演講人:宋曉峯 洋錢罐大數據運維總監
十年破壁:從數據築基到智能生態的全鏈路實踐
一、數據築基——自建大數據集羣的攻堅與突破
背景介紹
瓴嶽科技(Fintopia)是以大數據和人工智能為基礎的數字科技集團,為全球用户提供卓越的金融體驗。2015年成立至今,瓴嶽科技始終聚焦消費金融,業務遍佈中國大陸、東南亞、拉丁美洲和非洲等;集團旗下擁有洋錢罐、Easycash等知名品牌,截至2025年,服務全球金融機構超過114家,全球註冊用户超過1.81億,全球累計交易額超過5400億元。在公司發展的過程中,我們大數據部門為智能風控、精準營銷、產品創新三大核心業務提供數據支撐,整合多源數據,利用機器學習算法實時識別欺詐風險,構建全流程風控體系,基於用户行為、偏好等數據,定製個性化金融服務推薦,通過分析市場趨勢與用户需求數據,為產品開發提供精準方向,助力瓴嶽科技全球化業務佈局。
大數據技術棧迭代與升級路徑
過去十年,洋錢罐的大數據技術棧經歷了多次迭代。
2018年,面對數據孤島問題及傳統MySQL數據庫無法有效支持複雜分析任務的挑戰,我們自建了首個基於十多個節點的Hadoop大數據集羣。當時用户規模約2000萬,每日新增數據量約300GB。
隨着業務需求的增長,特別是在2018年至2021年間,原有的MapReduce 框架因處理延遲較高而難以滿足日益增長的數據處理時效性要求。因此,在2021年,我們將離線數據處理引擎由MapReduce遷移至Apache spark 2.x,並同步升級了Hive版本至3.x以提升數據倉庫性能。彼時,系統每天運行約3,000個批處理作業。
為進一步提高數據處理效率並響應業務對數據實時性的更高期待,2022年我們引入了數據湖技術Apache Hudi,從而將原本的日全量數據抽取轉變為增量更新模式,顯著提升了數據的新鮮度至小時級別。
此外,為了更好地支持交互式查詢場景,在2023年我們採用StarRocks作為新的Ad-hoc查詢引擎,取代了之前依賴於Spark Thrift Server實現的方法。截至目前,Ad-hoc 日均SQL查詢請求量超過8,000,P95響應時間控制在60秒以內。鑑於全球化佈局帶來的彈性資源、業務穩定性和成本優化要求,我們在2024年對整個集羣架構進行了重大升級,將自建集羣遷移至阿里雲EMR Serverless平台,Yarn 節點規模超過一千台,在此過程中,我們也將spark 2.x升級到了spark 3.x。
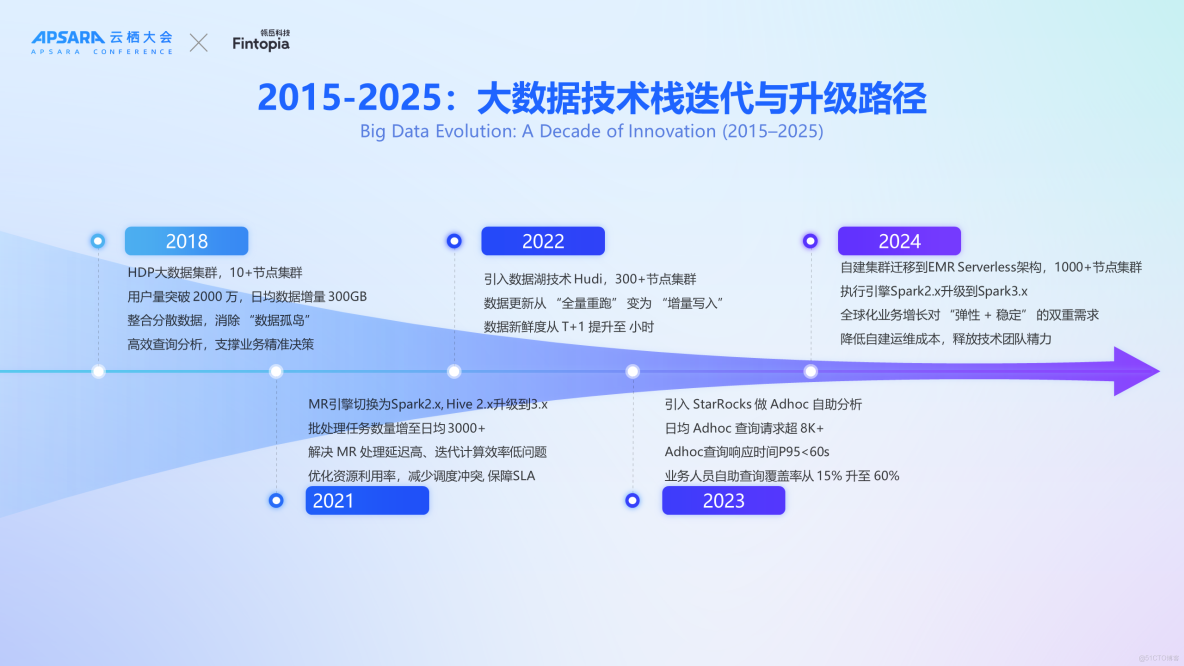
當前,我們集羣的整體存儲能力已經達到單副本10PB的規模,每日新增數據量約為30TB。核心業務報表數量超過3000份,而調度工作流數量已突破15000個。在StarRocks集羣方面,我們同時採用了存算一體化架構與存算分離架構,並根據不同的業務線進行了劃分,因此目前擁有超過30個獨立的StarRocks集羣實例。左側展示的是我們的調度能力和 Ad-hoc 查詢能力,YARN日執行job量超過4萬。

從穩定性到效率:自建集羣的困境解析
在自建大數據集羣的過程中,我們遇到了諸多挑戰,主要集中在穩定性、彈性資源管理和運維效率三個方面。
首先,在穩定性方面,我們面臨的主要問題是業務SLA破線。這種情況往往源於底層 NodeManager 因網絡帶寬限制或shuffle 量大而導致任務失敗率上升。此外,在使用開源組件過程中,也存在一些 bug 或者性能問題,比如我們在使用 Hive3.x 開源版本時,在高併發的場景下會出現進程卡死等問題,從而影響業務穩定性,無法滿足生產環境的要求。
其次,在彈性資源管理上,自建集羣缺乏快速擴展的能力以應對突發流量需求。例如,在凌晨遇到緊急情況時,希望迅速增加計算資源來解決問題變得不可行。同時,即使進行了物理服務器的擴容,在YARN的容量調度策略下,也難以有效平衡不同隊列之間的負載分佈,導致部分隊列利用率過高而其他隊列則相對空閒,整體上降低了集羣資源利用效率。
最後,關於運維效率的問題,大數據集羣的維護工作相當複雜且耗時。從硬件採購到最終完成配置並投入使用,整個過程通常需要兩至三天時間。此外,開發人員還需投入大量精力進行性能調優、故障排除及日常巡檢等任務,這不僅增加了人力成本,也影響了團隊的工作效率。

Spark 引擎核心痛點解析
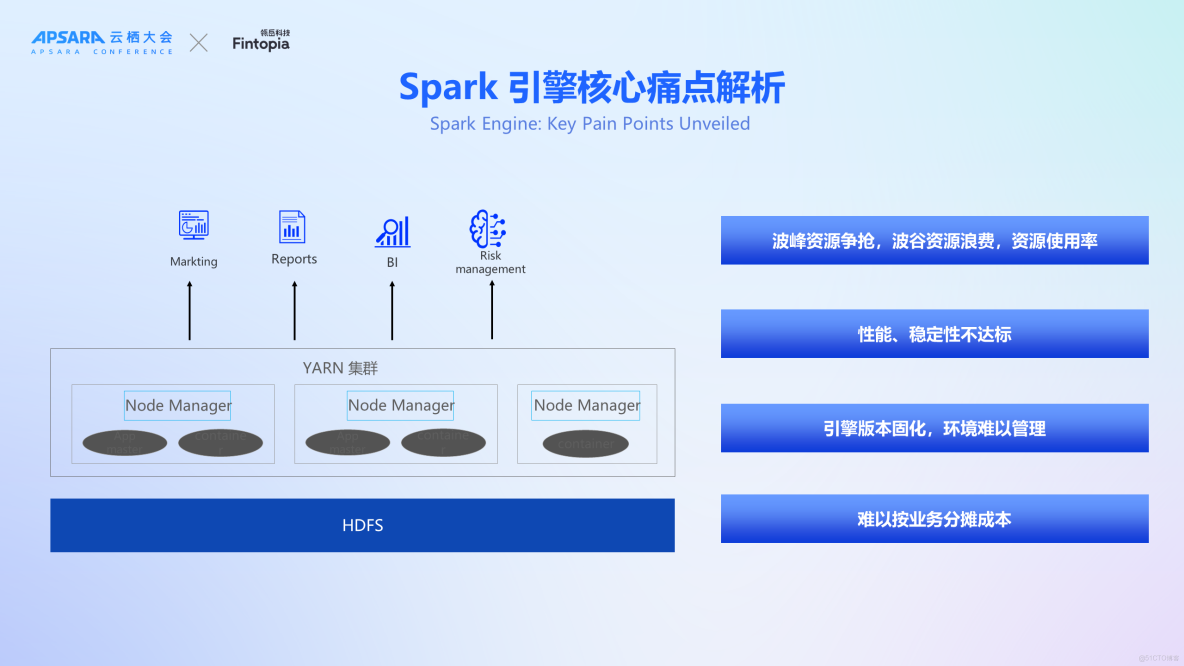
在使用Apache Spark引擎的過程中,我們遇到了幾個核心痛點,這些問題主要集中在資源管理、性能與穩定性、版本升級以及成本控制等方面。
首先,在資源管理方面,我們面臨的主要問題之一是峯值資源的優化。例如,在凌晨執行大規模任務時,該任務可能會佔用隊列中90%以上的資源,而其他較小的任務雖然只佔用了剩餘10%左右的資源,但其完成時間卻可能更長。這表明了當前資源分配機制存在不合理之處,需要更加精細地調整以提高整體效率。另一個問題是谷值期間資源利用率低下。特別是在非高峯時段(如午夜過後),集羣的整體資源利用率往往只能達到30%左右,導致大量計算能力被閒置。
其次,在性能與穩定性方面也存在問題。當我們使用自建的大數據集羣部署Spark時,採用的是開源版的Shuffle Service作為NodeManager組件。然而,在高負載情況下,這種服務的表現並不理想,容易成為瓶頸,並且當單個NodeManager出現問題時,會嚴重影響到整個集羣上運行任務的穩定性和性能。
第三點關於引擎版本固化的問題也非常突出。比如將 spark 2.x遷移到spark 3.x,不僅耗時較長,還需要充分考慮新舊版本之間的兼容性問題、系統穩定性測試以及對現有業務流程的影響評估等多方面因素。
最後,在成本控制方面同樣存在着挑戰。由於不同業務線之間可能存在交叉需求,比如風控場景下的離線數據倉庫處理與Adhoc查詢同時進行,這就使得很難按照單一業務維度來精確劃分和管理相關費用。因此,如何有效地衡量並優化跨部門使用的Spark資源成本,成為了我們需要解決的重要課題之一。
StarRocks 問題解析
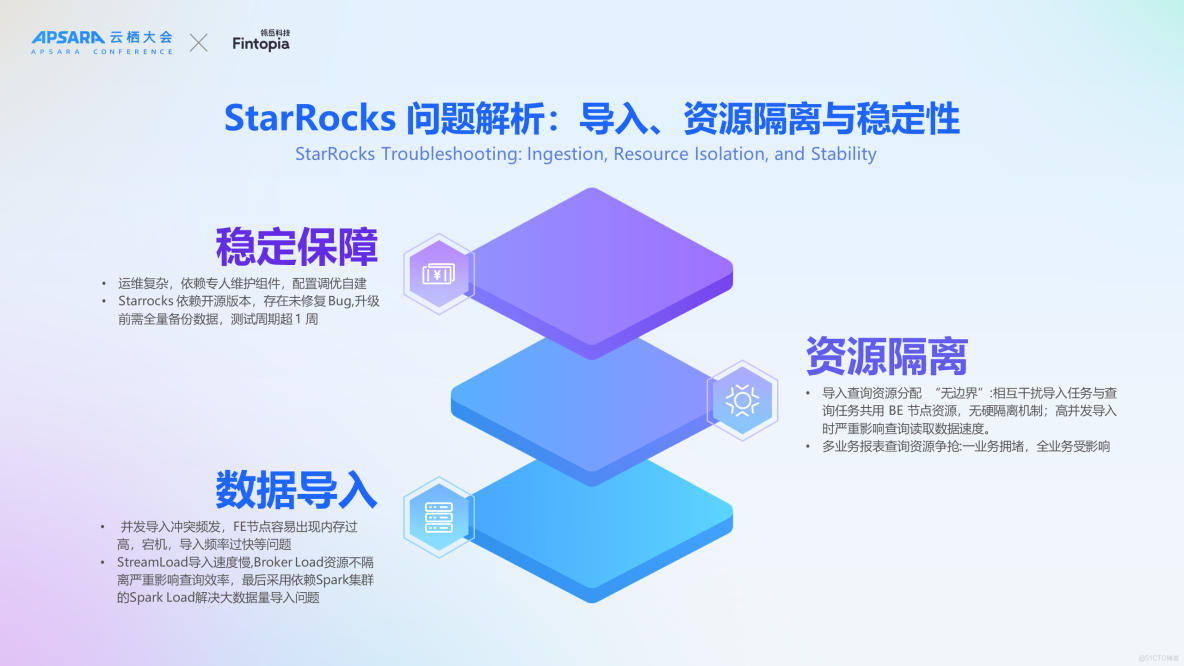
在使用 StarRocks 的過程中,我們也遇到了一些挑戰,主要集中在數據導入、資源隔離及系統穩定性三個方面。
首先,在數據導入方面,StreamLoad 導入速度慢,支持的數據量有限,當提高數據導入頻率時,可能會觸發 FE 內存問題,會出現MVC相關報錯。Broker Load 雖然導入速度快,但是軟性資源隔離策略會影響讀性能,最後我們還是要依賴Spark集羣的Spark Load解決大數據量導入問題
其次,關於資源隔離的問題,雖然開源版StarRocks提供了基本的資源隔離功能,但它是軟隔離,而非硬性隔離,數據導入與查詢操作之間存在競爭關係,尤其是大規模查詢請求可能會影響其他小型查詢請求的響應時間。
最後,在系統運維與穩定性保障方面,開源版本沒有自帶的管控頁面,運維人員不得不自行開發一系列腳本來完成擴縮容等請求,增加了運維難度。此外,在面對版本升級時,升級耗時長,還需額外進行業務迴歸測試以驗證新版本兼容性和系統穩定性。
以上因素共同構成了 StarRocks 在實際應用中面臨的主要技術挑戰。
二、雲帆起航——遷移阿里雲 EMR 的全鏈路實踐
面對上述挑戰,我們對大數據架構進行了全面升級,全面切換至阿里雲生態組件。此次升級的核心在於構建了一個符合數據湖理念的全新平台架構,該架構不僅滿足了當前業務需求,還為公司未來向數據湖方向的發展奠定了堅實基礎。此次升級主要對兩個計算引擎進行了重大改造。
首先,我們將Hive SQL完全遷移至Spark SQL。因為相較於Hive SQL,Spark SQL展現出更優的執行效率,這也是業界共識。整體遷移過程非常絲滑,在性能與兼容性方面,EMR Serverless Spark 表現亮眼,還支持豐富的開源生態,如Kyuubi、Livy等。
其次,我們將 StarRocks 存算一體版本切換為了存算分離版本,這也順應了Serverless 架構的發展趨勢。
基於計算引擎升級,我們在上層構建了自己的數據應用產品,如一站式開發平台、標籤系統、實時開發平台、數據質量監控系統、Ad-hoc查詢等。
我們還將底層存儲從傳統HDFS切換為阿里雲OSS-HDFS,消除了原生Hadoop文件系統中存在的單點故障問題。相比自建集羣成本,新架構成本僅為其十分之一左右。
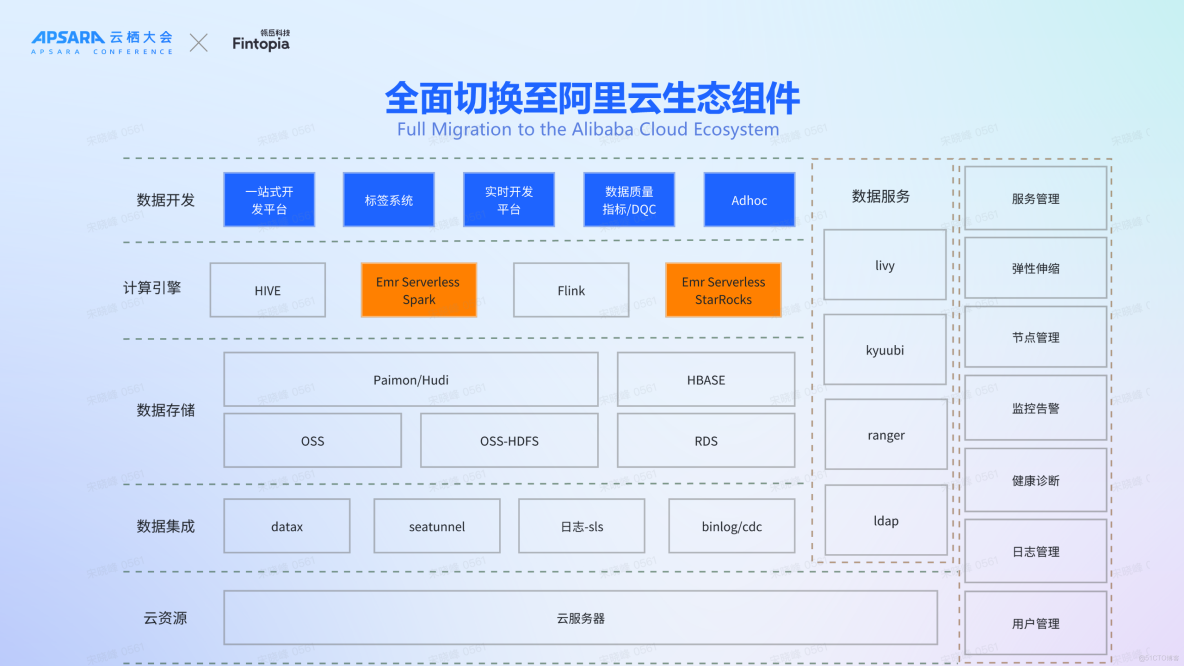
EMR Serverless Spark:一站式數據平台服務
EMR Serverless Spark 提供了一站式的數據平台服務,包括任務開發、調試、調度和運維等,極大地簡化了數據處理和模型訓練的全流程。內置 SQLEditor、Notebook 開發環境,提供版本管理,工作流調度,以及運維診斷能力。 版本管理功能使得用户能輕鬆切換Spark版本,只需確保SQL語句能正常運行,數據能正常處理即可,無需考慮底層基礎設施的複雜性。
針對Spark和Python環境,用户可以根據具體業務需求進行配置,如調整spark-defaults.conf文件中的參數值,來優化特定應用場景下的性能表現。通過簡單的spark-submit命令配合相關參數,即可快速切換到所需的運行時環境,極大提高了工作效率。
監控與診斷方面,EMR Serverless Spark 還提供完善的監控與診斷功能。提供工作空間、隊列以及任務等各種維度的資源指標統計,方便用户更清晰地掌握作業運行情況。在Spark任務完成之後,收集和分析該任務的各種資源消耗指標,並根據這些指標給出合理的優化建議。

EMR Serverless Spark 還提供極致資源彈性與性能。首先,在彈性伸縮方面,支持 Driver/Executor級別進程彈性,最低支持一核力度,容器拉起時間在20秒以內。資源供給方面,底層是 Iaas + 神龍資源池,提供海量供給,自遷移至 EMR Serverless Spark 以來,我們尚未遇到任何資源短缺問題。
此外,EMR Serverless Spark 採用類似於YARN的資源管理模式。Workspace/隊列兩層Quota管理支持用户根據業務特性選擇合適的提交路徑。平台提供了基於Workspace/隊列/作業的多維度、精確到天/時/分的多週期資源觀測能力。
性能方面,EMR Serverless Spark 自研 Fusion 引擎,內置高性能向量化計算和 RSS 能力,相比開源版本性能大幅提升
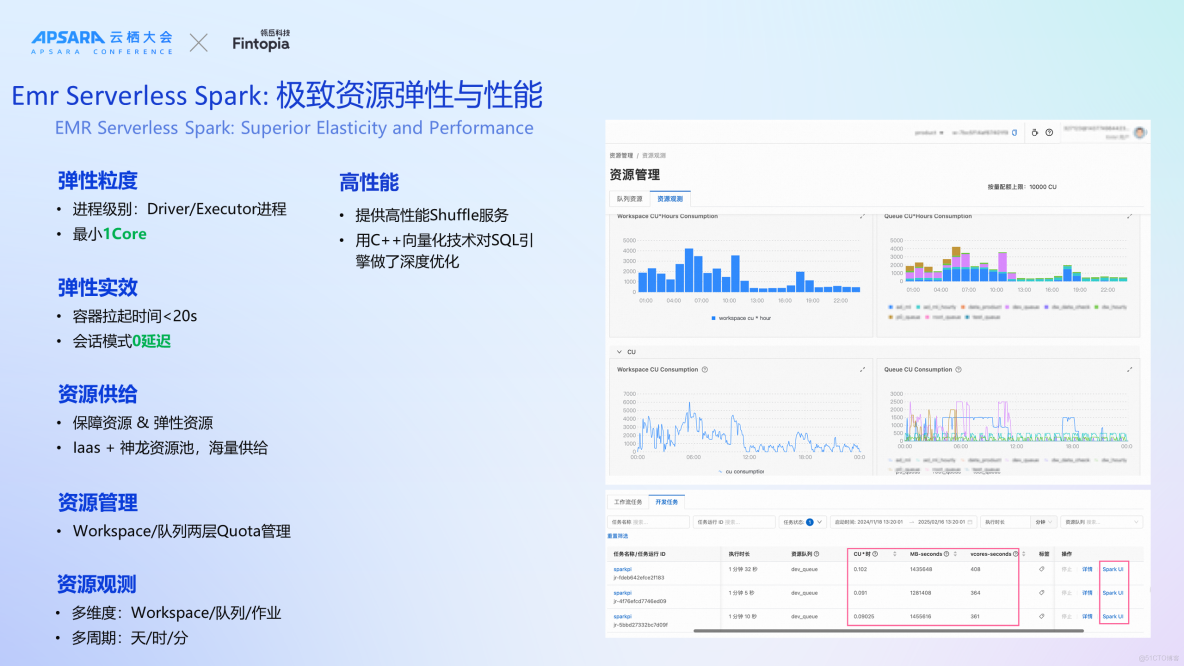
EMR Serverless StarRocks:功能豐富、性能卓越
EMR Serverless StarRocks在管控能力方面顯著優於自建方案,提供實例管理功能,包括創建,擴容縮容,升降配,網絡管理,白名單管理,操作任務管理,網關管理等。
此外,其管控平台提供實例健康報告與慢SQL診斷分析、可視化緩存管理、支持大/小版本主動觸發滾動升級、支持全鏈路實例操作審計等功能。
值得一提的是,EMR Serverless StarRocks 實現了真正的存算分離架構,提供物理隔離能力,不同計算組作業負載相互獨立,支持多計算組獨立配置。在我們的實際應用場景下,存算分離內表查詢較開源性能提升約100%,數據湖查詢較開源性能提升約50%。
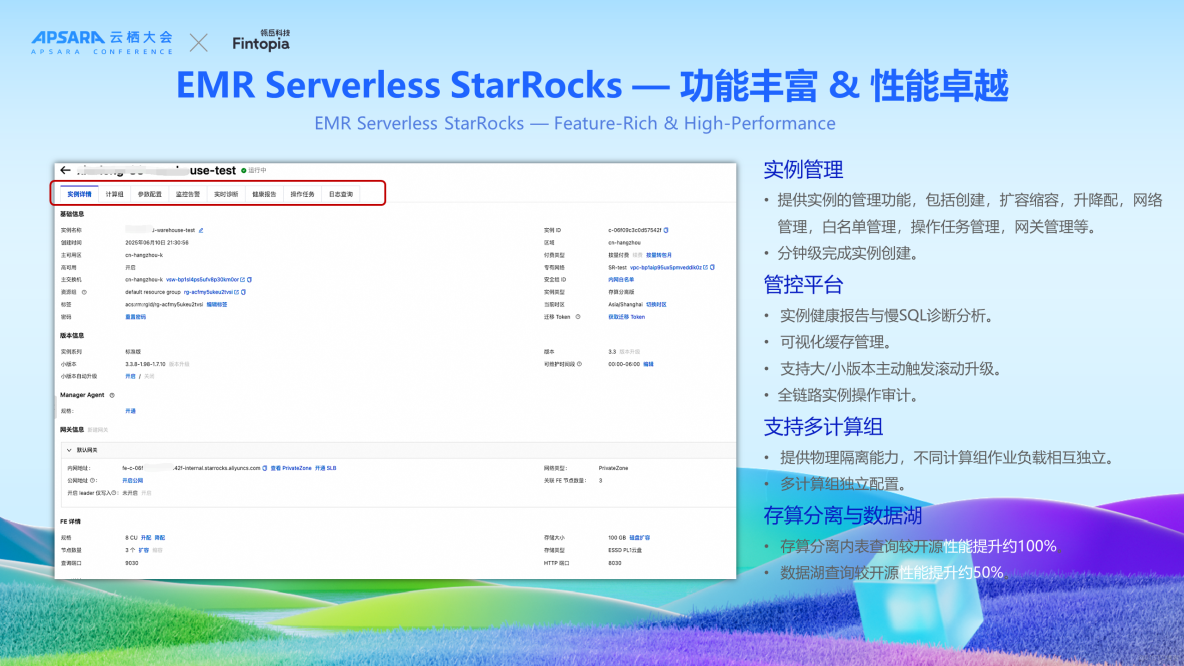
下圖展示了基於EMR Serverless StarRocks 的湖倉新範式,StarRocks 作為統一 Lakehouse,基於湖表進行自助分析查詢。數據寫入 StarRocks 提供極速分析;數據寫入開放數據湖,使用 StarRocks 直接分析數據湖;在DWD、DWS以及ADS層,通過構建物化視圖並實施分層建模策略,不僅能夠有效支撐各類報表需求,同時也為OLAP提供了強有力的支持。
架構升級帶來的關鍵價值
上述重大架構升級,帶來了哪些關鍵價值呢?
首先,在成本優化方面,通過引入彈性資源,顯著提高了資源利用率。
其次,從業務穩定性角度來看,EMR Serverless Spark 自帶的高性能 Shuffle 服務,極大地增強了系統的穩定性和可靠性。此外,StarRocks 的性能優化也進一步提升了整體業務處理能力與響應速度。
關於業務敏捷性,新架構支持快速部署新業務場景所需的計算資源,從而大幅縮短了業務上線週期。
運維效率方面,得益於 EMR Serverless Spark與 EMR Serverless StarRocks 豐富的管控能力,開發團隊所需投入的日常維護工作量顯著減少。同時,平台提供了全天候的技術支持服務,確保即使面對突發問題也能迅速獲得解決方案,進一步保障了系統的連續可用性。

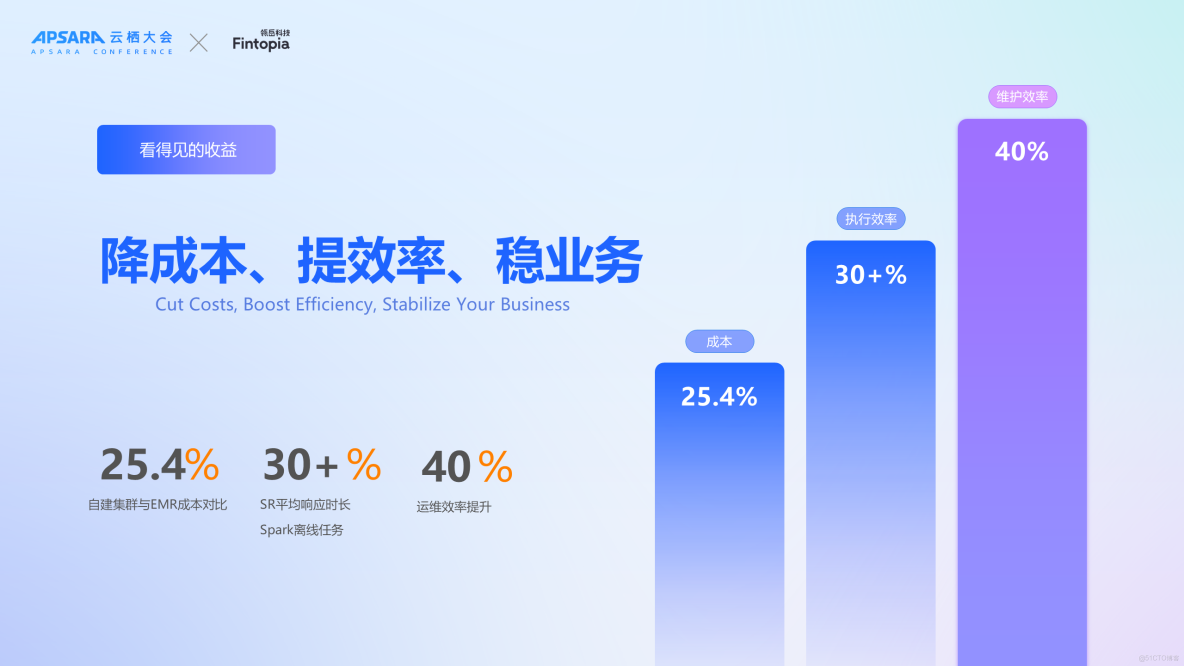
具體而言,在保持業務規模不變的前提下,與傳統的自建方案相比,基於 EMR Serverless 構建的解決方案能夠實現約25.4%的成本節約。基於 EMR Serverless StarRocks 進行查詢(如標籤系統和用户圈選場景),SQL 查詢執行時長縮短了30%。此外,在相同成本情況下,EMR Serverless Spark 作業的執行時間也縮短了30%以上。最值得注意的是運維效率方面的改進,實現了近40%的大幅提升。
三、智創未來——未來基於阿里雲的智能生態佈局
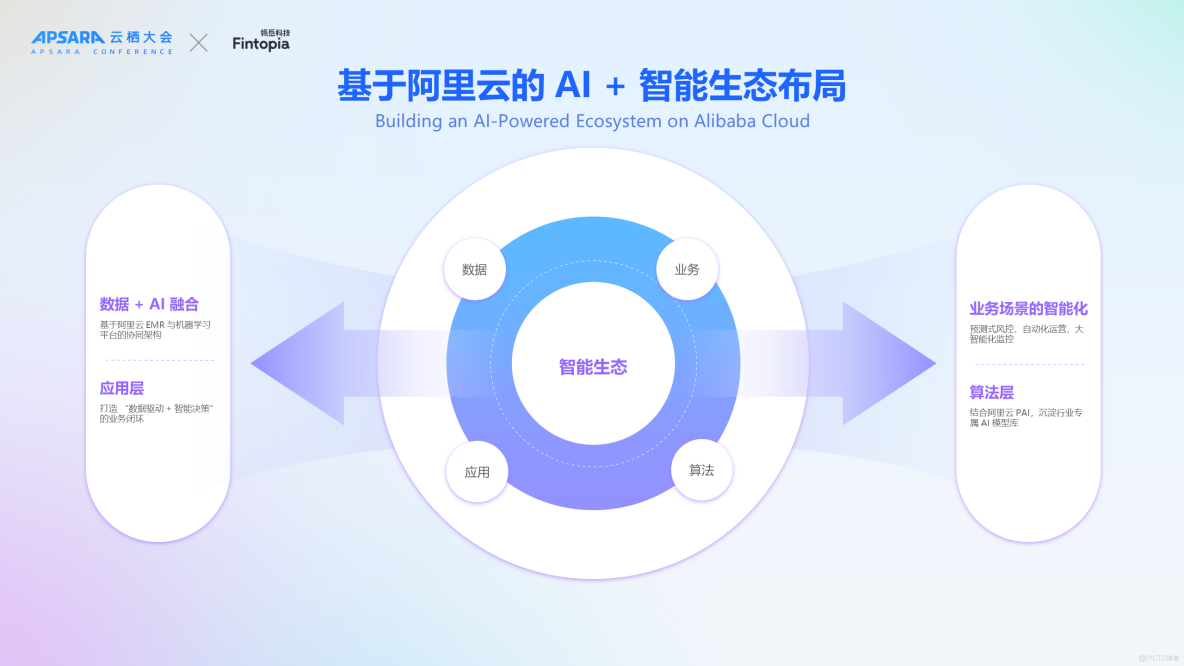
在完成架構升級後,整體穩定性得到顯著提升。展望未來,我們的目標是構建一個更加智能化的金融生態環境。為此,我們設想了四個主要發展方向:
首先,在數據處理方面,我們計劃基於阿里雲EMR及機器學習平台PAI來實現高效的數據協同架構。
其次,在業務流程優化上,通過整合阿里雲的大規模模型能力,旨在創建一個既簡化又高效的運營環境,涵蓋預測式風控、自動化運營,大智能化監控等領域。
再者,在應用層面,致力於形成以數據為驅動並支持智能決策的完整業務閉環。
最後,在算法創新方面,我們將依託於阿里雲機器學習平台PAI,專注於開發適用於特定行業的專屬AI模型庫。