

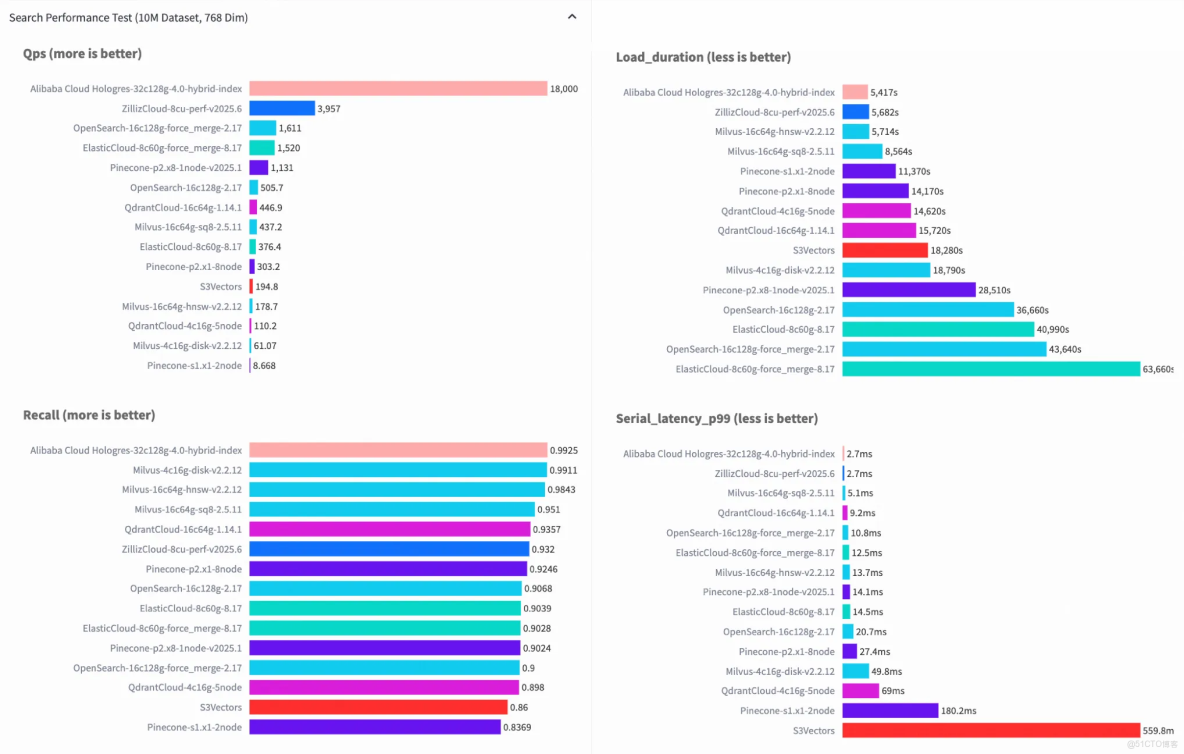
在數據驅動時代,非結構化數據(文本、圖像、音視頻、日誌等)與結構化、半結構化數據(JSON)共同構成企業的核心數據資產。其中,非結構化數據以更原始、多元的形態藴含着海量的業務洞察(如用户反饋、合同條款、產品缺陷圖像),Hologres4.0以“AI時代的一站式多模態分析平台”為核心理念,全面展示了Hologres在結構化、半結構化與非結構化數據分析能力上的重大突破,發佈全新向量索引HGraph,登頂 VectorDBBench 性價比榜單QPS、Recall、Latency、Load 四項第一,為AI應用的提供高性價比、高吞吐、低延遲、高併發的向量服務,成為全球最具性價比的向量數據庫!
基於Hologres構建多模態AI數據分析與檢索系統
本文將會模擬金融場景中對招股書、合同等PDF文件的檢索與分析,以輔助業務進行下一步的精細化運營決策。基於Hologres 4.0 對PDF非結構化數據的處理與檢索,包含的主要能力如下:
- 非結構化數據(Object Table):支持通過表的形式讀取OSS中非結構化數據(PDF/IMAGE/PPT等)。
- AI Function:在Hologres中可以用標準SQL的方式調用AI Function,自動調用內置大模型,完成AI服務建設場景
- 數據加工:提供Embed、Chunk算子,可以對非結構化數據加工成結構化數據存儲,無需使用外部算法就能自動Embed。
- 數據檢索和分析:提供
ai_gen、ai_summarize等算子,能夠通過SQL對數據進行推理、問題總結及翻譯等操作。
- Dynamic Table介紹:支持增量刷新模式對非結構化數據自動加工,每次只計算增量的數據有效減少重複計算,降低資源利用率。
- 向量檢索:支持標準SQL的向量檢索,用於非結構化數據的相似度搜索、場景識別等,在同一個查詢中可以自由地實現向量和標量的檢索。
- 全文檢索:通過倒排索引、分詞等機制實現對非結構化數據的高效檢索,支持關鍵詞匹配、短語檢索等豐富的檢索方式,實現更加靈活的檢索。
方案優勢
通過如上核心能力,在Hologres中多模態AI檢索與分析的核心優勢如下:
- 完整的AI數據處理流程:涵蓋從數據Embed、Chunk、增量加工、檢索/分析的全流程,開發人員可以使用大數據系統一樣,輕鬆構建AI應用。
- 標準SQL加工和分析非結構化數據:無需使用專用開發語言,純SQL就能完成非結構化數據提取、加工,也無需藉助外部系統,數據處理更加高效和簡單,降低開發人員學習成本。
- 檢索更精準、靈活和智能:可以輕鬆構建“關鍵詞+語義+多模態”的混合檢索鏈路,覆蓋從精準搜索到意圖理解的全場景需求。還能結合AI Function實現對用户意圖的深度理解,語義關聯和上下文推理,實現更智能的檢索能力。
- 數據不出庫,更安全:不需要將數據導出到外部系統,與hologres的多種安全能力無縫集成,高效保護數據安全。
本實踐文檔將會介紹如何通過上訴核心能力在Hologres中對非結構化數據加工和檢索,助力搭建企業級多模態AI數據平台,打破數據孤島,釋放全域數據價值
方案流程
本次方案的流程如下:
- 數據集準備。
將金融數據集中的PDF文件上傳至OSS存儲。
- PDF數據加工。
使用Object Table讀取PDF的元數據信息,然後創建增量刷新的Dynamic Table,並對數據進行Embed和Chunk,同時也對Dynamic Table構建向量索引和全文索引,以便後續檢索可以使用索引的能力。
- 使用
<font style="color:rgb(24, 24, 24);background-color:rgba(0, 0, 0, 0.04);">ai_embed</font>算子對將自然語言的問題進行Embedding,然後使用全文和向量雙路召回結果,並對結果進行排序,結合大模型的推理能力,最終輸出相似度最高的答案。

準備工作
- 數據準備
本文使用ModelScope公開的金融數據集中的PDF文件夾中的文件,共80份公司招股説明書。
- 環境準備
- 購買Hologres V4.0及以上版本實例並創建數據庫。
- 購買AI資源。
本文以large-96core-512GB-384GB、1個節點為例。
- 模型部署。本次方案使用的模型以及分配的資源為:
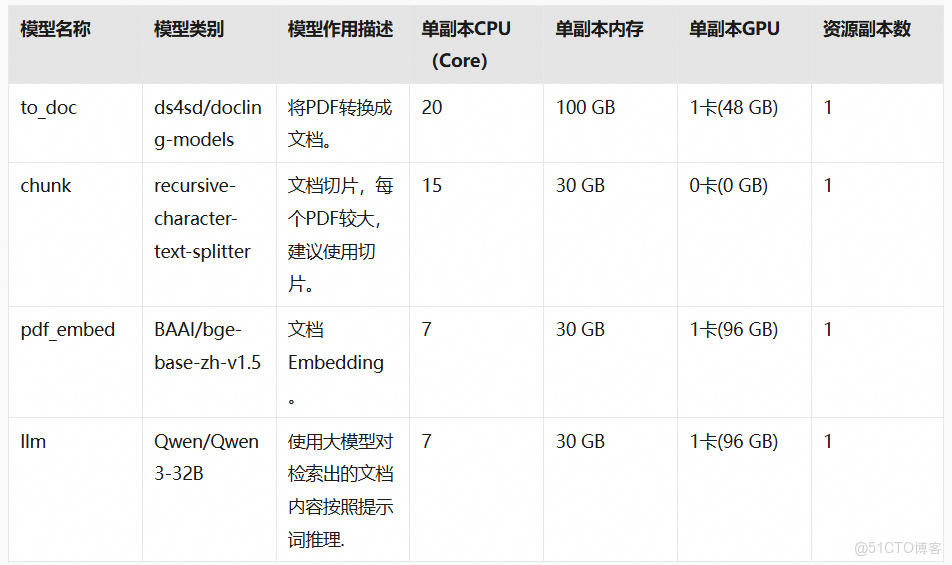
説明上述模型的資源均為默認分配的資源。
操作步驟
- 下載PDF文件並上傳至OSS。
- 下載博金大模型挑戰賽-金融千問14b數據集中80份招股書(PDF)。
- 登錄OSS管理控制枱,創建Bucket並將已下載的PDF文件上傳至該Bucket路徑下。上傳操作詳情,請參見簡單上傳。
- 賬號授權。
- 登錄RAM控制枱,創建阿里雲RAM角色並授予OSS的相關權限。
推薦授予AliyunOSSReadOnlyAccess權限。
- 為上述阿里雲RAM角色添加登錄和Hologres的訪問權限。
- 阿里雲賬號(主賬號)
修改RAM角色的信任策略。重點需更新如下參數:
- Action:更新為sts:AssumeRole。
- Service:更新為hologres.aliyuncs.com。
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"RAM": [
"acs:ram::1866xxxx:root"
],
"Service": [
"hologres.aliyuncs.com"
]
}
}
],
"Version": "1"
}- RAM 用户(子賬號)
● 為RAM用户授權。
a. 在權限管理 > 權限策略頁面,單擊創建權限策略,並選擇腳本編輯模式創建權限策略。具體操作,請參見創建自定義權限策略
Hologres可通過該策略判斷當前RAM用户是否具備創建對應RAM角色的權限。權限策略內容如下。
{
"Version": "1",
"Statement": [
{
"Effect": "Allow",
"Action": "hologram:GrantAssumeRole",
"Resource": "<arn賬號>"
}
]
}b. 在身份管理 > 用户頁面,單擊目標RAM用户操作列中的添加權限,為RAM用户(子賬號)授予上述步驟已創建的權限策略。具體操作,請參見為RAM用户授權。
● 為已創建的RAM角色授權。
修改RAM角色的信任策略。重點需更新如下參數:
- Action:更新為
sts:AssumeRole。 - Service:更新為
hologres.aliyuncs.com。
{
"Statement": [
{
"Action": "sts:AssumeRole",
"Effect": "Allow",
"Principal": {
"RAM": [
"acs:ram::1866xxxx:root"
],
"Service": [
"hologres.aliyuncs.com"
]
}
}
],
"Version": "1"
}- 對PDF文件進行Embedding和Chunk。
需要創建Object Table和Dynamic Table對PDF的元數據讀取以及加工。因為流程較長,Hologres直接將其封裝為存儲過程。該存儲過程包括的能力如下:
- 會創建一張Object Table,用於取PDF的元數據。
- 創建一張增量刷新模式的Dynamic Table結果表,用於存儲加工後的數據。同時,該表需設置向量索引和全文索引,且Dynamic Table不設置自動刷新,需要手動刷新。
- Dynamic Table的刷新過程中會使用
ai_embed、ai_chunk對數據進行Embed和切片。
該存儲過程代碼如下:
CALL create_rag_corpus_from_oss(
oss_path => 'oss://xxxx/bs_challenge_financial_14b_dataset/pdf',
oss_endpoint => 'oss-cn-hangzhou-internal.aliyuncs.com',
oss_role_arn => 'acs:ram::186xxxx:role/xxxx',
corpus_table => 'public.dt_bs_challenge_financial'
);- 刷新結果表。
通過如上存儲過程創建的Object Table和Dynamic Table均需手動刷新,才能完成數據加工。該步驟已被封裝為PDF加工存儲過程,該存儲過程包括的能力如下:
- 刷新一次Object Table獲取PDF元數據
- 刷新一次Dynamic Table,進行PDF的Embedding和Chunk加工。
該存儲過程使用代碼如下:
CALL refresh_rag_corpus_table(
corpus_table => 'public.dt_bs_challenge_financial'
);- PDF檢索。
加工好的數據可以根據業務使用場景,通過向量、全文等方式進行檢索。例如:可以根據招股書來查詢某個公司的業績走勢,以此來判斷公司後續的走勢是悲觀還是樂觀,以便對後續的投資意向提供輔助建議。
向量檢索
在向量檢索時,為了檢索方便,我們將問題Embedding和Prompt構建,大模型輸出答案等過程封裝成為向量檢索函數,直接調用如下該存儲過程可以實現向量召回。
-- 向量單路召回 + AI重排
SELECT qa_vector_search_retrieval(
question => '報告期內,湖南國科微電子股份有限公司2014年度、2015年度、2016年度營業收入和淨利潤分別較上年增長多大幅度?',
corpus_table => 'dt_bs_challenge_financial',
prompt => '請分析如下業績走勢是悲觀還是樂觀,並給出原因:${question}\n\n 參考信息:\n\n ${context}'
)檢索答案如下:
qa_retrieval
---------
"根據提供的信息,對湖南國科微電子股份有限公司的業績走勢進行分析,可以得出以下結論:
### 一、業績走勢分析:悲觀
#### 1. **營業收入增長乏力**
- 2014年度營業收入較上年增長 **15.13%**,但2015年度營業收入卻 **下降5.21%**,2016年度數據未提供,但可以看出營業收入增長趨勢在2015年出現明顯下滑。
- 2012年至2014年營業收入的年複合增長率僅為 **4.47%**,表明公司業務擴張較為緩慢。
#### 2. **淨利潤增長持續下降**
- 2014年度淨利潤增長 **5.43%**,2015年度淨利潤 **下降3.29%**。
- 扣除非經常性損益後,2014年度歸屬於母公司股東的淨利潤增長 **-3.14%**,2015年度進一步下降 **-5.60%**,表明公司主營業務盈利能力在持續惡化。
- 2012年至2014年扣除非經常性損益後淨利潤的年複合增長率為 **-4.38%**,遠低於營業收入增長,説明公司主營業務盈利能力不足,增長主要依賴非經常性損益。
#### 3. **非經常性損益佔比偏高**
- 報告期內,非經常性損益佔淨利潤的比例較高,2014年、2013年、2012年分別為 **17.54%、10.25%、8.06%**,表明公司利潤中有一部分來自政策扶持、政府補貼等非經常性因素,而非核心業務的持續增長。
- 依賴非經常性損益來維持利潤增長,不利於公司長期的穩定發展。
#### 4. **淨資產收益率下降**
- 加權平均淨資產收益率從2014年的 **18.10%** 下降到2015年的 **24.82%**,再到2016年的 **28.23%**,雖然數據看似增長,但需注意該指標是以扣除非經常性損益後的淨利潤計算的,而淨利潤本身在下降,因此這種增長可能與資本結構變化有關,而非盈利能力的實質性提升。
### 二、原因總結
1. **主營業務增長乏力**:營業收入和淨利潤增長均呈現下降趨勢,尤其是淨利潤的下降表明公司盈利能力在減弱。
2. **非經常性損益依賴度高**:公司利潤中非經常性損益佔比較高,説明主營業務的盈利能力不足,公司業績的持續性存疑。
3. **市場競爭激烈**:公司採購的工控機、顯示器、電源等產品市場競爭激烈,價格平穩,利潤空間受到擠壓。
4. **行業環境影響**:不鏽鋼市場價格波動、原材料價格波動可能對公司經營業績造成一定影響,雖然公司已採取措施降低影響,但長期來看仍需關注。
### 三、結論
總體來看,湖南國科微電子股份有限公司的業績走勢偏 **悲觀**。公司主營業務增長乏力,淨利潤持續下降,對非經常性損益依賴度高,未來盈利能力的可持續性存疑。公司需要加強核心業務的競爭力,優化成本結構,提高主營業務盈利能力,以實現長期穩健發展。"全文檢索
在全文檢索時,為了檢索方便,我們將問題Embedding和Prompt構建,大模型輸出答案等過程封裝為全文檢索函數,直接調用如下存儲過程可以實現全文召回:
--全文檢索召回
SELECT qa_text_search_retrieval(
question => '報告期內,湖南國科微電子股份有限公司2014年度、2015年度、2016年度營業收入和淨利潤分別較上年增長多大幅度?',
corpus_table => 'dt_bs_challenge_financial',
prompt => '請分析如下業績走勢是悲觀還是樂觀,並給出原因:${question}\n\n 參考信息:\n\n ${context}'
);檢索答案如下:
qa_text_search_retrieval
----------------
"根據提供的信息,湖南國科微電子股份有限公司在2014年、2015年和2016年的業績走勢整體上呈現**悲觀**趨勢,具體原因如下:
### 1. **營業收入增長乏力**
- 2014年營業收入增長率為**15.13%**,但2015年營業收入增長率轉為**-5.21%**,即出現負增長。
- 2012年至2014年的營業收入年複合增長率僅為**4.47%**,説明公司營業收入增長較為緩慢,業務發展不夠強勁。
- 2015年上半年營業收入預測與2014年同期相比大致持平,但2015年上半年淨利潤較上年同期**略有下降**,表明盈利能力下降。
### 2. **淨利潤和扣非淨利潤增長不佳**
- 2014年淨利潤增長率為**5.43%**,2015年淨利潤增長率下降為**-3.29%**,即淨利潤出現下滑。
- 扣除非經常性損益後的淨利潤增長率在2014年為**-3.14%**,2015年進一步下降為**-5.60%**,説明公司主營業務的盈利能力持續下降。
- 2012年至2014年扣非淨利潤的年複合增長率為**-4.38%**,明顯低於營業收入的年複合增長率,説明公司利潤質量不高,主營業務盈利能力較弱。
### 3. **經營活動現金流波動**
- 2014年銷售商品、提供勞務收到的現金佔營業收入的比例較前兩年有所下降,主要與部分收入確認項目的**收款跨期**有關,説明公司現金流管理存在問題。
- 2013年購買商品、接受勞務支付的現金佔營業成本比例較高,主要是由於當年**採購原材料並完成生產**,但部分成本在2014年才結轉,導致2014年該比例較低,反映公司採購和生產節奏不夠穩定。
### 4. **投資和盈利能力指標**
- 加權平均淨資產收益率(ROE)在2014年為**18.10%**,2015年上升至**24.82%**,2016年進一步上升至**28.23%**,雖然有所提升,但ROE的提高可能主要依賴**財務槓桿**,而非核心業務盈利能力的提升。
- 考慮到淨利潤和扣非淨利潤持續下降,ROE的提升並不能完全反映公司經營質量的改善。
### 5. **2015年上半年業績預測**
- 2015年上半年營業收入預計為**8,505萬元至10,395萬元**,與2014年同期的**10,127.35萬元**大致持平,但淨利潤預計為**2,340萬元至2,860萬元**,低於2014年同期的**2,912.66萬元**,説明公司盈利能力下降。
### 總結
綜合來看,湖南國科微電子股份有限公司在2014年至2016年的業績走勢**偏向悲觀**。雖然ROE有所提升,但營業收入增長乏力、淨利潤和扣非淨利潤持續下降、經營活動現金流波動較大,表明公司主營業務盈利能力較弱,經營質量有待提升。"向量+全文混合檢索
在向量、全文結合Rank排序混合檢索場景中,為了檢索方便,Hologres將其封裝為向量+全文雙路召回+Rank排序函數,該存儲過程的能力如下:
- 根據問題使用向量計算,召回TOP 20的答案。
- 根據問題使用全文檢索,召回TOP 20的答案。
- 使用
ai_rank,對向量和全文召回的答案進行排序,最後輸出Top1的答案。 - 使用
ai_gen,結合大模型根據提示詞以及檢索的答案,生成最終答案並進行輸出。
-- 全文、向量雙路召回 + AI重排
SELECT qa_hybrid_retrieval(
question => '報告期內,湖南國科微電子股份有限公司2014年度、2015年度、2016年度營業收入和淨利潤分別較上年增長多大幅度?',
corpus_table => 'dt_bs_challenge_financial',
prompt => '請分析如下業績走勢是悲觀還是樂觀,並給出原因:${question}\n\n 參考信息:\n\n ${context}'
);檢索答案如下:
qa_hybrid_retrieval
---
"根據提供的信息,我們可以對湖南國科微電子股份有限公司的業績走勢進行如下分析,並判斷其趨勢是悲觀還是樂觀:
---
### 一、**營業收入走勢分析**
1. **2012-2014年複合增長率**:
- 營業收入的年複合增長率為 **4.47%**,表明公司營業收入的增長較為平穩。
- 2014年營業收入為 **18,154.06萬元**,較2013年增長 **15.13%**。
- 2015年營業收入較上年 **下降5.21%**,出現了負增長。
2. **結論**:
- 營業收入的增長在2014年有所回升,但2015年出現明顯下滑,表明公司業務擴張遇到了一定阻力。
---
### 二、**淨利潤走勢分析**
1. **2012-2014年複合增長率**:
- 扣除非經常性損益後的淨利潤年複合增長率為 **-4.38%**,低於營業收入的年複合增長率,説明公司盈利能力有所下降。
- 2014年扣非淨利潤為 **42,731,071.18元**,較2013年下降 **3.14%**。
- 2015年扣非淨利潤較上年進一步下降 **5.60%**。
2. **非經常性損益影響**:
- 2014年、2013年及2012年非經常性損益佔淨利潤的比例分別為 **17.54%、10.25%、8.06%**,呈上升趨勢。
- 非經常性損益的增加主要來自於政府補貼和理財產品收益,而非主營業務帶來的持續增長。
3. **結論**:
- 扣非淨利潤連續兩年下降,説明公司主營業務盈利能力減弱,業績增長依賴於非經常性損益,這是令人擔憂的信號。
---
### 三、**現金流量與經營穩定性**
1. **經營活動現金流**:
- 2014年營業收入為 **18,154.06萬元**,但銷售商品、提供勞務收到的現金並未明確給出,無法判斷現金流是否健康。
- 報告期內,公司銀行存款分別為 **13,063.38萬元、4,152.54萬元、9,864.61萬元**,資金流動性波動較大,但主要客户、供應商及經營模式保持穩定。
2. **結論**:
- 雖然公司現金流存在波動,但客户和供應商穩定,經營模式未發生重大變化,這為公司未來的發展提供了一定保障。
---
### 四、**2015年上半年業績預測**
- 2015年1至6月預計營業收入為 **8,505萬元至10,395萬元**,較2014年同期的 **4,641.19萬元**有明顯增長。
- 但2015年1至3月淨利潤較上年同期下降 **48.26%**,主要是因為確認收入的項目毛利率較低。
---
### 五、**綜合分析與判斷**
1. **樂觀因素**:
- 2014年營業收入增長較快,達到 **15.13%**。
- 2015年上半年營業收入預計增長顯著,表明公司可能正在逐步恢復。
- 主要客户、供應商及經營模式保持穩定,為公司提供了良好的運營基礎。
2. **悲觀因素**:
- 2015年營業收入較上年 **下降5.21%**,淨利潤也出現下滑。
- 扣非淨利潤連續兩年下降,表明公司主營業務盈利能力不足。
- 非經常性損益佔比上升,業績增長依賴於政府補貼和理財產品收益,缺乏內生增長動力。
- 2015年1至3月淨利潤大幅下滑 **48.26%**,表明短期業績波動較大。
---
### **最終結論:整體趨勢偏悲觀**
- 儘管公司在2014年營業收入有所回升,且2015年上半年預計增長,但 **扣非淨利潤連續下降**、**淨利潤增長依賴非經常性損益**、**短期業績波動較大**,表明公司目前的業績增長缺乏持續性和穩定性。
- 因此,從長期來看,公司業績走勢偏 **悲觀**,需關注其主營業務盈利能力的改善和非經常性損益的依賴問題。
---
### **建議**
1. 關注公司未來主營業務的盈利能力是否能有所提升。
2. 降低對非經常性損益的依賴,提高內生增長動力。
3. 穩定客户和供應商關係,優化業務結構,提高毛利率。"向量+全文雙路召回+RRF排序
使用向量和全文檢索後,通過RRF (Reciprocal Rank Fusion)排序召回結果。為了檢索方便,Hologres已經封裝為向量+全文雙路召回+RRF排序函數(詳細定義見下方附錄),該存儲過程的能力如下:
- 根據問題使用向量計算,召回TOP 20的答案。
- 根據問題使用全文檢索,召回TOP 20的答案。
- 對向量和全文召回的答案,計算RRF分數,最後輸出Top N的答案。
- 使用
<font style="color:rgb(24, 24, 24);background-color:rgba(0, 0, 0, 0.04);">ai_gen</font>、大模型根據提示詞,以及檢索的答案,拼裝成最終答案並輸出。
-- 全文、向量雙路召回 + RRF重排
SELECT qa_hybrid_retrieval_rrf(
question => '報告期內,湖南國科微電子股份有限公司2014年度、2015年度、2016年度營業收入和淨利潤分別較上年增長多大幅度?',
corpus_table => 'dt_bs_challenge_financial',
prompt => '請分析如下業績走勢是悲觀還是樂觀,並給出原因:${question}\n\n 參考信息:\n\n ${context}'
);檢索答案如下:
qa_hybrid_retrieval_rrf
------------------
"根據提供的信息,對湖南國科微電子股份有限公司的業績走勢進行分析,可以得出以下結論:
### **業績走勢判斷:悲觀**
#### **原因分析如下:**
1. **淨利潤增長低於營業收入增長:**
- 提供的信息指出,公司2012年至2014年的**營業收入年複合增長率為4.47%**,表明公司整體業務增長較為平穩。
- 但**扣除非經常性損益後歸屬於母公司股東的淨利潤年複合增長率為-4.38%**,明顯低於營業收入的增長率。這説明公司在收入增長的同時,盈利能力並未同步提升,甚至出現下滑,可能受到成本上升、毛利率下降或非經常性損益減少等因素影響。
2. **淨利潤波動較大:**
- 2015年1至3月的淨利潤較上年同期減少了48.26%,且主要原因在於確認收入的項目毛利率較低(如無錫地鐵一號線項目以模塊外購為主)。這表明公司短期業績容易受到業務結構變化的影響,存在一定的不穩定性。
3. **毛利率和盈利能力下降:**
- 提到“主營業務利潤對公司淨利潤的貢獻”在2014年較2013年略有下降,而2013年又較2012年下降。這説明公司核心業務的盈利能力可能在減弱,可能受到市場競爭加劇、成本上升或產品結構變化的影響。
4. **2015年上半年預測利潤下降:**
- 2015年1至6月預計營業收入為8,505萬元至10,395萬元,與2014年同期大致持平,但淨利潤預計為2,340萬元至2,860萬元,低於2014年同期的2,912.66萬元。這表明公司盈利能力在進一步下降,可能面臨一定的經營壓力。
5. **業務增長乏力:**
- 雖然營業收入增長較為平穩,但淨利潤的下降表明公司業務增長的質量不高,未能有效轉化為利潤。這可能影響投資者對公司未來發展的信心。
### **總結:**
湖南國科微電子股份有限公司的業績走勢整體偏向**悲觀**。雖然營業收入保持了平穩增長,但淨利潤的增長明顯滯後甚至出現負增長,表明公司盈利能力在下降,業務發展質量不高,且存在短期業績波動的風險。如果公司不能有效提升毛利率、控制成本或優化產品結構,未來業績可能繼續承壓。"附錄:存儲過程定義
上述文檔中使用的存儲過程定義如下,方便您做參考。
説明在Hologres中不支持創建Function,如下存儲過程僅做參考,無法修改後直接執行。
PDF加工存儲過程
- 創建Object Table和Dynamic Table
CREATE OR REPLACE PROCEDURE create_rag_corpus_from_oss(
oss_path TEXT,
oss_endpoint TEXT,
oss_role_arn TEXT,
corpus_table TEXT,
embedding_model TEXT DEFAULT NULL,
parse_document_model TEXT DEFAULT NULL,
chunk_model TEXT DEFAULT NULL,
chunk_size INT DEFAULT 300,
chunk_overlap INT DEFAULT 50,
overwrite BOOLEAN DEFAULT FALSE
)
AS $$
DECLARE
corpus_schema TEXT;
corpus_name TEXT;
obj_table_name TEXT;
full_corpus_ident TEXT;
full_obj_ident TEXT;
embed_expr TEXT;
chunk_expr TEXT;
parse_expr TEXT;
embedding_dims INT;
BEGIN
-- 1. 拆 schema name + table name
IF position('.' in corpus_table) > 0 THEN
corpus_schema := split_part(corpus_table, '.', 1);
corpus_name := split_part(corpus_table, '.', 2);
ELSE
corpus_schema := 'public';
corpus_name := corpus_table;
END IF;
obj_table_name := corpus_name || '_obj_table';
full_corpus_ident := format('%I.%I', corpus_schema, corpus_name);
full_obj_ident := format('%I.%I', corpus_schema, obj_table_name);
-- 2. 如果需要覆蓋,先刪表和索引
IF overwrite THEN
DECLARE
dyn_table_exists BOOLEAN;
rec RECORD;
BEGIN
-- 檢查 dynamic table 是否存在
SELECT EXISTS (
SELECT 1
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relname = corpus_name
AND n.nspname = corpus_schema
)
INTO dyn_table_exists;
IF dyn_table_exists THEN
-- 2.1 關閉動態表自動刷新
-- RAISE NOTICE 'Disabling auto refresh for %', full_corpus_ident;
-- EXECUTE format('ALTER TABLE IF EXISTS %s SET (auto_refresh_enable=false)', full_corpus_ident);
-- 2.2 查找 RUNNING 刷新任務並取消
FOR rec IN
EXECUTE format(
$f$
SELECT query_job_id
FROM hologres.hg_dynamic_table_refresh_log(%L)
WHERE status = 'RUNNING';
$f$,
corpus_table
)
LOOP
RAISE NOTICE 'Found running refresh job: %', rec.query_job_id;
IF hologres.hg_internal_cancel_query_job(rec.query_job_id::bigint) THEN
RAISE NOTICE 'Cancel job % succeeded.', rec.query_job_id;
ELSE
RAISE WARNING 'Cancel job % failed.', rec.query_job_id;
END IF;
END LOOP;
-- 2.3 刪除 Dynamic Table
EXECUTE format('DROP TABLE IF EXISTS %s;', full_corpus_ident);
ELSE
RAISE NOTICE 'Dynamic table % does not exist, skip cancel job and drop.', full_corpus_ident;
END IF;
-- 2.4 無論如何,Object Table 都要刪除
EXECUTE format('DROP OBJECT TABLE IF EXISTS %s;', full_obj_ident);
END;
END IF;
-- 3. 創建 Object Table
RAISE NOTICE 'Create object table: %', obj_table_name;
EXECUTE format(
$f$
CREATE OBJECT TABLE %s
WITH (
path = %L,
oss_endpoint = %L,
role_arn = %L
);
$f$,
full_obj_ident,
oss_path,
oss_endpoint,
oss_role_arn
);
COMMIT;
-- 4. 刷新 Object Table
RAISE NOTICE 'Refresh object table: %', obj_table_name;
EXECUTE format('REFRESH OBJECT TABLE %s;', full_obj_ident);
COMMIT;
-- 5. 文檔解析模型選擇
IF parse_document_model IS NULL OR length(trim(parse_document_model)) = 0 THEN
parse_expr := 'ai_parse_document(file, ''auto'', ''markdown'')';
ELSE
parse_expr := format(
'ai_parse_document(%L, file, ''auto'', ''markdown'')',
parse_document_model
);
END IF;
-- 6. chunk 模型選擇
IF chunk_model IS NULL OR length(trim(chunk_model)) = 0 THEN
chunk_expr := format('ai_chunk(doc, %s, %s)', chunk_size, chunk_overlap);
ELSE
chunk_expr := format(
'ai_chunk(%L, doc, %s, %s)',
chunk_model,
chunk_size,
chunk_overlap
);
END IF;
-- 7. embedding 模型選擇
IF embedding_model IS NULL OR length(trim(embedding_model)) = 0 THEN
embed_expr := 'ai_embed(chunk)';
EXECUTE 'SELECT array_length(ai_embed(''dummy''), 1)'
INTO embedding_dims;
ELSE
embed_expr := format('ai_embed(%L, chunk)', embedding_model);
EXECUTE format(
'SELECT array_length(ai_embed(%L, ''dummy''), 1)',
embedding_model
)
INTO embedding_dims;
END IF;
RAISE NOTICE 'embedding dimension is: %', embedding_dims;
-- 8. 創建 RAG 輸出動態表
RAISE NOTICE 'create dynamic table: %', corpus_name;
EXECUTE format(
$f$
CREATE DYNAMIC TABLE %s(
CHECK(array_ndims(embedding_vector) = 1 AND array_length(embedding_vector, 1) = %s)
)
WITH (
vectors = '{
"embedding_vector": {
"algorithm": "HGraph",
"distance_method": "Cosine",
"builder_params": {
"base_quantization_type": "sq8_uniform",
"max_degree": 64,
"ef_construction": 400,
"precise_quantization_type": "fp32",
"use_reorder": true
}
}
}',
auto_refresh_mode = 'incremental',
freshness = '5 minutes',
auto_refresh_enable = 'false'
) AS
WITH parsed_doc AS (
SELECT object_uri,
etag,
%s AS doc
FROM %s
),
chunked_doc AS (
SELECT object_uri,
etag,
unnest(%s) AS chunk
FROM parsed_doc
)
SELECT
object_uri,
etag,
chunk,
%s AS embedding_vector
FROM chunked_doc;
$f$,
full_corpus_ident,
embedding_dims,
parse_expr,
full_obj_ident,
chunk_expr,
embed_expr
);
COMMIT;
-- 9. 創建全文索引(索引名 = 表名 || '_fulltext_idx')
EXECUTE format(
'CREATE INDEX %I ON %s USING FULLTEXT (chunk);',
corpus_name || '_fulltext_idx',
full_corpus_ident
);
RAISE NOTICE '';
RAISE NOTICE 'Create RAG corpus success to table: %', corpus_table;
RAISE NOTICE ' Vector index is: %.embedding_vector', corpus_table;
RAISE NOTICE ' TextSearch index is: %.chunk', corpus_table;
END;
$$ LANGUAGE plpgsql;- 刷新Object Table和Dynamic Table存儲過程
CREATE OR REPLACE PROCEDURE refresh_rag_corpus_table(
corpus_table TEXT
)
AS $$
DECLARE
corpus_schema TEXT;
corpus_name TEXT;
obj_table_name TEXT;
full_corpus_ident TEXT;
full_obj_ident TEXT;
BEGIN
-- 1. 解析 schema 和表名
IF position('.' in corpus_table) > 0 THEN
corpus_schema := split_part(corpus_table, '.', 1);
corpus_name := split_part(corpus_table, '.', 2);
ELSE
corpus_schema := 'public';
corpus_name := corpus_table;
END IF;
obj_table_name := corpus_name || '_obj_table';
full_corpus_ident := format('%I.%I', corpus_schema, corpus_name);
full_obj_ident := format('%I.%I', corpus_schema, obj_table_name);
-- 2. 刷新 Object Table
RAISE NOTICE 'Refreshing Object Table: %', obj_table_name;
EXECUTE format('REFRESH OBJECT TABLE %s;', full_obj_ident);
-- 3. 刷新 Dynamic Table
RAISE NOTICE 'Refreshing Dynamic Table: %', corpus_name;
EXECUTE format('REFRESH TABLE %s;', full_corpus_ident);
RAISE NOTICE 'Refresh complete for corpus table %', corpus_table;
END;
$$ LANGUAGE plpgsql;- 刪除Object Table和Dynamic Table存儲過程
CREATE OR REPLACE PROCEDURE drop_rag_corpus_table(
corpus_table TEXT
)
AS $$
DECLARE
corpus_schema TEXT;
corpus_name TEXT;
obj_table_name TEXT;
full_corpus_ident TEXT;
full_obj_ident TEXT;
rec RECORD;
BEGIN
-- 1. 解析 schema 和表名
IF position('.' in corpus_table) > 0 THEN
corpus_schema := split_part(corpus_table, '.', 1);
corpus_name := split_part(corpus_table, '.', 2);
ELSE
corpus_schema := 'public';
corpus_name := corpus_table;
END IF;
obj_table_name := corpus_name || '_obj_table';
full_corpus_ident := format('%I.%I', corpus_schema, corpus_name);
full_obj_ident := format('%I.%I', corpus_schema, obj_table_name);
-- 2. 刪除表
-- 2.1 關閉動態表自動刷新
-- RAISE NOTICE 'Disabling auto refresh for %', full_corpus_ident;
-- EXECUTE format('ALTER TABLE IF EXISTS %s SET (auto_refresh_enable=false)', full_corpus_ident);
-- 2.2 查找 RUNNING 刷新任務並取消
FOR rec IN
EXECUTE format(
$f$
SELECT query_job_id
FROM hologres.hg_dynamic_table_refresh_log(%L)
WHERE status = 'RUNNING';
$f$,
corpus_table
)
LOOP
RAISE NOTICE 'Found running refresh job: %', rec.query_job_id;
IF hologres.hg_internal_cancel_query_job(rec.query_job_id::bigint) THEN
RAISE NOTICE 'Cancel job % succeeded.', rec.query_job_id;
ELSE
RAISE WARNING 'Cancel job % failed.', rec.query_job_id;
END IF;
END LOOP;
-- 2.3 刪除 Dynamic Table
RAISE NOTICE 'Dropping Dynamic Table: %', corpus_name;
EXECUTE format('DROP TABLE IF EXISTS %s;', full_corpus_ident);
-- 2.4 刪除 Object Table
RAISE NOTICE 'Dropping Object Table: %', obj_table_name;
EXECUTE format('DROP OBJECT TABLE IF EXISTS %s;', full_obj_ident);
RAISE NOTICE 'Drop complete for corpus: %', corpus_table;
END;
$$ LANGUAGE plpgsql;向量檢索函數
-- RAG向量單路召回問答
CREATE OR REPLACE FUNCTION qa_vector_search_retrieval(
question TEXT,
corpus_table TEXT,
embedding_model TEXT DEFAULT NULL,
llm_model TEXT DEFAULT NULL,
ranking_model TEXT DEFAULT NULL,
prompt TEXT DEFAULT 'Please answer the following question in ${language} based on the reference information.\n\n Question: ${question}\n\n Reference information:\n\n ${context}',
language TEXT DEFAULT 'Chinese',
vector_recall_count INT DEFAULT 20,
rerank_recall_count INT DEFAULT 5,
vector_col TEXT DEFAULT 'embedding_vector'
)
RETURNS TEXT AS
$$
DECLARE
final_answer TEXT;
sql TEXT;
embedding_expr TEXT;
ai_rank_expr TEXT;
ai_gen_expr TEXT;
embedding_model_valid BOOLEAN;
llm_model_valid BOOLEAN;
ranking_model_valid BOOLEAN;
BEGIN
embedding_model_valid := (embedding_model IS NOT NULL AND trim(embedding_model) != '');
llm_model_valid := (llm_model IS NOT NULL AND trim(llm_model) != '');
ranking_model_valid := (ranking_model IS NOT NULL AND trim(ranking_model) != '');
IF embedding_model_valid THEN
embedding_expr := 'ai_embed(' || quote_literal(embedding_model) || ', ' || quote_literal(question) || ')';
ELSE
embedding_expr := 'ai_embed(' || quote_literal(question) || ')';
END IF;
IF ranking_model_valid THEN
ai_rank_expr := 'ai_rank(' || quote_literal(ranking_model) || ', ' || quote_literal(question) || ', chunk)';
ELSE
ai_rank_expr := 'ai_rank(' || quote_literal(question) || ', chunk)';
END IF;
IF llm_model_valid THEN
ai_gen_expr := 'ai_gen(' || quote_literal(llm_model) ||
', replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) || '), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || ') )';
ELSE
ai_gen_expr := 'ai_gen(replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) || '), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || '))';
END IF;
sql := '
WITH
embedding_recall AS (
SELECT
chunk,
approx_cosine_distance(' || vector_col || ', ' || embedding_expr || ') AS distance
FROM
' || corpus_table || '
ORDER BY
distance DESC
LIMIT ' || vector_recall_count || '
),
rerank AS (
SELECT
chunk,
' || ai_rank_expr || ' AS score
FROM
embedding_recall
ORDER BY
score DESC
LIMIT ' || rerank_recall_count || '
),
concat_top_chunks AS (
SELECT string_agg(chunk, E''\n\n----\n\n'') AS merged_chunks FROM rerank
)
SELECT ' || ai_gen_expr || '
FROM concat_top_chunks;
';
EXECUTE sql INTO final_answer;
RETURN final_answer;
END;
$$ LANGUAGE plpgsql;全文檢索函數
CREATE OR REPLACE FUNCTION qa_text_search_retrieval(
question TEXT,
corpus_table TEXT,
llm_model TEXT DEFAULT NULL,
ranking_model TEXT DEFAULT NULL,
prompt TEXT DEFAULT 'Please answer the following question in ${language} based on the reference information.\n\n Question: ${question}\n\n Reference information:\n\n ${context}',
language TEXT DEFAULT 'Chinese',
text_search_recall_count INT DEFAULT 20,
rerank_recall_count INT DEFAULT 5,
text_search_col TEXT DEFAULT 'chunk'
)
RETURNS TEXT AS
$$
DECLARE
final_answer TEXT;
sql TEXT;
ai_rank_expr TEXT;
ai_gen_expr TEXT;
llm_model_valid BOOLEAN;
ranking_model_valid BOOLEAN;
BEGIN
llm_model_valid := (llm_model IS NOT NULL AND trim(llm_model) != '');
ranking_model_valid := (ranking_model IS NOT NULL AND trim(ranking_model) != '');
IF ranking_model_valid THEN
ai_rank_expr := 'ai_rank(' || quote_literal(ranking_model) || ', ' || quote_literal(question) || ', chunk)';
ELSE
ai_rank_expr := 'ai_rank(' || quote_literal(question) || ', chunk)';
END IF;
IF llm_model_valid THEN
ai_gen_expr := 'ai_gen(' || quote_literal(llm_model) ||
', replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) ||
'), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || ') )';
ELSE
ai_gen_expr := 'ai_gen(replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) ||
'), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || '))';
END IF;
sql := '
WITH
text_search_recall AS (
SELECT
chunk
FROM
' || corpus_table || '
ORDER BY
text_search(' || text_search_col || ', ' || quote_literal(question) || ') DESC
LIMIT ' || text_search_recall_count || '
),
rerank AS (
SELECT
chunk,
' || ai_rank_expr || ' AS score
FROM
text_search_recall
ORDER BY
score DESC
LIMIT ' || rerank_recall_count || '
),
concat_top_chunks AS (
SELECT string_agg(chunk, E''\n\n----\n\n'') AS merged_chunks FROM rerank
)
SELECT ' || ai_gen_expr || '
FROM concat_top_chunks;
';
EXECUTE sql INTO final_answer;
RETURN final_answer;
END;
$$ LANGUAGE plpgsql;向量+全文雙路召回+Rank排序函數
CREATE OR REPLACE FUNCTION qa_hybrid_retrieval(
question TEXT,
corpus_table TEXT,
embedding_model TEXT DEFAULT NULL,
llm_model TEXT DEFAULT NULL,
ranking_model TEXT DEFAULT NULL,
prompt TEXT DEFAULT 'Please answer the following question in ${language} based on the reference information.\n\n Question: ${question}\n\n Reference information:\n\n ${context}',
language TEXT DEFAULT 'Chinese',
text_search_recall_count INT DEFAULT 20,
vector_recall_count INT DEFAULT 20,
rerank_recall_count INT DEFAULT 5,
vector_col TEXT DEFAULT 'embedding_vector',
text_search_col TEXT DEFAULT 'chunk'
)
RETURNS TEXT AS
$$
DECLARE
final_answer TEXT;
sql TEXT;
embedding_expr TEXT;
ai_rank_expr TEXT;
ai_gen_expr TEXT;
embedding_model_valid BOOLEAN;
llm_model_valid BOOLEAN;
ranking_model_valid BOOLEAN;
BEGIN
embedding_model_valid := (embedding_model IS NOT NULL AND trim(embedding_model) != '');
llm_model_valid := (llm_model IS NOT NULL AND trim(llm_model) != '');
ranking_model_valid := (ranking_model IS NOT NULL AND trim(ranking_model) != '');
IF embedding_model_valid THEN
embedding_expr := 'ai_embed(' || quote_literal(embedding_model) || ', ' || quote_literal(question) || ')';
ELSE
embedding_expr := 'ai_embed(' || quote_literal(question) || ')';
END IF;
IF ranking_model_valid THEN
ai_rank_expr := 'ai_rank(' || quote_literal(ranking_model) || ', ' || quote_literal(question) || ', chunk)';
ELSE
ai_rank_expr := 'ai_rank(' || quote_literal(question) || ', chunk)';
END IF;
IF llm_model_valid THEN
ai_gen_expr := 'ai_gen(' || quote_literal(llm_model) ||
', replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) || '), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || ') )';
ELSE
ai_gen_expr := 'ai_gen(replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) || '), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || '))';
END IF;
sql := '
WITH
embedding_recall AS (
SELECT
chunk
FROM
' || corpus_table || '
ORDER BY
approx_cosine_distance(' || vector_col || ', ' || embedding_expr || ') DESC
LIMIT ' || vector_recall_count || '
),
text_search_recall AS (
SELECT
chunk
FROM
' || corpus_table || '
ORDER BY
text_search(' || text_search_col || ', ' || quote_literal(question) || ') DESC
LIMIT ' || text_search_recall_count || '
),
union_recall AS (
SELECT chunk FROM embedding_recall
UNION
SELECT chunk FROM text_search_recall
),
rerank AS (
SELECT
chunk,
' || ai_rank_expr || ' AS score
FROM
union_recall
ORDER BY
score DESC
LIMIT ' || rerank_recall_count || '
),
concat_top_chunks AS (
SELECT string_agg(chunk, E''\n\n----\n\n'') AS merged_chunks FROM rerank
)
SELECT ' || ai_gen_expr || '
FROM concat_top_chunks;
';
EXECUTE sql INTO final_answer;
RETURN final_answer;
END;
$$ LANGUAGE plpgsql;向量+全文雙路召回+RRF排序函數
CREATE OR REPLACE FUNCTION qa_hybrid_retrieval_rrf(
question TEXT,
corpus_table TEXT,
embedding_model TEXT DEFAULT NULL,
llm_model TEXT DEFAULT NULL,
ranking_model TEXT DEFAULT NULL,
prompt TEXT DEFAULT 'Please answer the following question in ${language} based on the reference information.\n\n Question: ${question}\n\n Reference information:\n\n ${context}',
language TEXT DEFAULT 'Chinese',
text_search_recall_count INT DEFAULT 20,
vector_recall_count INT DEFAULT 20,
rerank_recall_count INT DEFAULT 5,
rrf_k INT DEFAULT 60,
vector_col TEXT DEFAULT 'embedding_vector',
text_search_col TEXT DEFAULT 'chunk'
)
RETURNS TEXT AS
$$
DECLARE
final_answer TEXT;
sql TEXT;
embedding_expr TEXT;
ai_rank_expr TEXT;
ai_gen_expr TEXT;
embedding_model_valid BOOLEAN;
llm_model_valid BOOLEAN;
ranking_model_valid BOOLEAN;
BEGIN
embedding_model_valid := (embedding_model IS NOT NULL AND trim(embedding_model) <> '');
llm_model_valid := (llm_model IS NOT NULL AND trim(llm_model) <> '');
ranking_model_valid := (ranking_model IS NOT NULL AND trim(ranking_model) <> '');
IF embedding_model_valid THEN
embedding_expr := 'ai_embed(' || quote_literal(embedding_model) || ', ' || quote_literal(question) || ')';
ELSE
embedding_expr := 'ai_embed(' || quote_literal(question) || ')';
END IF;
IF ranking_model_valid THEN
ai_rank_expr := 'ai_rank(' || quote_literal(ranking_model) || ', ' || quote_literal(question) || ', chunk)';
ELSE
ai_rank_expr := 'ai_rank(' || quote_literal(question) || ', chunk)';
END IF;
IF llm_model_valid THEN
ai_gen_expr := 'ai_gen(' || quote_literal(llm_model) ||
', replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) || '), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || ') )';
ELSE
ai_gen_expr := 'ai_gen(replace(replace(replace(' || quote_literal(prompt) ||
', ''${question}'', ' || quote_literal(question) || '), ''${context}'', merged_chunks), ''${language}'', ' || quote_literal(language) || '))';
END IF;
sql := '
WITH embedding_recall AS (
SELECT
chunk,
vec_score,
ROW_NUMBER() OVER (ORDER BY vec_score DESC) AS rank_vec
FROM (
SELECT
chunk,
approx_cosine_distance(' || vector_col || ', ' || embedding_expr || ') AS vec_score
FROM
' || corpus_table || '
) t
ORDER BY vec_score DESC
LIMIT ' || vector_recall_count || '
),
text_search_recall AS (
SELECT
chunk,
text_score,
ROW_NUMBER() OVER (ORDER BY text_score DESC) AS rank_text
FROM (
SELECT
chunk,
text_search(' || text_search_col || ', ' || quote_literal(question) || ') AS text_score
FROM
' || corpus_table || '
) ts
WHERE text_score > 0
ORDER BY text_score DESC
LIMIT ' || text_search_recall_count || '
),
rrf_scores AS (
SELECT
chunk,
SUM(1.0 / (' || rrf_k || ' + rank_val)) AS rrf_score
FROM (
SELECT chunk, rank_vec AS rank_val FROM embedding_recall
UNION ALL
SELECT chunk, rank_text AS rank_val FROM text_search_recall
) sub
GROUP BY chunk
),
top_chunks AS (
SELECT chunk
FROM rrf_scores
ORDER BY rrf_score DESC
LIMIT ' || rerank_recall_count || '
),
concat_top_chunks AS (
SELECT string_agg(chunk, E''\n\n----\n\n'') AS merged_chunks FROM top_chunks
)
SELECT ' || ai_gen_expr || '
FROM concat_top_chunks;
';
EXECUTE sql INTO final_answer;
RETURN final_answer;
END;
$$ LANGUAGE plpgsql;如果想體驗更多操作流程,歡迎到阿里雲官網領取Hologres免費試用,開通Hologres4.0,並按照操作文檔實踐。
https://help.aliyun.com/zh/hologres/user-guide/best-practices-financial-multimodal-ai-data-analysis-and-retrieval-system