
目錄
前言
Paddle-OCR安裝
關於什麼是paddle-ocr這裏詳細的介紹一下
核心特點:
典型應用場景:
使用優勢:
安裝
代碼編寫
運行演示
問題原因和解決辦法
前言
在上一篇章節,我們實現了基於文件來進行回答,不過還遺留了一些問題,那就是無法識別帶有文字的圖片,不過現在會在這篇篇章進行問題解決。
原因是markitdown的官網並沒有寫明白,mrkitdown並不具備含有ocr圖片文件識別,但是標註了,ocr識別是基於模型是否能夠支持圖片輸入進行回答,那就需要含有視覺的模型來支撐這個ocr,如果你的模型本身就是普通的聊天模型,那不好意思,識別不到。
關於什麼是paddle-ocr這裏詳細的介紹一下
PaddleOCR 是百度飛槳(PaddlePaddle)推出的一款開源 OCR(Optical Character Recognition,光學字符識別)工具庫,主要用於將圖片、掃描件等視覺內容中的文字信息提取為可編輯的文本。
核心特點:
- 多語言支持:默認支持中文、英文、數字,還可擴展至日文、韓文、德文等 80+ 語言,覆蓋常見場景的文字識別需求。
- 多場景適配:能處理印刷體(如文檔、海報、車牌)、手寫體(如筆記、簽名)、表格、二維碼等多種形式的文字內容。
- 高精度模型:基於深度學習技術,內置經過大規模數據訓練的預訓練模型,識別準確率在行業內處於較高水平(尤其對中文場景優化明顯)。
- 輕量化部署:支持本地離線部署(無需聯網),提供 Python API、C++ 接口等,可輕鬆集成到桌面應用、移動端或服務器端。
- 開源免費:代碼和模型完全開源,允許商業使用,開發者可根據需求二次開發或優化模型。
典型應用場景:
- 文檔數字化(掃描件轉文字、PDF 文字提取);
- 證件識別(身份證、銀行卡、營業執照等);
- 場景文字識別(街景招牌、商品標籤、快遞單等);
- 表格識別(Excel 表格內容提取);
- 手寫體識別(手寫筆記、作業批改等)。
使用優勢:
對於開發者而言,PaddleOCR 開箱即用,無需從零訓練模型,通過簡單的代碼調用即可實現文字識別功能(如你之前改造的代碼中,通過 PaddleOCR() 初始化後直接調用 ocr.ocr() 即可提取圖片文本),且支持 CPU/GPU 加速,兼顧易用性和性能。
安裝
需python3.10以上的環境
在控制枱輸入以下兩條指令即可
# 安裝 PaddlePaddle(核心框架,選 CPU 版即可本地運行)
pip install paddlepaddle==3.2.0
# 安裝 PaddleOCR(包含預訓練模型,支持中英文等多語言)
pip install paddleocr代碼編寫
還是之前那個邏輯,原本的邏輯
md = MarkItDown()
file_path = "C:\\Users\\a\Desktop\\AgentTestworddemo.txt"
res = md.convert(file_path)
text = res.text_content
# 修改此處:對系統提示中的大括號進行轉義
prompt = ChatPromptTemplate.from_messages(
[
("system",
f"用户上傳文件的內容{text}\n\n你是一個問答助手,用户和你進行對話,你先基於用户上傳文件的內容查詢回答,如果沒有需要根據用户問題給出一個回答。".replace(
"{", "{{").replace("}", "}}")),
("human", "{question}"),
]
)
chat = prompt | llm
question = input("請輸入問題:")
response = chat.invoke({"question": question})
print(response.content)我們還是一樣的思路,不過編寫的是Paddle-OCR的端口
代碼參考
"""用paddleocr識別圖片中的文本(支持中英文,多語言)"""
OCR = PaddleOCR(lang="ch",use_angle_clas=True,use_gpu=False,show_log=False)
image_path = "D:\\pychram\\test_ocr.png"
res = OCR.ocr(image_path,cls= True)
#提取識別文字(按順序拼接)
text = ""
for line in res:
if line is not None:
for word_info in line:
text += word_info[1][0] + "\n" #word_info[1][0]為識別文字
text.strip() #去除首位空行
ocr_text = text
prompt = ChatPromptTemplate.from_messages(
[
("system",
f"用户上傳文件內容{ocr_text}\n\n你是一個問答助手,用户和你進行對話,你需要基於用户上傳文件內容查詢回答,如果沒有需要根據用户問題給出一個回答。".replace(
"{", "{{").replace("}", "}}")),
("human", "{question}"),
]
)
chat = prompt | llm
# 開始聊天
question = input("請輸入問題:")
response = chat.invoke({"question": question})
print(response.content)可以不難發現,大體的邏輯都是能實現的
運行演示
不出意外,你應該會和我一樣
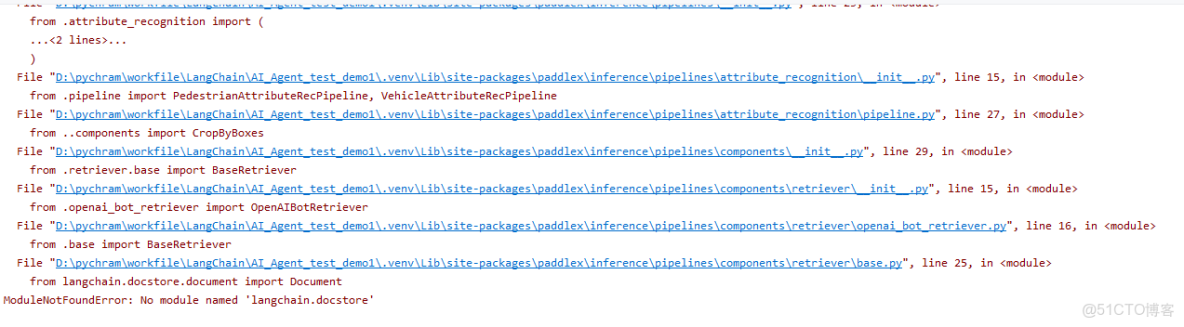
報錯了,別擔心,接下來會告訴原因,和解決辦法。
問題原因和解決辦法
原因呢,很簡單,Langchain最新版本不支持舊版的"langchain.docstore"模塊了,但是paddle-ocr還是要查詢這個模塊調用,後續應該會更新,不過目前應該沒有辦法去解決
那麼解決辦法就很簡單,就是降版本。
那麼思路就很清晰
卸載當前的Langchain,我知道捨不得,但是同志們,沒辦法,這種事情會哼常見的。
pip uninstall langchain langchain-core -y然後下載一個長期穩定的使用的舊版本
pip install langchain==0.2.14 langchain-core==0.2.34那麼到這裏,基本上就能完成了,在重新運行,這裏就不放演示了,因為我還沒解決,你們自己嘗試一下,萬一還有其他的方法,我也想學習,嘿嘿。