
目錄
yolov7-logo-detection項目概述
一、項目目標與核心概念界定
1. 核心目標
2. 關鍵概念區分
二、技術架構:為何選擇 YOLOv7?
1. YOLOv7 的核心優勢
2. YOLOv7 的三大核心組件
3. YOLOv7 的關鍵改進
三、數據集:從小規模驗證到大規模擴展
1. 兩個數據集的核心參數對比
2. 核心訓練集(Flickr Logos 27)細節
四、本地部署與訓練:全流程可復現
1. 環境與數據準備(前置步驟)
2. 模型訓練:參數與資源適配
3. 推理測試(驗證模型效果)
五、結果評估:可視化與模型獲取
1. 核心評估圖表
2. 模型獲取
六、項目特點與潛在優化方向
1. 項目優勢
2. 潛在優化方向
小結
補充 LogoDet-3K 訓練步驟
一、第一步:處理「舊數據衝突」
二、第二步:確認「LogoDet-3K 標註轉換」正確
1. 方案1:使用原腳本src/convert_annotations.py
1.1. 執行標註轉換命令
1.2. 關鍵檢查點
2. 方案2:從huggingface直接獲取(推薦)
2.1 convert_annotations_logodet3k_parquet.py 代碼(原convert_annotations.py)
2.2 關鍵修改説明
2.3 使用方法
三、第三步:運行「數據劃分」
1. 方案1:(複用現有 prepare_data.py)
2. 方案2:prepare_data_logodet3k.py(convert_annotations_logodet3k_parquet.py後續)
2.1 核心問題分析
2.2 prepare_data_logodet3k.py(原prepare_data.py)
2.3 關鍵修改説明
2.4 使用方法
2.5 驗證劃分結果
四、第四步:配置文件「替換與檢查」(僅改這 1 個文件)
1. 方案1:複用原文件logo_data.yaml
2. 更新logo_data.yaml(基於convert_annotations_logodet3k_parquet.py)
2.1 update_yaml_names.py
2.2 運行方法
2.3 驗證結果
五、第五步:啓動訓練(複用 train.py,僅微調參數)
附錄(項目代碼解析)
一、Flickr27 數據集
二、LogoDet-3K數據集
三、關鍵代碼解釋
1. src/convert_annotations.py詳細註釋
1.1. YOLOv7 要求的標註格式説明
1.2. src/convert_annotations.py代碼詳細解析
2. src/prepare_data.py詳細解釋
2.1. 數據集劃分比例
2.2. 目錄結構整理
2.3. 針對不同數據集的適配
2.4. 關鍵函數作用
2.5. 代碼詳細解釋
3. src/yolov7/train.py代碼解析
3.1. 訓練命令參數解析
3.2. 推理輸出位置設定
3.3. src/yolov7/train.py詳細註釋
4. src/yolov7/detect.py詳細解釋
4.1. 推理命令參數解析
4.2. 推理腳本的使用説明
4.3. src/yolov7/detect.py詳細註釋
四、可供參考的bug
1. pickle.UnpicklingError
2. AttributeError (np.int)
3. RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
4. 本地加載bug
yolov7-logo-detection項目概述
項目圍繞基於 YOLOv7 的自然場景 Logo 檢測展開。基於先進的YOLOv7架構,在充足的高質量數據上訓練(Flickr27與LogoDet-3K),對已知類別的Logo可以達到非常高的檢測精度和召回率。YOLO是著名的單階段、端到端檢測模型,推理速度極快,非常適合需要實時檢測的場景。本文涵蓋yolov7-logo-detection項目基本實現,基於LogoDet-3K的進階實現,以及Debug。
https://github.com/nuwandda/yolov7-logo-detection(github地址)
一、項目目標與核心概念界定
1. 核心目標
訓練一個能在自然場景圖像(in the wild) 中檢測 Logo 的模型,通過對比兩個不同規模數據集的適配性,驗證 YOLOv7 在 Logo 檢測任務中的有效性。
2. 關鍵概念區分
項目首先明確了目標檢測(Object Detection) 與圖像識別(Image Recognition) 的核心差異,這是理解項目技術定位的基礎。
|
對比維度
|
圖像識別(Image Recognition)
|
目標檢測(Object Detection)
|
|
核心輸出
|
僅為圖像整體標籤(如 “狗”)
|
標籤 + 邊界框(如 “狗 1(x1,y1,x2,y2)”“狗 2(x3,y3,x4,y4)”)
|
|
核心能力
|
分類圖像 “是什麼”
|
定位 + 分類:“是什麼” 且 “在哪裏”
|
|
項目適配場景
|
無法滿足 Logo 檢測(需定位單個 / 多個 Logo)
|
完全適配(需標註 Logo 位置並分類品牌)
|
二、技術架構:為何選擇 YOLOv7?
項目選用 YOLOv7 作為基礎架構,核心原因是其在速度與精度的平衡上具備行業領先性,且架構設計適配 Logo 檢測的 “細粒度目標 + 複雜背景” 需求。
1. YOLOv7 的核心優勢
- 性能天花板:在 GPU V100 上,是所有實時目標檢測器中(30 FPS 及以上)精度最高的,AP(平均精度)達 56.8%;
- 速度覆蓋廣:支持 5 FPS ~ 160 FPS 的速度範圍,可適配不同硬件資源(從低端 GPU 到高端 GPU)。
2. YOLOv7 的三大核心組件
YOLOv7 基於全連接神經網絡(FCNN) 構建,部分版本引入 Transformer,核心分為三部分,各司其職:
- Backbone(骨幹網絡):核心功能是提取圖像關鍵特徵(如 Logo 的邊緣、紋理、顏色分佈),為後續檢測提供 “特徵原料”;
- Neck(頸部網絡):對 Backbone 輸出的特徵圖進行整合,構建特徵金字塔—— 解決 “小 Logo 漏檢” 問題(不同層級特徵圖適配不同尺寸的 Logo);
- Head(頭部網絡):輸出層,最終生成 Logo 的邊界框座標和類別標籤,完成檢測任務。
3. YOLOv7 的關鍵改進
項目特別提及 YOLOv7 論文中的兩大核心改進,這是其超越前代 YOLO 模型的關鍵:
(1)架構優化(提升特徵提取效率)
- E-ELAN(擴展高效層聚合網絡):通過更靈活的特徵聚合方式,增強模型對複雜場景(如 Logo 被遮擋、光照變化)的適應性;
- 基於拼接的模型縮放(Model Scaling for Concatenation-based Models):在擴大模型規模時,避免特徵冗餘,平衡精度與計算成本(適配 Logo 檢測的 “輕量部署需求”)。
(2)可訓練 BoF(Bag of Freebies,無額外計算成本的精度提升)
- 規劃化重參數化卷積(Planned re-parameterized convolution):訓練時用複雜卷積提升精度,推理時簡化為普通卷積,不增加推理耗時;
- 粗細損失策略(Coarse for auxiliary, Fine for lead loss):輔助分支用 “粗粒度標籤” 快速收斂,主分支用 “細粒度標籤” 提升精度,適配 Logo 類間差異小(如 Nike 與 Puma)的特點。
三、數據集:從小規模驗證到大規模擴展
項目採用 “雙數據集” 設計,兼顧快速驗證與未來擴展,解決了 “小數據訓練快但泛化弱,大數據泛化強但訓練耗時” 的矛盾。
1. 兩個數據集的核心參數對比
|
數據集名稱
|
規模級別
|
類別數
|
標註對象數
|
圖像總數
|
標註類型
|
項目用途
|
|
Flickr Logos 27 |
小規模
|
27
|
810 個(每類 30 張)
|
810 張
|
邊界框(Bounding Box)
|
核心訓練集(耗時短,快速驗證模型)
|
|
LogoDet-3K |
大規模
|
3000
|
~20 萬個
|
158,652 張
|
邊界框
|
擴展支持(暫未訓練,待補充步驟)
|
2. 核心訓練集(Flickr Logos 27)細節
- 覆蓋品牌:含 Adidas、Apple、Coca Cola、Nike、Starbucks 等 27 個主流品牌,場景多樣(如廣告、包裝、門店);
- 數據質量:全手動標註邊界框,無標註噪聲,適合作為 “模型 baseline 驗證集”。
四、本地部署與訓練:全流程可復現
文檔提供了 ** step-by-step 的實操命令 **,降低了復現門檻,核心流程分為 “環境準備→數據處理→模型訓練→推理測試” 四步。
1. 環境與數據準備(前置步驟)
|
步驟
|
核心操作
|
目的
|
|
1. 下載數據集
|
項目根目錄下,運行 |
獲取 Flickr Logos 27 的標註圖像,無需手動下載
|
|
2. 下載基礎模型
|
下載 3 個預訓練權重:- yolov7_training.pt(基礎版)- yolov7-tiny.pt(輕量版)- yolov7-e6e_training.pt(高精度版)
|
基於預訓練權重 “微調”,減少訓練迭代次數,提升收斂速度
|
|
3. 安裝依賴
|
運行 |
解決依賴衝突,確保代碼可運行
|
|
4. 標註格式轉換
|
運行 |
將 Flickr 的原始標註格式轉為 YOLOv7 要求的 “圖像 + txt 標籤” 格式(txt 含類別 ID + 邊界框歸一化座標)
|
|
5. 數據集劃分
|
運行 |
按 8:1:1 劃分為訓練集(train)、驗證集(val)、測試集(test),符合機器學習標準流程
|
2. 模型訓練:參數與資源適配
(1)核心訓練參數(基於 NVIDIA RTX 3060 Laptop GPU)
|
參數
|
取值
|
選擇理由
|
|
Epoch(迭代輪次)
|
300
|
小數據集(810 張)需足夠輪次讓模型收斂,避免欠擬合
|
|
Batch Size(批次大小)
|
2
|
筆記本 GPU 顯存有限(RTX 3060 Laptop 通常 6GB),批次過大會導致顯存溢出
|
|
Image Size(圖像尺寸)
|
640x640
|
平衡精度與速度:640 是 YOLO 系列最優尺寸,可覆蓋多數 Logo 大小,320 則精度下降
|
(2)顯存不足的解決方案
- 降低 Batch Size(如從 2→1);
- 改用輕量模型(yolov7-tiny.pt,計算量僅為基礎版的 1/3);
- 縮小圖像尺寸(如 640→320,精度會降低,但顯存佔用減少 50%+)。
(3)訓練命令與擴展支持
- 基礎命令:
python src/yolov7/train.py --img-size 640 --cfg src/cfg/training/yolov7.yaml --hyp data/hyp.scratch.yaml --batch 2 --epoch 300 --data data/logo_data_flickr.yaml --weights src/yolov7_training.pt --workers 2 --name yolo_logo_det --device 0- 雲環境支持:提供 Google Colab 鏈接,無需本地 GPU 即可復現訓練(降低硬件門檻)。
3. 推理測試(驗證模型效果)
通過一下命令實現:
python src/yolov7/detect.py --source data/Sample/test --weights runs/train/yolo_logo_det/weights/best.pt --conf 0.25 --name yolo_logo_det--source:指定測試圖像路徑;--weights:加載訓練好的最優模型(best.pt);--conf 0.25:置信度閾值設為 0.25(過濾低置信度預測,平衡漏檢與誤檢)。
五、結果評估:可視化與模型獲取
項目未提供具體的 AP、Precision、Recall 數值,但通過關鍵評估圖表展示了模型性能,且提供了訓練好的模型供直接使用。
1. 核心評估圖表
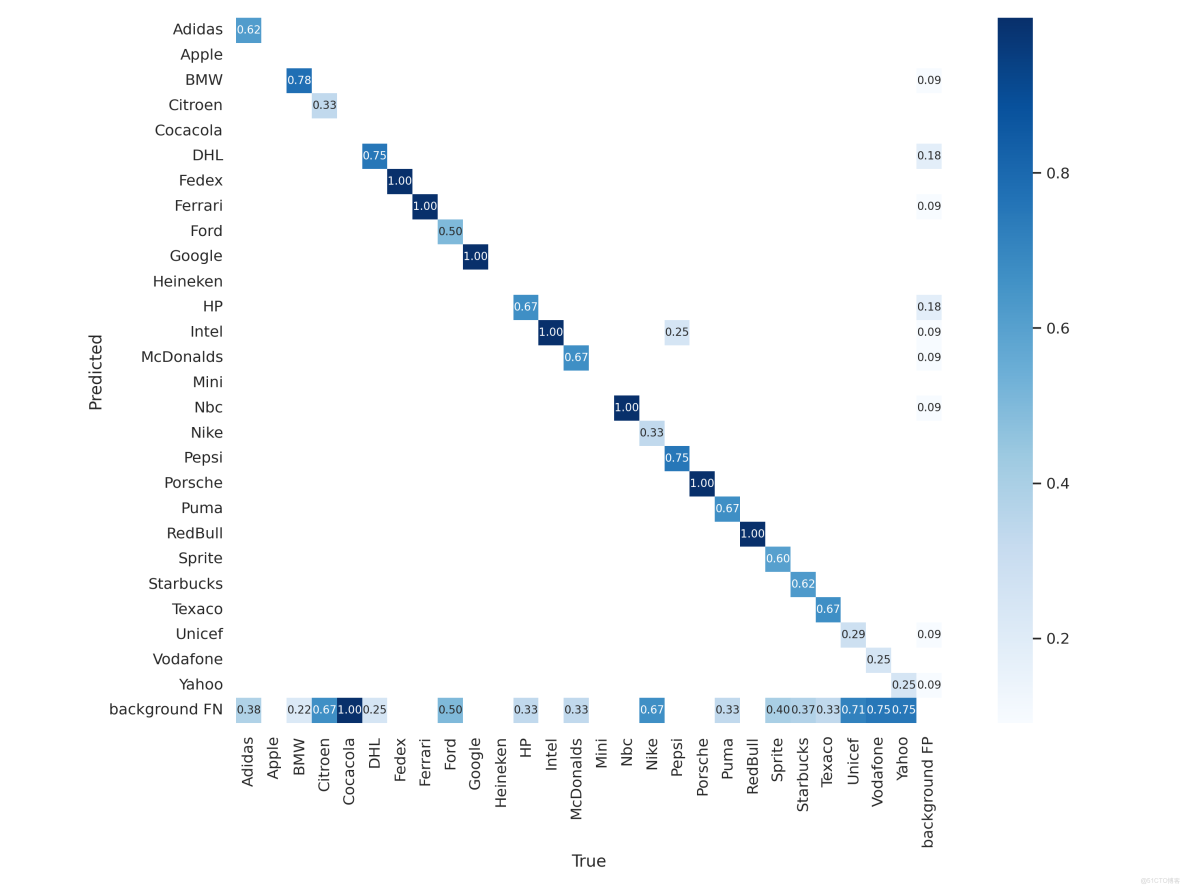
混淆矩陣(Confusion Matrix):
- 作用:展示 27 個 Logo 類別的 “真實標籤” 與 “預測標籤” 對應關係,可直觀發現 “易混淆品牌”(如 Puma 與 Adidas,因 Logo 均含條紋元素);
- 理想狀態:對角線數值高(預測正確),非對角線數值低(誤判少)。
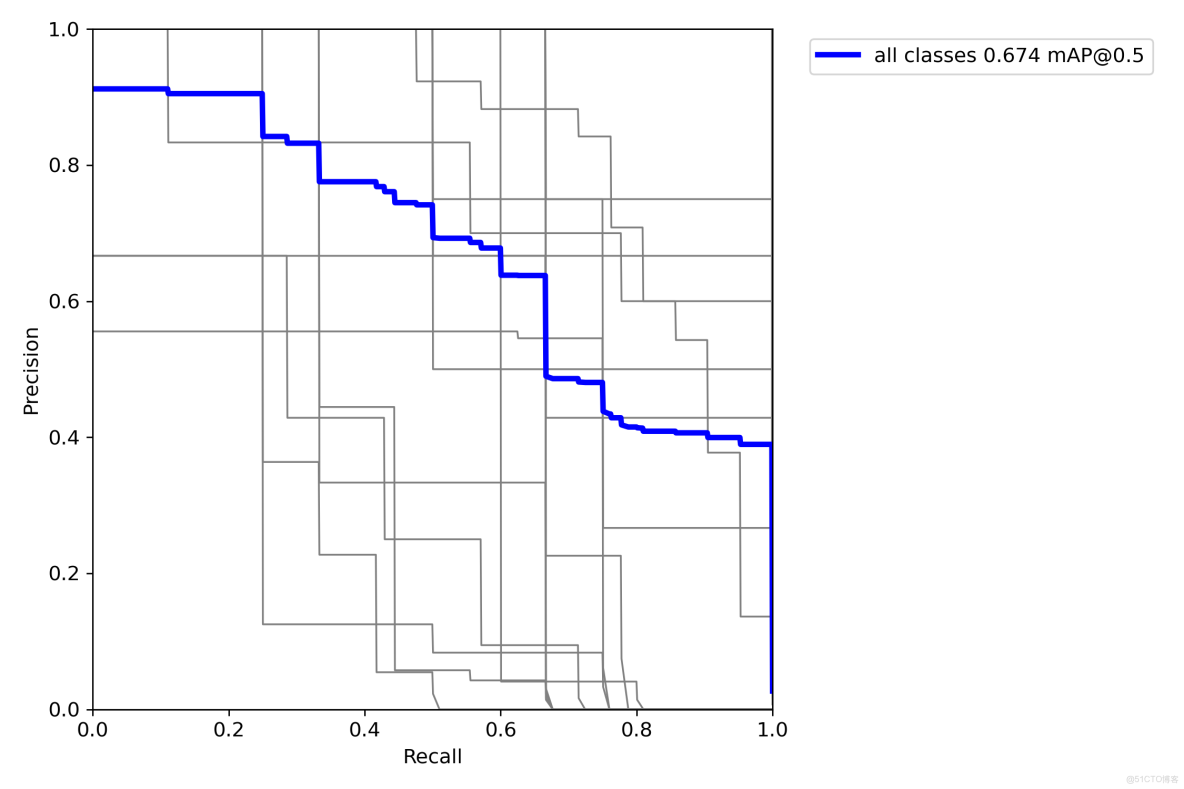
PR 曲線(Precision-Recall Curve):
- 作用:展示 “精確率(Precision)” 與 “召回率(Recall)” 的權衡關係(精確率高→誤檢少,召回率高→漏檢少);
- 評估標準:曲線下面積(AUC)越大,模型整體性能越好,尤其適合 “類別不平衡” 的 Logo 檢測場景(部分品牌樣本少)。
2. 模型獲取
提供訓練好的模型下載鏈接,可直接用於 Logo 檢測推理,無需重複訓練,降低應用門檻。
但鏈接顯示不存在。
六、項目特點與潛在優化方向
1. 項目優勢
- 可復現性強:從數據下載到推理的每一步均提供具體命令,且支持 Colab,新手友好;
- 架構適配性高:選用 YOLOv7 平衡速度與精度,適合實際場景部署(如攝像頭實時 Logo 檢測);
- 擴展性好:預留 LogoDet-3K 數據集的適配空間,未來可支持 3000 類 Logo 檢測,泛化性大幅提升。
2. 潛在優化方向
- 補充 LogoDet-3K 訓練步驟:當前僅用小數據集訓練,大規模數據集的訓練參數(如學習率調整、顯存優化)需進一步明確;
- 增加量化評估指標:需補充具體的 AP@0.5、AP@0.5:0.95、FPS 等數值,更精準衡量模型性能;
- 數據增強策略:針對 Logo 檢測的 “遮擋、變形、光照變化” 問題,可增加隨機遮擋、透視變換、亮度調整等數據增強,提升模型魯棒性。
小結
該項目是一個 “從理論到實操” 完整的 Logo 檢測方案 ,通過 YOLOv7 的高效架構、清晰的數據集設計、可復現的流程,為 “自然場景 Logo 檢測” 提供了可靠的技術路徑。其核心價值在於:既適合新手學習目標檢測與 YOLOv7 的應用,也可作為實際項目的 baseline(直接使用訓練好的模型或擴展到大規模數據集)。
補充 LogoDet-3K 訓練步驟
要在該項目中擴充使用 LogoDet-3K 數據集,核心思路是複用項目已有的訓練框架,但需要針對 LogoDet-3K 的數據格式和規模,補充 / 調整 數據準備階段的步驟(標註轉換、數據集劃分),並微調訓練參數。
該項目的 train.py 是基於 YOLOv7 通用訓練邏輯編寫的,其訓練邏輯不綁定特定數據集(Flickr Logos 27 或 LogoDet-3K),僅依賴 符合 YOLOv7 格式的數據集目錄結構 和 數據集配置文件(.yaml)。只要保證 LogoDet-3K 最終處理後的數據格式與 Flickr Logos 27 一致(即 YOLOv7 要求的格式),train.py 即可直接複用,無需修改訓練函數本身。
src/convert_annotations.py和src/prepare_data.py,預留了將logodet3k轉化為yolov7格式訓練數據的接口。(詳情見附錄代碼詳細分析)
因此,基於項目預留的接口和現有代碼邏輯,要切換到 LogoDet-3K 訓練,核心是處理數據衝突 + 確保配置對齊 + 微調訓練參數,無需大幅修改核心腳本。
一、第一步:處理「舊數據衝突」
由於我已經訓練過Flickr Logos 27,data/ 目錄下已存在 images/ 和 annotations/(對應 27 類數據)。如果直接運行 LogoDet-3K 的數據劃分,新舊數據會混合覆蓋,導致訓練出錯。因此必須先清理 / 備份舊數據:
備份舊數據(推薦,後續可回退)
# 備份 Flickr 27 的數據
mkdir -p data/backup_flickr27
mv data/images data/backup_flickr27/
mv data/annotations data/backup_flickr27/
mv data/labels data/backup_flickr27/ # labels 是 annotations 的副本,也需備份二、第二步:確認「LogoDet-3K 標註轉換」正確
1. 方案1:使用原腳本src/convert_annotations.py
項目預留了 --dataset logodet3k 接口,但需先驗證 標註轉換結果是否正確(否則訓練會出現「類別不匹配」或「無目標檢測」問題):
1.1. 執行標註轉換命令
將 LogoDet-3K 原始數據(圖片 + 標註)按項目預期路徑存放,即data/LogoDet-3k,運行:
# 轉換 LogoDet-3K 標註為 YOLOv7 格式(.txt)
python src/convert_annotations.py --dataset logodet3k
# 可選:可視化驗證(隨機抽查10張圖,確認邊界框和類別是否正確)
python src/convert_annotations.py --dataset logodet3k --plot1.2. 關鍵檢查點
標註文件格式:檢查 data/logodet3k/annotations/ 下是否生成了與圖片同名的 .txt 文件,內容是否符合 YOLO 格式
5 0.32 0.45 0.18 0.22 # [類別ID] [x_center] [y_center] [寬] [高](均歸一化)
12 0.65 0.78 0.21 0.19類別 ID 映射:確保 .txt 中的「類別 ID」與你 logo_data.yaml 中「names 列表的順序」完全一致(例如:ID=0 對應 names [0] = "tachipirina",ID=1 對應 names [1] = "thomapyrin",以此類推)。

