
2.2、核函數Kernel
2.2.1、特徵空間的隱式映射:核函數
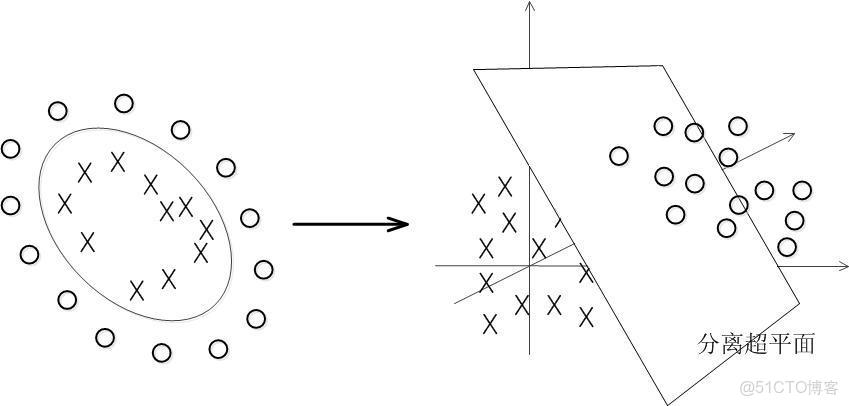
咱們首先給出核函數的來頭:在上文中,我們已經瞭解到了SVM處理線性可分的情況,而對於非線性的情況,SVM 的處理方法是選擇一個核函數 κ(⋅,⋅) ,通過將數據映射到高維空間,來解決在原始空間中線性不可分的問題。
此外,因為訓練樣例一般是不會獨立出現的,它們總是以成對樣例的內積形式出現,而用對偶形式表示學習器的優勢在為在該表示中可調參數的個數不依賴輸入屬性的個數,通過使用恰當的核函數來替代內積,可以隱式得將非線性的訓練數據映射到高維空間,而不增加可調參數的個數(當然,前提是核函數能夠計算對應着兩個輸入特徵向量的內積)。
7-7所示,一堆數據在二維空間無法劃分,從而映射到三維空間裏劃分:
而在我們遇到核函數之前,如果用原始的方法,那麼在用線性學習器學習一個非線性關係,需要選擇一個非線性特徵集,並且將數據寫成新的表達形式,這等價於應用一個固定的非線性映射,將數據映射到特徵空間,在特徵空間中使用線性學習器,因此,考慮的假設集是這種類型的函數:
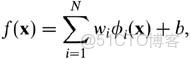
ϕ:X->F是從輸入空間到某個特徵空間的映射,這意味着建立非線性學習器分為兩步:
- 首先使用一個非線性映射將數據變換到一個特徵空間F,
- 然後在特徵空間使用線性學習器分類。
而由於對偶形式就是線性學習器的一個重要性質,這意味着假設可以表達為訓練點的線性組合,因此決策規則可以用測試點和訓練點的內積來表示:
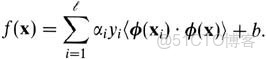
如果有一種方式可以 在特徵空間中直接計算內積〈φ(xi · φ(x) 〉,就像在原始輸入點的函數中一樣,就有可能將兩個步驟融合到一起建立一個非線性的學習器,這樣直接計算法的方法稱為核函數方法:
核是一個函數K,對所有x,z(-X,滿足
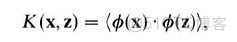
,這裏
φ是從X到內積特徵空間F的映射。
2.2.2、核函數:如何處理非線性數據
下文將會有一個相應的三維空間圖)?

X1 和 X2
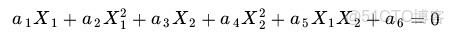
Z1=X1, Z2=X21, Z3=X2, Z4=X22, Z5=X1X2,那麼顯然,上面的方程在新的座標系下可以寫作:
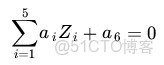
Z ,這正是一個 hyper plane 的方程!也就是説,如果我們做一個映射 ϕ:R2→R5 ,將 X 按照上面的規則映射為 ZKernel 方法處理非線性問題的基本思想。
X2
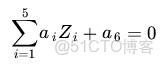
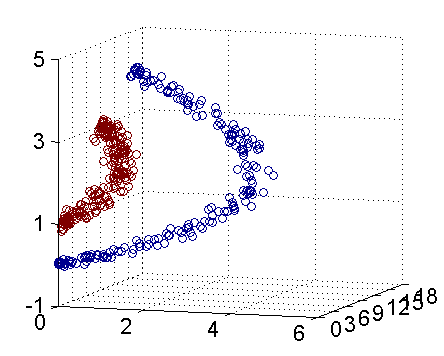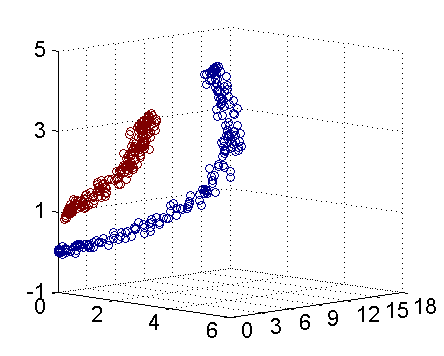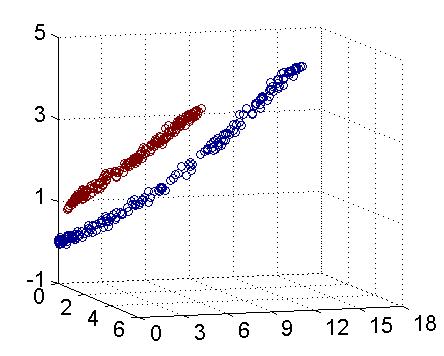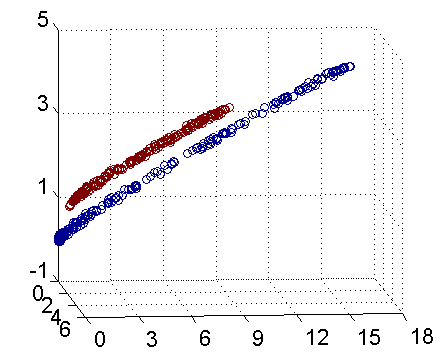
Z1=X21, Z2=X22, Z3=X2 這樣一個三維空間中即可,下圖即是映射之後的結果,將座標軸經過適當的旋轉,就可以很明顯地看出,數據是可以通過一個平面來分開的(pluskid:下面的gif 動畫,先用 Matlab 畫出一張張圖片,再用 Imagemagick 拼貼成):
核函數相當於把原來的分類函數:
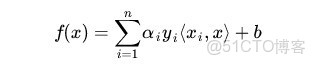
映射成:
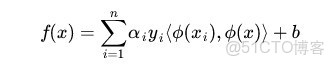
而其中的
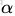
可以通過求解如下 dual 問題而得到的:
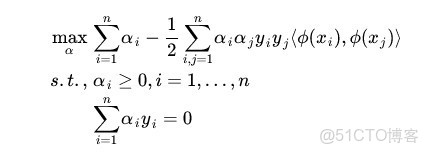
,然後一股腦把原來的數據映射到新空間中,再做線性 SVM 即可。不過事實上沒有這麼簡單!其實剛才的方法稍想一下就會發現有問題:在最初的例子裏,我們對一個二維空間做映射,選擇的新空間是原始空間的所有一階和二階的組合,得到了五個維度;如果原始空間是三維,那麼我們會得到 19 維的新空間,這個數目是呈爆炸性增長的,這給
不妨還是從最開始的簡單例子出發,設兩個向量
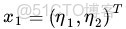
和
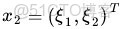
,而
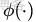
即是到前面説的五維空間的映射,因此映射過後的內積為:
(公式説明:上面的這兩個推導過程中,所説的前面的五維空間的映射,這裏説的前面便是文中2.2.1節的所述的映射方式,回顧下之前的映射規則,再看那第一個推導,其實就是計算x1,x2各自的內積,然後相乘相加即可,第二個推導則是直接平方,去掉括號,也很容易推出來)
另外,我們又注意到:
二者有很多相似的地方,實際上,我們只要把某幾個維度線性縮放一下,然後再加上一個常數維度,具體來説,上面這個式子的計算結果實際上和映射
之後的內積
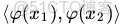
的結果是相等的,那麼區別在於什麼地方呢?
- 一個是映射到高維空間中,然後再根據內積的公式進行計算;
- 而另一個則直接在原來的低維空間中進行計算,而不需要顯式地寫出映射後的結果。
上面之中,最後的兩個式子,第一個算式,是帶內積的完全平方式,可以拆開,然後,通過湊一個得到,第二個算式,也是根據第一個算式湊出來的)
回憶剛才提到的映射的維度爆炸,在前一種方法已經無法計算的情況下,後一種方法卻依舊能從容處理,甚至是無窮維度的情況也沒有問題。
我們把這裏的計算兩個向量在隱式映射過後的空間中的內積的函數叫做核函數 (Kernel Function) ,例如,在剛才的例子中,我們的核函數為:
核函數能簡化映射空間中的內積運算——剛好“碰巧”的是,在我們的 SVM 裏需要計算的地方數據向量總是以內積的形式出現的。對比剛才我們上面寫出來的式子,現在我們的分類函數為:
避開了直接在高維空間中進行計算,而結果卻是等價的!當然,因為我們這裏的例子非常簡單,所以我可以手工構造出對應於
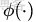
的核函數出來,如果對於任意一個映射,想要構造出對應的核函數就很困難了。
2.2.3、幾個核函數
通常人們會從一些常用的核函數中選擇(根據問題和數據的不同,選擇不同的參數,實際上就是得到了不同的核函數),例如:
- 多項式核,顯然剛才我們舉的例子是這裏多項式核的一個特例(R = 1,d = 2)。雖然比較麻煩,而且沒有必要,不過這個核所對應的映射實際上是可以寫出來的,該空間的維度是,其中
- 高斯核,這個核就是最開始提到過的會將原始空間映射為無窮維空間的那個傢伙。不過,如果選得很大的話,高次特徵上的權重實際上衰減得非常快,所以實際上(數值上近似一下)相當於一個低維的子空間;反過來,如果選得很小,則可以將任意的數據映射為線性可分——當然,這並不一定是好事,因為隨之而來的可能是非常嚴重的過擬合問題。不過,總的來説,通過調控參數,高斯核實際上具有相當高的靈活性,也是使用最廣泛的核函數之一。下圖所示的例子便是把低維線性不可分的數據通過高斯核函數映射到了高維空間:
- 線性核,這實際上就是原始空間中的內積。這個核存在的主要目的是使得“映射後空間中的問題”和“映射前空間中的問題”兩者在形式上統一起來了(意思是説,咱們有的時候,寫代碼,或寫公式的時候,只要寫個模板或通用表達式,然後再代入不同的核,便可以了,於此,便在形式上統一了起來,不用再分別寫一個線性的,和一個非線性的)。
2.2.4、核函數的本質
上面説了這麼一大堆,讀者可能還是沒明白核函數到底是個什麼東西?我再簡要概括下,即以下三點:
- 實際中,我們會經常遇到線性不可分的樣例,此時,我們的常用做法是把樣例特徵映射到高維空間中去(如上文2.2節最開始的那幅圖所示,映射到高維空間後,相關特徵便被分開了,也就達到了分類的目的);
- 但進一步,如果凡是遇到線性不可分的樣例,一律映射到高維空間,那麼這個維度大小是會高到可怕的(如上文中19維乃至無窮維的例子)。那咋辦呢?
- 此時,核函數就隆重登場了,核函數的價值在於它雖然也是講特徵進行從低維到高維的轉換,但核函數絕就絕在它事先在低維上進行計算,而將實質上的分類效果表現在了高維上,也就如上文所説的避免了直接在高維空間中的複雜計算。
最後引用這裏的一個例子舉例説明下核函數解決非線性問題的直觀效果。
假設現在你是一個農場主,圈養了一批羊羣,但為預防狼羣襲擊羊羣,你需要搭建一個籬笆來把羊羣圍起來。但是籬笆應該建在哪裏呢?你很可能需要依據牛羣和狼羣的位置建立一個“分類器”,比較下圖這幾種不同的分類器,我們可以看到SVM完成了一個很完美的解決方案。
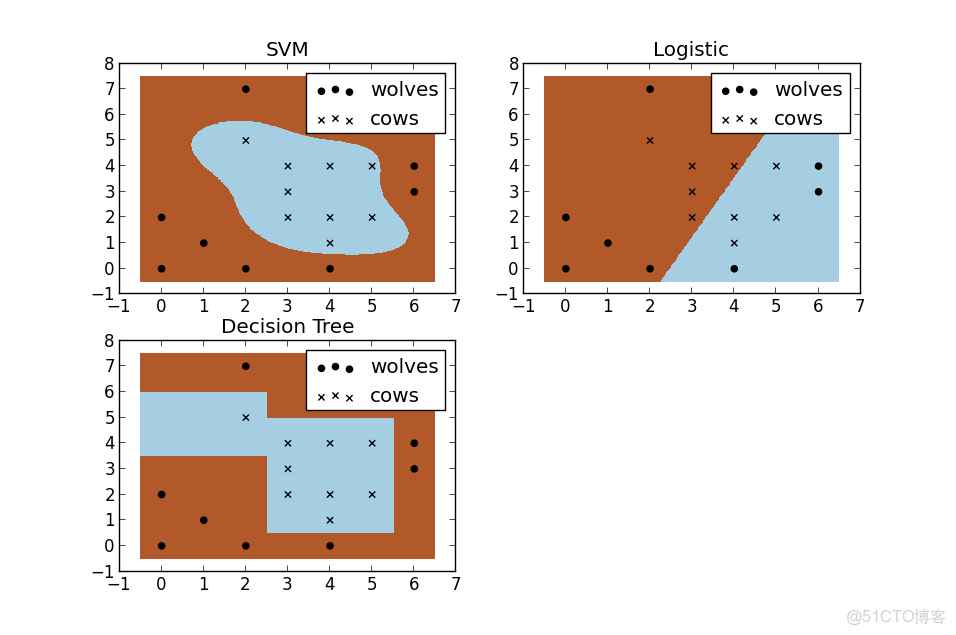
這個例子從側面簡單説明了SVM使用非線性分類器的優勢,而邏輯模式以及決策樹模式都是使用了直線方法。
OK, 不再做過多介紹了,對核函數有進一步興趣的,還可以看看此文。