
1. Llama Factory 到底是什麼?
1.1 簡單比喻
想象你要定製一輛汽車:
傳統方式(沒有 Llama Factory):
- 你需要自己造發動機、設計車身、組裝零件
- 需要懂機械工程、電子技術、材料科學
- 整個過程複雜、容易出錯、耗時很長
使用 Llama Factory:
- 你只需要:
- 選擇基礎車型(預訓練模型)
- 告訴工廠你的需求(訓練數據)
- 選擇改裝方案(訓練方法)
- 工廠自動完成所有改裝
- 你不需要懂技術細節,只需要提需求
1.2 一句話定義
Llama Factory 是一個"AI模型定製工廠",它讓普通人也能輕鬆地定製和訓練自己的大語言模型。
2. 為什麼需要 Llama Factory?
2.1 傳統訓練的痛點
假設你想訓練一個懂醫療知識的AI助手:
# 傳統方式 - 需要寫很多複雜代碼
import torch
from transformers import AutoModel, AutoTokenizer, TrainingArguments, Trainer
from datasets import load_dataset
import deepspeed
# 1. 數據預處理(很複雜)
def preprocess_function(examples):
# 需要懂分詞、填充、截斷等技術
pass
# 2. 模型配置(容易出錯)
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-5,
# ... 還有幾十個參數需要設置
)
# 3. 訓練循環(需要深度學習知識)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
data_collator=data_collator,
# ... 更多複雜配置
)
# 4. 處理各種錯誤(內存不足、配置錯誤等)問題總結:
- 技術門檻高:需要懂編程、深度學習、分佈式訓練
- 配置複雜:幾十個參數需要調優
- 容易出錯:內存溢出、配置錯誤、訓練不穩定
- 效率低下:大量時間花在調試上
2.2 Llama Factory 的解決方案
# 使用 Llama Factory 的方式
from llama_factory import TrainArguments, run_train
# 只需要配置幾個關鍵參數
train_args = TrainArguments(
model_name_or_path="Qwen/Qwen2-7B-Instruct", # 基礎模型
dataset="my_medical_data", # 你的數據
finetuning_type="lora", # 訓練方法
output_dir="./my_medical_ai" # 輸出位置
)
# 一鍵開始訓練
run_train(train_args)3. Llama Factory 的核心功能詳解
3.1 四種訓練方法(像選擇汽車改裝方案)
方案1:全參數微調 - "整車大改裝"
工作原理:更新模型的所有參數
✅ 優點:效果最好,能力最強
❌ 缺點:成本高,需要大量GPU內存
💡 適合:大公司,有充足計算資源
🔧 需求:多張A100/H100顯卡
內存需求:模型大小 × 4 × 3 ≈ 12倍模型大小
例如:7B模型需要 7×4×3 = 84GB GPU內存
方案2:LoRA - "加裝智能配件"
工作原理:只訓練少量新增的參數,不改變原模型
✅ 優點:節省90%內存,訓練快,可切換不同任務
❌ 缺點:效果略低於全參數微調
💡 適合:大多數應用場景
🔧 需求:單張RTX 3090/4090即可
內存需求:模型大小 + 少量額外參數
例如:7B模型只需要 7GB + 0.1GB = 7.1GB GPU內存
方案3:QLoRA - "輕量化智能配件"
工作原理:在LoRA基礎上,把模型壓縮到4位精度
✅ 優點:極省內存,消費級顯卡就能訓練大模型
❌ 缺點:效果有輕微損失
💡 適合:個人開發者,資源有限
🔧 需求:單張RTX 3080/4060即可
內存需求:模型大小 × 0.5 + 少量參數
例如:7B模型只需要 7×0.5 + 0.1 = 3.6GB GPU內存
方案4:P-Tuning - "只改方向盤"
工作原理:只訓練極少量提示參數
✅ 優點:超級省內存,訓練極快
❌ 缺點:效果有限,能力提升小
💡 適合:快速實驗,極小資源
🔧 需求:幾乎任何顯卡都能用
內存需求:模型大小 + 極少量參數
4. Llama Factory 的完整工作流程
4.1 第一步:準備數據(像準備菜譜)
數據格式要求:
// 你的訓練數據應該長這樣
[
{
"instruction": "給以下症狀提供醫療建議",
"input": "患者發燒38.5℃,咳嗽,流鼻涕",
"output": "建議多休息、多喝水,可服用退燒藥,如症狀持續請就醫"
},
{
"instruction": "翻譯以下英文",
"input": "Hello, how are you?",
"output": "你好,最近怎麼樣?"
}
]各個字段的含義:
instruction:你要AI完成什麼任務input:給AI的輸入信息output:你期望AI輸出的正確答案
數據準備技巧:
- 數量:至少100條,越多越好
- 質量:確保答案准確、專業
- 多樣性:覆蓋各種場景和問題類型
4.2 第二步:選擇基礎模型(像選擇原材料)
常見基礎模型推薦:
中文任務:
- Qwen系列(阿里通義千問):對中文支持最好
- ChatGLM系列(清華):中文理解強
- Baichuan系列(百川):中文優化好
英文任務:
- Llama系列(Meta):生態豐富
- Mistral系列:性能優秀
- Gemma系列(Google):輕量高效
多語言任務:
- Qwen系列:中英文都不錯
- Llama系列:通過擴展支持多語言選擇原則:
- 任務語言 → 選擇對應語言優化好的模型
- 硬件限制 → 選擇參數量合適的模型
- 功能需求 → 選擇能力匹配的模型
4.3 第三步:配置訓練參數(像設置烹飪參數)
# 一個完整的訓練配置示例
train_args = TrainArguments(
# 基礎配置
model_name_or_path="Qwen/Qwen2-7B-Instruct", # 基礎模型
dataset="my_medical_data", # 數據集名稱
finetuning_type="lora", # 訓練方法
# LoRA 專用配置
lora_target="q_proj,v_proj", # 要改動的模型部件
lora_rank=16, # 改動程度(16-64)
lora_alpha=32, # 學習強度
# 訓練參數
output_dir="./my_medical_ai", # 保存位置
per_device_train_batch_size=4, # 批次大小
gradient_accumulation_steps=4, # 梯度累積
learning_rate=2e-4, # 學習率
num_train_epochs=3, # 訓練輪數
# 資源優化
fp16=True, # 使用半精度節省內存
logging_steps=10, # 每10步輸出日誌
)4.4 第四步:開始訓練(像啓動智能廚房)
from llama_factory import run_train
# 一鍵開始訓練
run_train(train_args)
# 訓練過程中你會看到:
# 🔥 開始訓練...
# 📊 第1步,損失: 2.3456
# 📊 第10步,損失: 1.2345
# 📊 第20步,損失: 0.8765
# 💾 保存檢查點...
# 🎉 訓練完成!4.5 第五步:測試和使用(像品嚐菜品)
from llama_factory import load_model, get_infer_args
# 加載訓練好的模型
infer_args = get_infer_args({
"model_name_or_path": "Qwen/Qwen2-7B-Instruct",
"adapter_name_or_path": "./my_medical_ai", # 你的訓練結果
"template": "qwen"
})
model, tokenizer = load_model(infer_args)
# 測試你的AI助手
messages = [
{"role": "user", "content": "我發燒38℃,應該怎麼辦?"}
]
response = model.chat(tokenizer, messages)
print(f"AI回答: {response}")
# 輸出:建議多休息、多喝水,可服用退燒藥...5、介紹完,就可以嘗試了
LLaMA-Factory 是一個用於訓練和微調模型的工具。它支持全參數微調、LoRA 微調、QLoRA 微調、模型評估、模型推理和模型導出等功能。
微調的過程
模型微調通過在特定任務的數據集上繼續訓練預訓練模型來進行,使得模型能夠學習到與任務相關的特定特徵和知識。這個過程通常涉及到模型權重的微幅調整,而不是從頭開始訓練一個全新的模型。微調過程主要包括以下幾個步驟:
1. 數據準備:收集和準備特定任務的數據集。
2. 模型選擇:選擇一個預訓練模型作為基礎模型。
3. 遷移學習:在新數據集上繼續訓練模型,同時保留預訓練模型的知識。
4. 參數調整:根據需要調整模型的參數,如學習率、批大小等。
5. 模型評估:在驗證集上評估模型的性能,並根據反饋進行調整。
安裝
若電腦沒有GPU,可以使用ModelScope雲服務
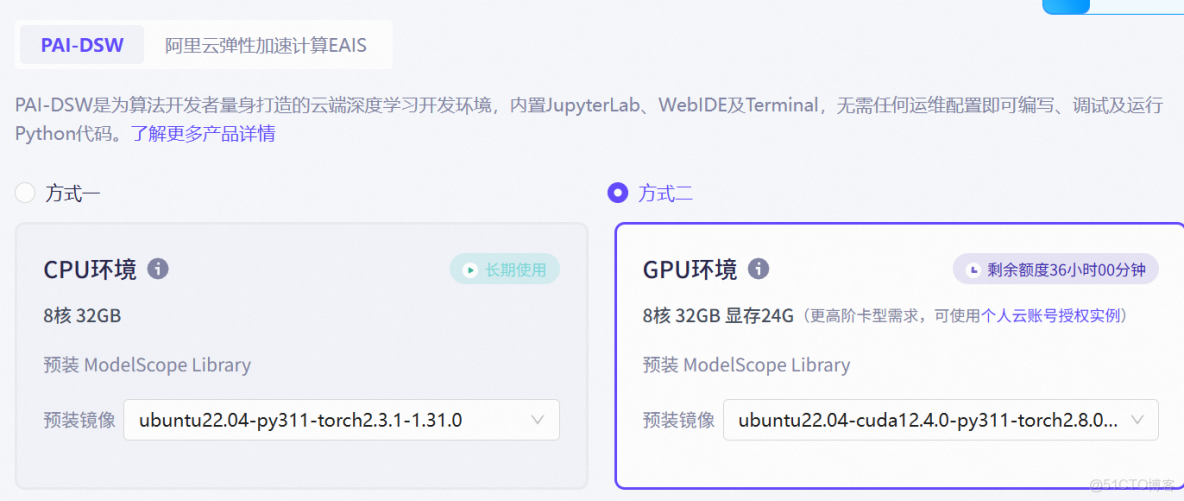
前提CUDA要安裝,然後安裝llamafactory
# 構建虛擬環境
conda create -n llamafactory python=3.10 -y && conda activate llamafactory
# 下載倉庫
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安裝
pip install -e .
校驗
llamafactory-cli version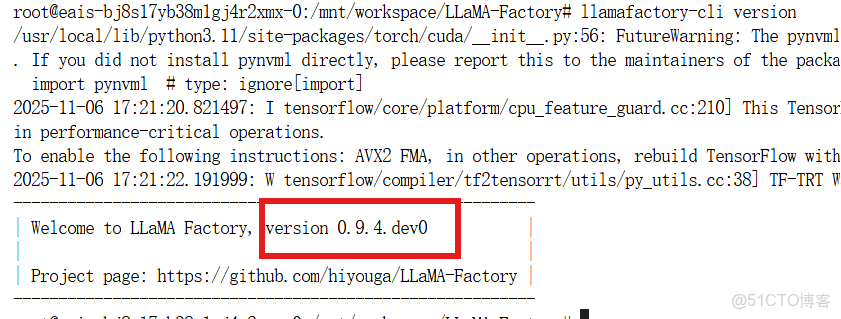
安裝完成後、可以啓動webUI界面配置,也可以直接在示例文件夾下修改。
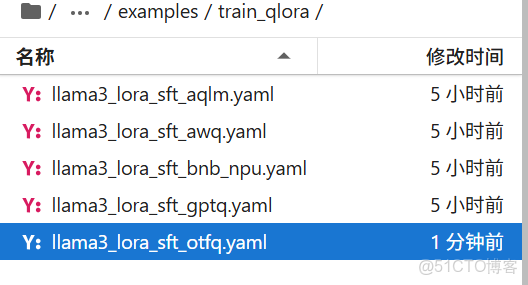
可以讀一下readme使用哪個方法訓練,有對應命令行的執行命令

打開這個文件有幾個配置
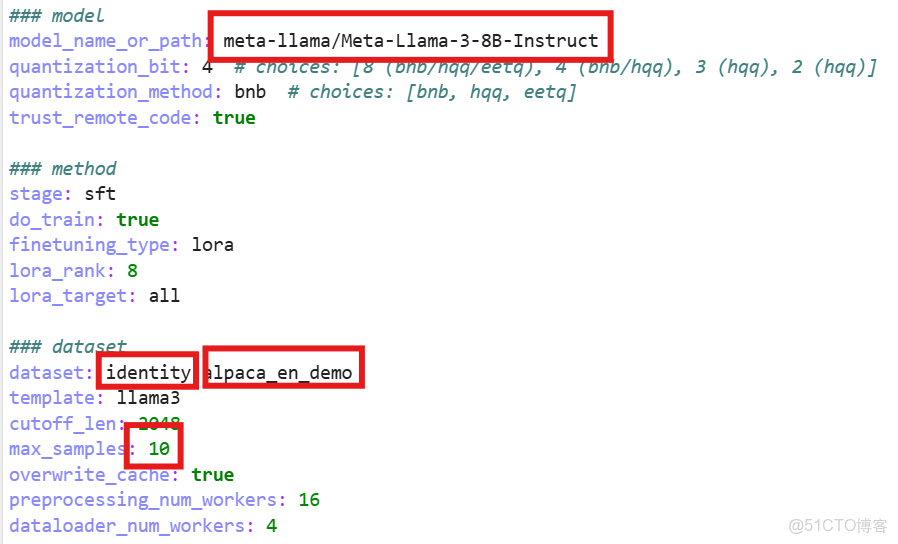
第一個框是它要訓練的模型路徑,默認模型文件從modelScope上下載
第二個框是用的數據集,有兩個,第一個是自我認證:

用户什麼都沒有輸入,只是讓模型知道它是誰,一個自我認證的數據集
第二個就是微調的數據集(en證明是英文的)。

第三個框是一次訓練最大例子數量,可以調小一點加快訓練。
訓練配置完成後就可以在命令行執行:
llamafactory-cli train examples/train_qlora/llama3_lora_sft_otfq.yaml