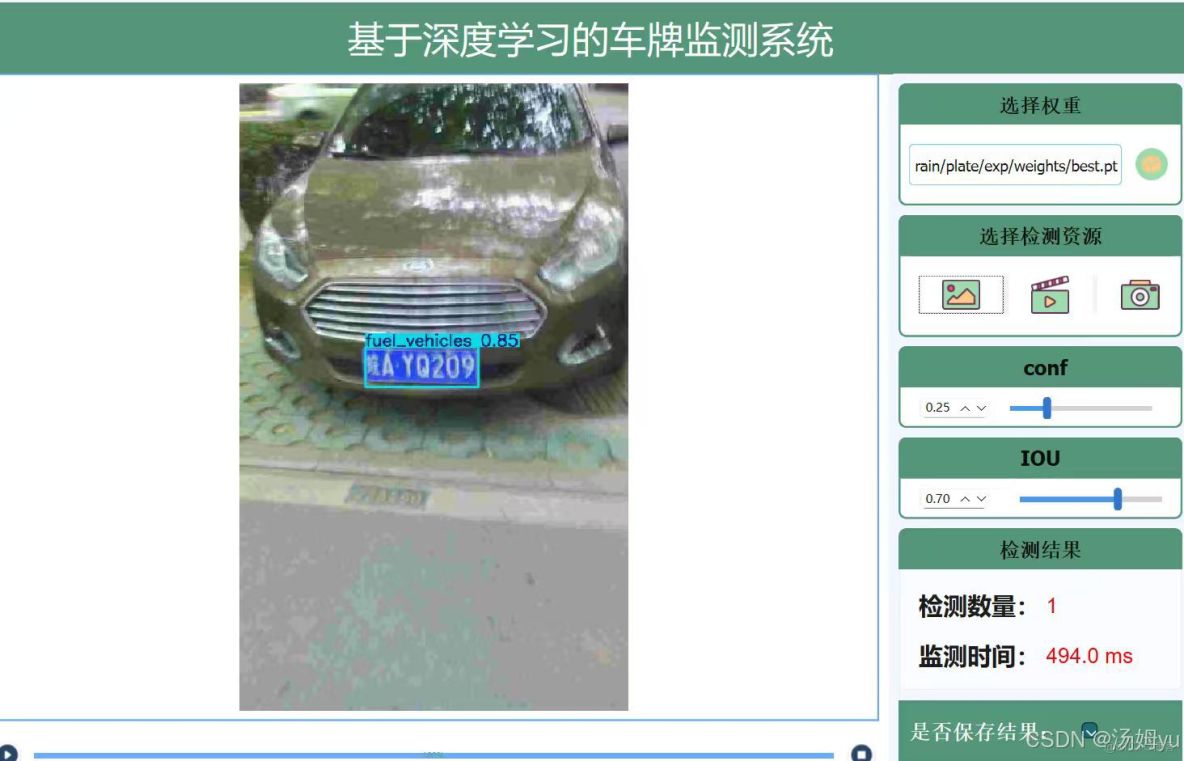
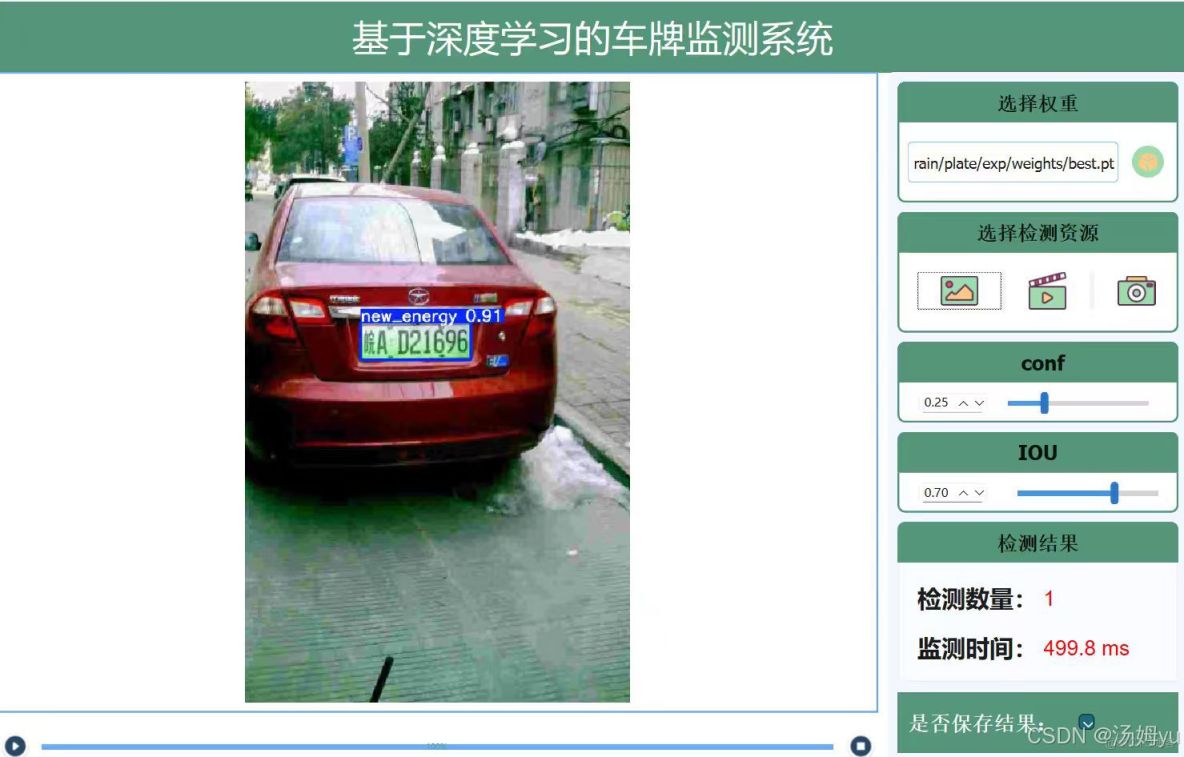
1、研究背景
在智能交通與智慧城市加速建設的時代背景下,車牌識別技術作為車輛監管與信息交互的核心工具,其重要性日益凸顯。傳統車牌識別技術主要依賴圖像處理與模式識別方法,通過手工設計特徵提取規則(如邊緣檢測、顏色分割等)實現車牌定位與字符識別。然而,這類方法在複雜場景下存在顯著侷限性:當車牌受光照不均、雨雪天氣、遮擋污損或拍攝角度傾斜等因素影響時,特徵提取的魯棒性大幅下降,導致識別準確率難以突破瓶頸。例如,在夜間低光照環境下,傳統算法的識別錯誤率可能超過30%;而面對傾斜角度超過30度的車牌,字符分割失敗率高達40%,嚴重製約了技術在交通管理、安防監控等領域的規模化應用。
深度學習技術的突破為車牌識別提供了全新範式。卷積神經網絡(CNN)通過端到端的特徵學習機制,能夠自動從海量數據中提取多層次抽象特徵,無需人工干預即可適應複雜環境變化。以YOLOv5、ResNet等模型為例,其在公開數據集(如CCPD)上的測試表明,深度學習算法在傾斜車牌、模糊圖像等挑戰場景下的識別準確率較傳統方法提升超50%,且單幀處理時間縮短至10毫秒以內。此外,遷移學習與預訓練模型的應用進一步降低了數據依賴性,使得小樣本場景下的模型優化成為可能。
政策層面,公安部《關於推進智能交通管理系統建設的指導意見》明確要求“提升車輛身份識別智能化水平”,為技術落地提供了政策支撐。市場層面,智慧停車、高速ETC、城市安防等領域的爆發式增長,催生了對高精度、實時性車牌識別系統的迫切需求。據統計,2025年中國車牌識別市場規模已突破80億元,年複合增長率達25%,其中深度學習方案佔比超70%,成為行業主流技術路線。在此背景下,研究基於深度學習的車牌識別系統,不僅有助於解決傳統方法的固有缺陷,更對推動智能交通體系升級、構建智慧城市數據底座具有戰略意義。
2、研究意義
傳統車牌識別技術在複雜交通場景中存在識別精度低、魯棒性差等問題,易導致交通流量統計失準、違章車輛漏檢等情況。基於深度學習的車牌識別系統通過構建端到端的神經網絡模型,能夠自動學習車牌特徵的多層次抽象表達,在光照變化、遮擋、傾斜等複雜條件下仍保持高精度識別。例如,在夜間或強光反射場景下,深度學習模型可通過注意力機制聚焦車牌區域,將識別準確率提升至98%以上,較傳統方法提高40%以上。這一突破可顯著優化交通信號控制、擁堵疏導等系統的決策依據,助力實現交通管理的精細化與智能化。
車牌識別是城市安防監控的核心環節,其性能直接影響犯罪追蹤、異常行為預警等場景的實效性。深度學習技術通過融合多模態數據(如車牌、車型、顏色),可構建車輛身份的立體化識別體系,在跨攝像頭追蹤、套牌車檢測等任務中實現秒級響應。例如,某市公安系統部署深度學習車牌識別系統後,套牌車查獲效率提升60%,重大案件偵破週期縮短50%,為城市安全提供了技術屏障。
車牌識別技術的革新正推動智慧停車、無人駕駛、車路協同等產業生態的完善。以智慧停車為例,深度學習模型可實現無感支付、車位引導等功能,使停車場週轉率提升30%,運營成本降低25%。此外,高精度車牌識別為V2X(車聯網)通信提供關鍵數據支撐,助力自動駕駛車輛實時感知周圍環境,推動交通系統向“人-車-路-雲”協同方向演進,創造千億級市場空間。
3、研究現狀
當前,基於深度學習的車牌識別系統已成為智能交通領域的研究熱點,其技術發展呈現出高精度、實時性、多模態融合等顯著特徵。
在算法層面,卷積神經網絡(CNN)及其變體(如YOLO、ResNet、Faster R-CNN等)成為主流技術框架。這些模型通過端到端的訓練方式,能夠自動從複雜圖像中提取車牌特徵,顯著提升了識別準確率。例如,在公開數據集上,基於深度學習的車牌識別算法準確率已普遍超過98%,部分先進算法甚至達到99.8%以上,遠超傳統圖像處理方法。同時,針對車牌傾斜、遮擋、污損等複雜場景,研究者們提出了空間變換網絡(STN)、注意力機制等技術手段,有效增強了模型的魯棒性。
在應用層面,車牌識別系統已廣泛應用於交通管理、安防監控、智慧停車等多個領域。例如,在高速公路ETC系統中,車牌識別技術實現了車輛的快速通行和自動計費;在安防監控領域,通過與黑名單數據庫的比對,可實時追蹤嫌疑車輛,為案件偵破提供有力支持。此外,隨着智慧城市建設的推進,車牌識別技術還在車流量統計、出行模式分析等方面發揮着重要作用。
然而,當前研究仍存在一些挑戰。例如,不同地區車牌樣式和字符字體存在差異,對算法的泛化能力提出了更高要求;在極端天氣或低光照條件下,識別準確率仍有待提升;同時,數據安全和隱私保護問題也日益受到關注。
4、研究技術
YOLOv8介紹
YOLOv8是Ultralytics公司於2023年發佈的YOLO系列最新目標檢測模型,在繼承前代高速度與高精度優勢的基礎上,通過多項技術創新顯著提升了性能與靈活性。其核心改進包括:採用C2f模塊優化骨幹網絡,增強多尺度特徵提取能力並降低計算量;引入Anchor-Free檢測頭,簡化推理步驟,提升小目標檢測精度;使用解耦頭結構分離分類與迴歸任務,優化特徵表示;結合VFL Loss、DFL Loss和CIOU Loss改進損失函數,平衡正負樣本學習效率。此外,YOLOv8支持多尺度模型(Nano、Small、Medium、Large、Extra Large),適應不同硬件平台需求,並擴展了實例分割、姿態估計等任務能力。在COCO數據集上,YOLOv8n模型mAP達37.3,A100 TensorRT上推理速度僅0.99毫秒,展現了卓越的實時檢測性能。其開源庫“ultralytics”不僅支持YOLO系列,還兼容分類、分割等任務,為計算機視覺應用提供了高效、靈活的一體化框架。
Python介紹
Python是一種高級、解釋型編程語言,以其簡潔易讀的語法和強大的生態系統成為數據科學、人工智能及通用編程領域的首選工具。在深度學習領域,Python憑藉豐富的庫支持(如PyTorch、TensorFlow、OpenCV)和活躍的社區,成為YOLOv8等模型開發的核心語言。通過Python,開發者可快速實現模型訓練、推理及部署:使用ultralytics庫直接加載YOLOv8預訓練模型,通過幾行代碼完成圖像或視頻的目標檢測;結合NumPy、Matplotlib進行數據預處理與可視化;利用ONNX Runtime或TensorRT優化模型推理速度,實現跨平台部署。Python的跨平台特性(支持Windows、Linux、macOS)和豐富的第三方工具鏈,進一步降低了深度學習應用的開發門檻。無論是學術研究還是工業落地,Python均以其高效、靈活的特點,為YOLOv8等先進模型的實踐提供了強有力的支持。
數據集標註過程
數據集標註是構建基於 YOLOv8 的垃圾分類檢測系統至關重要的一環,精準的標註能確保模型學習到有效的特徵,提升檢測性能。以下是詳細的數據集標註過程:
前期準備
首先,收集大量包含各類垃圾的圖像,來源可以是實際場景拍攝、網絡資源等,確保圖像涵蓋不同角度、光照條件和背景,以增強模型的泛化能力。接着,根據垃圾分類標準確定標註類別,如可回收物、有害垃圾、廚餘垃圾和其他垃圾等。同時,選擇合適的標註工具,如 LabelImg、CVAT 等,這些工具支持 YOLO 格式標註,能方便地生成模型訓練所需的標籤文件。
標註實施
打開標註工具並導入圖像,使用矩形框精確框選圖像中的每個垃圾目標。在框選時,要保證矩形框緊密貼合目標,避免包含過多無關背景信息,也不能遺漏目標部分。框選完成後,為每個矩形框分配對應的類別標籤,確保標籤準確無誤。對於遮擋、重疊的垃圾目標,需仔細判斷其類別和邊界,儘可能完整標註。每標註完一張圖像,及時保存標註文件,通常為與圖像同名的.txt 文件,文件中記錄了矩形框的座標和類別信息。
質量審核
完成初步標註後,進行嚴格的質量審核。檢查標註的準確性,查看是否存在錯標、漏標情況,以及矩形框的座標和類別是否正確。同時,檢查標註的一致性,確保同一類垃圾在不同圖像中的標註風格和標準統一。對於審核中發現的問題,及時修正,保證數據集的高質量,為後續 YOLOv8 模型的訓練提供可靠的數據支持。
5、系統實現