
本文詳細解析阿里Qwen3大模型的架構與實現。首先介紹Qwen3在代碼、數學等領域的出色性能,然後深入解析其模型結構,包括輸入處理、Transformer塊、GQA注意力機制、前饋網絡和RMSNorm歸一化等。文章提供了完整的PyTorch代碼實現,從Qwen3Model到各個組件,幫助讀者理解大模型的工作原理和實現細節。
引言
2025年4月29號,阿里千問團隊發表了Qwen3模型,這是 Qwen 系列大型語言模型的最新成員。他們的旗艦模型 Qwen3-235B-A22B 在代碼、數學、通用能力等基準測試中,與 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等頂級模型相比,表現出極具競爭力的結果。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活參數數量是 QwQ-32B 的 10%,表現更勝一籌,甚至像 Qwen3-4B 這樣的小模型也能匹敵 Qwen2.5-72B-Instruct 的性能。

Qwen3模型結構
1、輸入處理:輸入的文本首先被轉換為token ID序列,通過嵌入層將token轉換為向量表示。
2、核心Transformer塊:Qwen3由多個相同的Transformer塊堆疊而成,每個塊包含以下組件:
3、自注意力機制:使用多頭自注意力機制,能夠捕捉輸入序列中各個token之間的關係。
4、歸一化層:採用RMSNorm替代LayerNorm,在每個自注意力層和前饋網絡之後進行歸一化處理。
5、前饋網絡:使用GEGLU或SwiGLU激活函數,增強模型的表達能力。
輸出層:通過RMSNorm後,使用QWenLMHead生成下一個token的預測概率分佈。
模型結構如下圖所示:
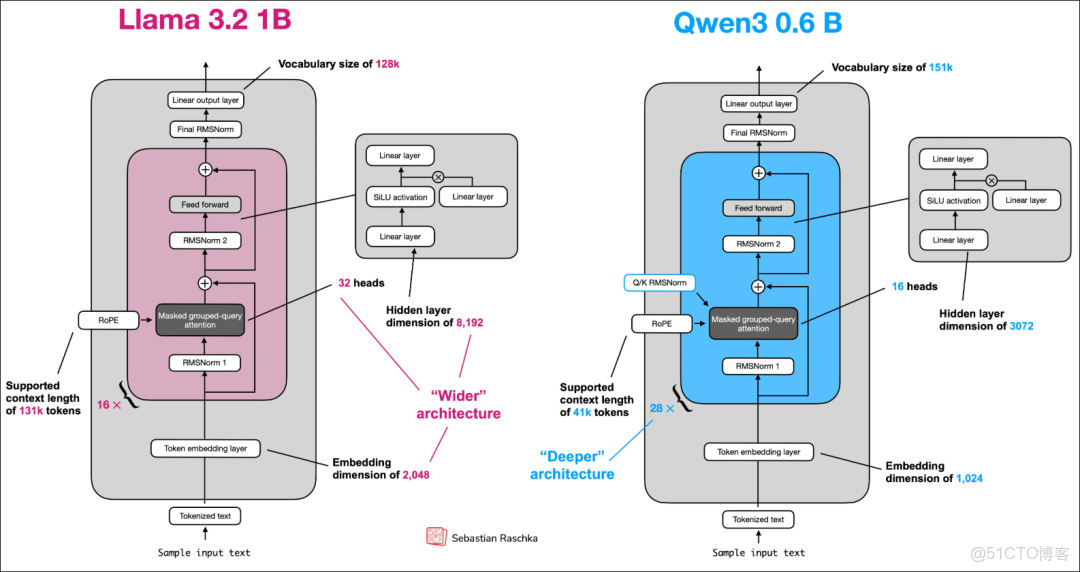
整體實現
根據上面的五個組成部分,我們分別來進行一個實現。
1、數據輸入處理,通過加載tokenizer,將輸入的input text轉為token_ids
device = torch.device("gpu") # 這裏根據實際情況選擇,可以是cpu,也可以是gpu
tokenizer_file_path = Path("qwen3") / "tokenizer-base.json"
model_file = Path("qwen3") / "qwen3-0.6B-base.pth"
tokenizer = Qwen3Tokenizer(tokenizer_file_path=tokenizer_file_path)
model = Qwen3Model(QWEN_CONFIG_06_B)
model.load_state_dict(torch.load(model_file))
model.to(device)
prompt = "什麼是大語言模型?"
input_token_ids_tensor = torch.tensor(
tokenizer.encode(prompt),
device=device
).unsqueeze(0)接下來的代碼都可以在這裏獲取:
接下來我們進行第二步,Qwen3網絡結構整體編碼。
2、Qwen3網絡結構編碼
class Qwen3Model(nn.Module):
def __init__(self, cfg):
super().__init__()
# 模型的主要參數, 開源模型一般就是config.json文件裏面的參數
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"],
dtype=cfg["dtype"])
# 大模型層數
self.trf_blocks = nn.ModuleList(
[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
self.final_norm = RMSNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False,
dtype=cfg["dtype"])
# rope 旋轉位置編碼
if cfg["head_dim"] is None:
head_dim = cfg["emb_dim"] // cfg["n_heads"]
else:
head_dim = cfg["head_dim"]
cos, sin = compute_rope_params(
head_dim=head_dim,
theta_base=cfg["rope_base"],
context_length=cfg["context_length"]
)
self.register_buffer("cos", cos, persistent=False)
self.register_buffer("sin", sin, persistent=False)
self.cfg = cfg
self.current_pos = 0 # kvcache使用
def forward(self, in_idx, cache=None):
tok_embeds = self.tok_emb(in_idx)
x = tok_embeds
num_tokens = x.shape[1]
if cache is not None: # kvcache
pos_start = self.current_pos
pos_end = pos_start + num_tokens
self.current_pos = pos_end
mask = torch.triu(
torch.ones(pos_end, pos_end, device=x.device, dtype=torch.bool),
diagonal=1
)[pos_start:pos_end, :pos_end]
else:
pos_start = 0 # Not strictly necessary but helps torch.compile
mask = torch.triu(
torch.ones(num_tokens, num_tokens, device=x.device,
dtype=torch.bool),
diagonal=1
)
# Shape (1, 1, num_tokens, num_tokens) to broadcast across batch and heads
mask = mask[None, None, :, :]
for i, block in enumerate(self.trf_blocks):
blk_cache = cache.get(i) if cache else None
x, new_blk_cache = block(x, mask, self.cos, self.sin,
start_pos=pos_start,
cache=blk_cache)
if cache is not None:
cache.update(i, new_blk_cache)
x = self.final_norm(x)
logits = self.out_head(x.to(self.cfg["dtype"]))
return logits
def reset_kv_cache(self):
self.current_pos = 0這部分代碼就是整個Qwen3 核心所在:
第一步:完成了了input text 到token ids的過程;
第二步(看結構圖): Token embedding layer ,通過nn.embedding將token ids 轉為embedding
第三步(看圖,紅色塊): Transfomer Block,通過trf_blocks封裝包含RMSNorm、GQA、FFN
第四步:Final RMSNorm , 對應代碼中的 self.final_norm(x)
最後:Linear output layer, 對應 self.out_head
3、Transformer Block 編碼
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention( # GQA實現
d_in=cfg["emb_dim"],
num_heads=cfg["n_heads"],
head_dim=cfg["head_dim"],
num_kv_groups=cfg["n_kv_groups"],
qk_norm=cfg["qk_norm"],
dtype=cfg["dtype"]
)
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-6)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-6)
def forward(self, x, mask, cos, sin, start_pos=0, cache=None):
# Shortcut connection ,一種特殊的殘差連接
shortcut = x
x = self.norm1(x)
x, next_cache = self.att(
x, mask, cos, sin, start_pos=start_pos,cache=cache
) # Shape [batch_size, num_tokens, emb_size]
x = x + shortcut
# Shortcut connection for feed-forward block
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = x + shortcut # Add the original input back
return x, next_cache這部分代碼是Transformer Block核心(看途中紅色或藍色框):
第一步: self.norm1(x) 參數歸一化,後面緊跟着GQA
第二步:GQA,GQA是什麼結構,可以參考下圖
第三步:shortcut connnection
第四步: self.norm2(x)
第五步:self.ff(x)
第六步:shortcut connnection
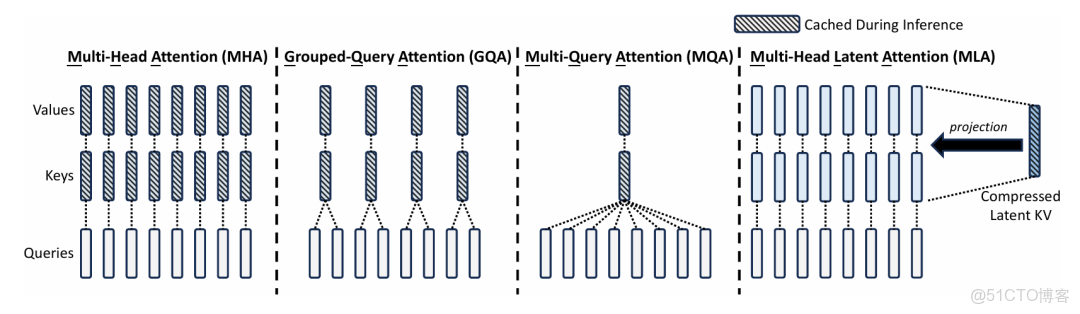
4、GQA的編碼
很多模型都會在這個基礎去創新,比如最開始的MHA–>GQA–>MQA–>MLA,通過上圖可以看到GQA核心是將KV進行分組,多個Q給到分組的KV(核心參數:num_kv_groups),從而減少計算和內存開銷。
class GroupedQueryAttention(nn.Module):
def __init__(self,d_in, num_heads , num_kv_groups ,head_dim =None,qk_norm=False,dtype=None):
super().__init__()
assert num_heads % num_kv_groups == 0
self.num_heads = num_heads
self.num_kv_groups = num_kv_groups
self.group_size = num_heads // num_kv_groups
if head_dim is None:
assert d_in % num_heads ==0
head_dim = d_in // num_heads
self.head_dim = head_dim
self.d_out = num_heads * head_dim
self.W_query = nn.Linear(d_in, self.d_out,bias=False,dtype=dtype)
self.W_key = nn.Linear(d_in,num_kv_groups * head_dim , bias=False,dtype=dtype)
self.W_value = nn.Linear(d_in,num_kv_groups * head_dim,bias=False,dtype=dtype)
self.out_proj = nn.Linear(self.d_out,d_in,bias=False,dtype=dtype)
if qk_norm:
self.q_norm = RMSNorm(head_dim,eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self,x,mask,cos,sin,start_pos=0,cache=None):
b, num_tokens,_ = x.shape
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
queries = queries.view(b,num_tokens,self.num_heads,self.head_dim).transpose(1,2)
keys_new = keys.view(b,num_tokens,self.num_kv_groups,self.head_dim).transpose(1,2)
values_new = values.view(b,num_tokens,self.num_kv_groups,self.head_dim).transpose(1,2)
if self.q_norm:
queries =self.q_norm(queries)
if self.k_norm:
keys_new = self.k_norm(keys)
queries = apply_rope(queries,cos,sin,offset=start_pos)
keys_new = apply_rope(keys_new,cos,sin,offset=start_pos)
if cache is not None:
prev_k , prev_v = cache
keys = torch.cat([prev_k,keys_new],dim=2)
values = torch.cat([prev_v,values_new],dim=2)
else:
start_pos = 0
keys ,values = keys_new,values_new
next_cache = (keys, values)
keys = keys.repeat_interleave(self.group_size,dim=1)
values = values.repeat_interleave(self.group_size,dim=1)
attn_scores = queries @ keys.transpose(2, 3)
attn_scores = attn_scores.masked_fill(mask, -torch.inf)
attn_weights = torch.softmax(attn_scores / self.head_dim**0.5, dim=-1)
context = (attn_weights @ values).transpose(1,2)
context = context.reshape(b,num_tokens,self.d_out)
return self.out_proj(context),next_cache這裏整個代碼就是GQA的實現邏輯,核心還是QKV分組、維度對齊、計算的過程。接下來我們看看FFN
5、FFN實現
class FeedForward(nn.Module):
def __init__(self,cfg):
super().__init__()
self.fc1 = nn.Linear(cfg["emb_dim"],cfg["hidden_dim"],dtype=cfg["dtype"],bias=False)
self.fc2 = nn.Linear(cfg["emb_dim"],cfg["hidden_dim"],dtype=cfg["dtype"],bias=False)
self.fc3 = nn.Linear(cfg["emb_dim"],cfg["hidden_dim"],dtype=cfg["dtype"],bias=False)
def forward(self,x):
x_fc1 = self.fc1(x)
x_fc2 = self.fc2(x)
x = nn.functional.silu(x_fc1) * x_fc2
return self.fc3(x)FFN實現相對簡單,一個多層感知機,通過三個線性層以及激活函數完成,
6、RMSNorm歸一化
歸一化是為了讓參數在某一個範圍內,以致模型訓練過程比較穩定
class RMSNorm(nn.Module):
def __init__(self,emb_dim, eps=1e-6, bias =False, qwen3_compatible=True):
super().__init__()
self.eps = eps
self.qwen3_compatible = qwen3_compatible
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim)) if bias else None
def forward(self,x):
input_dtype = x.dtype
if self.qwen3_compatible:
x = x.to(torch.float32)
variance = x.pow(2).mean(dim=-1, keepdim=True)
norm_x = x * torch.rsqrt(variance + self.eps)
norm_x = norm_x * self.scale
if self.shift is not None:
norm_x = norm_x + self.shift
return norm_x.to(input_dtype)具體公式可參考:
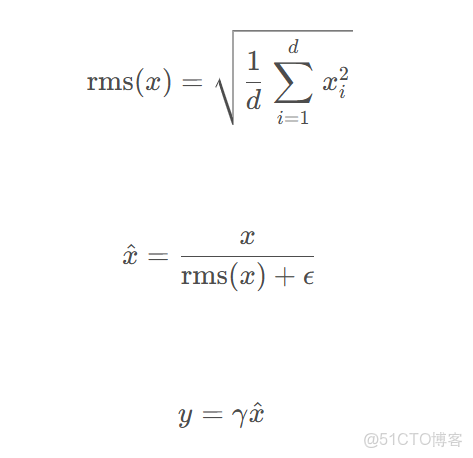
整體的一個Qwen3的網絡結構代碼完成了,至於更深層次的一些隱藏原理和訓練過程,後續可以一起探討。