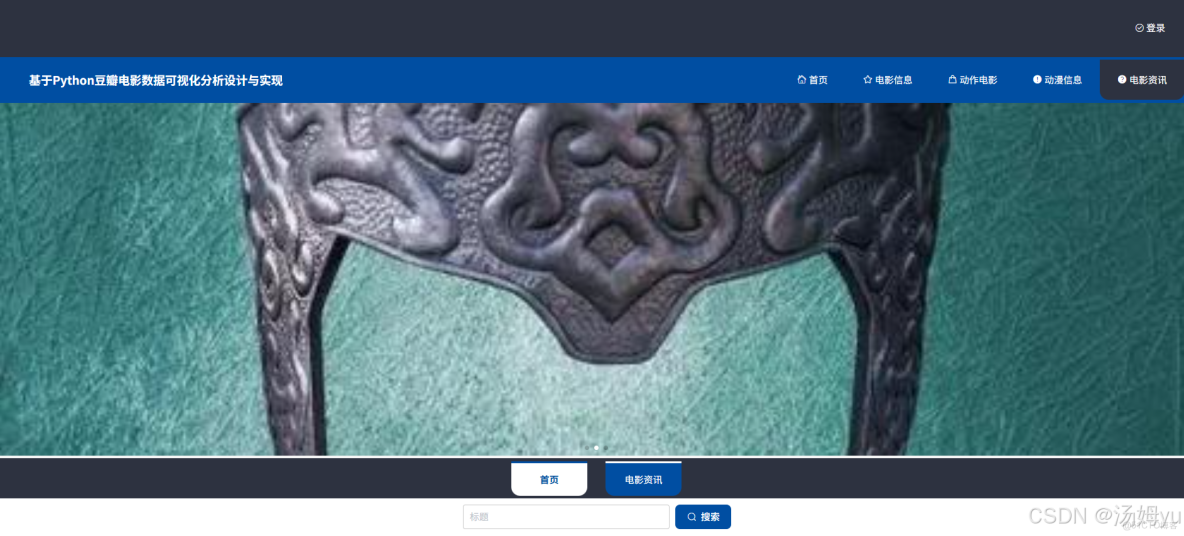
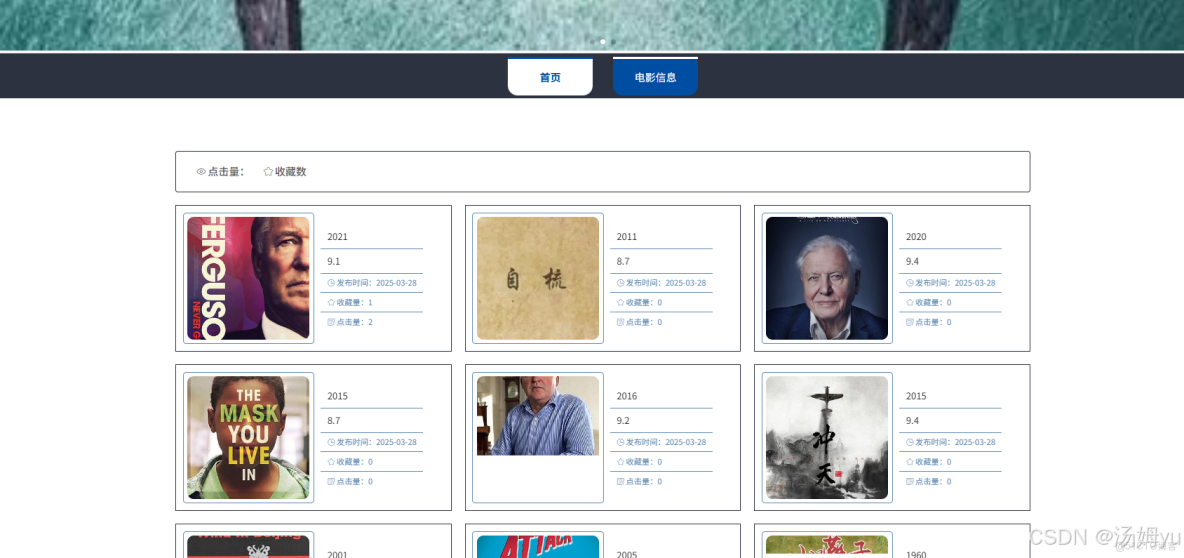
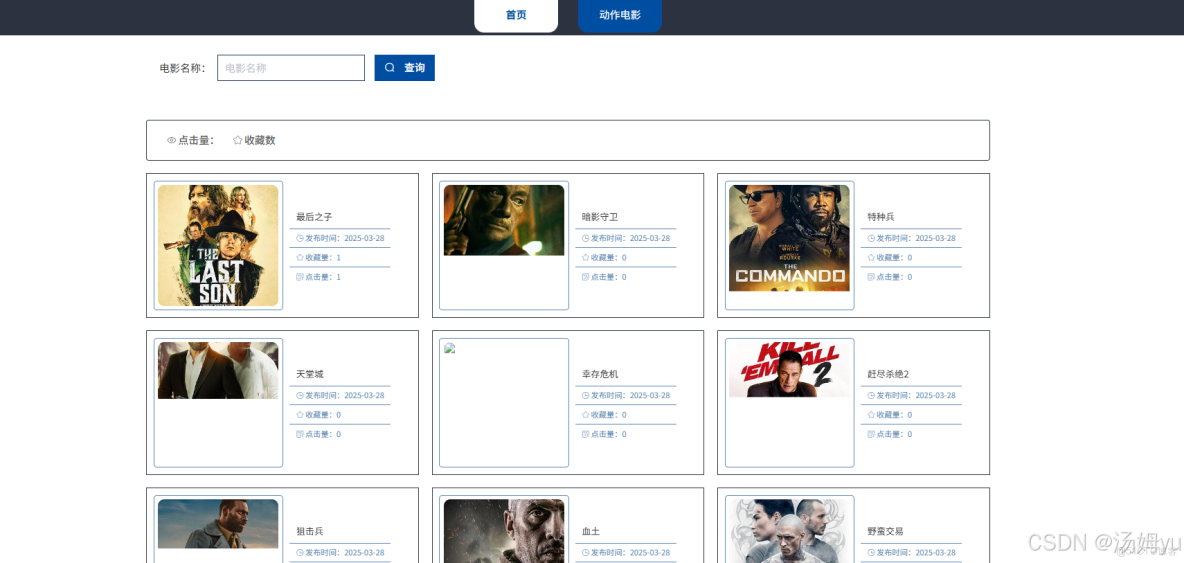
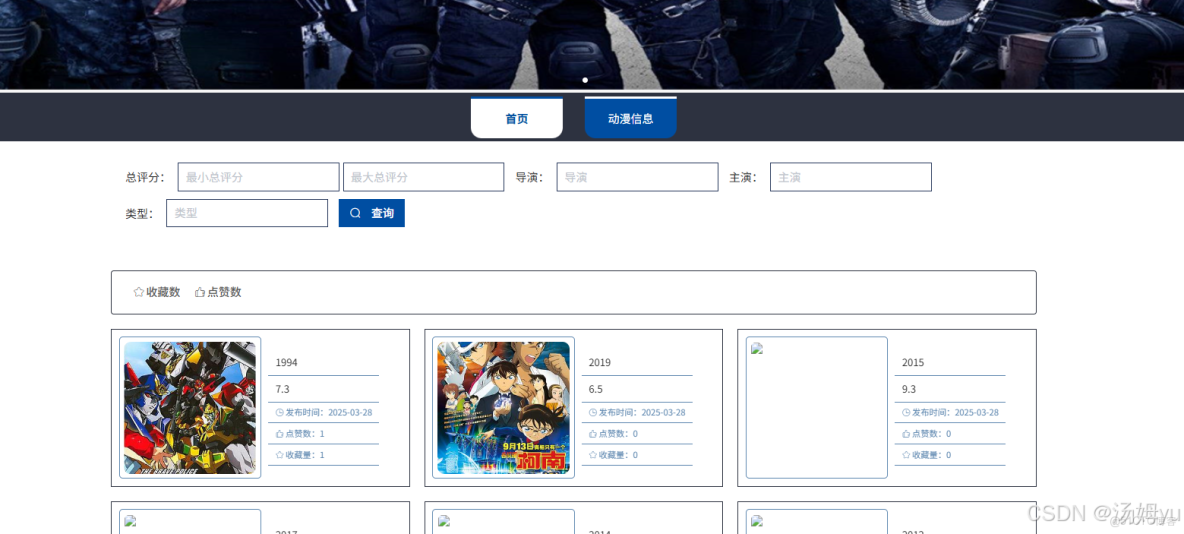
1、研究背景
在當今數字化時代,電影產業蓬勃發展,全球電影市場年票房收入持續增長。據統計,2023 年全球電影票房總收入達到數百億美元,電影數量也呈爆發式增長,每年有數千部電影在全球各大院線上映。然而,如此龐大的電影數據藴含着豐富的信息,但缺乏有效的分析手段,使得電影從業者、投資者和觀眾難以從中獲取有價值的知識。傳統的電影分析方法主要依賴人工統計和簡單圖表展示,效率低下且難以挖掘數據背後的深層次規律。例如,電影製片方在策劃新項目時,需要了解不同類型電影的市場表現、觀眾偏好以及票房與成本之間的關係,但僅靠傳統方法很難全面準確地獲取這些信息。此外,觀眾在眾多電影中選擇觀影時,也缺乏直觀的方式瞭解電影的質量、口碑和熱度。Python 作為一種功能強大且易於使用的編程語言,在大數據處理和可視化領域具有顯著優勢。它擁有豐富的庫和框架,如 Pandas 用於數據清洗和預處理,NumPy 用於數值計算,Matplotlib 和 Seaborn 用於數據可視化,Scikit - learn 用於機器學習分析等。這些工具能夠幫助我們高效地處理海量的電影數據,並通過可視化手段直觀地展示分析結果。基於 Python 大數據的電影分析可視化系統應運而生。該系統可以整合來自多個渠道的電影數據,包括票房數據、觀眾評分、社交媒體討論熱度、電影類型、導演和演員信息等。通過對這些數據進行深入分析,電影從業者可以更好地把握市場趨勢,制定更精準的營銷策略;投資者可以根據電影的歷史表現和潛在市場價值做出更明智的投資決策;觀眾也能通過可視化展示更直觀地瞭解電影的綜合情況,從而做出更合適的觀影選擇。
2、研究意義
在電影產業競爭日益激烈的當下,科學決策至關重要。基於 Python 大數據的電影分析可視化系統能夠整合多源數據,涵蓋票房、口碑、受眾羣體等多維度信息。電影製片方藉助該系統,可精準把握不同類型電影的市場表現,分析觀眾對特定題材、風格電影的偏好趨勢,從而在選題策劃階段做出更貼合市場需求的決策,降低投資風險。發行方能依據系統對不同地區、不同時段電影市場熱度的分析,合理規劃影片發行策略,提高影片的上座率和票房收益。影院方則可根據系統對觀眾觀影習慣和消費偏好的分析,優化排片安排,提升資源利用效率,增加經營收入。
電影投資具有高風險性,投資者需要全面瞭解電影項目的潛在價值。該系統可以對電影的歷史數據、製作團隊過往成績、演員市場影響力等進行綜合分析,通過可視化圖表直觀展示電影項目的投資回報率、風險評估等關鍵指標。投資者能夠依據這些信息,對不同電影項目進行橫向和縱向比較,篩選出更具投資潛力的項目,做出更明智的投資決策,提高投資的成功率和收益率。
3、研究現狀
基於Python大數據的電影分析可視化系統研究在技術與案例層面均取得顯著進展。技術層面,系統多采用分層架構設計,以Scrapy、Requests等庫實現多源數據爬取,結合Pandas、NumPy進行數據清洗與特徵工程,處理缺失值、重複項及異常值,確保數據質量;利用MongoDB存儲非結構化數據,MySQL管理結構化數據,並通過Django、Flask框架搭建Web服務,實現前後端分離。可視化環節,Matplotlib、Seaborn用於靜態圖表繪製,Echarts、Plotly支持交互式動態展示,結合詞雲、熱力圖、雷達圖等多維度呈現票房趨勢、評分分佈、導演影響力等關鍵指標,部分系統還引入TensorFlow構建深度學習推薦模型,提升個性化推薦精度。
具體案例中,有系統從豆瓣、IMDb等平台爬取超10萬條電影元數據,涵蓋評分、票房、類型等28個字段,數據清洗後存儲至MongoDB與PostgreSQL,通過隨機森林算法構建評分預測模型,R²達0.87,優於線性迴歸;前端採用Flask+Echarts實現票房趨勢折線圖、導演影響力雷達圖等20餘種可視化視圖,用户可動態篩選數據。另有案例以國慶檔電影為切入點,爬取貓眼、豆瓣數據,結合SPSS進行多元線性迴歸,分析導演影響力、演員陣容、評分等10餘個因素對票房的顯著性影響,為檔期策略制定提供依據。此外,部分系統集成用户管理模塊,區分管理員與普通用户權限,支持數據增量更新與定期爬取,確保分析時效性。
4、研究技術
Python
Python是一種高級、動態類型的解釋型腳本語言,語法簡潔易讀,適合初學者入門,也為專業開發者提供強大功能。它擁有龐大社區和豐富第三方庫,如NumPy、Pandas、Matplotlib等,在數據分析、機器學習領域發揮關鍵作用。Python的跨平台性使其能在多操作系統運行,變量無需聲明即可直接賦值,支持條件語句、循環語句等控制結構,函數可接受輸入參數並返回結果。憑藉這些優勢,Python廣泛應用於Web開發、網絡爬蟲、自動化運維等多個領域,成為當今最受歡迎的編程語言之一。
Vue
Vue.js是流行的JavaScript框架,用於構建用户界面和單頁面應用。其核心特性包括響應式數據綁定,數據變化時視圖自動更新,無需手動操作DOM;組件化開發,將頁面拆分為可重用組件,提高開發效率與代碼複用性;簡單易學,API設計簡潔,學習曲線平緩;靈活性高,可逐漸引入到現有項目或與其他庫混合使用;生態系統豐富,有Vue Router用於路由管理、Vuex用於狀態管理等。Vue.js能輕鬆構建交互式用户界面,適合新手和有經驗開發者開發優秀Web應用。
MySQL
MySQL是流行的關係型數據庫管理系統,採用SQL語言管理和操作數據,以表格形式存儲,由行記錄和列字段組成。它具有高度可擴展性,支持多種存儲引擎,如InnoDB提供事務支持和行級鎖定,MyISAM查詢性能出色。MySQL應用場景廣泛,無論是小型項目還是大型企業級應用都能滿足需求。與Oracle相比,MySQL開源免費,對中小型應用更輕便靈活;和Microsoft SQL Server比,跨平台性更好;較PostgreSQL,處理大規模讀操作和簡單查詢表現更佳,且易用性高,是不同規模應用場景的可靠選擇。
Django
Django是用Python編寫的開源Web框架,旨在簡化Web應用開發流程。它具備快速開發、功能豐富、安全性高及支持大規模網站等特點。Django遵循MTV架構,內置ORM數據庫映射,讓開發者用Python類與數據庫交互,無需編寫SQL;強大的URL路由使用正則表達式靈活定義;模板引擎支持邏輯判斷、循環處理,方便渲染HTML頁面;提供自動化管理後台,簡單模型定義即可生成強大界面;還具備國際化支持、高安全性等優勢。適合內容管理系統、社交平台、電子商務網站等項目開發。
爬蟲技術
網絡爬蟲是按一定規則自動抓取萬維網信息的程序或腳本,可自動採集能訪問到的頁面內容,分為數據採集、處理、儲存三部分。按功能分有通用網絡爬蟲,目標數據是整個互聯網,常用於搜索引擎;聚焦網絡爬蟲,專注於某一主題,選擇性爬取匹配數據;增量式網絡爬蟲,對已爬取網頁增量更新,維持數據庫穩健實時;深層網絡爬蟲,可訪問隱藏在表單後無法直接獲取的頁面。網絡爬蟲在大數據時代作用重大,為人工智能、數據分析提供海量數據支撐,提高數據獲取效率。