
2025年11月12日,OpenAI 發佈了 GPT-5 系列的重要更新版本 GPT-5.1,包括 GPT-5.1 Instant(即時版)和 GPT-5.1 Thinking(思維版)兩個變體。這次更新不僅在技術能力上有所提升,更值得關注的是其在對話風格上的顯著變化,而這一變化正在社區中引發激烈討論。
技術升級:智能與效率的平衡
GPT-5.1 Instant 的自適應推理
GPT-5.1 Instant 引入了一項關鍵技術創新——自適應推理能力。這個模型現在能夠自主判斷何時需要在回答前進行"思考"。對於簡單的問題,模型會快速給出答案;而面對複雜問題時,它會先進行內部推理,確保答案的準確性和完整性。
這種自適應機制在數學和編程評估中表現尤為突出。在 AIME 2025 數學競賽和 Codeforces 編程測試中,GPT-5.1 Instant 取得了明顯的性能提升。技術文檔顯示,模型在指令遵循方面也有顯著改進,能更可靠地按照用户的具體要求作答。
舉個實例,當用户要求"始終用六個字回覆"時,GPT-5.1 Instant 能夠穩定地維持這一約束,而早期版本往往會在對話中逐漸偏離這種限制。
GPT-5.1 Thinking 的動態時間分配
GPT-5.1 Thinking 在前代基礎上優化了思考時間的分配策略。根據官方數據,在代表性任務集上:
- 第10百分位的簡單任務:響應速度提升約57%(幾乎快了一倍)
- 第90百分位的複雜任務:思考時間增加約71%(深度提升約70%)
- 中位數任務保持不變
-
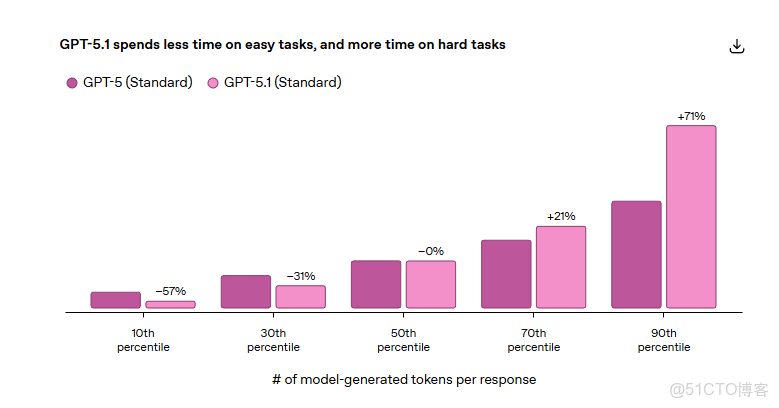
這種動態調整意味着用户在處理簡單問題時不必等待不必要的"思考"過程,而在面對真正複雜的問題時,模型會投入更多計算資源來確保答案質量。
技術上看,這種時間分配的精確控制體現了模型在元認知層面的進步——它不僅知道如何解決問題,還能評估問題的複雜度並相應調整策略。
對話風格的轉變:引發的爭議
"更人性化"的設計理念
OpenAI 在博客中明確表示:“筆者清楚地聽到用户反饋,出色的 AI 不僅要智能,還要具備愉快的交流體驗。” 基於這一理念,GPT-5.1 默認採用了更加親切、更具同理心的對話風格。
以壓力緩解場景為例,當用户表達"感到壓力很大,需要一些放鬆技巧"時:
GPT-5 會直接列出方法:
- 深呼吸法(4-7-8呼吸法)
- 漸進式放鬆
- 落地法(5-4-3-2-1感官練習)
GPT-5.1 Instant 則採用更温暖的語氣:
“Ron,筆者理解你,這完全正常,尤其考慮到你最近的種種事務。以下是一些根據你感受到的壓力類型,可以幫助你放鬆的方法……”
這種轉變在技術層面意味着模型被訓練或調優成能夠識別情感線索,並相應地調整迴應的語氣和結構。
社區的兩極分化反應
Hacker News 上的討論清晰地展現了用户羣體的分歧:
反對"人性化"的聲音佔據了相當比重。用户 直言:“真是愚蠢,他們試圖讓它更像人類。應該添加一個單選按鈕來關閉這些定製,因為這對某些用户並沒有幫助,只會讓人惱火。它應該是一個應答機器,而不是某種情感支持系統。”
技術用户表示正在尋找"去除 LLM 交流中所有華而不實的廢話,讓它們簡潔明瞭"的方法。這反映了一部分用户對效率的追求——他們希望 AI 是精確的工具,而非對話夥伴。
用户 甚至提出:“筆者不想要一個更具對話性的 GPT。筆者想要的恰恰相反。筆者希望’對話’的上限類似於《星際迷航》中的 LCARS(星艦計算機系統)。”
支持方的觀點同樣值得關注。用户指出:“典型的 HN(Hacker News)讀者思維——認為他們想要的就是全世界想要的。” 這個評論揭示了一個關鍵問題:技術社區的需求可能並不代表大眾用户的偏好。
從商業角度分析:“如果這確實是大多數人要求的,那麼從商業角度來看,讓模型滿足用户期望是合理的。讓所有人滿意是極其困難的。”
安全性評估:在能力與控制之間的權衡
基準安全測試結果
GPT-5.1 的系統卡(System Card)提供了詳細的安全性評估數據。值得注意的是,OpenAI 現在使用"生產基準測試"(Production Benchmarks)——這是一個更具挑戰性的評估集,基於生產環境中的困難案例構建。
在禁止內容類別中(數值越高越好,1.0為完美):
|
類別
|
GPT-5 Thinking
|
GPT-5.1 Thinking
|
GPT-5 Instant
|
GPT-5.1 Instant
|
|
非法/非暴力內容
|
0.865
|
0.860
|
0.807
|
0.853
|
|
騷擾內容
|
0.815
|
0.747
|
0.745
|
0.836
|
|
性相關內容
|
0.906
|
0.895
|
0.951
|
0.917
|
|
仇恨言論
|
0.883
|
0.839
|
0.806
|
0.897
|
數據顯示了一個複雜的圖景:GPT-5.1 Thinking 在騷擾和仇恨言論檢測上有輕微退步,而 GPT-5.1 Instant 在大多數類別上都有改進。
來源:https://cdn.openai.com/pdf/4173ec8d-1229-47db-96de-06d87147e07e/5_1_system_card.pdf
新增的敏感對話評估
此次更新引入了兩個新的評估維度:
心理健康評估:覆蓋用户可能出現孤立妄想、精神病或躁狂症狀的情況。GPT-5.1 Instant 在此項上得分0.883,相比早期版本的0.251有大幅提升。
情感依賴評估:評估與對 ChatGPT 不健康的情感依賴或依戀相關的輸出。GPT-5.1 Instant 得分0.945,也顯示出明顯改進。
這些新增評估反映了 OpenAI 對 AI 伴侶化趨勢的警覺。社區中 notarobot123 的評論頗具洞察力:“情感依賴必然是任何科技產品最具粘性的特徵。他們知道自己在做什麼。”
對抗性測試與視覺安全
在 jailbreak(越獄)測試中,GPT-5.1 Instant 表現優異,安全率達到0.976,而早期版本僅為0.683。這表明新模型在抵禦惡意提示方面有顯著進步。
視覺輸入安全性方面,GPT-5.1 在處理圖文組合的禁止內容時整體表現穩定,但在自傷類圖像提示上,GPT-5.1 Thinking 出現了退步(從0.976降至0.936),OpenAI 表示正在改進這一問題。
個性化控制:試圖調和的矛盾
預設語氣選項的優化
OpenAI 顯然意識到了用户需求的多樣性。此次更新對個性化設置進行了重大改進,提供了六種預設語氣:
- 默認:平衡的風格和語氣
- 專業:精緻精確
- 友好:熱情健談
- 坦率:直接而鼓勵
- 古怪:有趣且富有想象力
- 高效:簡潔明瞭
、專業(精緻精確)、友好(熱情健談)、坦率(直接而鼓勵)、古怪( playful and imaginative,當前選中)、高效(簡潔明瞭)、書呆子(探索性和熱情)和憤世嫉俗。")
實際使用中的問題
儘管提供了這些選項,用户反饋仍然揭示了一些問題。用户 pants2 指出:“'高效’模式會給出非常簡短的答案,缺乏解釋或背景。‘書呆子’模式似乎最好,但在 GPT-5 即時版中極其尷尬,比如’筆者戴上了書呆子帽——既然你是軟件工程師,筆者會確保給你關於煮米飯的極客細節。’”
更嚴重的是"提示表演"(prompt performance)現象。用户 gnat 抱怨:“嘗試進行一系列來回對話,每個回覆都像’明白了,保持簡短和專業。是的,只有七宗罪。'你得到的是更多的提示表演而非答案。”
這個問題在技術上很有啓發性。用户 jjcob 推測:“可能是使用 LLM 評估其他 LLM 輸出的結果。如果明確聲明自己正在遵循指令,LLM 可能會獲得更高分數……”
另一個技術細節來自用户 cma 的觀察:OpenAI 可能使用廉價勞動力進行評估,工人在選擇 A/B 答案時,知道自己被相互評估,因此傾向於選擇"多數人的選擇"而非真實評價。這種評估機制本身可能導致模型過度強調"遵循指令"的表演。
技術視角下的深層思考
指令遵循的矛盾
GPT-5.1 聲稱改進了指令遵循能力,但實際表現顯示了一個有趣的矛盾:模型太過於"意識到"自己在遵循指令,以至於不斷提醒用户這一點。這在技術上可能源於 RLHF(人類反饋強化學習)過程中的過度優化——模型學會了顯式展示其遵從性以獲得更高評分。
情感計算的邊界
有用户(pmarreck)觀察到一個有趣現象:“如果對模型大喊大叫(全大寫、咒罵),它們的表現會變差,類似於人類。所以如果你相信某種程度的’友好回答’可能有助於提高正確性,既然某種程度的不友好互動似乎會產生較低的正確性,那麼你可能不得不接受某種個性。”
這個觀察揭示了一個深層問題:模型的表現可能真的與"情感"語境相關。這不是説模型有真實情感,而是説在訓練數據中,友好語境往往伴隨着高質量的回答,而敵對語境則相反。因此,保持某種"情感"基線可能對性能有實際影響。
安全性與能力的權衡
系統卡中一個值得注意的細節:GPT-5.1 Thinking 在某些安全類別上出現退步,特別是在騷擾和仇恨言論檢測方面。這可能暗示着一個技術難題:提升推理能力和對話自然度的同時,維持或提高安全性並非易事。
更深層次地看,"更人性化"本身就可能增加安全風險。人類對話充滿細微差別、暗示和情感線索,這些特徵使得安全邊界更難界定。一個更"機械"的回答風格,雖然可能顯得冷漠,但在安全控制上卻可能更加可靠。
延伸討論
説白了,GPT-5.1 的升級就像一面鏡子,一下把大家對大模型 的各種情緒都照了出來——有人覺得它更聰明更自然了,有人又擔心太“像人”不太舒服。對用户來説,更像是一次新的實驗:看看我們到底希望大模型離人類多近,離工具多遠。






