支持向量機 (三): 優化方法與支持向量迴歸
優化方法
一、SMO算法
回顧 支持向量機 (二) 中 (1.7)(1.7) 式最後要求解的優化問題:

在求出滿足條件的最優 αα 後,即可得 svm 模型的參數 (w,b)(w,b) ,進而獲得分離超平面。可以用通用的二次規劃算法求解,該二次規劃問題有 mm 個變量 ( mm 為樣本數), (m+1)(m+1) 項約束,所以當樣本容量 mm 很大時,問題變得不可解,而本節介紹的 SMO(sequential minimal optimization)算法就是高效求解上述問題的算法之一。
SMO 算法將原來非常大的二次規劃問題分解成了一系列非常小的可解的二次規劃問題。SMO 算法最誘人的地方在於,這些分解後小的二次規劃問題 ,都是擁有解析解的,也就是説,求解這些小的二次規劃優化問題不需要通過非常耗時的循環來得到問題的結果。由於不需要矩陣計算,使得 SMO 算法 在實際的數據集的測試中,其計算複雜度介於線性複雜度和二次複雜度之間。SMO 算法的計算複雜度和 svm 的模型也有關係,比如線性核 svm 計算速度較快。在實際測試中發現,如果訓練樣本是稀疏數據集,那麼SMO 算法的效率會極其高。
SMO算法的基本思路是:選擇兩個變量 α1α1和 α2α2 ,固定其他所有 αi(i=3…m)αi(i=3…m),僅針對這兩個變量構建二次規劃問題,這樣就比原來複雜的優化問題簡化很多。由於有約束條件 m∑i=1αiyi=0∑i=1mαiyi=0 ,固定了其他 αi(i=3…m)αi(i=3…m) 後,可得 α1y1+α2y2=−m∑i=3αiyiα1y1+α2y2=−∑i=3mαiyi 。所以 α1α1 確定後,α2α2 即可自動獲得,則該小型二次規劃問題中的兩個變量會同時更新,接着再不斷選取新的變量進行優化。
如何在每一步選擇合適的 αα 進行優化? SMO 採用啓發式的變量選擇方法:第 1 個變量 α1α1 ,一般選擇訓練樣本中違反 KKT 條件最嚴重的樣本點所對應的 αα 。而第 2 個變量 α2α2 則選取與 α1α1 的樣本點之間間隔最大的樣本點對應的 αα ,這樣二者的更新往往會給目標函數帶來更大的變化。這裏的 KKT 條件具體指的是:

其中 f(xi)=w⊤xi+b=m∑j=1αjyjx⊤ixj+bf(xi)=w⊤xi+b=∑j=1mαjyjxi⊤xj+b 。還有一點就是,由於 KKT 條件過於地嚴格,比如 yif(xi)=1yif(xi)=1 ,這個條件一般很難達到,所以在檢驗 KKT 條件的時候,都是在一定的誤差範圍 ϵϵ 內檢驗 KKT 條件的, 即 |yif(xi)−1|<ϵ|yif(xi)−1|<ϵ 。
在選擇了合適的變量後,下面來看如何解 α1α1 和 α2α2:
若不考慮約束項 (1.2)(1.2) 和 (1.3)(1.3) ,由於固定了其他所有 αi(i=3…m)αi(i=3…m) ,因此設 α1y1+α2y2=−m∑i=3αiyi=ζα1y1+α2y2=−∑i=3mαiyi=ζ ,利用 y2i=1yi2=1 兩邊同乘以 y1y1 ,則 α1=(ζ−α2y2)y1α1=(ζ−α2y2)y1 ,代入 (1.1)(1.1) 式並求導即可得最優的 α2α2 ,繼而利用上式求得 α1α1 。
然而由於約束項 (1.3)(1.3) 的存在,α1α1 和 α2α2 必須位於 [0,C]×[0,C][0,C]×[0,C] 圍成的矩形區域內; 且由於約束項 (1.2)(1.2) 的存在, α1y1+α2y2=−m∑i=3αiyi=ζα1y1+α2y2=−∑i=3mαiyi=ζ ,又由於 y1y1, y2y2 只能取 +1+1 和 −1−1 ,所以在第一種情況 —— y1y1 和 y2y2 異號時,α1α1 和 α2α2 位於直線 α1−α2=ζα1−α2=ζ 上 (這裏取 y1=1,y2=−1y1=1,y2=−1 ,反過來情況類似),如下圖:
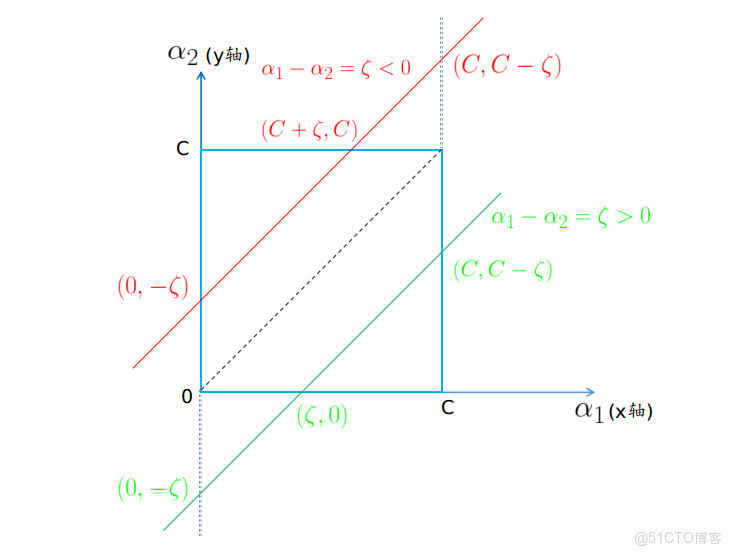
這裏採用迭代優化,假設上一輪迭代得到的最優解是 αold1α1old 和 αold2α2old,本輪迭代完成後的解為 αnew1α1new 和 αnew2α2new。由於要滿足約束條件,αnew2α2new 存在下界 LL 和上界 HH ,即: L⩽αnew2⩽HL⩽α2new⩽H 。
假設要求 α2α2 的最小值,從圖中可以看到只有當 α1=0α1=0 時,α2α2 可以在矩形區域內的直線 α1−α2=ζα1−α2=ζ 上取得最小值。此時 αnew2=−ζ=αold2−αold1α2new=−ζ=α2old−α1old ( 後面一個等式是因為 ζζ 是常數 ) ,從圖中也顯示紅線和綠線與 yy 軸都相交於 (0,−ζ)(0,−ζ) ,然而由於約束 0⩽α2⩽C0⩽α2⩽C 的存在,圖中綠線的下端點只能取到 (ζ,0)(ζ,0) ,所以綜合這兩種情況 α2α2 的下界 L=max(0,−ζ)=max(0,αold2−αold1)L=max(0,−ζ)=max(0,α2old−α1old) 。
同理要求 α2α2 的最大值,只有當 α1=Cα1=C 時,α2α2 可以在矩形區域內的直線 α1−α2=ζα1−α2=ζ 上取得最大值。紅線和綠線與 yy 軸都相交於 (C,C−ζ)(C,C−ζ) ,然而由於約束 0⩽α2⩽C0⩽α2⩽C 的存在,圖中紅線的上端點只能取到 (C+ζ,C)(C+ζ,C) ,所以綜合下來 α2α2 的上界 H=min(C,C−ζ)=min(C,C+αold2−αold1)H=min(C,C−ζ)=min(C,C+α2old−α1old) 。
第二種情況 —— y1y1 和 y2y2 同號時,α1α1 和 α2α2 位於直線 α1+α2=ζα1+α2=ζ 上 (這裏取 y1=1,y2=1y1=1,y2=1 ,反過來情況類似),如下圖:
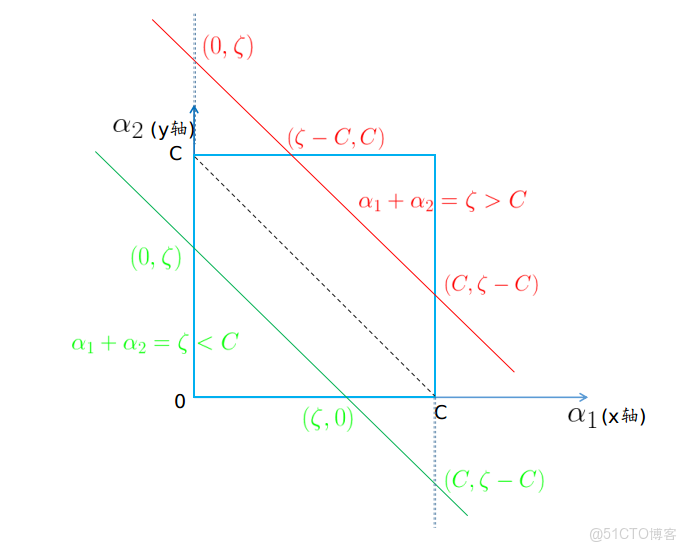
假設要求 α2α2 的最小值,從圖中可以看到只有當 α1=Cα1=C 時,α2α2 可以在矩形區域內的直線 α1+α2=ζα1+α2=ζ 上取得最小值。此時 αnew2=ζ−C=αold1+αold2−Cα2new=ζ−C=α1old+α2old−C ,從圖中也顯示紅線和綠線與 yy 軸都相交於 (C,ζ−C)(C,ζ−C) ,然而由於約束 0⩽α2⩽C0⩽α2⩽C 的存在,圖中綠線的下端點只能取到 (ζ,0)(ζ,0) ,所以綜合這兩種情況 α2α2 的下界 L=max(0,ζ−C)=max(0,αold1+αold2−C)L=max(0,ζ−C)=max(0,α1old+α2old−C) 。
同理要求 α2α2 的最大值,只有當 $\alpha_1 = 0時,0時,\alpha_2$ 可以在矩形區域內的直線 α1+α2=ζα1+α2=ζ 上取得最大值。紅線和綠線與 yy 軸都相交於 (0,ζ)(0,ζ) ,然而由於約束 0⩽α2⩽C0⩽α2⩽C 的存在,圖中紅線的上端點只能取到 (ζ−C,C)(ζ−C,C) ,所以綜合下來 α2α2 的上界 H=min(C,ζ)=min(C,αold1+αold2)H=min(C,ζ)=min(C,α1old+α2old) 。
於是在 L⩽αnew2⩽HL⩽α2new⩽H 的約束範圍內求得 αnew2α2new 後,繼而從 α1y1+α2y2=−m∑i=3αiyi=ζα1y1+α2y2=−∑i=3mαiyi=ζ 中求得 αnew1α1new ,這樣 α1α1 和 α2α2 就同時得到了更新。接下來不斷選擇變量進行優化,當所有 αiαi 都滿足 KKT 條件時,算法終止,求得了最優的 αi,i=1,2,…mαi,i=1,2,…m 。
二、Hinge Loss 梯度下降
svm 使用的損失函數為 hinge loss,即為:

hinge losshinge loss 使得 yf(x)>1yf(x)>1 的樣本損失皆為 0,由此帶來了稀疏解,使得 svm 僅通過少量的支持向量就能確定最終超平面。下面來看 hinge loss 是如何推導出來的,支持向量機 (二) 中 (1.1)(1.1) 式帶軟間隔的 svm 最後的優化問題為:

(1.5)(1.5) 式重新整理為 ξi⩾1−yi(w⊤xi+b)ξi⩾1−yi(w⊤xi+b) 。若 1−yi(w⊤xi+b)<01−yi(w⊤xi+b)<0 ,由於約束(1.6)(1.6) 的存在,則 ξi⩾0ξi⩾0 ;若1−yi(w⊤xi+b)⩾01−yi(w⊤xi+b)⩾0 ,則依然為 ξi⩾1−yi(w⊤xi+b)ξi⩾1−yi(w⊤xi+b) 。所以 (1.5),(1.6)(1.5),(1.6) 式結合起來:

又由於 (1.4)(1.4) 式是最小化問題,所以取 ξiξi 的極小值,即令 ξi=max(0,1−yf(x))ξi=max(0,1−yf(x)) 代入 (1.4)(1.4) 式,並令λ=12Cλ=12C :
svm 中最常用的優化算法自然是上文中的 SMO 算法,不過有了損失函數後也可以直接優化。由於 hinge loss 在 yi(wTxi+b)=1yi(wTxi+b)=1 處不可導,因而無法直接使用梯度下降,不過可以通過求次梯度 (subgradient) 來進行優化:

支持向量迴歸
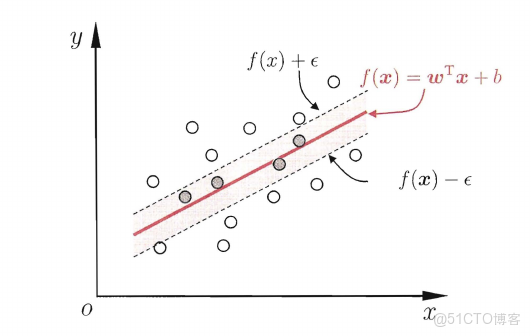
前文主要敍述支持向量機用於分類問題,當然其也可用於迴歸問題。給定一組數據 {(x1,y1),(x2,y2),…,(xm,ym)}{(x1,y1),(x2,y2),…,(xm,ym)} ,其中 xi∈Rdxi∈Rd ,yi∈Ryi∈R ,迴歸問題希望學得一個模型 f(x)=w⊤x+bf(x)=w⊤x+b ,使得 f(x)f(x) 與 yy 儘可能接近 。傳統的迴歸模型通常基於模型輸出 f(x)f(x) 與真實輸出 yy 之間的差別來計算損失。當且僅當 f(x)f(x) 與 yy 完全相同時,損失才為零。支持向量迴歸 ( Support Vector Regression,以下簡稱 svrsvr ) 與之不同,它假設能容忍 f(x)f(x) 與 yy 之間最多有 ϵϵ 的偏差,即僅當 |f(x)−y|>ϵ|f(x)−y|>ϵ 時,才計算損失。如下圖所示,svrsvr 相當於以 f(x)f(x) 為中心,構建了一個寬度為 ϵϵ 的間隔帶。若訓練樣本落在此間隔帶內則被認為是預測正確的。
svrsvr 的損失函數由此被稱為 ϵ−insensitive errorϵ−insensitive error ,形如 :

本質上我們希望所有的模型輸出 f(x)f(x) 都在 ϵϵ 的間隔帶內,因而與 支持向量機 (一) 中的 (1.3)(1.3) 式一樣,我們可以定義 svrsvr 的優化目標:

同樣類似於 支持向量機 (二) 中的 (1.1)(1.1) 式,可以為每個樣本點引入鬆弛變量 ξ>0ξ>0,即允許一部分樣本落到間隔帶外,使得模型更加 robust 。由於這裏用的是絕對值,實際上是兩個不等式,也就是説兩邊都需要鬆弛變量,我們定義為 ξ∨i,ξ∧iξi∨,ξi∧ ,於是優化目標變為:
上式中的 CC 和 ϵϵ 分別對應 scikit-learn 的 SVR 中的參數 CC 和 epsilonepsilon ,CC 越大,意味着對離羣點的懲罰就越大,最終就會有較少的點跨過間隔邊界,模型也會變得複雜。而 CC 設的越小,則較多的點會跨過間隔邊界,最終形成的模型較為平滑。而 epsilonepsilon 越大,則對離羣點容忍度越高,最終的模型也會較為平滑,這個參數是 svrsvr 問題中獨有的,svm 中沒有這個參數。
對於 (2.3)(2.3) 式,為每條約束引入拉格朗日乘子 μ∨i⩾0,μ∧i⩾0,α∨i⩾0,α∧i⩾0μi∨⩾0,μi∧⩾0,αi∨⩾0,αi∧⩾0 :
其對偶問題為:

上式對 w,b,ξ∨i,ξ∧iw,b,ξi∨,ξi∧ 求偏導為零可得:

將 (2.6)∼(2.9)(2.6)∼(2.9) 式代入 (2.4)(2.4) 式,並考慮由(2.8),(2.9)(2.8),(2.9) 式得 C−αi=ui⩾0C−αi=ui⩾0 ,因而 0⩽αi⩽C0⩽αi⩽C 得化簡後的優化問題:

上述求最優解的過程需滿足 KKTKKT 條件,其中的互補鬆弛條件為 :

若樣本在間隔帶內,則 ξi=0ξi=0 , |yi−w⊤x−b|<ϵ|yi−w⊤x−b|<ϵ ,於是要讓互補鬆弛成立,只有使 α∨i=0,α∧i=0αi∨=0,αi∧=0 ,則由 (2.6)(2.6) 式得 w=0w=0 ,説明在間隔帶內的樣本都不是支持向量,而對於間隔帶上或間隔帶外的樣本,相應的 α∨iαi∨ 或 α∧iαi∧ 才能取非零值。此外一個樣本不可能同時位於 f(x)f(x) 的上方和下方,所以 (2.11)(2.11) 和 (2.12)(2.12) 式不能同時成立,因此 α∨iαi∨ 和 α∧iαi∧ 中至少一個為零。
優化問題 (2.10)(2.10) 同樣可以使用二次規劃或 SMO 算法求出 αα ,繼而根據 (2.6)(2.6) 式求得模型參數 w=∑mi=1(α∧i−α∨i)xiw=∑i=1m(αi∧−αi∨)xi 。而對於模型參數 bb 來説,對於任意滿足 0<αi<C0<αi<C 的樣本,由 (2.13)(2.13) 和 (2.14)(2.14) 式可得 ξi=0ξi=0 ,進而根據 (2.11)(2.11) 和 (2.12)(2.12) 式:

則 svrsvr 最後的模型為:

支持向量機算法總結
支持向量機的優點:
- 解決高維特徵的分類問題和迴歸問題很有效,在特徵維度大於樣本數時依然有很好的效果。
- 僅僅使用一部分樣本決定超平面,內存佔用少。
- 有大量的核函數可以使用,從而可以很靈活的來解決各種非線性的分類迴歸問題。
支持向量機的缺點:
- 當採用核函數時,如果需要存儲核矩陣,則空間複雜度為 O(m2)O(m2) 。
- 選擇核函數沒有通用的標準 (當然其實是有的,見下文~) 。
- 樣本量很大時,計算複雜度高。
對於第 3 個缺點,scikit-learn 的 SVC 文檔中有一句話:
The fit time scales at least quadratically with the number of samples and may be impractical beyond tens of thousands of samples.
我特意去查了下字典,”tens of thousands“ 意為 ”好幾萬“,也就是説對於幾萬的數據 svm 處理起來就已經很捉急了,至於百萬到億級的數據基本就不用想了,這在如今這個大數據時代確實不夠看,不過這裏説的是使用核函數的 svm。而對於線性 svm 來説,情況要好很多,一般為 O(m)O(m)。
LibSVM 的作者,林智仁教授在其一篇小文(A Practical Guide to Support Vector Classification)中提出了 svm 庫的一般使用流程 :

其中第二步 scaling 對於 svm 的整體效果有重大影響。主要原因為在沒有進行 scaling 的情況下,數值範圍大的特徵會產生較大的影響,進而影響模型效果。
第三步中認為應優先試驗 RBF 核,通常效果比較好。但他同時也提到,RBF 核並不是萬能的,在一些情況下線性核更加適用。當特徵數非常多,或者樣本數遠小於特徵數時,使用線性核已然足夠,映射到高維空間作用不大,而且只要對 C 進行調參即可。雖然理論上高斯核的效果不會差於線性核,但高斯核需要更多輪的調參。

下表總結了 scikit-learn 中的 svm 分類庫:
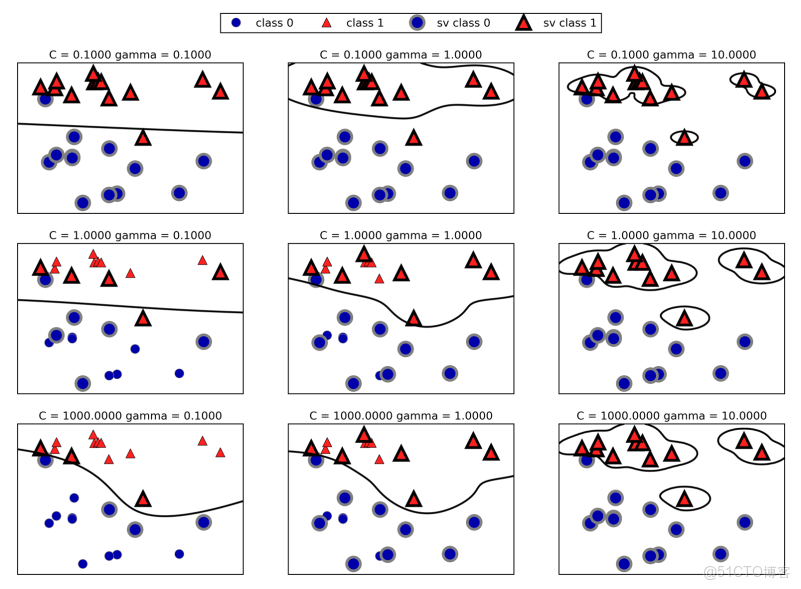
scikit-learn 中 svm 庫的兩個主要超參數為 CC 和 γγ ,CC 和 γγ 越大,則模型趨於複雜,容易過擬合;反之,CC 和 γγ 越小,模型變得簡單,如下圖所示: