
1、損失函數(代價函數)
損失函數(loss function)是用來估量模型的預測值f(x)與真實值Y的不一致程度,它是一個非負實值函數,通常使用L(Y, f(x))來表示,損失函數越小,模型的魯棒性就越好。損失函數和代價函數是同一個東西,目標函數是一個與它們相關但更廣的概念。
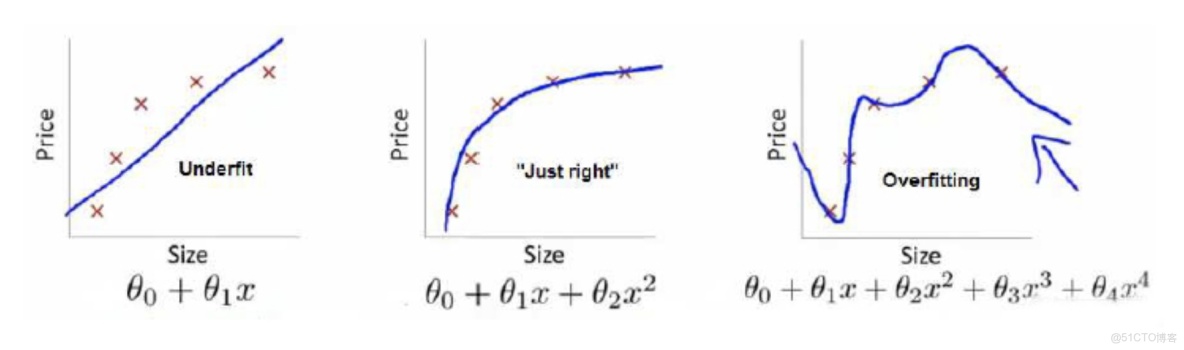
上面三個圖的函數依次為
,
,
。我們是想用這三個函數分別來擬合Price,Price的真實值記為 Y 我們給定
,這三個函數都會輸出一個
,這個輸出的
與真實值 Y可能是相同的,也可能是不同的,為了表示我們擬合的好壞,我們就用一個函數來度量擬合的程度,比如:
,這個函數就稱為損失函數(loss function),或者叫代價函數(cost function)。損失函數越小,就代表模型擬合的越好。
那是不是我們的目標就只是讓loss function越小越好呢?還不是。
這個時候還有一個概念叫風險函數(risk function)。風險函數是損失函數的期望,這是由於我們輸入輸出的
遵循一個聯合分佈,但是這個聯合分佈是未知的,所以無法計算。但是我們是有歷史數據的,就是我們的訓練集,
關於訓練集的平均損失稱作經驗風險(empirical risk),即
,所以我們的目標就是最小化
,稱為經驗風險最小化。
統計學習常用的損失函數有以下幾種:
1)0-1損失
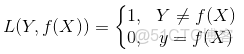
2)平方損失函數
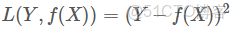
當樣本個數為n時,此時的損失函數變為:
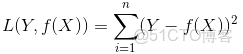
在實際應用中,通常會使用均方差(MSE)作為一項衡量指標
3)絕對損失函數
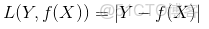
4)對數損失函數
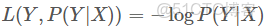
2、目標函數
如果到這一步就完了的話,那我們看上面的圖,那肯定是最右面的
的經驗風險函數最小了,因為它對歷史的數據擬合的最好嘛。但是我們從圖上來看
肯定不是最好的,因為它過度學習歷史數據,導致它在真正預測時效果會很不好,這種情況稱為過擬合(over-fitting)。為什麼會造成這種結果?大白話説就是它的函數太複雜了,都有四次方了,這就引出了下面的概念,我們不僅要讓經驗風險最小化,還要讓結構風險最小化。這個時候就定義了一個函數
,這個函數專門用來度量模型的複雜度,在機器學習中也叫正則化(regularization)。常用的有
,
範數。到這一步我們就可以説我們最終的優化函數是:
,即最優化經驗風險和結構風險,而這個函數就被稱為目標函數。結合上面的例子來分析:最左面的
結構風險最小(模型結構最簡單),但是經驗風險最大(對歷史數據擬合的最差);最右面的
經驗風險最小(對歷史數據擬合的最好),但是結構風險最大(模型結構最複雜);而
達到了二者的良好平衡,最適合用來預測未知數據集。
參考:
【作者:zzanswer,