

為電商或遊戲平台引入AI智能體(特別是RAG技術)能顯著提升用户體驗和運營效率。為了幫助你快速進行技術儲備,我為你整合了一套從概念到實戰的學習路徑和資源。
下面的表格梳理了構建RAG智能體的核心環節及對應的實用工具與平台,你可以根據自身情況靈活選擇。
|
核心環節 |
目標 |
推薦工具與平台 |
|
💡 快速體驗與原型構建 |
零代碼或低代碼驗證想法,快速搭建可演示的雛形
|
阿里雲百鍊、PAI LangStudio、n8n、京東雲言犀
|
|
🛠️ 開發框架與核心組件 |
提供開發骨架,處理知識檢索、智能體推理等核心邏輯
|
LangChain、MuAgent框架
|
|
📚 向量數據庫與檢索 |
存儲和快速查詢處理後的知識數據
|
Pinecone、Milvus、FAISS
|
|
🧠 大模型服務 |
提供核心的語義理解和內容生成能力
|
通義千問、DeepSeek、OpenAI、言犀大模型
|
從理論到實踐:四步構建你的知識體系
擁有工具只是第一步,如何正確使用它們更為關鍵。你可以遵循以下路徑進行學習和實踐。
1. 理解核心概念:RAG是什麼?
- 基本原理:RAG的全稱是檢索增強生成。它的工作流程很像一個專業的顧問:當你提問時,它會先去自己的資料庫(知識庫)裏快速查找相關信息(檢索),然後結合找到的資料和自身的學識,組織成一段完整、準確的回答(增強生成)。
- 解決什麼問題:它主要解決大模型在處理專業、實時或私有數據時可能出現的“胡言亂語”或信息滯後問題,讓AI的回答更精準、可靠。
2. 參考成功案例:看看別人怎麼做?
瞭解行業內的成熟應用能給你帶來直觀感受和設計靈感。
- 電商平台:
- 用户行為分析:結合AI智能體與大數據技術(如Flink、Spark),可以實現對海量用户行為(瀏覽、加購等)的實時分析和決策,比如在用户加購未下單時自動觸發優惠券發放。
- 智能購物顧問:像NVIDIA推出的零售購物顧問參考架構,可以讓AI助手準確回答關於商品的問題,並提供個性化推薦。
- 遊戲平台:
- 智能客服與問答:盛趣遊戲在《雲海之下》中部署的“知鏈”系統,能在0.3秒內掃描百萬級知識庫,為玩家解答關卡難題、賬號安全等問題。
- 智能NPC:《傳奇世界》中的智能NPC“玄玄老人”可以通過自然語言對話,為玩家提供實時、精準的遊戲情報和攻略。
3. 掌握關鍵技術:如何優化你的智能體?
一個基礎的RAG系統搭建起來不難,但要讓它表現優異,你需要關注以下優化技術:
- 高效的檢索策略:不要只依賴單一的檢索方式。可以嘗試混合檢索,即結合基於語義的向量檢索和基於關鍵詞的檢索(如BM25),讓檢索結果更全面、準確。
- 檢索結果精煉:使用上下文壓縮等技術,對檢索到的大量文檔進行摘要和提煉,只保留最相關的信息,這能顯著提升大模型處理效率和質量。
- 複雜任務處理:對於需要多步驟推理的複雜任務(如分析數據趨勢並撰寫報告),可以引入智能體(Agent)工作流,讓AI具備規劃、執行和調試的能力。
4. 動手實踐:選擇一個路徑開始
理論結合實踐是學習的最佳方式,你可以根據自身技術背景選擇起點。
- 如果你是零代碼愛好者:
- 使用阿里雲百鍊,可以在10分鐘內通過拖拽和配置,為一個網站添加具備私有知識庫的AI助手。
- 使用n8n這類自動化工具,可以通過可視化的工作流來構建一個簡單的RAG智能體,例如用於回答關於特定文檔(如遊戲規則)的問題。
- 如果你是開發者或希望深入定製:
- 從框架入手:學習使用 LangChain 這樣的流行框架,它用代碼將文檔加載、文本分割、向量化存儲和檢索集成為完整的鏈條,是構建複雜應用的基礎。
- 研究開源項目:在GitHub等平台上有許多MCP-RAG之類的開源項目,通過閲讀和運行別人的代碼,你能更深入地理解系統如何運作。
大數據背景如何轉AI智能體
大數據背景是構建AI智能體的巨大優勢。你們團隊的數據處理能力和對遊戲用户行為的理解,正是智能體成功的核心基礎。
基於你們的情況,我為你設計了一個從數據價值最大化出發的實戰路徑:
大數據團隊的獨特優勢與目標場景
你的核心資產是數據——用户行為日誌、遊戲數據、運營數據等。智能體是你的“價值放大器”。
高價值應用場景:
- 實時個性化推薦智能體:結合實時用户行為(如剛瀏覽了某類裝備),動態調整推薦內容。
- 玩家流失預警與干預智能體:識別有流失風險的玩家,並自動觸發個性化的召回任務(如推送專屬福利或他們可能感興趣的新內容)。
- 遊戲平衡與經濟系統分析智能體:讓智能體分析道具產出/消耗、玩家戰力分佈等,為策劃提供數據洞察和調整建議。
- 智能客服與遊戲問答助手:基於遊戲Wiki、版本更新公告、平衡性調整日誌等構建,為玩家提供精準問答。
技術架構與選型建議
對於大數據團隊,建議採用更靈活、可控的技術棧,以便與現有數據管道無縫集成。
組件選型建議:
- 數據預處理與ETL:繼續使用你熟悉的Spark。利用
spark-nlp等庫進行大規模的文本清洗和預處理。 - 向量數據庫:推薦 Milvus 或 Chroma。
- Milvus:性能強勁,適合大規模、高併發的生產環境,與大數據生態結合好。
- Chroma:輕量、開源,易於上手和調試,適合快速原型驗證。
- 開發框架:
- LangChain/LlamaIndex:依然是首選。它們提供了豐富的模塊,能快速構建起RAG管道。
- MuAgent:一個專門為智能體設計的框架,對行為規劃、工具調用支持得很好,如果你要構建能執行復雜任務(如“為A玩家羣體生成一個運營活動並評估其風險”)的智能體,值得關注。
- 大模型:
- 雲端API(快速啓動):DeepSeek、通義千問。成本可控,性能強大,適合初期驗證。
- 本地微調(長期發展):如果有敏感數據或需要定製化,可以考慮在後期使用 Qwen、 Baichuan 等開源模型,用你們自己的遊戲數據做微調。
四階段實戰路線圖
階段一:快速驗證(2-4周)- 構建一個“遊戲問答助手”
- 目標:選擇一個具體場景,跑通端到端的流程,獲得正反饋。
- 行動:
- 數據準備:選取一份結構清晰的遊戲知識文檔,如“遊戲玩法説明”或“客服QA文檔”。
- 構建管道:使用 LangChain + Chroma,寫一個Python腳本,將文檔切塊、向量化後存入Chroma。
- 搭建服務:創建一個簡單的Web界面(如用Gradio),讓團隊成員可以提問並得到基於文檔的準確回答。
- 成果:一個可演示的智能客服原型。
階段二:數據驅動(1-2個月)- 開發“玩家流失預警智能體”
- 目標:將智能體與你們的實時數據流結合,解決業務痛點。
- 行動:
- 定義規則:與運營同學合作,明確流失玩家的數據特徵(如“連續3天未登錄”且“等級>10”)。
- 構建智能體:
- 檢索:當系統識別出風險玩家時,智能體自動檢索該玩家的歷史行為(付費記錄、常用英雄、最近副本失敗次數等)。
- 分析與決策:讓大模型根據檢索到的玩家畫像,生成個性化的干預建議。例如:“該玩家是付費玩家,主玩‘法師’,最近副本失敗5次。建議:推送一條包含‘法師高級符文試用券’的登錄激勵信息。”
- 系統集成:將這個智能體作為API服務,集成到你們的用户運營平台或消息推送系統中。
- 成果:一個能自動識別風險並給出智能干預策略的AI智能體。
階段三:能力擴展(1-2個月)- 引入複雜任務處理能力
- 目標:讓智能體能夠使用工具,執行更復雜的任務。
- 行動:
- 為智能體賦予工具調用能力。例如,它可以調用:
- 內部數據API:查詢實時在線人數、某個道具的銷售數據。
- 執行API:發送郵件、創建JIRA工單、觸發一個推送任務。
- 場景:構建一個“運營日報智能體”,它每天自動檢索關鍵數據,調用大模型生成一份包含數據解讀和趨勢分析的報告,並通過郵件發送給相關負責人。
階段四:模型優化(長期)- 領域模型微調
- 目標:讓模型更懂你的遊戲,回答更專業。
- 行動:收集智能體運行中的高質量QA對話,以及遊戲內的專有名詞、技能描述等數據,對開源大模型進行領域適配微調。
給大數據工程師的特別提示
- 從“批處理”思維轉向“實時服務”思維:智能體往往需要低延遲的響應。關注向量檢索的性能和服務的穩定性。
- 數據質量是天花板:你比任何人都清楚“垃圾進,垃圾出”。用於檢索的知識庫(無論是文檔還是用户行為數據)的清洗和結構化質量,直接決定了智能體的上限。
- 評估體系:建立一套評估指標,如檢索準確率、回答滿意度、問題解決率等,用數據驅動智能體的迭代優化。
四階段執行方法
你的技術背景使得你無需從零學習數據處理,可以直接切入最核心的“如何用AI讓數據產生智能”這一環節。從一個小而美的場景開始,快速交付價值,然後逐步擴展,這是大數據團隊構建AI智能體最順暢的路徑。
如果需要,我可以就第一階段“遊戲問答助手”的具體技術實現,提供更詳細的代碼示例和步驟。
階段一:快速驗證 - 遊戲智能問答助手原型
目標:在2-4周內,利用靜態文檔數據,構建一個可演示的RAG原型,驗證技術可行性。
架構圖:
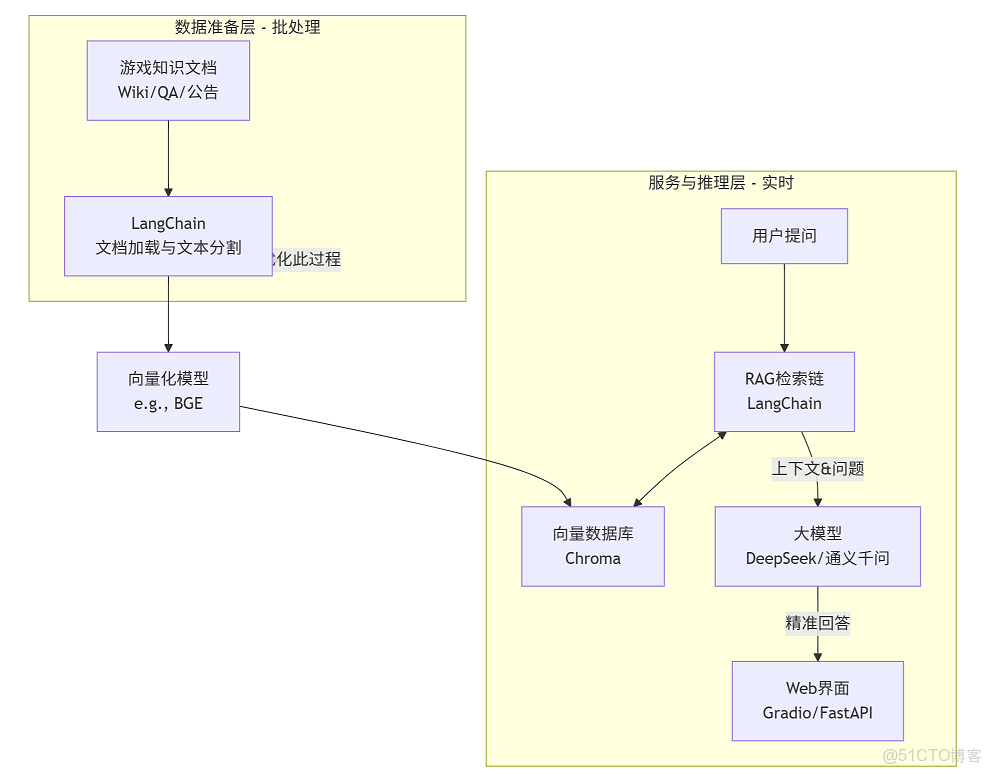
核心數據流與技術棧:
- 數據加載與分割:使用
LangChain的TextLoader、MarkdownLoader和RecursiveCharacterTextSplitter處理文檔。 - 向量化與存儲:採用輕量級開源向量模型(如
BGE)和向量數據庫(Chroma),便於快速部署。 - 檢索與生成:
LangChain組建檢索鏈,從Chroma查詢相似片段,連同用户問題發送給大模型生成答案。 - 交付:通過
Gradio快速構建前端界面,或使用FastAPI提供後端接口。
階段二:數據驅動 - 玩家流失預警與干預智能體
目標:將智能體與實時數據流結合,實現從風險識別到智能干預的閉環。
架構圖:
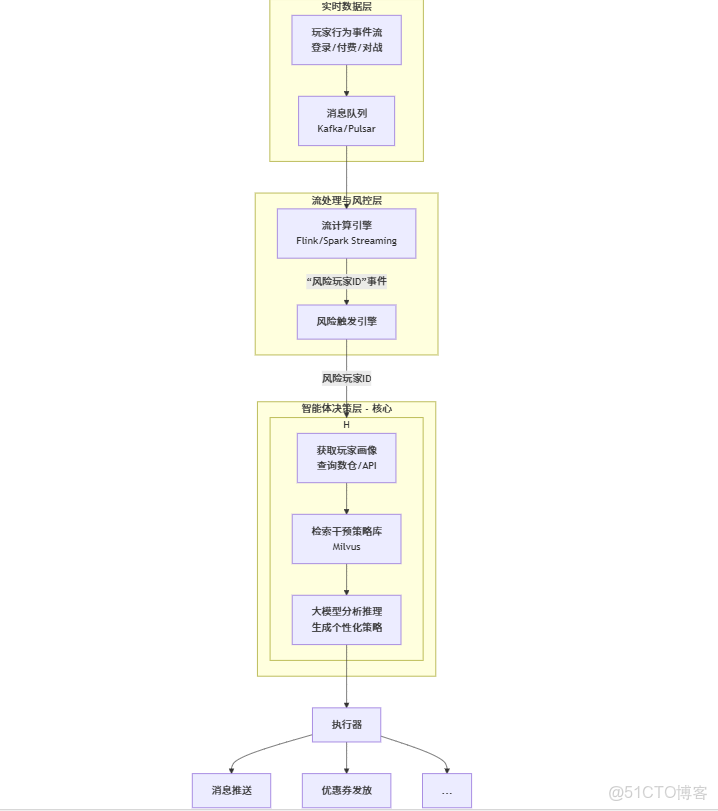
核心數據流與技術棧:
- 實時風控:
Flink消費Kafka數據,通過預定義的規則(如“連續3天未登錄”)實時生成風險事件。 - 智能體決策:
- 數據檢索:智能體接收風險玩家ID後,首先查詢 數據倉庫(如ClickHouse)或 用户畫像系統,獲取該玩家的詳細畫像(付費、裝備、活躍度)。
- 策略檢索:同時,從
Milvus中檢索已有的“干預策略”案例。 - 推理決策:大模型綜合 玩家畫像 和 策略庫,生成個性化干預命令(如:推送“法師專屬符文”)。
- 動作執行:智能體通過調用內部 API(推送、營銷平台)完成動作執行。
階段三:能力擴展 - 運營日報生成智能體
目標:引入智能體(Agent)和工具調用(Tool Use)能力,讓AI自動完成複雜、多步驟的任務。
架構圖:
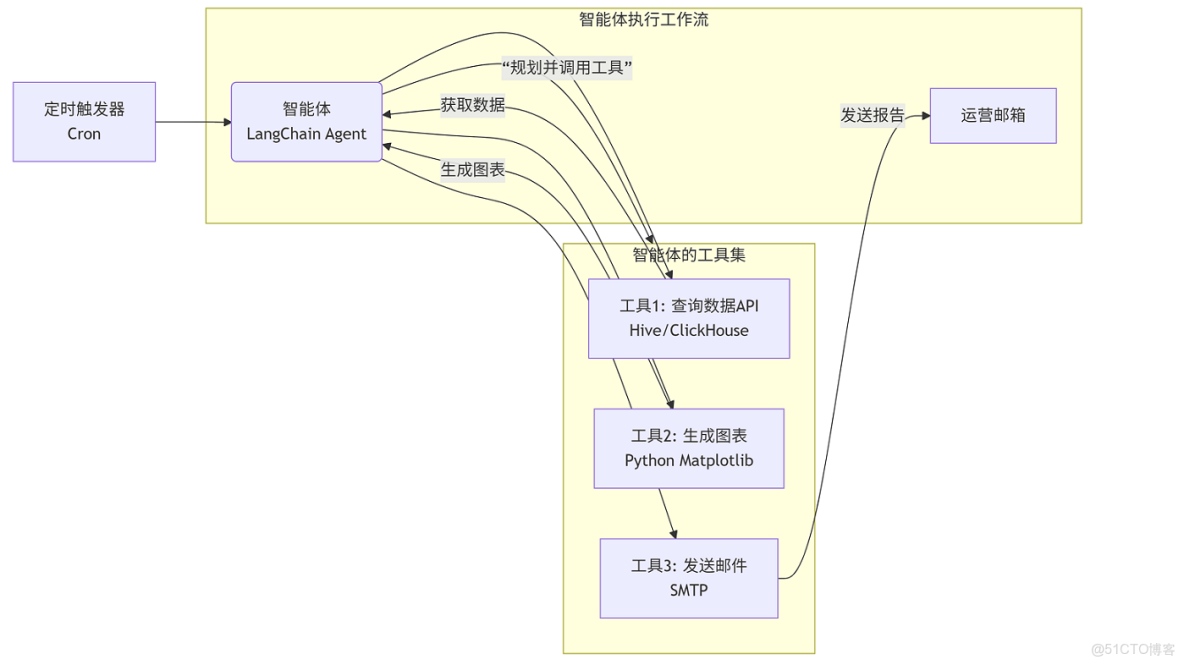
核心數據流與技術棧:
- 智能體核心:使用
LangChain Agent框架,它具備規劃和工具調用能力。 - 工具集:
- 數據查詢工具:封裝對數據倉庫的查詢SQL,返回核心KPI(DAU、收入)。
- 圖表生成工具:調用
Matplotlib或Pyecharts生成趨勢圖。 - 郵件發送工具:封裝
SMTP邏輯。
- 工作流:智能體接收“生成日報”任務後,會自主規劃步驟:調用工具1獲取數據 -> 調用工具2生成圖表 -> 組織圖文報告 -> 調用工具3發送郵件。
階段四:模型優化 - 領域模型微調
目標:讓通用大模型更懂你的遊戲,成為領域的“專家”,提升所有上游智能體的表現。
架構圖:
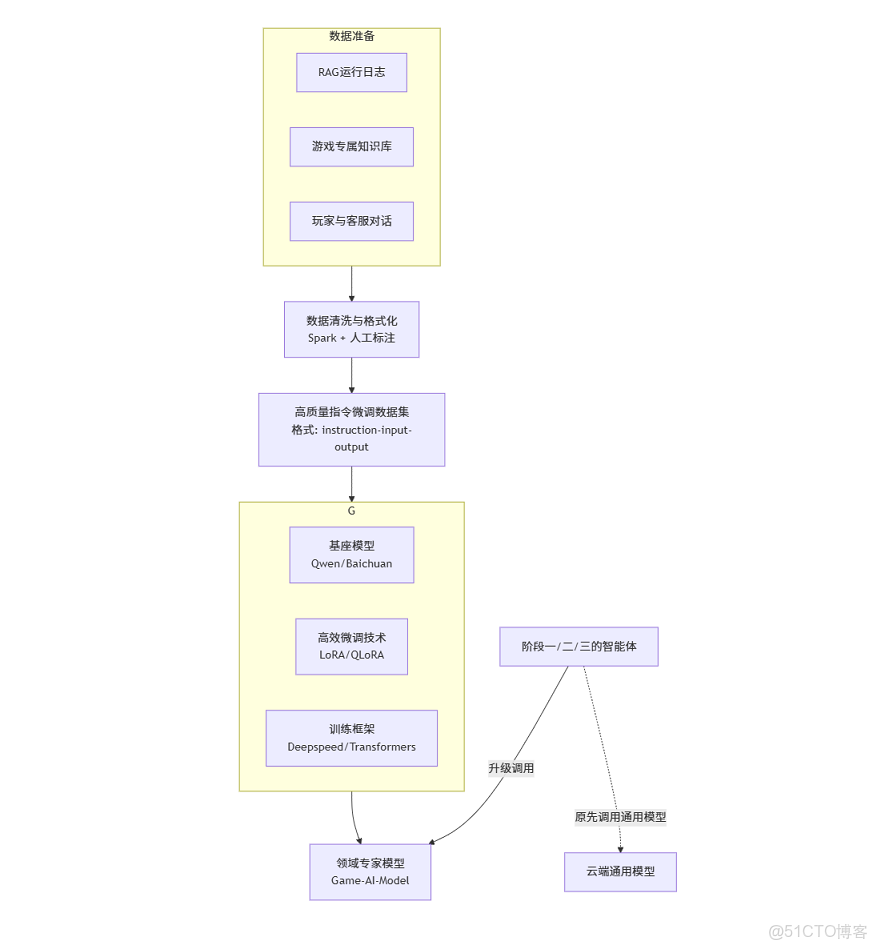
核心數據流與技術棧:
- 數據構建:從前期智能體的運行日誌、遊戲Wiki、優質客服對話中提煉高質量的QA對,構建指令微調數據集。
- 高效微調:
- 基座模型:選擇優秀的開源模型,如
Qwen。 - 微調技術:採用
LoRA/QLoRA等技術,大幅降低計算成本和顯存需求,即可在少量A100/A800上完成。
- 模型部署:將微調後的模型部署為 內部API服務(可使用
vLLM等高性能推理框架)。 - 上游集成:將階段一、二、三的智能體接入點,從雲端通用模型切換至你這個私有的“領域專家模型”,從而獲得更精準、更專業的性能提升。
這四張架構圖清晰地勾勒出了從技術驗證到深度集成的演進路徑。建議你從第一階段開始,快速為團隊建立一個直觀的認知和信心。








