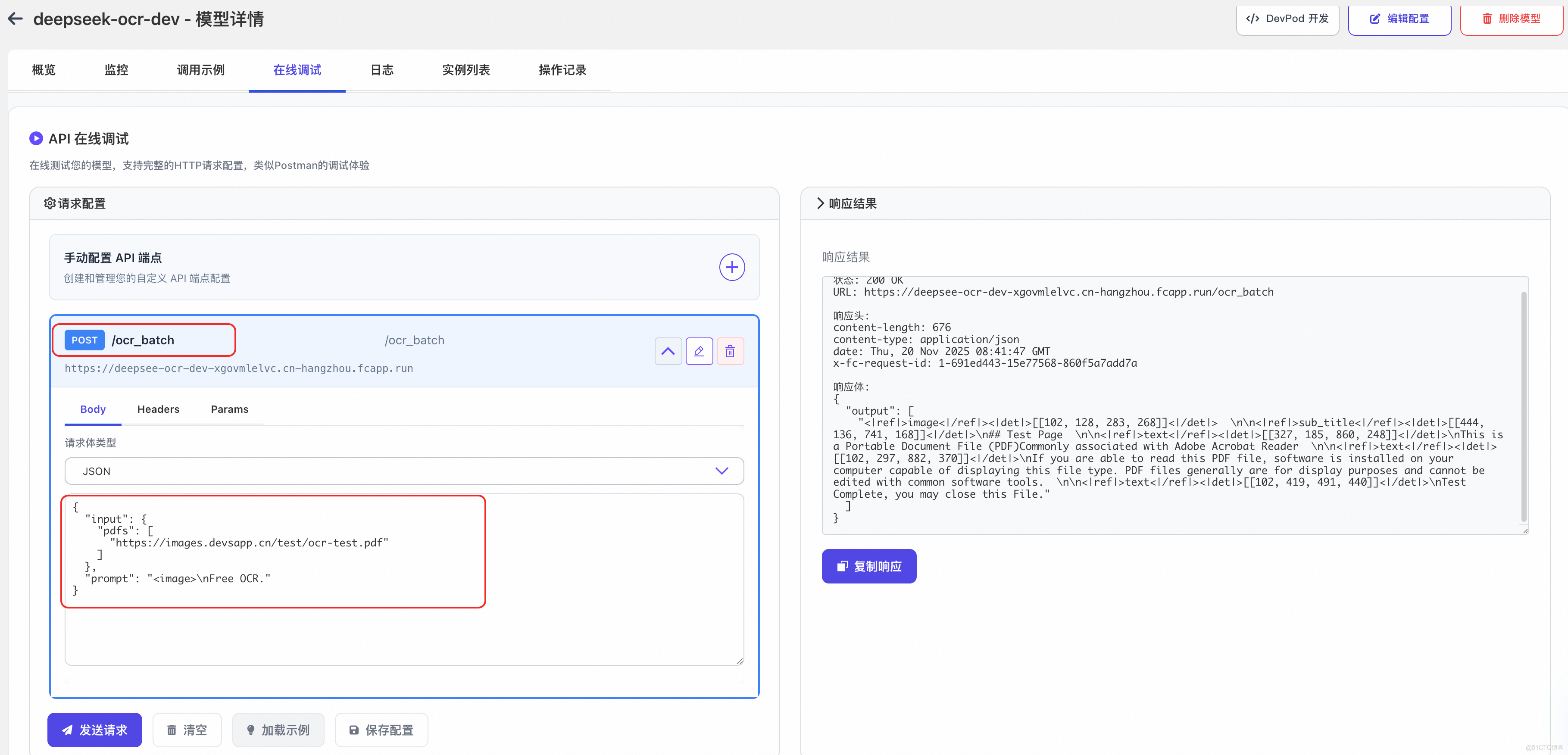
4. 監控與迭代:閉環的開發運維體驗
部署不是終點。DevPod 與 FunModel 深度集成,提供了完整的監控面板:
- 性能監控:實時查看 GPU 利用率、請求延遲、吞吐量
- 日誌分析:集中收集所有實例日誌,支持關鍵詞檢索
- 變更部署記錄:每次變更配置(如卡型、擴縮容策略、 timeout 等)的部署都有記錄追溯
- 在線快捷調試:快速測試部署後的模型服務
當需要優化模型或修復問題時,開發者可以:
- 在監控中發現問題
- 直接打開 DevPod 繼續開發調試
- 驗證修復方案
- 製作新的鏡像, 一鍵部署

整個過程在統一環境中完成,避免了環境不一致導致的問題,真正實現了開發與運維的無縫協作。
總結
通過本文的實戰演示,我們可以看到 DevPod 不僅解決了"啓動難"的問題,更構建了從代碼到服務的完整閉環:
- 環境一致性:開發、測試、生產環境完全一致,消除"環境漂移"
- 資源彈性:按需分配 GPU 資源,開發時低配,生產時高配
- 工作流集成:無需在多個平台間切換,所有操作在一個工作區完成
- 部署零學習曲線:無需掌握 K8s、Dockerfile 等複雜概念,專注業務價值
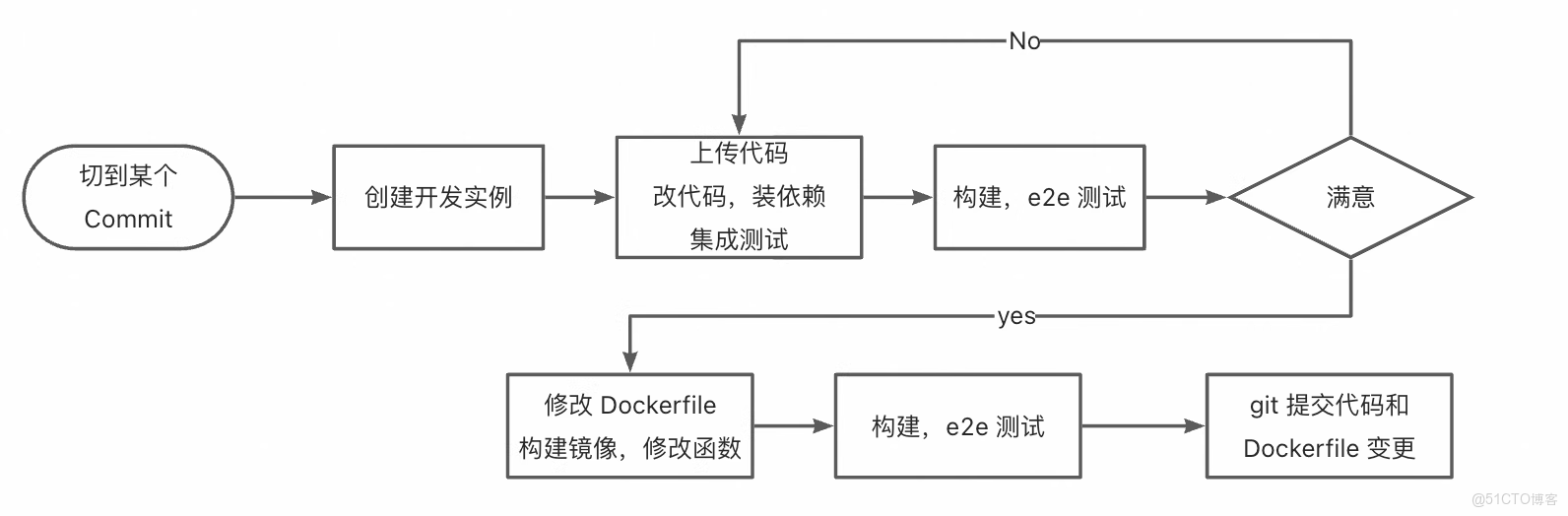
DevFlow1:雲端開發與部署的無縫閉環
DevFlow1 描繪了開發者基於 DevPod 實現的高效工作流:
- 開發者首先啓動一個預配置的雲端開發環境——已內置所需依賴與 GPU 資源,可即刻進行代碼編寫與調試。
- 代碼修改完成後,無需手動編寫 Dockerfile 或管理構建流程,只需一鍵操作,系統即自動將當前開發環境與代碼打包為標準化鏡像。
- 該鏡像可直接部署為生產級服務,對外提供 API 接口。
- 當需要迭代優化時,開發者可無縫返回開發環境繼續修改,再次一鍵構建並更新線上服務。 整個流程實現了從開發、調試到部署、迭代的全鏈路自動化,徹底屏蔽了基礎設施的複雜性,讓開發者真正聚焦於業務邏輯與模型優化本身。
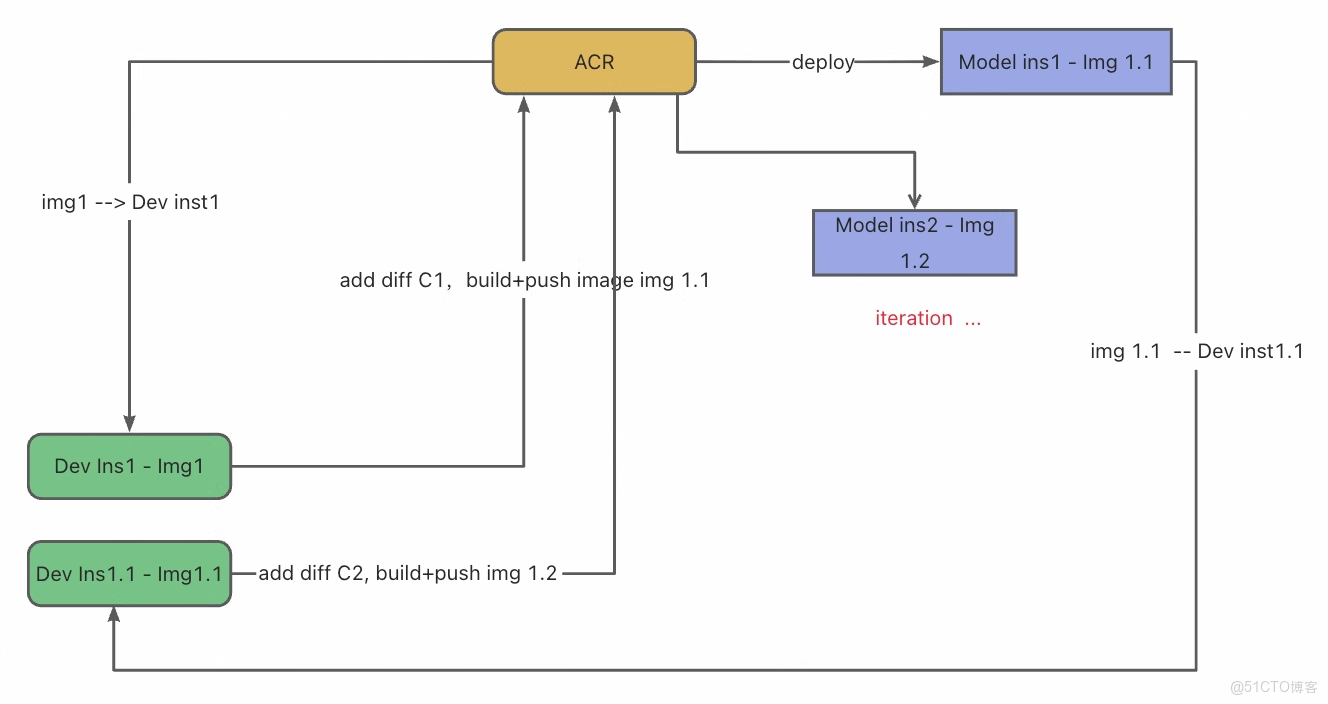
DevFlow2:面向工程化的開發者工作流
DevFlow2 適用於熟悉容器化與工程化實踐的開發者:
- 開發者從代碼倉庫的指定穩定版本(Commit)切入,啓動專屬開發環境,進行代碼迭代、依賴安裝及集成測試。
- 一旦測試驗證通過且結果符合預期,開發者即可着手準備部署:手動編寫或調整 Dockerfile,精確配置鏡像構建邏輯,並按需設定函數入口或服務參數。
- 隨後,系統依據該 Dockerfile 重建鏡像,並執行端到端測試,以確保生產環境中的行為一致性。
- 最終,代碼與 Dockerfile 變更一同提交至 Git,完成一次標準、可追溯且可復現的發佈流程。
此流程賦予開發者對部署細節的精細控制,契合追求工程規範與長期可維護性的團隊需求。
在阿里雲 FunModel 平台,我們正在見證 AI 開發範式的轉變:從"先建基礎設施,再開發模型"到"先驗證想法,再擴展規模"。DevPod 作為這一變革的核心載體,讓 AI 開發者真正迴歸創造本身,而非被工具和環境所束縛。
瞭解函數計算模型服務 FunModel
FunModel 是一個面向 AI 模型開發、部署與運維的全生命週期管理平台。您只需提供模型文件(例如來自 ModelScope、Hugging Face 等社區的模型倉庫),即可利用 FunModel 的自動化工具快速完成模型服務的封裝與部署,並獲得可直接調用的推理 API。平台在設計上旨在提升資源使用效率並簡化開發部署流程。
FunModel 依託 Serverless + GPU,天然提供了簡單,輕量,0 門檻的模型集成方案,給個人開發者良好的玩轉模型的體驗,也讓企業級開發者快速高效的部署、運維和迭代模型。
在阿里雲 FunModel 平台,開發者可以做到:
- 模型的快速部署上線:從原來的以周為單位的模型接入週期降低到 5 分鐘,0 開發,無排期
- 一鍵擴縮容,讓運維不再是負擔:多種擴縮容策略高度適配業務流量,實現“無痛運維”
技術優勢
| 特性 | FunModel 實現機制 | 説明 |
|---|---|---|
| 資源利用率 | 採用 GPU 虛擬化與資源池化技術。 | 該設計允許多個任務共享底層硬件資源,旨在提高計算資源的整體使用效率。 |
| 實例就緒時間 | 基於快照技術的狀態恢復機制。 | 實例啓動時,可通過快照在毫秒級別恢復運行狀態,從而將實例從創建到就緒的時間控制在秒級。 |
| 彈性擴容響應 | 結合預熱資源池與快速實例恢復能力。 | 當負載增加時,系統可以從預熱資源池中快速調度並啓動新實例,實現秒級的水平擴展響應。 |
| 自動化部署耗時 | 提供可一鍵觸發的構建與部署流程。 | 一次標準的部署流程(從代碼提交到服務上線)通常可在10分鐘內完成。 |
訪問模型廣場(https://fcnext.console.aliyun.com/fun-model/cn-hangzhou/fun-model/model-market)快速部署 DeepSeek-OCR。
更多內容請參考
- 模型服務FunModel 產品文檔
- FunModel快速入門
- FunModel 自定義部署
- FunModel 模型廣場
附錄
完整代碼:
/workspace/DeepSeek-OCR/DeepSeek-OCR-master/DeepSeek-OCR-vllm/server.py
import os
import io
import torch
import uvicorn
import requests
from PIL import Image
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional, Dict, Any, List
import tempfile
import fitz
from concurrent.futures import ThreadPoolExecutor
import asyncio
# Set environment variables
if torch.version.cuda == '11.8':
os.environ["TRITON_PTXAS_PATH"] = "/usr/local/cuda-11.8/bin/ptxas"
os.environ['VLLM_USE_V1'] = '0'
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
from config import MODEL_PATH, CROP_MODE, MAX_CONCURRENCY, NUM_WORKERS
from vllm import LLM, SamplingParams
from vllm.model_executor.models.registry import ModelRegistry
from deepseek_ocr import DeepseekOCRForCausalLM
from process.ngram_norepeat import NoRepeatNGramLogitsProcessor
from process.image_process import DeepseekOCRProcessor
# Register model
ModelRegistry.register_model("DeepseekOCRForCausalLM", DeepseekOCRForCausalLM)
# Initialize model
print("Loading model...")
llm = LLM(
model=MODEL_PATH,
hf_overrides={"architectures": ["DeepseekOCRForCausalLM"]},
block_size=256, # Memory block size for KV cache
enforce_eager=False, # Use eager mode for better performance with multimodal models
trust_remote_code=True, # Allow execution of code from remote repositories
max_model_len=8192, # Maximum sequence length the model can handle
swap_space=0, # No swapping to CPU, keeping everything on GPU
max_num_seqs=max(MAX_CONCURRENCY, 100), # Maximum number of sequences to process concurrently
tensor_parallel_size=1, # Number of GPUs for tensor parallelism (1 = single GPU)
gpu_memory_utilization=0.9, # Use 90% of GPU memory for model execution
disable_mm_preprocessor_cache=True # Disable cache for multimodal preprocessor to avoid issues
)
# Configure sampling parameters
# NoRepeatNGramLogitsProcessor prevents repetition in generated text by tracking n-gram patterns
logits_processors = [NoRepeatNGramLogitsProcessor(ngram_size=20, window_size=50, whitelist_token_ids={128821, 128822})]
sampling_params = SamplingParams(
temperature=0.0, # Deterministic output (greedy decoding)
max_tokens=8192, # Maximum number of tokens to generate
logits_processors=logits_processors, # Apply the processor to avoid repetitive text
skip_special_tokens=False, # Include special tokens in the output
include_stop_str_in_output=True, # Include stop strings in the output
)
# Initialize FastAPI app
app = FastAPI(title="DeepSeek-OCR API", version="1.0.0")
class InputData(BaseModel):
"""
Input data model to define what types of documents to process
images: Optional list of image URLs to process
pdfs: Optional list of PDF URLs to process
Note: At least one of these fields must be provided in a request
"""
images: Optional[List[str]] = None
pdfs: Optional[List[str]] = None
class RequestData(BaseModel):
"""
Main request model that defines the input data and optional prompt
"""
input: InputData
# Add prompt as an optional field with a default value
prompt: str = '<image>\nFree OCR.' # Default prompt
class ResponseData(BaseModel):
"""
Response model that returns OCR results for each input document
"""
output: List[str]
def download_file(url: str) -> bytes:
"""Download file from URL"""
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
return response.content
except Exception as e:
raise HTTPException(status_code=400, detail=f"Failed to download file from URL: {str(e)}")
def is_pdf_file(content: bytes) -> bool:
"""Check if the content is a PDF file"""
return content.startswith(b'%PDF')
def load_image_from_bytes(image_bytes: bytes) -> Image.Image:
"""Load image from bytes"""
try:
image = Image.open(io.BytesIO(image_bytes))
return image.convert('RGB')
except Exception as e:
raise HTTPException(status_code=400, detail=f"Failed to load image: {str(e)}")
def pdf_to_images(pdf_bytes: bytes, dpi: int = 144) -> list:
"""Convert PDF to images"""
try:
images = []
pdf_document = fitz.open(stream=pdf_bytes, filetype="pdf")
zoom = dpi / 72.0
matrix = fitz.Matrix(zoom, zoom)
for page_num in range(pdf_document.page_count):
page = pdf_document[page_num]
pixmap = page.get_pixmap(matrix=matrix, alpha=False)
img_data = pixmap.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img.convert('RGB'))
pdf_document.close()
return images
except Exception as e:
raise HTTPException(status_code=400, detail=f"Failed to convert PDF to images: {str(e)}")
def process_single_image_sync(image: Image.Image, prompt: str) -> Dict: # Renamed and made sync
"""Process a single image (synchronous function for CPU-bound work)"""
try:
cache_item = {
"prompt": prompt,
"multi_modal_data": {
"image": DeepseekOCRProcessor().tokenize_with_images(
images=[image],
bos=True,
eos=True,
cropping=CROP_MODE
)
},
}
return cache_item
except Exception as e:
raise HTTPException(status_code=500, detail=f"Failed to process image: {str(e)}")
async def process_items_async(items_urls: List[str], is_pdf: bool, prompt: str) -> tuple[List[Dict], List[int]]:
"""
Process a list of image or PDF URLs asynchronously.
Downloads files concurrently, then processes images/PDF pages in a thread pool.
Returns a tuple: (batch_inputs, num_results_per_input)
"""
loop = asyncio.get_event_loop()
# 1. Download all files concurrently
download_tasks = [loop.run_in_executor(None, download_file, url) for url in items_urls]
contents = await asyncio.gather(*download_tasks)
# 2. Prepare arguments for processing (determine if PDF/image, count pages)
processing_args = []
num_results_per_input = []
for idx, (url, content) in enumerate(zip(items_urls, contents)):
if is_pdf:
if not is_pdf_file(content):
raise HTTPException(status_code=400, detail=f"Provided file is not a PDF: {url}")
images = pdf_to_images(content)
num_pages = len(images)
num_results_per_input.append(num_pages)
# Each page will be processed separately
processing_args.extend([(img, prompt) for img in images])
else: # is image
if is_pdf_file(content):
# Handle case where an image URL accidentally points to a PDF
images = pdf_to_images(content)
num_pages = len(images)
num_results_per_input.append(num_pages)
processing_args.extend([(img, prompt) for img in images])
else:
image = load_image_from_bytes(content)
num_results_per_input.append(1)
processing_args.append((image, prompt))
# 3. Process images/PDF pages in parallel using ThreadPoolExecutor
with ThreadPoolExecutor(max_workers=NUM_WORKERS) as executor:
# Submit all processing tasks
process_tasks = [
loop.run_in_executor(executor, process_single_image_sync, img, prompt)
for img, prompt in processing_args
]
# Wait for all to complete
processed_results = await asyncio.gather(*process_tasks)
return processed_results, num_results_per_input
async def run_inference(batch_inputs: List[Dict]) -> List:
"""Run inference on batch inputs"""
if not batch_inputs:
return []
try:
# Run inference on the entire batch
outputs_list = llm.generate(
batch_inputs,
sampling_params=sampling_params
)
return outputs_list
except Exception as e:
raise HTTPException(status_code=500, detail=f"Failed to run inference: {str(e)}")
@app.post("/ocr_batch", response_model=ResponseData)
async def ocr_batch_inference(request: RequestData):
"""
Main OCR batch processing endpoint
Accepts a list of image URLs and/or PDF URLs for OCR processing
Returns a list of OCR results corresponding to each input document
Supports both individual image processing and PDF-to-image conversion
"""
print(f"Received request data: {request}")
try:
input_data = request.input
prompt = request.prompt # Get the prompt from the request
if not input_data.images and not input_data.pdfs:
raise HTTPException(status_code=400, detail="Either 'images' or 'pdfs' (or both) must be provided as lists.")
all_batch_inputs = []
final_output_parts = []
# Process images if provided
if input_data.images:
batch_inputs_images, counts_images = await process_items_async(input_data.images, is_pdf=False, prompt=prompt)
all_batch_inputs.extend(batch_inputs_images)
final_output_parts.append(counts_images)
# Process PDFs if provided
if input_data.pdfs:
batch_inputs_pdfs, counts_pdfs = await process_items_async(input_data.pdfs, is_pdf=True, prompt=prompt)
all_batch_inputs.extend(batch_inputs_pdfs)
final_output_parts.append(counts_pdfs)
if not all_batch_inputs:
raise HTTPException(status_code=400, detail="No valid images or PDF pages were processed from the input URLs.")
# Run inference on the combined batch
outputs_list = await run_inference(all_batch_inputs)
# Reconstruct final output list based on counts
final_outputs = []
output_idx = 0
# Flatten the counts list
all_counts = [count for sublist in final_output_parts for count in sublist]
for count in all_counts:
# Get 'count' number of outputs for this input
input_outputs = outputs_list[output_idx : output_idx + count]
output_texts = []
for output in input_outputs:
content = output.outputs[0].text
if '<|end▁of▁sentence|>' in content:
content = content.replace('<|end▁of▁sentence|>', '')
output_texts.append(content)
# Combine pages if it was a multi-page PDF input (or image treated as PDF)
if count > 1:
combined_text = "\n<--- Page Split --->\n".join(output_texts)
final_outputs.append(combined_text)
else:
# Single image or single-page PDF
final_outputs.append(output_texts[0] if output_texts else "")
output_idx += count # Move to the next set of outputs
return ResponseData(output=final_outputs)
except HTTPException:
raise
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal server error: {str(e)}")
@app.get("/health")
async def health_check():
"""Health check endpoint"""
return {"status": "healthy"}
@app.get("/")
async def root():
"""Root endpoint"""
return {"message": "DeepSeek-OCR API is running (Batch endpoint available at /ocr_batch)"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, workers=1)