

前言
大語言模型Agent在複雜任務中展現出卓越能力。相比傳統線性推理鏈(Chain-of-Thought),“交錯思維”(Interleaved Thinking)通過"思考→行動→觀察→再思考"的閉環機制,有效解決了狀態漂移和上下文遺忘問題,顯著提升多輪交互的連貫性與策略調整能力。
阿里雲 PAI 團隊結合交錯思維的推理機制,構建了涵蓋多輪交互的訓練數據集,訓練更符合交錯思維特性的輕量級 Agent 模型,有效提升性能與響應效率。本文將在 EasyDistill(https://github.com/modelscope/easydistill)開源框架下,系統闡述面向 Interleaved Thinking 的大模型 Agent 蒸餾實踐,涵蓋數據集構建和蒸餾算法的開發,並結合實際應用案例,全面展示該技術在智能體模型訓練中的潛力與優勢。
面向Interleaved Thinking的蒸餾方法
在本節中,我們首先回顧 Interleaved Thinking 的基礎範式 ReAct,其次詳細介紹面向 Interleaved Thinking 的大模型蒸餾方法,最後對蒸餾模型在 Agent 評測任務上的實際效果進行評測。
ReAct範式回眸
我們首先簡要回顧 Interleaved Thinking 的基礎推理範式 ReAct。ReAct(Reasoning and Acting)由普林斯頓大學與谷歌研究團隊提出,作為一種交互式推理框架,旨在解決傳統大語言模型在複雜多輪推理任務中遇到的固有瓶頸與效率問題。傳統的 Chain-of-Thought(CoT)推理方法通常採用線性、單向的處理流程,即模型先生成完整的推理鏈條,隨後統一執行行動步驟。這種“先思考後行動”的順序方法,在面對動態變化、環境不確定或需要多工具交互的任務時,容易導致上下文信息丟失、狀態漂移和響應延遲,顯著制約了模型的實用性和魯棒性。
ReAct 範式的核心理念是將推理(Reasoning)與行動(Acting)緊密動態交織,通過“思考→行動→觀察→再思考”的閉環交互,構建一個實時反饋驅動的推理體系。在實際運行中,模型在每一步不僅生成推理文本,還會決定是否調用外部工具(如數據庫查詢、API 調用、代碼執行等),並根據工具反饋的結果即時調整推理策略與推理狀態。這樣,模型能夠持續更新工作記憶中的環境狀態和推理上下文,有效避免在多輪複雜推理與工具調用過程中出現的意圖偏離和信息遺忘,確保推理的連貫性與動作執行的準確性。
技術上,ReAct 框架設計了一套交叉迭代的執行機制,具體流程包括:模型基於當前上下文進行推理,生成下一步的行動指令;系統執行對應工具調用並返回結果;模型根據返回信息更新推理狀態,進行下一輪思考和決策。該機制不僅提升了模型對環境的響應敏捷性,也支持條件路徑分支和自我糾正能力,使 Agent 能應對高度動態和不確定的任務環境。ReAct 與其他基礎範式的對比如下所示:

(上圖源自ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023)
教師軌跡數據生成
教師軌跡數據的質量直接決定了學生模型推理能力的上限和訓練效果的穩定性,因此,高質量軌跡數據的生成是多步推理與工具調用能力訓練的關鍵基礎環節。我們可以選用任何具備足夠能力的大語言模型作為教師(Teacher),如 Qwen3-Max 等,藉助其強大的理解與推理能力,生成高質量的任務執行軌跡。生成的軌跡需符合 ReAct 範式。以求解數學題為例,我們採用 Python 代碼解釋器作為工具,生成的軌跡數據採用標準的三元組結構 [Thought, Code, Observation],具體對應如下:
- Thought(思考):教師模型以自然語言對問題進行分析和推理,描述拆解思路、邏輯判斷和決策依據;
- Code(代碼):緊接思考後的工具調用指令,通常為 Python 代碼,直接執行具體操作或計算,確保每步推理均具有可執行性與明確、可驗證的輸出;
- Observation(觀察):代碼執行後的環境反饋,包含具體結果和狀態信息,為後續推理步驟提供實時上下文支持。
這一設計充分模擬了人類在解決複雜問題時“思考→行動→觀察→再思考”的思維閉環,保障了推理流程的透明性和過程的可復現性。
以下是一個典型的軌跡示例,展示教師模型如何根據題意動態拆解問題、生成工具調用代碼,並根據代碼執行的反饋調整後續步驟:
|
Question
|
In how many ways can 6 girls and 2 boys sit in a row if the 2 boys sit next to each other?
|
|
Thought 1 (Teacher)
|
First, I need to treat the 2 boys as a single unit, which means I have 7 units to arrange. I will calculate the number of ways.
|
|
Code 1 (Teacher)
|
import math
ways_wo_boys_together = math.factorial(7)
print(ways_wo_boys_together )
|
|
Observation 1
|
5040
|
|
Thought 2 (Teacher)
|
The boys can switch places within their unit, I will multiply it by 2.
|
|
Code 2 (Teacher)
|
ways = ways_wo_boys_together * 2
print(ways)
|
|
Observation 2
|
10080
|
|
Thought 3 (Teacher)
|
I will provide the true answer.
|
|
Code 3 (Teacher)
|
print(“There are 10080 ways.”)
|
通過構建自動化的數據生成流水線,並結合分佈式高性能計算資源,我們能夠高效產出大規模、多樣化的教師軌跡數據集。整個流程包括任務指令發起、教師模型推理執行、代碼運行環境反饋採集以及軌跡結果的驗證與篩選等步驟,形成閉環,從而保證數據生成的穩定性與可擴展性。
行為克隆訓練
通過模仿教師模型的推理與執行軌跡,行為克隆訓練使學生模型逐步學會如何將複雜問題拆解為有序的步驟,並能夠基於上下文生成合理的推理思路和可執行代碼,從而實現對任務的基本掌控。行為克隆訓練採用標準的監督學習框架,其目標是最大化學生模型在訓練軌跡數據上生成教師動作的概率。在訓練過程中,每個時間步

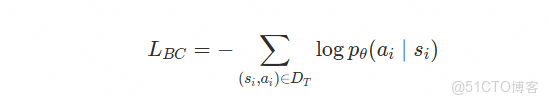
其中,


經過行為克隆階段的訓練,學生模型表現出以下能力提升:
- 多步邏輯拆解能力:模型能夠基於問題描述合理分解步驟,以符合邏輯的自然語言思維指導問題求解;
- 準確代碼生成:學生模型生成的代碼在語法和功能上表現明顯提升,確保行動步驟可執行且輸出結果有效;
- 動態反饋適應:模型能夠有效利用環境反饋調整推理狀態,展現了一定程度的閉環推理能力。
該階段的訓練顯著降低了後續訓練的難度和複雜度。
教師糾錯訓練
在完成行為克隆訓練後,學生模型已經具備了基本的多步推理與工具調用能力,但在面對未見任務場景時,仍然可能出現推理漏洞或執行錯誤。為了促進學生模型能力的動態自適應提升,本階段旨在讓學生模型在全新任務中主動進行“思考-執行-觀察”的閉環推理,自主嘗試解決問題,並結合教師模型的針對性糾錯輔導,實現能力的精準匹配與持續優化。
具體而言,在任務環境中,學生模型接收問題輸入後,按照 ReAct 範式生成一系列軌跡步驟,每一步均包含自然語言推理(Thought)、對應代碼執行(Code)及環境反饋(Observation)。通過讓學生模型真實地“自己動手”解題,主動與環境交互生成完整的推理軌跡,我們大大減少了傳統行為克隆中由於“模仿分佈漂移”帶來的訓練偏差,使訓練數據更加貼近真實推理行為。
例如,針對題目“6個女孩和2個男孩排成一排,要求2個男孩相鄰,有多少種排法?”,學生模型的思考和執行可能出現如下情況:
|
Question
|
In how many ways can 6 girls and 2 boys sit in a row if the 2 boys sit next to each other?
|
|
Thought 1 (Student)
|
First, I need to treat the 2 boys as a single unit, which means I have 7 units to arrange. I will calculate the number of ways.
|
|
Code 1 (Student)
|
import math
ways_wo_boys_together = math.factorial(7)
print(ways_wo_boys_together )
|
|
Observation 1
|
5040
|
|
Thought 2 (Student)
|
The boys are a single unit, the ways equal to ways_wo_boys_together
|
|
Code 2 (Student)
|
ways = ways_wo_boys_together
print(ways)
|
|
Observation 2
|
5040
|
此處,學生模型在第二步未考慮男孩內部位置的交換,導致結果出現偏差。我們可以採用經過教師糾錯和修正的完整軌跡,作為更貼合學生當前能力的訓練樣本。這樣,模型既能學習關鍵錯誤的更正過程,又能避免在純模仿訓練中因錯誤軌跡未加控制而導致的誤差快速累計與指數級擴散。技術實現上,本階段訓練時,模型以初始行為克隆階段的權重為基礎,利用教師修正後的軌跡作為訓練輸入,並沿用第一階段的交叉熵監督損失。此舉能夠有效引導模型糾正其局部錯誤,持續提升推理與工具調用的準確性與魯棒性。
實驗效果評測
為驗證面向 Interleaved Thinking 的蒸餾方法在真實 Agent 任務中的優勢,我們在多類 Agent 基準任務上對蒸餾模型進行了評測與對比。具體包括以下任務和評測基準:
- 數學推理(需頻繁調用 Python 工具):AIME2024、AIME2025、MATH500、OlymMath
- 指標:判斷最終答案的正確性
- 事實 / 多跳問答(需搜索工具):HotpotQA、2WikiMultihopQA、MuSiQ、Bamboogle
- 指標:token-level F1
- Deep Search:GAIA、WebWalker、HLE、xBench
- 指標:使用 LLM-as-a-judge 判定正確性
在工具設置上,數學推理問題採用 Python 解釋器,事實問答任務則使用在線搜索 API snippet(不包含瀏覽器功能),以降低工具調用成本和時延。
實驗結果表明,面向 Interleaved Thinking 的蒸餾框架能夠顯著提升小模型在多步推理與工具調用任務中的穩定性和成功率。具體而言,經過上述模型蒸餾訓練,在數學推理和事實 / 多跳問答任務上,7B 模型的效果已超過 32B 模型,並接近 72B 模型的表現;在 Deep Search 任務上,8B 模型的結果也與 72B 模型接近。


EasyDistill應用實踐
在 EasyDistill 開源框架中,我們支持了上文提到的面向 Interleaved Thinking 的大模型Agent蒸餾訓練。在此,我們給出具體的應用實踐示例。
項目主體框架
EasyDistill 的 Agent 蒸餾模塊主要基於 langgraph 框架,用於 Agent 推理軌跡生成,以及基於該軌跡的小型 Agent 模型蒸餾訓練,其項目主體框架如下所示:
.
├── configs/
│ └── agentkd_local.json # 主配置文件
├── data/
│ └── agent_demo.jsonl # 原始數據源
│ └── agent_demo_labeled.jsonl # 生成的推理軌跡
├── easydistill/agentkd
│ └── infer.py # agent推理軌跡生成
│ └── train.py # 蒸餾訓練腳本實踐應用示例
1、首先,我們進行數據準備工作。數據集格式支持.jsonl,我們已經在 data/agent_demo.jsonl 中提供了示例數據。每條數據格式如下:
{
"id": 0,
"question": "TLDR",
"solution": "TLDR",
"true_answer": "TLDR"
}2、接着,我們配置訓練所需參數,configs/agentkd_local.json 包含了生成 Agent 軌跡和蒸餾訓練所需的全部參數配置信息,如下所示:
{
"job_type": "agentkd_local",
"dataset": {
"instruction_path": "data/agent_demo.jsonl",
"labeled_path_raw": "data/agent_demo_labeled_raw.jsonl",
"labeled_path": "data/agent_demo_labeled.json"
},
"models": {
"teacher": "Qwen/Qwen2.5-72B-Instruct",
"student": "Qwen/Qwen2.5-7B-Instruct"
},
"inference":{
...
},
"training": {
...
}
}3、使用 命令一鍵生成Agent軌跡數據和拉起訓練任務
easydistill --config configs/agentkd_local.json該命令會基於源數據 data/agent_demo.jsonl 生成 原始Agent 推理軌跡,並將其進行格式轉換,最終生成直接可用於訓練的軌跡數據(實際使用中可根據需要調整推理參數),即 data/agent_demo_labeled.json,示例數據格式如下:
[
{
"conversations": [
{
"from": "human",
"value": "A pool has 48 blue tiles and 32 red tiles. If the pool needs 100 tiles to be completed, how many more tiles are needed?"
},
{
"from": "gpt",
"value": "<first_thought>Calculate the total number of tiles currently in the pool, then subtract this number from the total number of tiles needed to find out how many more tiles are required.</first_thought>"
},
{
"from": "human",
"value": "Observation: None"
},
{
"from": "gpt",
"value": "<thought>I need to calculate the total number of tiles currently in the pool and then find out how many more tiles are needed to reach 100 tiles.</thought><code># Calculate the total number of tiles currently in the pool\nblue_tiles = 48\nred_tiles = 32\ntotal_tiles_current = blue_tiles + red_tiles\n\n# Calculate how many more tiles are needed\ntiles_needed = 100 - total_tiles_current\nprint(tiles_needed)</code>"
},
{
"from": "human",
"value": "Observation: 20"
},
{
"from": "gpt",
"value": "<thought>I have already calculated the number of tiles needed to complete the pool, which is 20. Now, I need to format this number as a final answer in LaTeX format.</thought><code>final_answer_print(r\"\boxed{20}\")</code>"
}
]
}
]基於生成的 Agent 推理軌跡(data/agent_demo_labeled.json),該命令將自動進行最終的蒸餾訓練。同樣地,在實際使用中可根據需要修改 configs/agentkd_local.json 中的訓練參數。
本文小結
本文圍繞面向 Interleaved Thinking 的大模型 Agent 蒸餾,系統介紹了基於動態交錯推理機制的訓練數據構建與蒸餾算法設計方法。通過引入符合交錯思維特點的多輪交互數據及專門的蒸餾策略,我們能夠訓練出輕量、高效且具備強推理能力的 Agent 模型,有效提升模型在複雜任務中的表現和響應速度。這不僅突破了傳統 CoT 推理鏈在多輪交互場景下的侷限,也為智能體系統的規模化應用奠定了堅實基礎。展望未來,我們將基於 EasyDistill 框架進一步開源更多 Agent 蒸餾相關的算法與模型。歡迎大家加入我們,共同交流大模型蒸餾技術!
參考工作
EasyDistill 系列相關論文
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations. arXiv preprint
- Yuanjie Lyu, Chengyu Wang, Jun Huang, Tong Xu. From Correction to Mastery: Reinforced Distillation of Large Language Model Agents. arXiv preprint
- Chengyu Wang, Junbing Yan, Wenrui Cai, Yuanhao Yue, Jun Huang. EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models. EMNLP 2025
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Thinking with DistilQwen: A Tale of Four Distilled Reasoning and Reward Model Series. EMNLP 2025
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Enhancing Reasoning Abilities of Small LLMs with Cognitive Alignment. EMNLP 2025
- Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang. DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models. ACL 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024