
DeepSeek-OCR: Optical Compression Solves LLM Long Context Challenge
文章摘要
DeepSeek-OCR提出了一種革命性的方法,通過將文本轉換為圖像並使用專門的視覺編碼器進行光學壓縮,解決了大語言模型在處理長文本時面臨的計算成本爆炸性增長問題,實現了10:1的壓縮比下97%的準確率。
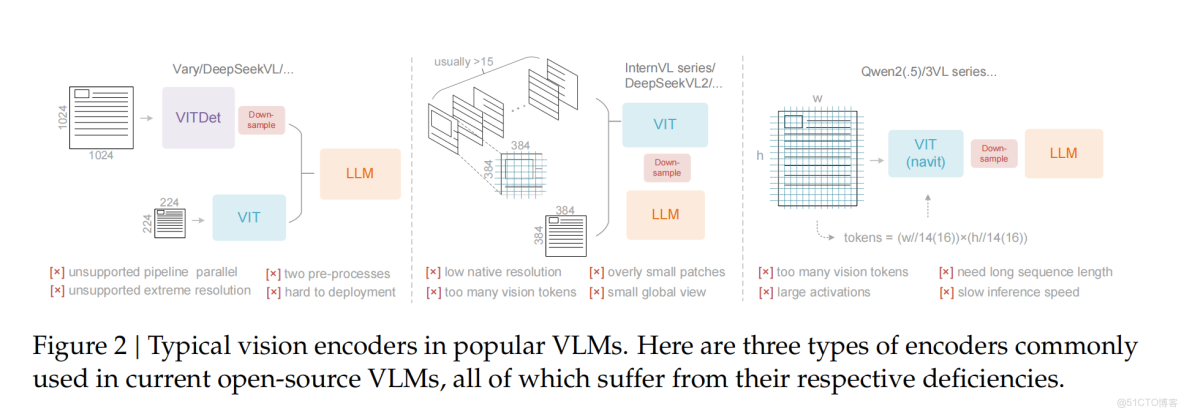
正文
大語言模型的致命瓶頸
大語言模型雖然功能強大,但它們有一個顯著的阿喀琉斯之踵:記憶能力限制。當我們向LLM輸入長文檔(如書籍或詳細報告)時,模型開始出現困難。計算成本呈爆炸性增長,甚至可能在讀到結尾時忘記開頭的內容。
當前LLM面臨的核心問題是其處理成本與文本長度呈二次方關係增長。這意味着文本長度翻倍,計算工作量不是翻倍,而是增長四倍。這是一個巨大的瓶頸。
革命性的解決方案:光學壓縮
DeepSeek-OCR提出了一個激進的想法:如果解決方案不是構建更大的內存,而是從根本上改變這些模型的"閲讀"方式會怎樣?如果AI不是逐詞處理文本,而是能夠將整頁密集文本作為單個高度壓縮的圖像來感知會怎樣?
這種方法建議進行完整的範式轉換。通過將長篇文本轉換為視覺格式——基本上是文本的圖像——我們可能能夠繞過這個擴展問題。這更像是瞥一眼頁面照片來獲取信息,而不是逐詞閲讀書籍。這不僅僅是一種更高級的光學字符識別(OCR)方法,而是完全重新思考如何將大量信息輸入AI系統,這是解鎖分析整個研究圖書館或多年對話歷史等功能的關鍵。
DeepEncoder架構:光學壓縮的核心技術
要實現這種光學壓縮,不能僅僅使用現成的組件。需要專門為此任務設計的專用視覺編碼器。這正是論文接下來介紹的內容。
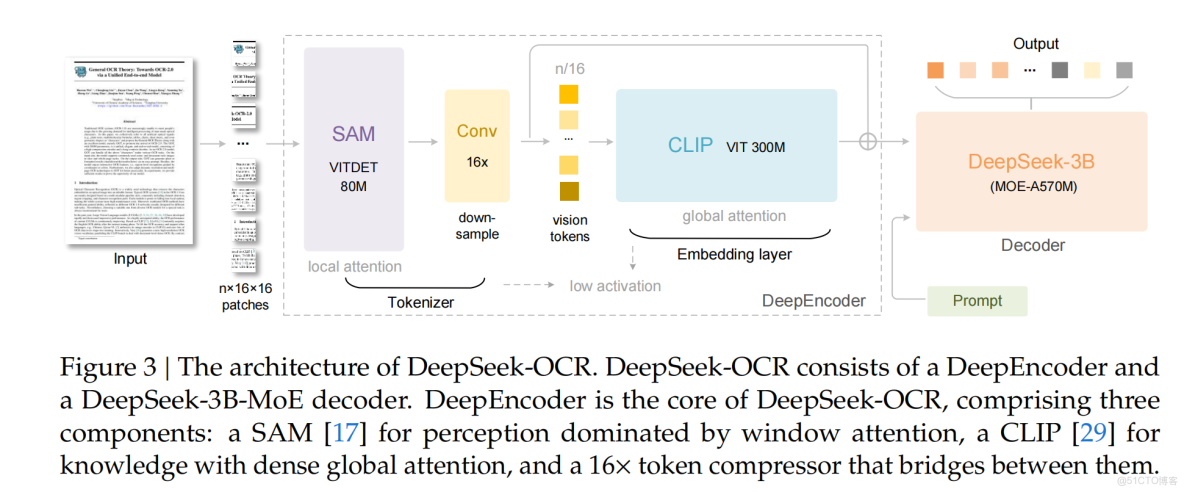
DeepSeek-OCR的核心是一種名為DeepEncoder的新型架構。它被設計來完成聽起來矛盾的任務:處理超高分辨率圖像的同時使用極少的內存,最重要的是,產生極少數量的視覺令牌。
DeepEncoder通過一個巧妙的兩階段過程實現這一目標:
- 第一階段:使用窗口注意力(window attention)來感知細粒度細節,就像我們的眼睛專注於場景的一小部分一樣。
- 第二階段:在傳遞信息之前,使用強大的16倍卷積壓縮器。這是秘密武器。它在信息進入第二階段之前大幅縮減令牌數量,第二階段使用全局注意力來理解全貌。
技術創新的關鍵:智能壓縮時機
為什麼這是如此重要的突破?關鍵創新在於壓縮的時機和積極性。大多數傳統視覺編碼器在面對高分辨率圖像時,只是產生大量令牌洪流,然後壓垮必須理解所有這些令牌的語言模型。DeepEncoder更智能——它在到達計算成本最高的部分(全局注意力階段)之前智能地下采樣信息。
這就像在開始真正複雜的食譜之前預處理和濃縮配料。這種設計允許模型從高分辨率輸入中看到更多細節,而不會產生嚴重的計算成本,使其完美適合光學壓縮任務。
令人印象深刻的性能表現
有了這個高效編碼器,真正的問題變成:它真的有效嗎?性能數據確實令人印象深刻。在一個基準測試中,DeepSeek-OCR能夠以10:1的比例壓縮文本——意味着文本令牌數量是視覺令牌數量的十倍——同時在文本解碼中仍然達到超過97%的準確率。即使被推到極端的20:1壓縮比,它仍保持約60%的準確率。

在另一個基準測試中,它超越了現有模型,使用顯著更少的視覺令牌實現了更好或相當的結果。這不僅僅是實驗室實驗;該模型足夠高效,可以在生產中使用,能夠在單台機器上每天從超過200,000頁生成訓練數據。
技術驗證與未來前景
這些結果真正驗證了整個概念。在10倍壓縮比下能夠獲得近乎無損重建的事實意味着這是一個可行的、實用的策略。這表明我們可以構建具有更大有效上下文窗口的LLM。
這也開啓了迷人的可能性,比如創建模仿人類記憶的系統。遺忘不僅僅是缺陷;它是我們優先處理信息方式的特徵。AI可能能夠做類似的事情,通過將較舊或不太相關的信息更積極地壓縮為模糊、低令牌圖像,同時保持最近上下文的清晰度。DeepSeek-OCR的成功表明,這種基於視覺的上下文管理方法是值得探索的道路。
關鍵技術要點總結
第一,光學壓縮——將文本轉換為圖像以輸入LLM——是解決長上下文問題的真正有前途的解決方案。它允許顯著的令牌減少,從7到20倍,同時保持高準確率。
第二,這種效率的秘密在於新穎的DeepEncoder架構。通過在最苛刻的計算階段之前智能壓縮視覺令牌,它成功地處理高分辨率信息而沒有通常的內存和處理成本。
第三,這不僅僅是理論模型。DeepSeek-OCR在困難的文檔解析基準測試中提供最先進的性能,在證明其對抗其他方法的能力的同時,令牌效率要高得多。
第四,整個方法具有巨大的實際意義。它不僅對生成大量訓練數據有用,而且為構建能夠處理超長上下文甚至模擬類人記憶機制的AI新研究開闢了道路。
產業影響與應用前景
從技術角度來看,DeepSeek-OCR代表了AI領域的一個重要里程碑。對於企事業單位和科研院所而言,這項技術具有多重價值:
研究機構應用:研究圖書館的全文分析、大規模文獻綜述、歷史檔案數字化處理等場景將得到革命性提升。
企業級應用:企業可利用此技術處理海量文檔、合同分析、知識管理系統優化,顯著提升信息處理效率。
投資價值分析:該技術解決了LLM發展中的核心瓶頸問題,具有廣闊的商業化前景和投資潛力。特別是在數據密集型行業,如金融、法律、醫療等領域。
技術發展趨勢
DeepSeek-OCR的成功驗證了多模態AI發展的重要方向。未來可能的發展包括:
- 更高壓縮比:隨着算法優化,壓縮比有望進一步提升
- 多模態融合:結合音頻、視頻等其他模態信息
- 邊緣計算應用:優化後可能實現移動端部署
- 專業領域定製:針對不同行業需求進行專門優化