
前言:
在數字化轉型浪潮中,企業數據分析決策的時效性與準確性已成為競爭勝負的關鍵。隨着“Data + AI”融合加深,ChatBI 產品爆發式增長。但在當前市場中,大多數 ChatBI 產品依賴大模型直接生成 SQL 的技術路徑(NL2SQL),普遍面臨“大模型幻覺”導致的數據不可信問題——模型可能生成與事實不符、計算邏輯矛盾、口徑不一致甚至完全虛構的數據結果,直接影響分析決策質量。
痛點直擊:“大模型幻覺”導致數據不可信
眾所周知,“大模型幻覺”是生成式 AI 的固有缺陷,在企業數據分析決策場景中如果缺乏可信的數據基礎,則會引發數據準確性不可靠、決策方向誤導、協作效率下降等問題。
比如,當用户查詢“近七天的訂單數”時,大模型生成的 SQL 可能直接對訂單金額進行聚合計算,看似正確,但可能不符合企業對訂單數的標準定義(如剔除刷單或測試訂單)。再比如,某生產製造企業依賴 AI 生成的財報分析,因模型虛構收入指標,導致其錯誤擴大生產規模,最終形成庫存積壓,或者某對衝基金因 AI 算法錯誤判斷市場趨勢,造成單日超千萬的損失等。
究其根本,在於 NL2SQL 方案的侷限性。目前市面上主流的 NL2SQL 方案是直接將自然語言映射為 SQL,依賴表結構與字段名的精確匹配。當表結構變更或業務語義複雜時(如“OEE 指標需跨多表計算”),模型極易生成錯誤 SQL,且難以追溯問題根源。
技術路徑對比:NL2SQL vs NL2MQL2SQL 的本質差異
1、NL2SQL:基於物理表的“概率生成”
大模型直接解析用户問題,嘗試從物理表結構中生成 SQL。但物理表本身不具備業務語義,導致很多信息是無法讓大模型很好地理解的。例如,用户通過 ChatBI 提問“幫我分析華北區銷售額”,模型需要先識別表名 sales_region、字段名 region 和 amount,並拼接為 SELECT amount FROM sales_region WHERE region='華北'。這一過程中,大模型能否精準鎖定正確的物理表,並給出準確的數據就成了一個“概率性事件”。
與此同時,物理表結構一旦變更,便會導致 SQL 失效,需要重新訓練模型。同一指標在不同場景下,也可能存在着不同的計算邏輯(如“銷售額”是否含税),NL2SQL 技術路徑則難以統一管理,無法保障數據和業務語義對齊。此外,業務規則變化時,用户還需要手動調整所有相關 SQL 語句,直接帶來更高的維護成本。
2、NL2MQL2SQL:基於指標語義層的“確定性構建”
這一技術路徑則為 Aloudata Agent 分析決策智能體獨創且跑通。首先,大模型精準解析用户意圖,識別原子化數據要素,如指標、維度、篩選條件、時間範圍;隨後,再通過 NoETL 指標語義層將要素拼接為 MQL(Metrics Query Language),明確指標計算邏輯與業務口徑;最後,通過語義引擎將 MQL 轉化為 100% 準確的 SQL,並支持跨表動態查詢。
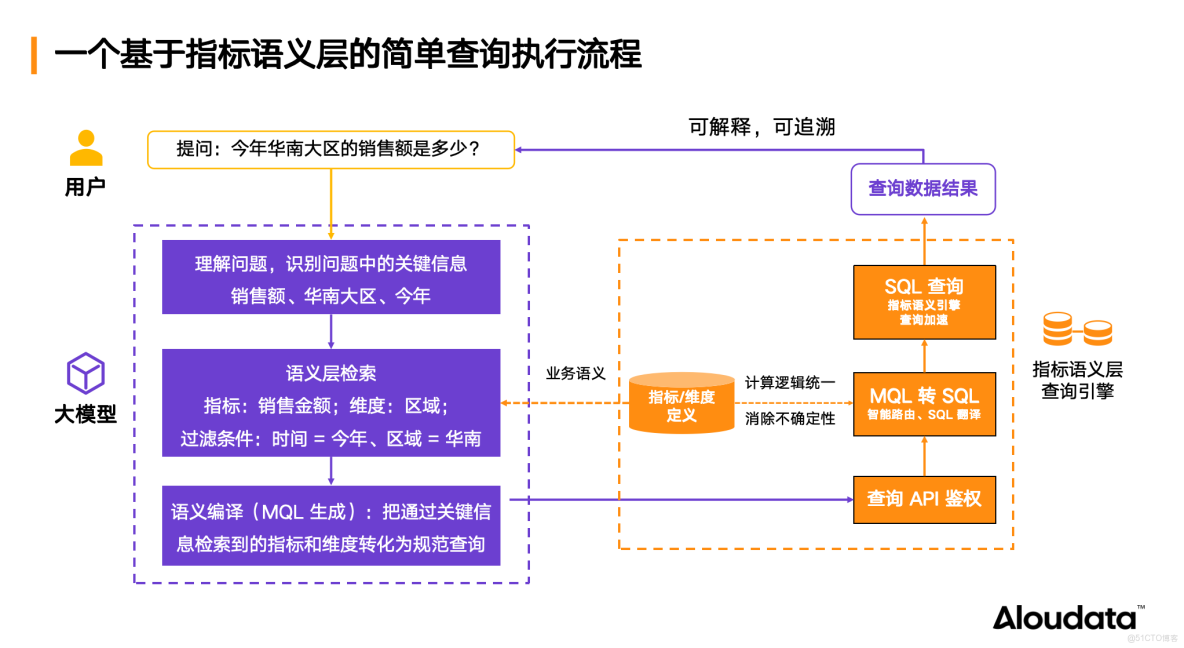
相較於 NL2SQL 技術路徑,NL2MQL2SQL 則實現了業務語義與物理表結構分離,表結構變更不影響查詢邏輯;同時指標計算邏輯在 NoETL 指標語義層明確定義,實現口徑的一致性,避免了“同名不同義”“同義不同名”的問題。此外,該路徑還支持多維度、多層次歸因分析,讓用户無需預定義複雜報表。
核心突破:NoETL 指標語義層如何確保 SQL 生成 100% 準確?
Aloudata Agent 分析決策智能體所依賴的 NoETL 指標語義層是保障 SQL 生成 100% 準確性的“數據引擎”,其設計包含三大核心機制:
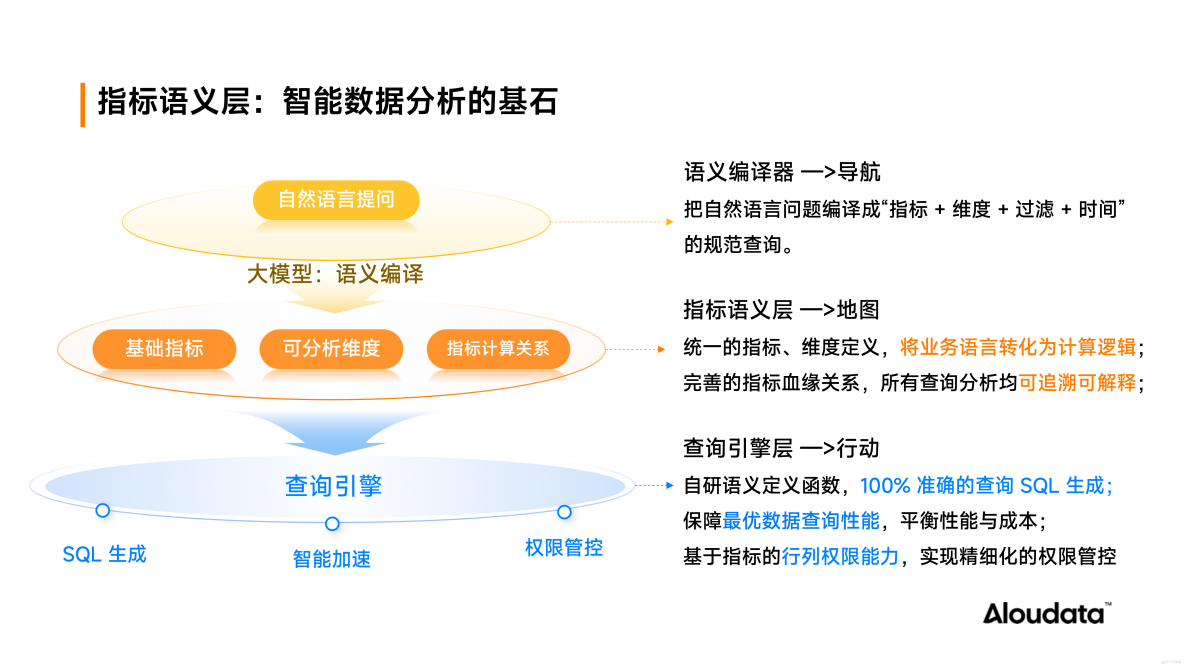
1、統一的指標語義定義:將混亂的數據轉化成唯一標準的指標
基於強大的邏輯模型和語義函數,將混亂的數據轉化成標準的指標定義,實現業務語言與 SQL 的映射。
- 強大的語義數據模型:NoETL 指標語義層支持一對一、一對多以及複雜的多角色關聯場景。例如,在電商場景中,一個用户可以同時是買家和賣家兩種身份,意味着訂單事實表中的買家 ID 和賣家 ID 要同時和客户維表中的用户 ID 進行關聯。
- 豐富的指標語義函數:NoETL 指標語義層提供 100+ 指標語義函數(日期類、文本類、聚合函數、窗口函數、邏輯函數、運算符、分析函數等),並封裝成配置化模板,任意指標皆可零代碼方式實現邏輯化定義和標準化管理。
2、動態 SQL 組裝:基於指標要素動態組裝出正確的 SQL
用户提問時,問題會映射到 NoETL 指標語義層中最原子化的要素,即詢問的指標和維度。隨後,NoETL 指標語義層將這些原子化要素 100% 準確的翻譯成 SQL,這涉及 NoETL 指標語義層中查詢元素的結構與 SQL Query 結構對齊。例如,SQL 中的 WHERE 對應指標元數據的業務限定,GROUP BY 對應分析維度等。
3、結果的可解釋性:一鍵查看結果背後的業務含義與計算邏輯
對於查詢結果,確保業務人員可以判斷與驗證數據準確性至關重要,即結果的可解釋性。傳統 NL2SQL 模式下,業務人員看不懂 SQL,無法判斷結果是否可信。NL2MQL2SQL 模式下采取兩個措施:一是透明化查詢過程,向用户展示大模型的思考過程和計算方式,且以業務人員能理解的查詢指標和維度呈現;二是展示指標的詳細業務口徑、計算邏輯和血緣,使用户能以業務語言判斷數據準確性,確保每次查詢結果可解釋、可驗證。若數據與設想不符,用户還可進行干預和調整。
綜上,Aloudata Agent 之所以能夠確保數據分析決策場景 SQL 生成 100% 準確,關鍵在於 NoETL 指標語義層的引入,將智能問數從“概率遊戲”拉回到“工程科學”。它不否定大模型的價值,而是為其劃定邊界——讓大模型做它最擅長的事(理解語言、歸納總結),而將準確性、一致性、安全性交給確定性的軟件工程體系,真正實現“自助式、敏捷化、可解釋”的 AI 數據分析決策。