
目錄
- 條件
- 安裝
- scala
- 發到虛擬機上,解壓
- 配置環境變量
- 配置SCALA_HOME,然後在PATH變量後加上`:$SCALA_HOME/bin`
- 驗證
- spark
- 下載
- 解壓
- 配置環境變量
- 配置SPARK_HOME,在PATH後加上`:$SPARK_HOME/bin`
- 配置文件
- copy一份 slaves.template到slaves中,並進行修改
- 測試
- 啓動Spark Shell命令行窗口
- 啓動spark
- 訪問http://192.168.199.100:8080/
- 怎麼查看job
- 啓動歷史服務器,需要指定hdfs目錄(hdfs目錄連不上或者不存在,那就無法啓動)
- 訪問
- 配置,不想每次都輸入hdfs目錄
- spark-submit測試
條件
jdk
hadoop
安裝
scala
https://www.scala-lang.org/download/
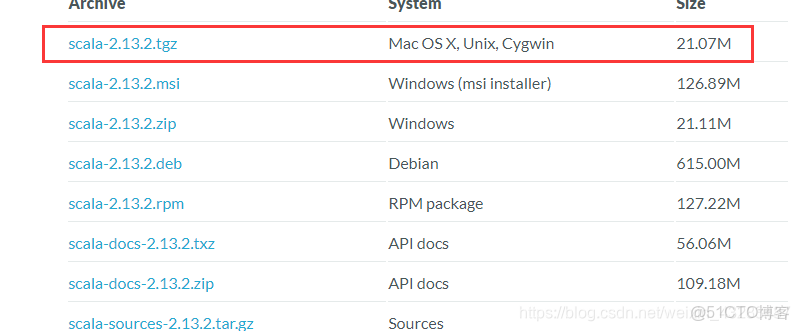
發到虛擬機上,解壓
tar -zxvf ./scala-2.13.2.tgz
mv scala-2.13.2 /usr/local/配置環境變量
vim /etc/profile
source /etc/profile配置SCALA_HOME,然後在PATH變量後加上:$SCALA_HOME/bin
#scala
export SCALA_HOME=/usr/local/scala-2.13.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin驗證
scala -version
出現
Scala code runner version 2.13.2 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.spark
下載
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz

解壓
tar -zxvf ./spark-2.4.5-bin-hadoop2.7.tgz
mv ./spark-2.4.5-bin-hadoop2.7 /usr/local/bigdata/配置環境變量
vi /etc/profile
source /etc/profile配置SPARK_HOME,在PATH後加上:$SPARK_HOME/bin
export SPARK_HOME=/usr/local/bigdata/spark-2.4.5-bin-hadoop2.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin配置文件
spark配置給了一些模板,我們可以copy一份改名,修改一下就可以用了
cd ./spark-2.4.5-bin-hadoop2.7/conf/copy一份spark-env.sh.template到spark-env.sh中,並進行修改
cp ./spark-env.sh.template spark-env.sh加上
export SCALA_HOME=/usr/local/scala-2.13.2
export JAVA_HOME=/usr/local/jdk1.8
export SPARK_HOME=/usr/local/bigdata/spark-2.4.5-bin-hadoop2.7
export SPARK_MASTER_IP=localhost
export SPARK_EXECUTOR_MEMORY=1Gcopy一份 slaves.template到slaves中,並進行修改
cp slaves.template slaves
vim slaves
測試
跑一個自帶的demo
./bin/run-example SparkPi 10
啓動Spark Shell命令行窗口
spark-shell啓動spark
./sbin/start-all.sh你看start-all.sh 和hadoop命令是不是衝突了
我們改一下名字
mv start-all.sh start-spark-all.sh
mv stop-all.sh stop-spark-all.sh訪問http://192.168.199.100:8080/

jps
10577 Master
10657 Worker
8153 SparkSubmit
10715 Jps怎麼查看job
每次spark運行完,就無法查看spark application
啓動歷史服務器,需要指定hdfs目錄(hdfs目錄連不上或者不存在,那就無法啓動)
./sbin/start-history-server.sh hdfs://standalone:9000/spark/history訪問
http://192.168.199.100:18080/?showIncomplete=false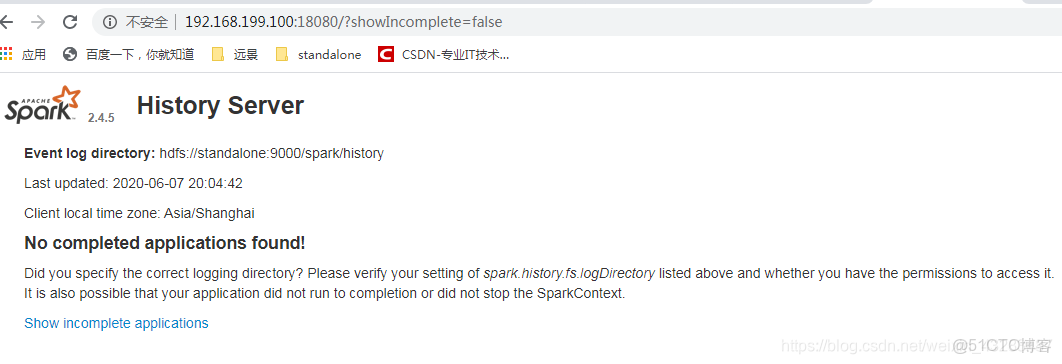
大概就是沒有權限的意思
hadoop fs -chgrp -R root/spark配置,不想每次都輸入hdfs目錄
./run-example org.apache.spark.examples.SparkPi這種是不顯示在spark-submit裏面的
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://standalone:9000/spark/history
spark.eventLog.compress truevim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=20 -Dspark.history.fs.logDirectory=hdfs://standalone:9000/spark/history"spark.history.ui.port=18080 調整WEBUI訪問的端口號為18080
spark.history.fs.logDirectory=hdfs://hadoop000:8020/directory 配置了該屬性後,在start-history-server.sh時就無需再顯示的指定路徑
spark.history.retainedApplications=20 指定保存Application歷史記錄的個數,如果超過這個值,舊的應用程序信息將被刪除
直接啓動就可以
./sbin/start-history-server.shspark-submit測試
./bin/run-example SparkPi 10是不會記錄在Application中的
跑一個spark-submit試一下
spark-submit \
--master local[2] \
--class RddTest \
--executor-memory 2G \
--total-executor-cores 2 \
/home/hht/sparksubmitdemo-1.0-SNAPSHOT.jar<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hht</groupId>
<artifactId>sparksubmitdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.3.0</spark.version>
<scala.version>2.11</scala.version>
<hadoop.version>2.6.0</hadoop.version>
<mysql.version>5.1.38</mysql.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>import org.apache.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkContext, sql}
import org.apache.spark.sql.SparkSession
object RddTest {
def main(args: Array[String]): Unit = {
val sparkSession = new spark.sql.SparkSession
.Builder()
.appName("wc")
.getOrCreate()
val sc: SparkContext = sparkSession.sparkContext
val list = List("rose is beautiful", "jennie is beautiful", "lisa is beautiful", "jisoo is beautiful")
val list_rdd: RDD[String] = sc.parallelize(list)
list_rdd.foreach(println)
//把一句話拆分成單詞
val flat_rdd = list_rdd.flatMap(_.split(" "))
flat_rdd.foreach(println)
//將每個單詞變成kv結構
val map_rdd = flat_rdd.map(word => (word,1))
map_rdd.foreach(println)
//聚合
val reduce_rdd = map_rdd.reduceByKey(_+_)
reduce_rdd.foreach(println) }
}