
目錄
Abstract
Introduction
Related Work
Methodology and the Bit-Flip-Spark+Chain-of-Reasoning Format
Preprocessing and Dataset Construction
Fine-tuning and Inference Pipeline
Evaluation
Discussion and Future Work
Abstract
生成新穎且富有創意的科學假設,是實現通用人工智能的核心基石。大型語言與推理模型有望助力系統化地創建、篩選和驗證基於科學依據的假設。然而,當前的基礎模型往往難以產出既新穎又可行的科學構想。其中一個原因,便是缺乏專門的數據集,無法將科學假設生成(SHG)任務視作自然語言生成(NLG)任務來處理。
為此,本文首次提出了HypoGen素材集——該數據集涵蓋約5500組結構化的問題-假設配對,均摘自頂級計算機科學會議,並採用“比特翻轉-靈感火花”框架進行組織:其中,“比特”代表傳統假設,“靈感火花”則是核心洞見或概念性飛躍,而“翻轉”則指由此產生的反向提案。HypoGen的獨特之處在於,它明確融入了鏈式推理環節,完整呈現了從“比特”到“翻轉”的思維過程。
我們證明,將假設生成問題轉化為條件語言建模任務,並在“比特-翻轉-靈感火花”及鏈式推理框架上對模型進行微調(且在推理階段僅給出“比特”信息),能夠顯著提升所生成假設的整體質量。我們的評估辦法結合了自動化指標與大模型評委的排名,以全面衡量假設的質量。實驗結果表明,通過在HypoGen數據集上進行微調,我們實用提升了所生成假設的新穎性、可行性以及整體質量。目前,HypoGen數據集已公開發佈於Hugging Face平台:
huggingface.co/datasets/UniverseTBD/hypogen-dr1
Introduction
大多數研究工作都指出了當前模型在應用於開放性研究問題時的侷限性,尤其是在生成新穎、富有創意、多樣化、可行、可操作、有趣且有用的想法或假設方面存在不足。
大型語言模型在應用於科學構思時面臨重大挑戰。這些模型容易出現幻覺現象,由於其基於標記概率最大化的目標,常常生成不實內容。此外,基於概率最大化的解碼策略(如貪婪搜索或高束搜索)可能導致生成的文本缺乏詞彙多樣性,這一問題即便在擁有數千億參數的模型中依然存在。
為了有效,科學假設不僅應該基於對當前領域廣泛理解而產生的創造性洞察力,還必須紮根於現有文獻,以確保其新穎性和相關性。此外,自動判斷某一想法在文獻中已存在的程度頗具難度,這一點尤為棘手,因為大型語言模型在生成內容時往往傾向於複製其訓練數據中的子集。鑑於驗證是科學方法的核心環節,大型語言模型的“黑箱”特性要求我們採取審慎而細緻的手段,以確保其結果具有可重複性和穩健性。
為應對這些挑戰,我們提出 HypoGen,一個包含約5500個結構化難題-假設配對的數據集,這些配對均摘自頂級計算機科學會議。該內容集標誌着將科學假設生成建模為條件語言建模問題的重要一步。通過將假設條件化為對問題的清晰表述(即 位)
HypoGen 包含一個詳細的推理鏈一種敍事,它映射了人類科學家從傳統智慧邁向創新性反向提案的迭代與反思過程,從而提升所生成假設的質量與可信度。
我們的主要貢獻包括開發了 HypoGen 材料集,以及將科學假設生成新穎地構想為一種帶有顯式推理鏈的條件語言建模問題。我們展示了基於LLaMA的模型在經過針對假設生成任務微調後,在該任務上的基準性能指標。 HypoGen材料集。我們採用了一種簡潔的評估框架,從新穎性和可行性兩個維度對假設進行評價,並結合自動化指標與大模型(LLM)的判斷。經過捕捉完整的推理鏈條,我們的方法能夠深入揭示科學發現背後的思想過程,提供寶貴見解。
Related Work
幾種手段將決策過程分解為多個子階段。
在提案階段,通常會運用推理,有時還會結合檢索,以生成候選行動或假設。
隨後,在評估階段,系統會對這些候選方案進行打分(例如,採用困惑度指標[Ahn等,2022]或學習到的獎勵函數[Yao等,2020]),從而篩選出最具潛力的方案。
此外,像ToT(Yao等,2023)和RAP(Hao等,2023)這樣的技術,更是通過樹狀搜索範式,以結構化的方式同時提出並評估多種解決方案路徑。而Shinn等(2023)和Lindes & Peter(2023)提出的反思性方法,則明確引入了對假設行動的迭代自我修正機制。周等(2024a)的研究進一步擴展了這一流程,利用迭代強化學習,並結合人類反饋,達成了更高效的科學假設生成。
這些進展凸顯了構建基準測試的重要性,這些基準需真實反映大型語言模型在生成、驗證及優化科學假設方面的能力。
然而,目前仍缺乏專門針對智能體AI環境的假設生成能力進行評估的標準化“前沿”基準測試,尤其是考慮到這類系統依賴高度互聯的模塊,應該艱難的推理能力。
HypoGen特別強調“推理鏈”:每個假設都附帶一條透明的溯因邏輯路徑,完整還原了人類專家的思維過程。我們的方法採用了一種結構化的“位翻轉-火花+推理鏈”格式,清晰地展現了從初始問題陳述(Bit)到關鍵洞察(Spark),再到最終完善構想(Flip)的概念演進脈絡。通過融入詳盡的推理鏈條,HypoGen有效降低了幻覺風險,同時為研究人員提供了一份可重複的、逐步展示新想法誕生過程的筆記本式文檔。
Methodology and the Bit-Flip-Spark+Chain-of-Reasoning Format
圖1展示了HypoGen 1的整體流程,該流程旨在利用Bit-Flip-Spark+推理鏈格式,從科學論文中提取結構化信息。
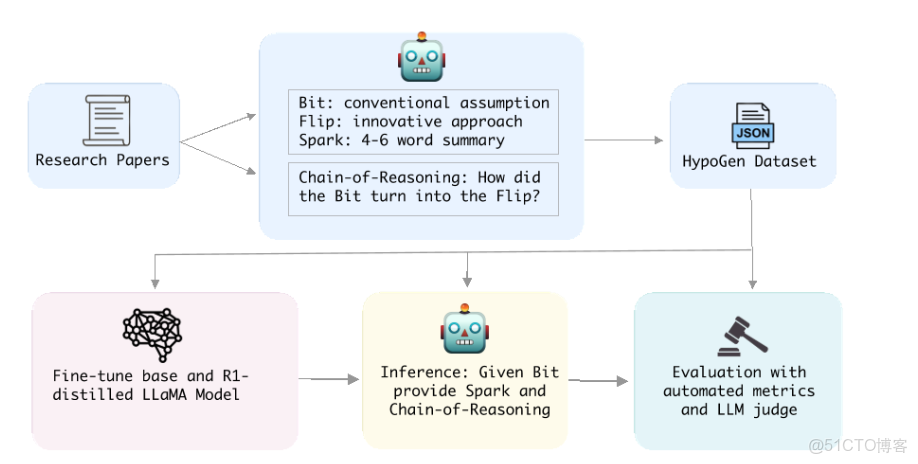
圖1:HypoGen流程始於輸入的論文摘要,OpenAI的o1模型從中提取出結構化的“Bit”(障礙)、“Flip”(解決方案)和“Spark”(關鍵洞察)。論文主體內容則由o1模型提煉出推理鏈條。這些輸出結果被用於微調基於LLaMA的模型,隨後該模型根據提供的“Bit”生成假設。最後,由Claude 3.7 Sonnet構成的評審模塊,依據假設的新穎性和可行性對其整體質量進行評估。
斯坦福大學的Bit-Flip框架2是一種簡潔而規範的假設提出技能,專門用於概括研究論文的核心學術貢獻。其中,“Bit”指出了當前研究領域中被論文試圖挑戰的主流觀點或假設;而“Flip”則清晰地闡述了論文為推動學科發展所提出的創新方法或反駁論點。此外,我們還引入了一個全新概念——“Spark”,它精準捕捉了“思想的精髓”,並以一種概念性飛躍的形式加以呈現。我們在附錄A中提供了來自Bahdanau等人(2015年)的一個示例,以及生成這一表述所需的完整提示內容。
眾多選擇之一,但我們發現,它非常適用於根據特定問題(即Bit)生成相應的解決方案(即Flip)。結果,推理鏈以詳盡的敍述形式,完整記錄了科學家從發現困難到提出解決方案的整個思維過程,巧妙地將Bit與Flip緊密相連。就是目標是將論文中複雜的思想提煉為一種簡潔而嚴謹的表述,從而清晰地傳達所要解決的問題(Flip)以及提出的解決方案(Bit)。這種方法立足於這樣的認知:一個表達清晰的假設,正是推動研究產生深遠影響的基石。儘管這種結構化的假設呈現方式帶有一定主觀性,且僅
Bit:傳統神經機器翻譯將整個源句子編碼為一個固定長度的單一向量。然而,這種方法存在瓶頸——關鍵的上下文信息可能在壓縮過程中丟失。
Spark:通過軟對齊實現靈活翻譯。
Flip:我們提出了一種創新思路,使模型能夠在每個解碼步驟中自動尋找源句子中與當前目標詞最相關的部分。這種機制摒棄了對單一固定長度表示的依賴,轉而採用一種動態聚焦於重要源信息的軟對齊機制,從而顯著提升了翻譯的質量與靈活性。
Chain-of-Reasoning:我先思考到,傳統神經機器翻譯通常依賴於一個固定長度的單一向量來編碼整個源句子,之後再生成目標序列;但這種僵化的瓶頸可能導致重要上下文信息的流失,進而限制了翻譯的質量與靈活性。因此,我開始質疑,是否需要一種更動態的方式來捕捉上下文線索,尤其是在處理較長序列時。為此,我引入了一種可學習的(軟)搜索機制,使目標詞能夠動態地與源句子中最相關的內容相匹配,徹底擺脱了固定長度編碼的束縛,從而更加靈活地關注上下文,最終生成質量更高的譯文。我還基於大規模雙語語料庫訓練了一個雙向編碼器-解碼器模型,選用三萬個詞彙的詞表,並藉助小批量梯度方法進行優化,同時測試了不同大小的隱藏層結構。那麼,我們如何驗證新方式確實能準確識別出正確的對齊關係呢?我通過可視化對齊權重發現,解碼器能夠有選擇地聚焦於源句中的關鍵詞彙,顯著提升了譯文的清晰度與準確性。隨後,我又進一步探討了如何應對未知或罕見詞彙的困難,這促使我深入研究更多提升詞彙覆蓋率的策略。正是在某個關鍵時刻,我意識到軟注意力機制能夠實用保留短文本和長文本輸入中的核心細節,確保翻譯質量的穩定提升。最後,我在獨立的測試集上驗證了模型的表現,結果表明,該模型不僅媲美甚至超越了基於短語的基準體系,而且在處理長句時依然表現出卓越的穩健性。這一整合式的推理過程,成功彌合了傳統方法的侷限性與動態對齊理念之間的差距,為建立更具上下文感知能力的神經翻譯工藝鋪平了道路。
Preprocessing and Dataset Construction
我們從被頂級計算機科學會議NeurIPS 2023(3218篇論文)和ICLR 2024(2260篇論文)錄用的論文中整理出數據集,最終得到5478個獨特樣本。隨後,我們使用了OpenAI的 o1 用於結構化提取步驟的模型。對於每篇論文,我們先提取出 位,翻轉,和 Spark 來自抽象的組件。我們進行了提示 o1識別傳統假設、創新方法,以及核心洞察的精煉4至6字概括。隨後,我們採用了一種穩健的並行處理辦法,並內置重試機制,每次提取最多嘗試三次,以確保輸出的高質量。
Fine-tuning and Inference Pipeline
我們的基線模型包括Meta LLaMA 3.1 8B和R1精煉版LLaMA 3.1 8B。這些模型在包含128,000個標記的廣泛語料庫上進行訓練,並採用字節對編碼進行標記化處理。(森裏奇等人, 2015; 工藤與理查森, 2018),包含一個128,000個標記的詞彙表。R1精煉版的LLaMA 3.1 8B模型是一種專門化模型,其知識源自參數規模達6710億的更大規模DeepSeek-R1模型。這一大規模預訓練賦予了模型強大的語言理解能力,這對於科學假設的生成至關重要。
我們利用精心構建的結構化挑戰-假設配對數據集進行微調,並採用因果語言建模目標。整個過程使用了4塊NVIDIA H100 GPU,每塊配備80GB顯存。此外,我們實施了4位量化技巧,並部署了LoRA模型。(胡等人, 2021) 帶有超參數: α = 16 以及0.1的丟棄率。模型以4位精度進行基礎加載,並根據需要採用適當的計算精度(在支持的情況下使用bf16,否則使用fp16)。我們還採用了8位的AdamW優化器。(洛什奇洛夫 & 胡特, 2017) 具有0.01的權重衰減、32的批量大小以及2的學習率 × 10−4. 訓練過程採用線性學習率調度器,包含5個預熱步,總訓練步數約為60步,並在每一步進行日誌記錄。在推理階段,僅使用 位 被給出給模型。隨後,模型生成相應的 Spark 以及一份詳細的 推理鏈. 我們使用 Ollama 用於LLaMA單次推理的LLM框架。
Evaluation
評估專為生成科學假設而設計的生成模型是一項充滿挑戰的任務,緣於科學研究本身具有高度的主觀性。在本文中,大家提出了一種雙層評估框架,主要結合了傳統的自動化指標與基於大語言模型的評判器。
我們的評估策略依託於一個由50個假設組成的測試集,這些假設均摘自2024年和2025年近期發表的文獻。該框架將自動化指標與一個LLM評判模塊相結合,通過兩兩比較的方式,從新穎性、可行性及整體質量等方面對假設進行綜合評估。此外,我們還使用第二個LLM評判器進一步驗證了這一方法的穩健性。對於評估集中的部分樣本,我們還採用了人工評估,以檢驗在HypoGen內容集上微調LLaMA-base模型是否能有效提升生成假設的質量。
作為初步評估指標,我們採用了困惑度(Perplexity),用於衡量所生成假設的流暢性和連貫性(Chen et al., 1998)。困惑度被定義為給定標記序列X的負對數似然平均值的指數函數。
IAScore用於量化LLM生成的假設與專家提出的研究思路之間的契合度。對於每篇論文j,IAScore通過IdeaMatcher(IM)模型(Kumar等,2024),計算作者提出的未來研究思路(AP-FRIj)與每項生成想法Iij之間的平均契合度:
隨後,針對整個領域的模型M,IAScore通過將所有P篇論文的得分取平均來計算:
Kumar等人(2024)之所以選用GPT作為IdeaMatcher,正是因為它在判斷生成的想法是否包含於作者提案中的表現更為出色——準確率達到91.8%,遠超基於RoBERTa MNLI和BERTScore的自然語言推理方法。因此,較高的IAScore值表明LLM生成的想法與作者視角在整個領域內具有更強的一致性。
此外,Idea Distinctiveness Index則通過嵌入式相似度而非表面文本差異,評估所生成假設之間的語義多樣性。具體而言,對於一組想法I,每個想法idi都會被轉換為向量vi,方法是利用預訓練的BERT模型(Kumar等,2024)。其中,idi與idj之間的區分度定義為Dij = 1 − sim(vi, vj),而sim表示餘弦相似度。最終,整組n個想法的整體區分度計算公式如下:
為了衡量模型在特定領域內的表現,我們可針對模型M為每篇論文p生成的所有想法,分別計算其Idea Distinctness Index DIpM,再對全部m篇論文的結果取平均值:
較高的Ddomain,M值意味着更高的想法多樣性,反映出該模型能夠在領域內生成語義各異的研究假設的能力。
為了評估我們評測集中的假設質量,我們採用了Anthropic的Claude 3.7 Sonnet-Thinking模型作為自動化評估工具。在每個資料集中,我們對50道題目進行了兩兩對比評估:每項評估實驗均由兩個大語言模型分別生成的一組配對解決方案構成。我們共設計了九個實驗,具體包括:LLaMA 3.1-8B-FT(簡稱為LLaMA-8B-FT)與人類的對比;LLaMA 3.1-8B-FT(LLaMA-8B-FT)與單樣本o1模型的對比;隨後是R1精餾版LLaMA-3.1-8B-FT(R1-distilled-LlaMA-FT)與人類、以及與o1-1shot的對比;LLaMA-8B-FT與R1精餾版LLaMA-8B-FT的對比;人類與o1-1shot的對比;R1精餾版LLaMA-8B-1shot與R1精餾版LLaMA-8B-FT的對比;LLaMA-8B-1shot與LLaMA-8B-FT的對比;以及LLaMA-8B-1shot與R1精餾版LLaMA-8B-1shot(R1-distilled-LlaMA-1shot)的對比。我們的實驗結果如圖2所示。其中,人類生成的假設即為基於評測集生成的o1結構化假設。
對於每個問題,LLM評估器被要求判斷哪一種方案(Spark + 鏈式推理)在新穎性和可行性方面提供了更優的整體建議。
我們隨機調整解決方案的呈現順序,以減少順序效應。每次評估實驗結束後,我們會記錄方案A在新穎性、可行性和整體表現上是否勝出,同時允許出現平局情況。此外,為了鼓勵深入思考,我們還為模型提供了8000個token的“思考”預算。
基於大語言模型的評估方法具備一致性和可擴展性,但同時也犧牲了穩健性和可驗證性。為應對這些挑戰,我們利用OpenAI的o3-mini模型作為裁判,重新進行了實驗分析,以檢驗兩者的意見一致性程度。此外,我們還開展了盲法的人工評估,由一位作者對20組假設進行逐一評判。完整的提示內容請參見附錄A。
自動化指標表1的結果顯示,人類生成的假設困惑度值遠高於其對應的大型語言模型(LLM)版本。尤其是,LLaMA基礎模型的困惑度介於16.70到34.98之間,而人類生成的假設則高達89.31。這可能表明,人類生成的想法中藴含着更強的語義創造力。儘管整體困惑度仍較低,但經過微調後,LLaMA模型的困惑度得分有所上升,反映出其在構思階段表現出更高的“不可預測性”。
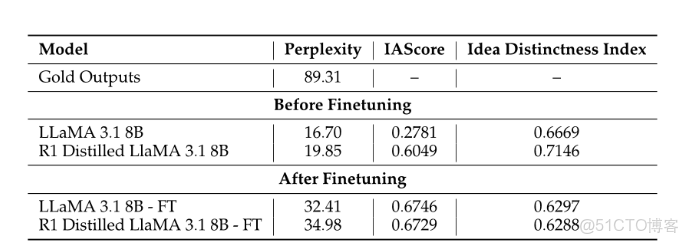
觀點與源材料的一致性,而觀點獨特性指數則用於量化生成假設的獨特性。就是表1:比較不同模型輸出的自動化評估指標。IAScore衡量的
其次,微調顯著提升了模型與目標領域的契合度,這種效果在經過蒸餾處理的LLaMA模型中並不明顯,這可能暗示了知識遷移機制的有效性。就是,這一點從標準LLaMA模型的IAScore大幅提高(從0.2781提升至0.6746)可見一斑。這一結果或許意味着,通過結構化的Bit-Flip-Spark+Chain-of-Reasoning訓練方法,模型能夠生成更貼近專家級科學思維的假設。值得注意的
此外,IAScore的提升與Idea Distinctness Index的下降之間存在明顯的反比關係——尤其在R1蒸餾版LLaMA模型中,該指數從0.7146顯著降至0.6288。這一現象表明,模型在更好地貼合專家級科學思維模式的同時,可能會犧牲一定的語義多樣性,從而導致輸出內容的差異化程度降低。
如圖2上半部分所示,LLM評委的兩兩比較結果顯示,儘管微調版本在新穎性評分上有所下降,但其整體假設質量卻始終優於同架構的一次性生成版本(偏好率高達86%-92%),這充分説明,在HypoGen數據集上的微調訓練有效地引導模型生成更具實用價值的假設。
最後,LLM評估的第二組實驗進一步揭示了不同實驗中新穎性與可行性之間的權衡關係:那些在創造性指標上表現突出的模型,往往在可行性方面稍顯不足;反之亦然。總體而言,由人類生成的假設在質量評估中全面勝出,佔據了80%到90%的比較優勢;然而,經過微調的模型則展現出與之相當的可行性評分。
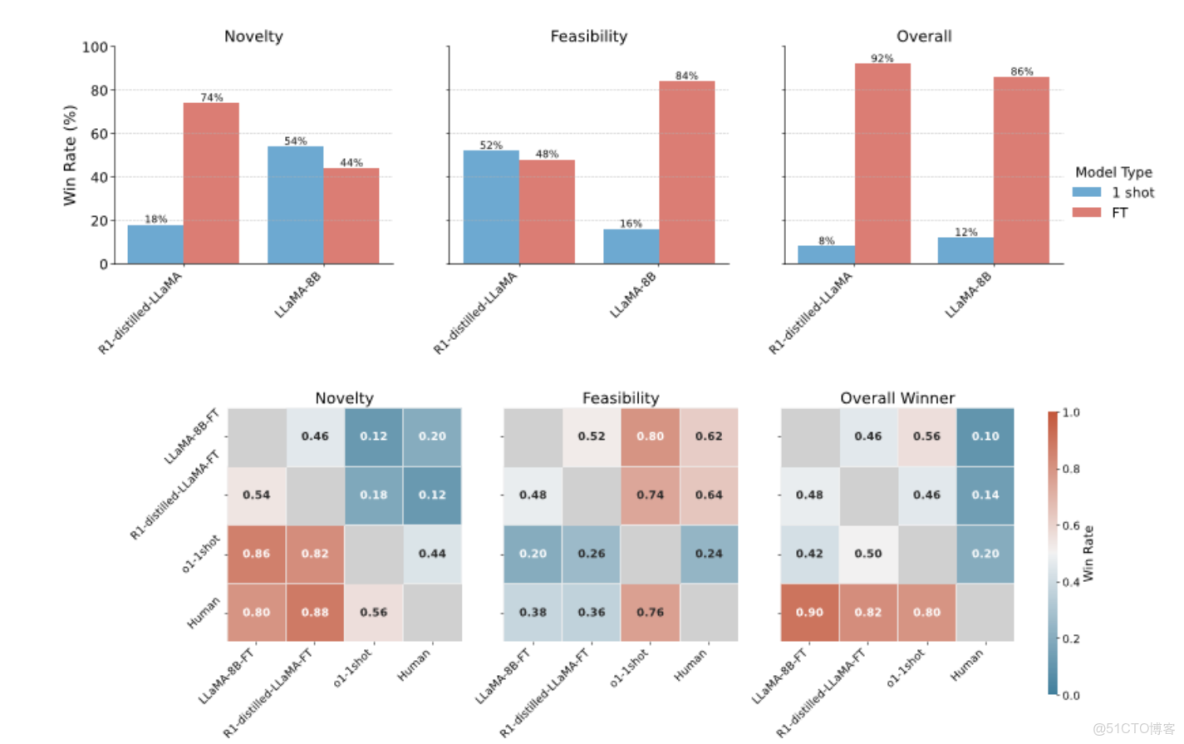
圖2:由LLM評測員Claude 3.7 Sonnet對九個實驗中生成假設質量的對比分析。上圖:比較未微調與微調後的LLaMA 3.1-8B(LlaMA-8B-FT)及R1精餾版LLaMA-3.1-8B(R1-distilled-8B-FT)模型在新穎性和可行性上的勝率,顯示了兩者之間的一致權衡——微調模型在可行性方面表現更佳(勝率74%-86%),而未微調版本則更具新穎性(勝率54%-86%)。下圖:展示了人類專家、微調模型(LLaMA-8B-FT、R1-FT)以及單次提示模型(O1-1shot、LLaMA-8B-1shot、R1-1shot)在新穎性、可行性和整體質量三個維度上的兩兩勝率熱圖。其中,人類提出的假設穩居勝局(勝率82%-90%),而微調模型在可行性評分上與人類相當(62%-64% vs. 人類)。此外,微調模型在整體質量上優於其單次提示版本(勝率86%-92%)。
人類評估結果表明,小規模的人類評估驗證了Claude 3.7 Sonnet思維模型所觀察到的模式。在R1精餾版LLaMA的對比中,人類評估者更傾向於微調模型的輸出,認為其在新穎性(95% vs. 5%)和可行性(70% vs. 30%)方面表現更優,且總體上更偏好微調模型的輸出(微調模型偏好70%,平局25%,基礎模型僅5%)。而在標準LLaMA-8B的對比中,微調模型的表現略顯遜色,儘管仍保持一定的優勢:在新穎性方面,微調模型略佔上風(47.6% vs. 42.9%,9.5%為平局);在可行性方面,微調模型同樣佔據微弱優勢(52.4% vs. 42.9%,4.8%為平局),導致整體偏好度更為接近(微調模型42.9%,單次提示模型33.3%,平局23.8%)。這一評估結果進一步證實,基於結構化Bit-Flip-Spark+Chain-of-Reasoning數據進行微調確實能有效提升假設的質量,尤其在R1精餾架構中,這種提升尤為顯著。不過,目前仍需開展更多的人類評估工作以深入驗證這些發現。
Discussion and Future Work
我們推出了HypoGen數據集,用於生成科學假設。該材料集在傳統的Bit-Flip-Spark格式基礎上,新增了詳細的推理鏈組件。實驗表明,在HypoGen上進行微調後,LLaMA 3.1-8B和R1-distilled-LLaMA 3.1-8B模型的假設能力均得到了顯著提升。這充分證明了在創意構思的中間環節進行微調的有效性,能夠進一步增強模型的透明性與可解釋性。大家以MIT許可證發佈HypoGen,旨在推動人工智能代理的發展,使其能夠協助人類專家完成創意構思過程。
HypoGen的關鍵侷限在於,它採用大語言模型(LLM)來評估所生成的假設。儘管在特定條件下,以LLM為“裁判”的模塊表現穩健(Lu et al., 2024a),但其訓練方式仍可能以微妙而複雜的方式引入偏見。為緩解這些意想不到的影響,大家計劃開展大規模的人工評估,以明確人類與LLM在特定判斷上的一致程度。這些研究發現將指導我們構建更加穩健的獎勵模型,使其更貼近人類的專業知識,從而進一步提升HypoGen在現實世界科學發現中的應用價值。
展望未來,我們希望探索HypoGen方法如何推廣至其他科學領域。目前,我們的評估主要集中在計算機科學領域,但微調技術在一個領域的表現能否有效遷移到其他領域,仍是一個開放性障礙。此外,我們還計劃擴展內容集,涵蓋天體物理學、生物學和材料科學等領域,因為這些領域中的假設生成有望加速各具特色的科學突破。這項工作致力於打造跨學科的人工智能夥伴,與人類專家攜手應對極具挑戰性的科學任務(Swanson et al., 2024),最終目標是讓科學更加普惠大眾。





