

在人工智能迅猛發展的今天,大型語言模型已成為解決各類問題的強大工具。但當您想要打造一個真正理解所在行業、掌握專業知識的大模型時,總會面臨一個關鍵問題:如何用最小的成本、最高的效率,讓通用模型變得"專業"?
這就像把一位通才培養成領域專家——選對方法,事半功倍。這正是LLaMA-Factory Online要解決的核心問題——通過智能化的微調,讓每個團隊都能輕鬆駕馭大模型適配技術。
從頭訓練一個大模型成本極高,無論是時間、數據還是計算資源,對大多數團隊來説都不現實。這就引出了模型適配的核心價值:利用預訓練模型的基礎能力,高效地將其適配到特定領域。
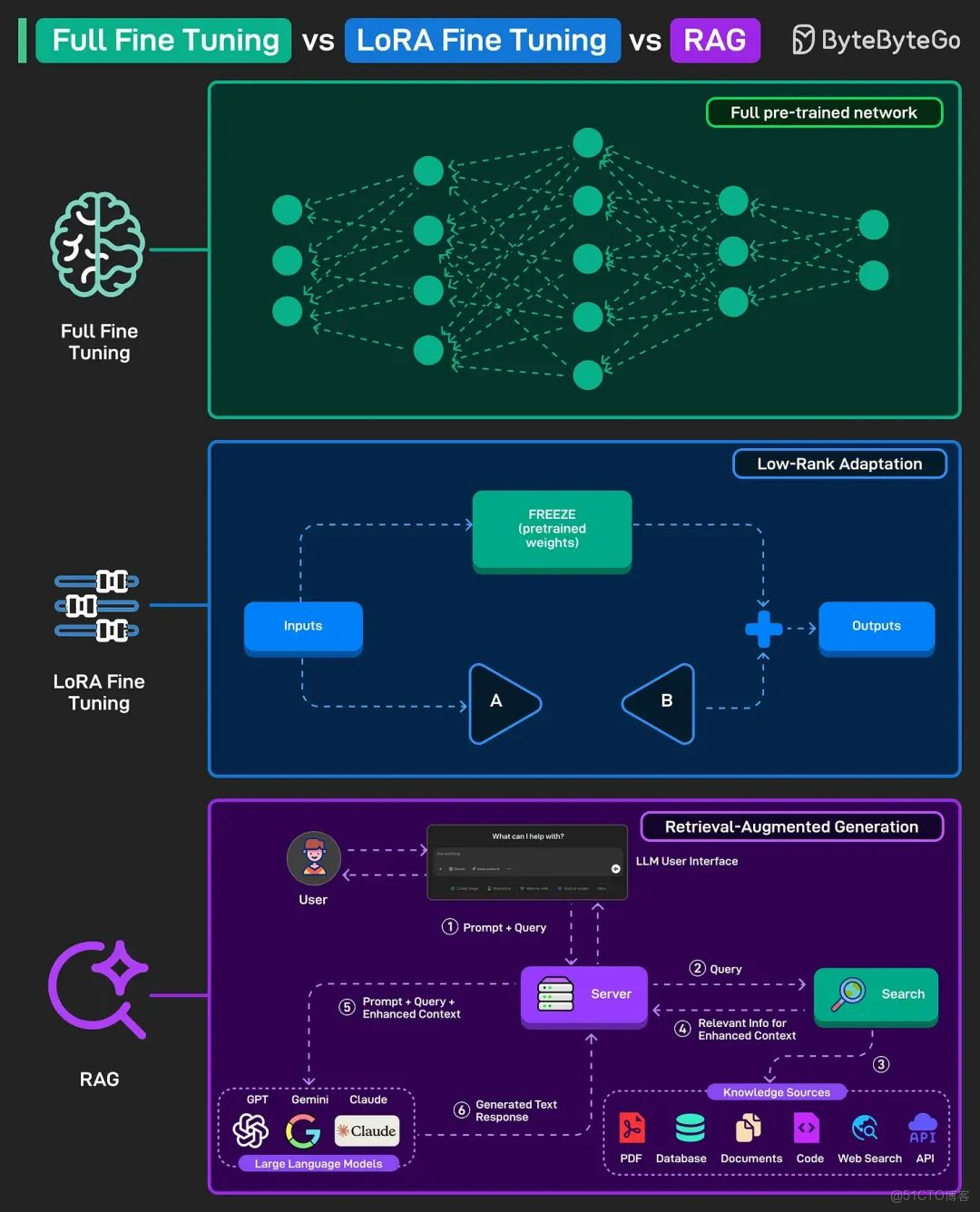
想象一下,您有一個醫學博士背景的員工,現在需要他成為神經外科專家。您有三種選擇:
● 全參數微調:讓他回醫學院重新學習,重塑整個知識體系
● LoRA微調:為他提供專業的神經外科手冊和培訓,保持核心知識不變
●RAG:讓他在遇到問題時查閲最新的醫學文獻和病例數據庫
不同的選擇意味着不同的投入和效果,這就是技術選型的本質。
快速自測:你真的需要微調嗎?
在深入技術細節前,先做個快速自查:
|
需求場景 |
推薦方案 |
核心原因 |
|
需要處理專業領域數據(醫療、法律、金融等)
|
考慮微調
|
通用模型對專業術語理解有限
|
|
希望模型以特定風格響應
|
建議微調
|
改變模型的"説話方式"和響應風格
|
|
需要處理內部文檔、最新信息
|
優先RAG
|
無需訓練,實時更新知識
|
|
計算資源有限
|
LoRA或RAG
|
低成本解決方案,快速見效
|
|
需要快速上線驗證
|
RAG先行
|
幾天內即可部署驗證效果
|
如果以上有多項符合你的情況,請繼續往下看。
三大適配技術深度解析
1. 全參數微調:深度改造的"專家培養"
適用場景:追求極致性能、資源充足的核心業務場景,如高精度醫療診斷、金融風控等
核心概念:在特定領域數據集上,重新訓練預訓練模型的所有參數,讓通用模型徹底轉變為領域專家
工作原理:
# 使用LLaMA-Factory進行全參數微調
llamafactory train \
--model_name_or_path llama-7b \
--data_path medical_data.json \
--output_dir ./medical_expert \
--finetuning_type full \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--learning_rate 5e-5優勢亮點:
● 性能最佳:所有參數都針對任務優化,效果最好
● 部署簡單:單個模型,開箱即用
● 能力全面:深度掌握領域知識
需要注意:
● 資源消耗大:需要多張高性能GPU
● 訓練時間長:通常需要數天時間
● 存儲成本高:每個任務都要保存完整模型
2. LoRA微調:輕量高效的"技能插件"
適用場景:資源有限的個人開發者、小團隊,需要快速迭代多個定製版本
核心概念:凍結預訓練模型參數,只訓練注入的小型低秩適配器,用極少的參數實現高效適配
工作原理:
# 使用LLaMA-Factory進行LoRA微調
llamafactory train \
--model_name_or_path llama-7b \
--data_path legal_finetune.json \
--output_dir ./legal_lora \
--finetuning_type lora \
--lora_rank 8 \
--lora_alpha 16 \
--target_modules q_proj,v_proj \
--num_train_epochs 3 \
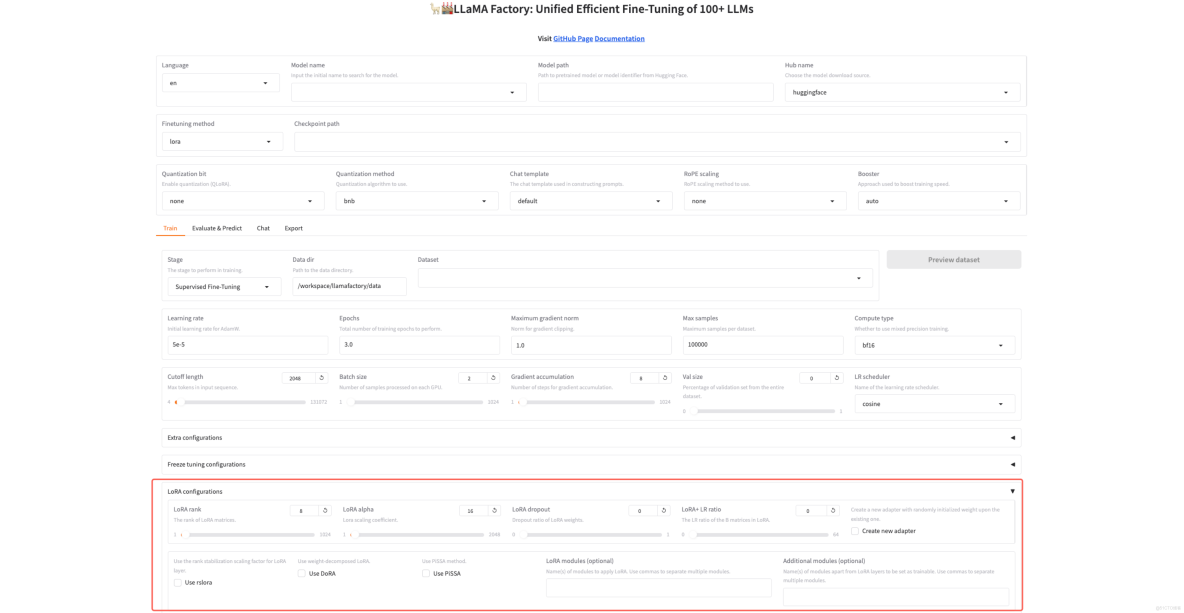
--per_device_train_batch_size 8Web界面操作更簡單:
# 在LLaMA-Factory Web界面中配置LoRA
lora_config = {
"r": 8, # 秩:控制參數規模
"lora_alpha": 16, # 縮放參數
"target_modules": [ # 目標註意力層
"q_proj", "v_proj",
"k_proj", "o_proj"
],
"task_type": "CAUSAL_LM"
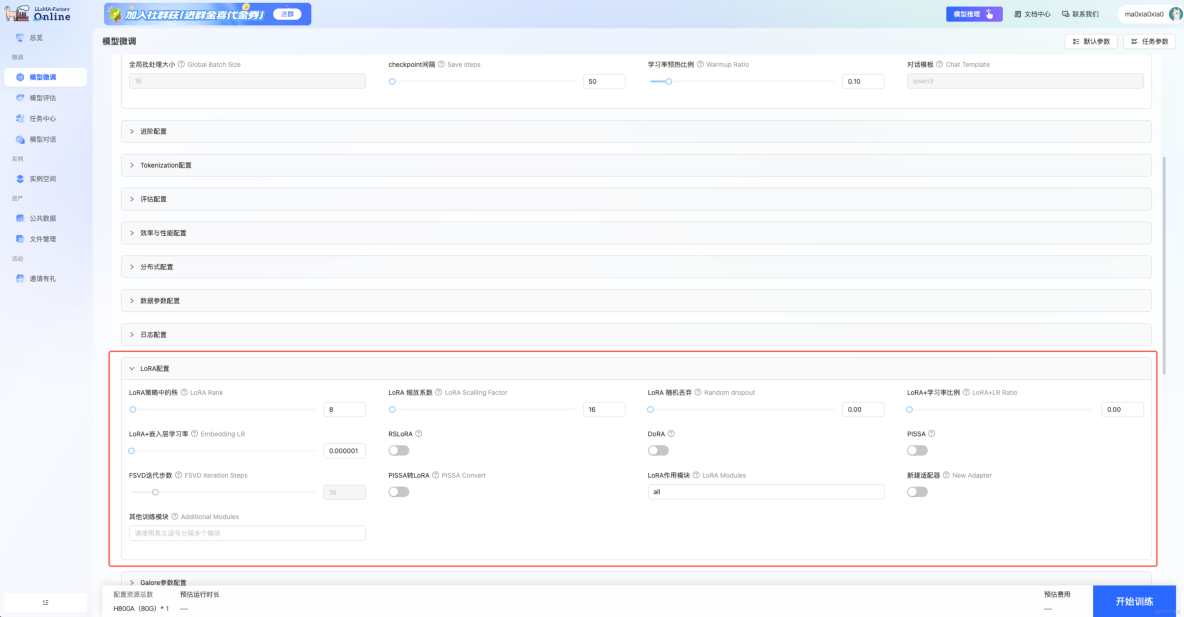
}LLaMA-Factory Online實例模式-LLaMA Factory原生web UI:
LLaMA-Factory Online任務模式:
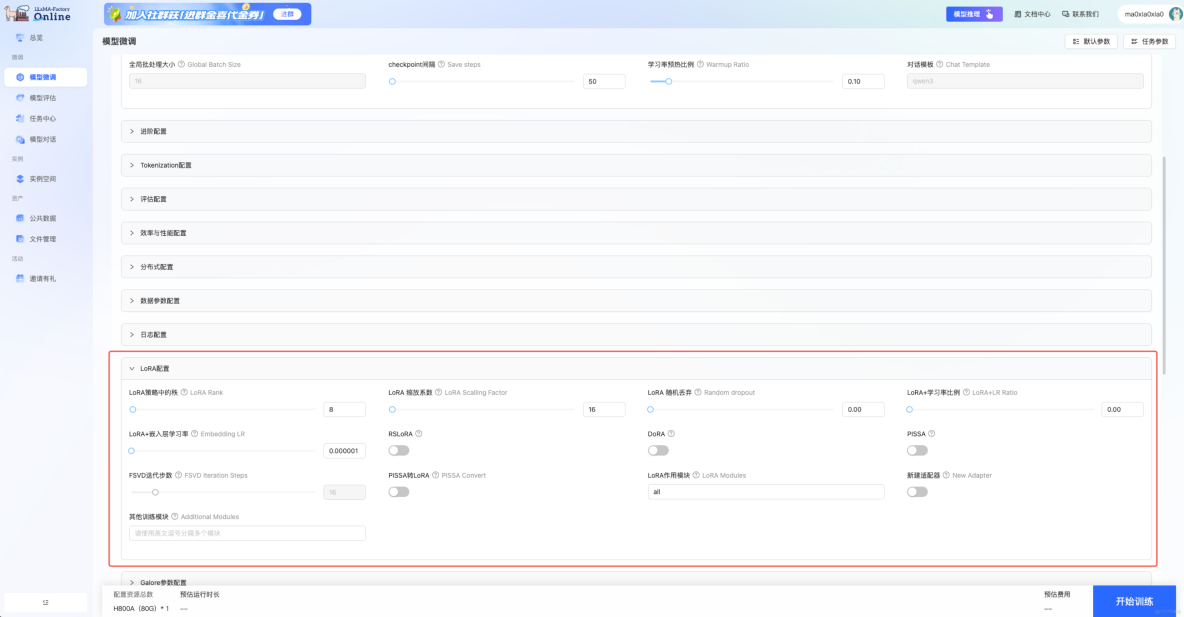
優勢亮點:
● 訓練飛快:比全參數微調快10倍以上
● 成本極低:單張消費級GPU即可完成
● 體積小巧:適配器權重僅幾MB到幾百MB
● 靈活切換:一個基礎模型,多個技能插件
需要注意:
● 性能略低:複雜任務可能稍遜於全參數微調
3. RAG:實時更新的"外掛知識庫"
適用場景:需要處理最新信息、內部文檔,且對答案溯源性要求高的場景
核心概念:不修改模型本身,通過檢索外部知識庫增強模型回答的準確性和時效性
工作流程:
1.用户提問:比如"2025 年最新的糖尿病治療指南是什麼?"
2.實時檢索:系統把問題轉成查詢詞,在知識庫中搜索最相關的指南內容
3.增強提示:把檢索到的內容片段和原始問題拼接成增強提示
4.生成答案:把增強提示發給 LLM,模型結合內部知識和外部信息輸出準確回答
優勢亮點:
● 無需訓練:立即部署使用
● 知識實時更新:修改文檔即可更新知識
● 答案可溯源:每個回答都有依據來源
● 減少幻覺:基於事實數據,準確性更高
需要注意:
● 依賴檢索質量:檢索準確性直接影響回答質量
● 推理成本稍高:提示詞更長,計算量更大
技術選型指南
核心維度對比
|
對比維度 |
全參數微調 |
LoRA 微調 |
RAG |
|
核心思想
|
重塑模型(通才變專才)
|
給模型加插件(輕量適配)
|
配外掛知識庫(實時補信息)
|
|
是否改權重
|
✅全部參數更新
|
✅僅新增適配器
|
❌模型不變
|
|
資源消耗
|
🔴極高(GPU集羣+海量數據)
|
🟢低(消費級GPU+少量數據)
|
🟢極低(僅需檢索系統)
|
|
輸出質量
|
🟢可能最高
|
🟢接近全微調
|
🟡依賴檢索質量
|
|
知識更新
|
🟢靜態(截止訓練數據)
|
🟢靜態(截止訓練數據)
|
🟡動態(實時更新)
|
|
部署複雜度
|
🟡 中等(獨立模型)
|
🟢 低(模型+小適配器)
|
🔴 高(整套檢索系統)
|
資源規劃參考
|
方案 |
GPU需求 |
時間成本 |
數據要求 |
適合團隊 |
|
RAG
|
無訓練需求
|
1-3天部署
|
結構化文檔
|
所有團隊
|
|
LoRA
|
單卡(24GB)
|
1-3天
|
數千條數據
|
中小團隊
|
|
全參數
|
多卡(4×80GB)
|
1-2周
|
數萬條數據
|
大型團隊
|
場景化建議
綜上,技術選型的核心在於精準匹配自身的數據特徵、資源條件和業務需求。沒有放之四海皆準的"最優解",只有在特定場景下的"最適合解"。
● 個人開發者/初創公司:優先考慮LoRA+RAG組合。用RAG快速搭建知識庫,同時通過LoRA低成本地優化模型在特定任務上的表現。這種組合成本低、效果明顯,特別適合在資源受限情況下快速迭代和驗證想法。
● 企業級應用:根據數據類型選擇,非結構化文檔處理可啓用RAG,技能和風格適配用LoRA,而對性能有極致要求的核心業務場景可考慮全參數微調。建議建立評估體系,並基於ROI做出決策。
● 科研機構/極致性能追求者:在資源允許的情況下可考慮全參數微調,但要注意評估邊際收益。事實上,通常"RAG+LoRA"的組合已經能夠滿足90%以上的場景需求,既能保證知識時效性,又能實現專業領域的深度適配。
混合策略:1+1>2 的效果
在實際工業應用中,混合使用多種技術往往能取得最佳效果。
案例一:智能客服系統
# 第一步:使用LoRA微調客服風格
llamafactory train \
--model_name_or_path llama-7b \
--data_path customer_service_style.json \
--finetuning_type lora \
--output_dir ./service_lora
# 第二步:結合RAG接入產品文檔
# 實現風格統一+知識準確的智能客服● 使用RAG:接入產品文檔、更新日誌、常見問題
● 使用LoRA:訓練客服回答風格、問題分類
● 案例效果:既保證信息準確,又優化用户體驗
案例二:法律諮詢助手
● 使用全參數微調:深度學習法律條文和判例
● 配合RAG:接入最新法律修訂和司法解釋
● 案例效果:專業準確,實時更新
未來趨勢展望
技術發展正沿着四個關鍵方向快速演進:QLoRA優化讓大模型微調門檻顯著降低,70B模型現可在單張24GB顯卡完成微調;自動化工具如LLaMA-Factory持續簡化操作流程;智能RAG從簡單檢索升級為具備推理能力的檢索增強;多模態適配正突破文本界限,實現文本、圖像、語音的統一微調。
結語
為了增強大模型在特定領域的能力,選擇技術方案如同選擇交通工具,RAG如同租車服務,隨用隨取,靈活便捷;LoRA好似高鐵,以出色性價比覆蓋大多數需求;全參數微調則像專機,體驗極致但成本高昂。基於當前技術成熟度與性價比,我們建議大多數團隊從LoRA起步,它在效果、成本和靈活性之間取得了最佳平衡,是開啓大模型定製之旅的理想選擇。
記住:最好的技術選擇不是追求最先進的,而是最適合當下需求的。在這個快速發展的領域,LLaMA-Factory Online將持續為您提供最新的微調技術和自動化工具,讓保持技術敏感度和實踐迭代能力變得簡單高效——畢竟,在這個快速演進的時代,持續進化的能力比一次完美的選擇更為重要。







