
代碼已放在:https://github.com/yanqiangmiffy/Agent-Tutorials-ZH/tree/main/deep_research_agent
什麼是深度研究智能體?
簡單來説,深度研究智能體(Deep Research Agents)是能夠對預設主題進行深入研究的系統。通常,這至少包括以下幾個步驟:
- 規劃研究: 這可能涉及創建研究報告的提綱,該提綱最終將成為系統的輸出。
- 拆解任務: 將上述提綱拆分為可管理的步驟。
- 深入研究: 對報告的各個部分進行深入研究,這意味着需要推理出提供全面分析所需的數據,並利用網絡搜索工具來支持分析。
- 數據反思: 反思研究過程中不同步驟生成的數據,並改進結果。
- 總結報告: 總結檢索到的數據,並撰寫最終的研究報告。
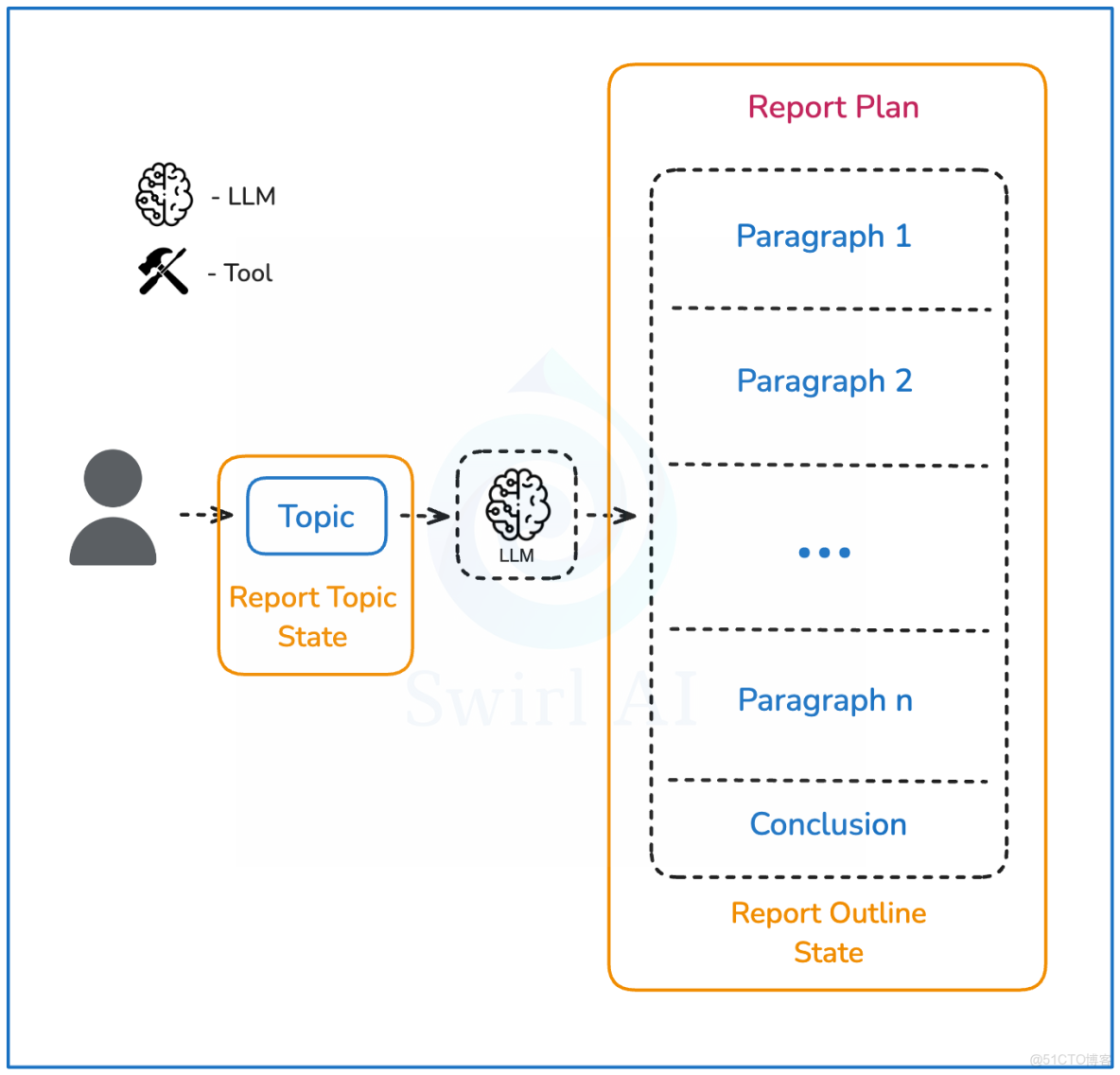
系統架構
下圖展示了我們將要構建的系統,該系統將執行以下步驟:
- 用户提供一個需要研究的查詢或主題。
- 大模型(LLM)將創建一個最終報告的提綱,並被指示生成的段落數量不超過某個限制。
- 每個段落的描述將單獨輸入到一個研究流程中,以生成一套全面的信息用於報告構建。研究流程的詳細描述將在下一節中闡述。
- 所有信息將進入總結步驟,構建最終報告,包括結論。
- 報告將以 Markdown 形式交付給用户。
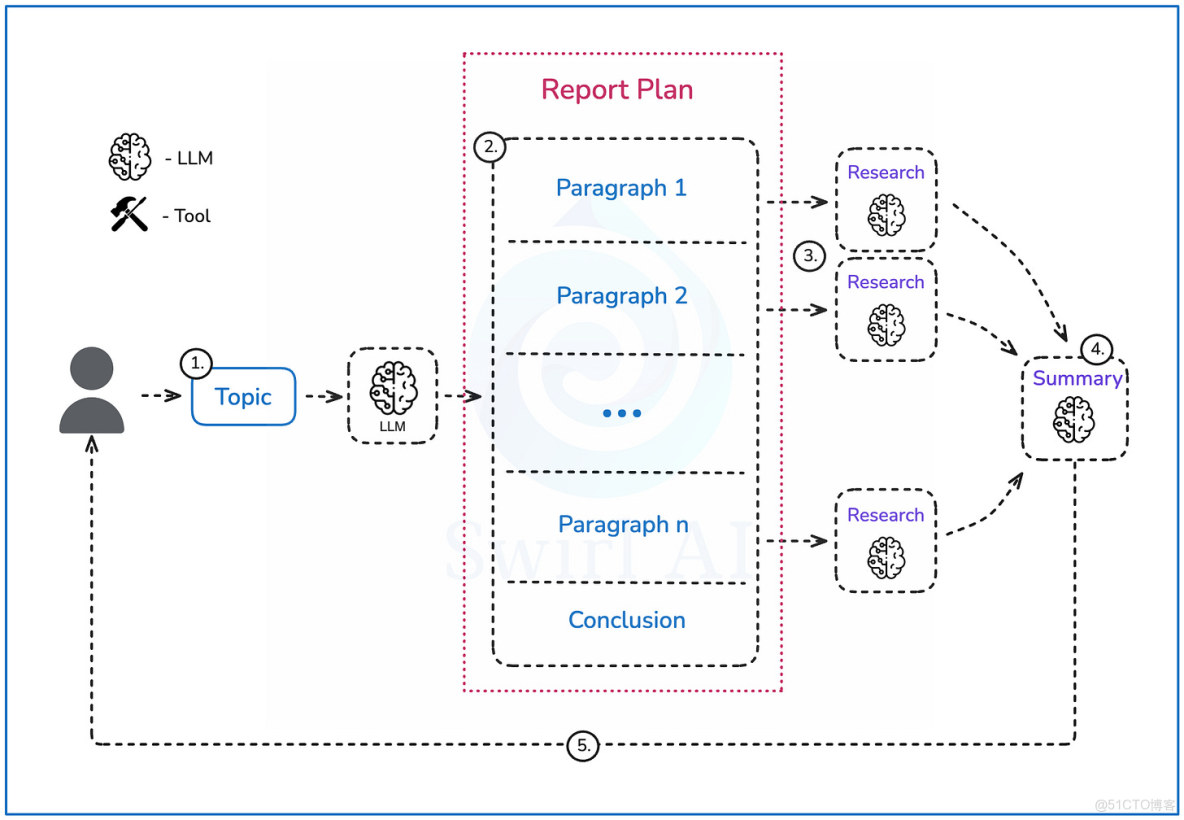
深度研究智能體結構示意圖
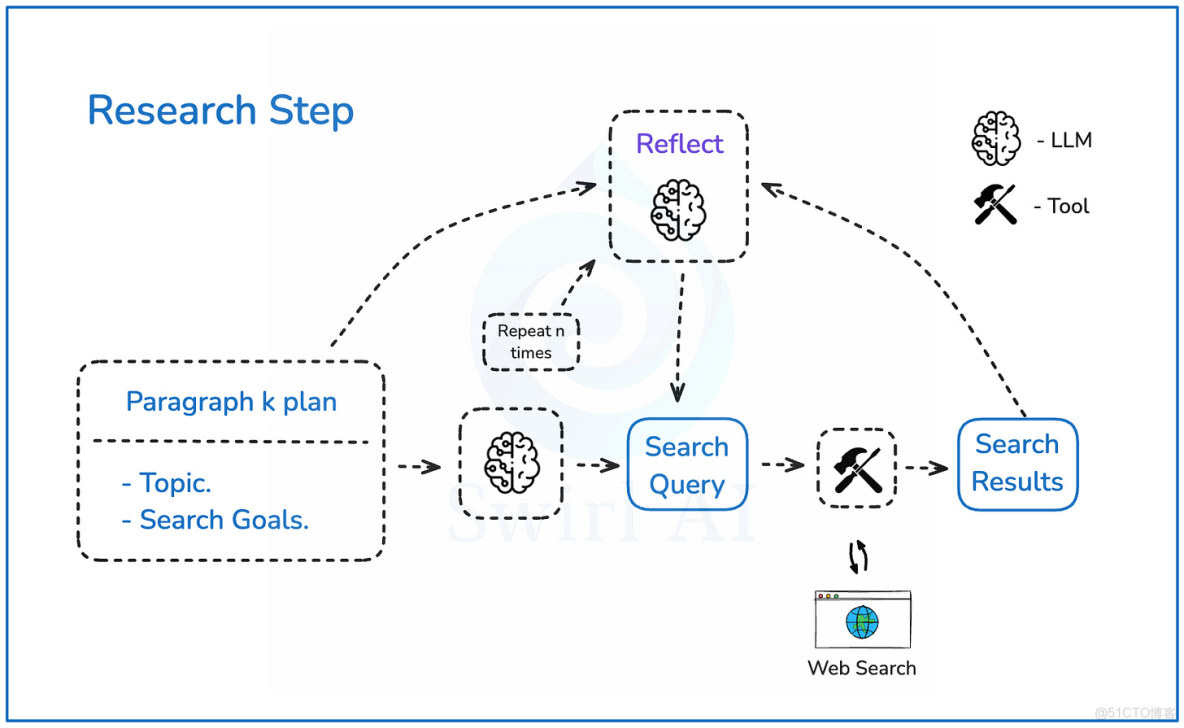
研究步驟
讓我們深入探討上一段中定義的研究步驟:
- 一旦我們有了每個段落的提綱,它將被傳遞給一個大模型(LLM),以構建網絡搜索查詢,從而儘可能豐富所需信息。
- LLM 將輸出搜索查詢及其背後的推理。
- 我們將根據查詢執行網絡搜索,並檢索最相關的結果。
- 結果將被傳遞到反思步驟,LLM 將在此處對任何遺漏的細微之處進行推理,並嘗試提出能夠豐富初始結果的搜索查詢。
- 這個過程將重複 n次,以期獲得最佳信息集。
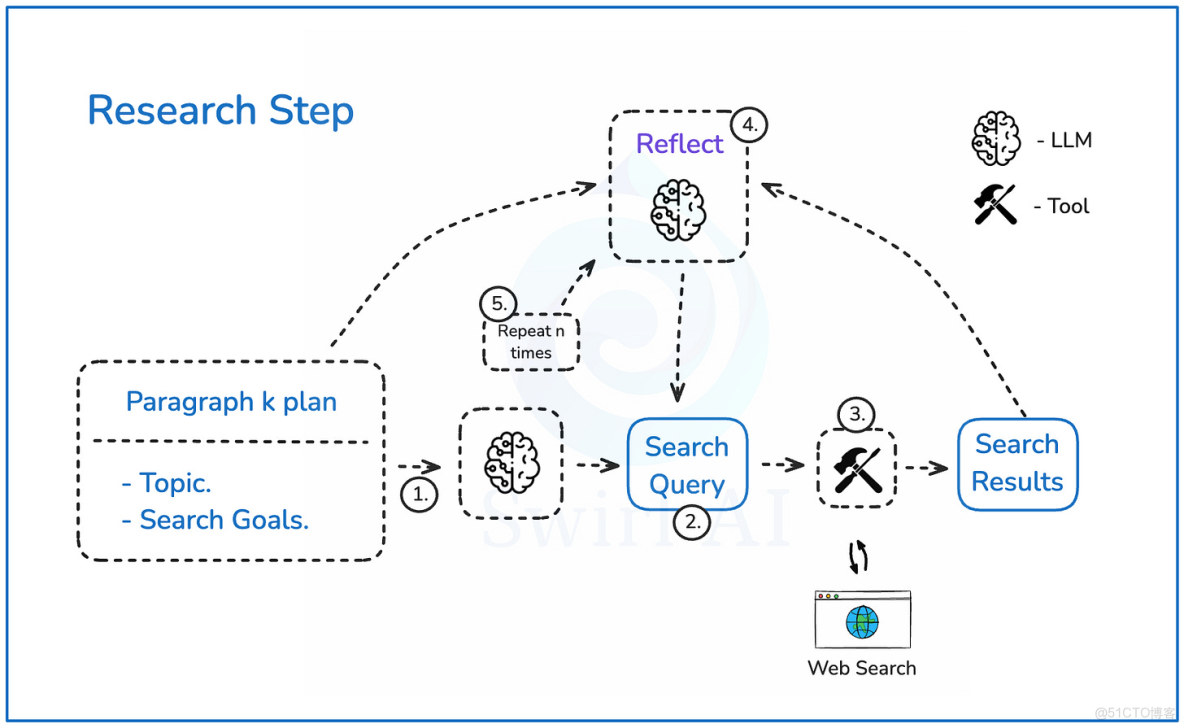
研究步驟示意圖
實現智能體
在進入實現階段之前,我們先做一些技術準備。比如準備一些API KEY,我這裏是直接使用的Deepseek,大家可以替換下下面的api_key和base_url
pip install openai本項目我們將使用未蒸餾的 DeepSeek-R1 版本,其參數量為 671B。
import os
import openai
client = openai.OpenAI(
api_key=os.environ.get("SAMBANOVA_API_KEY"),
base_url="https://preview.snova.ai/v1",
)
response = client.chat.completions.create(model="DeepSeek-R1",
messages=[{"role":"system","content":"You are a helpful assistant"},\
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)您應該會看到類似以下內容:
<think>
Okay, so I'm trying to ... <REDACTED>
</think>
The human species is distinguished by the remarkable cognitive abilities of the brain, which underpin a array of unique traits. Our brain's advanced structure and function enable complex thought, language, and social organization. These capabilities have driven innovation, art, and the creation of intricate societies, setting humans apart in their ability to adapt, innovate, and create beyond any other species. This cognitive prowess is the cornerstone of human achievement and our profound impact on the world.
```答案中將始終包含推理標記。雖然看到思考過程很有趣,但我們的系統只需要答案。這時我們可以創建一個清理函數來刪除 `<think>` 標籤之間的所有內容。
```python
def remove_reasoning_from_output(output):
return output.split("</think>")[-1].strip()這個函數簡單但實用。
這裏可以替換為DeepSeek的api情求方式:
第一部分:定義狀態
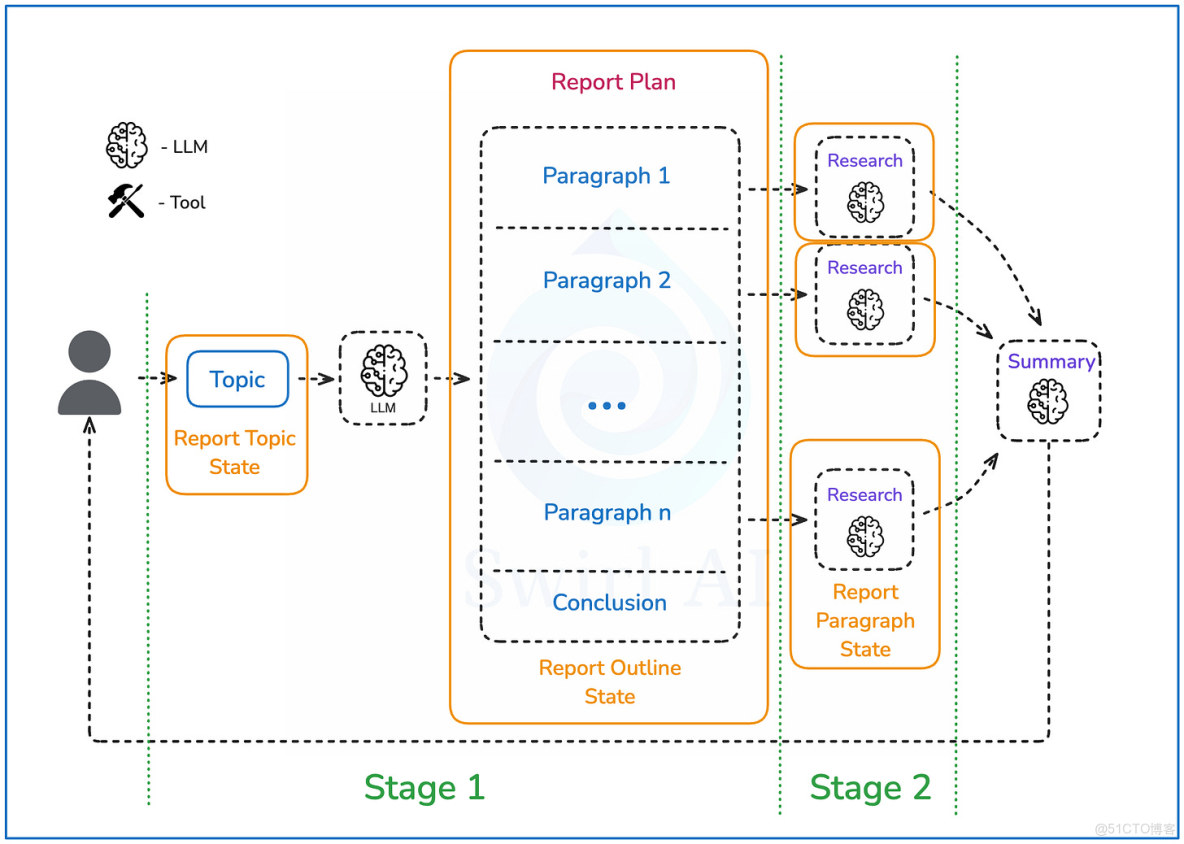
首先,我們需要定義整個系統的狀態,該狀態將在智能體(Agent)在環境中運行時不斷演進,並被系統的不同部分選擇性地使用。
我們將狀態與智能體系統的階段關聯起來:
中間狀態
- 階段 1 將是創建大綱,在此階段報告結構將被規劃,其狀態也會隨之演進。我們將從一個空狀態開始,然後將其演變為類似以下結構(推理在階段 2 中描述):
{
"report_title": "報告標題",
"paragraphs": [
{
"title": "段落標題",
"content": "段落內容",
"research": <...>
},
{
"title": "段落標題",
"content": "段落內容",
"research": <...>
}
]
}上述狀態可以使用 Python 的 dataclasses 庫優雅地實現,如下所示:
@dataclass
class Paragraph:
title: str = ""
content: str = ""
research: Research = field(default_factory=Research)
@dataclass
class State:
report_title:str = ""
paragraphs: List[Paragraph] = field(default_factory=list)- 階段 2 是我們將迭代每個段落狀態的階段。我們將更改每個段落的 "
research"字段。我們將使用以下結構來表示每個段落的研究狀態:
{
"search_history": [{"url": "某個 URL", "content": "某個內容"}],
"latest_summary": "組合搜索歷史的摘要",
"reflection_iteration": 1
}
研究步驟示意圖
search_history:我們將所有執行的搜索存儲在一個列表中,我們將同時需要 URL 和內容,以便我們可以對搜索結果進行去重,並在稍後形成最終報告時引用這些鏈接。
latest_summary:根據所有搜索結果給出的段落的總結版本。它將用於反思步驟,以確定是否需要更多搜索,並傳遞給摘要和報告創建的下一步。
reflection_iteration:這用於跟蹤當前反思迭代的次數,並在達到限制時強制停止。
同樣,我們可以通過 dataclasses 實現研究狀態:
@dataclass
class Search:
url: str = ""
content: str = ""
@dataclass
class Research:
search_history: List[Search] = field(default_factory=list)
latest_summary: str = ""
reflection_iteration: int = 0第二部分:創建報告大綱
不同模型版本在生成答案時的一致性會有所不同。我在 DeepSeek-R1 上進行了大量實驗,以下提示詞似乎能持續生成格式良好的輸出:
output_schema_report_structure = {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},"content": {"type": "string"}
}
}
}
SYSTEM_PROMPT_REPORT_STRUCTURE = f"""
你是一個深度研究助手。給定一個查詢,你需要為報告計劃一個結構,包括要包含的段落。
確保段落的順序合乎邏輯。
一旦創建了大綱,你將獲得工具來分別搜索網絡並對每個部分進行反思。
使用以下 JSON 模式定義來格式化輸出:<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_report_structure, indent=2)}
</OUTPUT JSON SCHEMA>
“title”和“content”屬性將用於更深層次的研究。
確保輸出是一個 JSON對象,並符合上面定義的輸出 JSON 模式。
只返回 JSON 對象,不需要任何解釋或額外文本。
"""注意這個提示語可以根據不同的模型效果進行調整
段落結構的狀態
讓我們使用上述系統提示詞運行一些示例查詢:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_REPORT_STRUCTURE},\
{"role":"user","content":"告訴我一些關於人類物種的有趣事情"}],
temperature=1
)
print(response.choices[0].message.content)您將得到類似以下內容:
```json
[
{
"title": "人類適應性簡介",
"content": "人類擁有獨特的適應能力,這對於他們在各種環境中生存和佔據主導地位至關重要。本簡介將為探索人類適應性的各個方面奠定基礎。"
},
...
<REDACTED>
...
{
"title": "結論:適應性在人類生存中的作用",
"content": "適應性一直是人類生存和進化的基石,使我們能夠面對挑戰並探索新領域,為未來的潛力提供了深刻見解。"
}
]輸出周圍的這些 JSON 標籤並無幫助,因為我們需要將輸出轉換為 Python 字典。一個非常簡單的函數可以刪除輸出的第一行和最後一行:
def clean_json_tags(text):
return text.replace("```json\n", "").replace("\n```", "")這是經過正確清理的輸出:
json.loads(clean_json_tags(remove_reasoning_from_output(response.choices[0].message.content)))我們現在可以直接將上述內容作為輸入到我們的全局狀態中。
STATE = State()
report_structure = json.loads(clean_json_tags(remove_reasoning_from_output(response.choices[0].message.content)))
for paragraph in report_structure:
STATE.paragraphs.append(Paragraph(title=paragraph["title"], content=paragraph["content"]))第三部分:Web 搜索工具
我們將使用 Tavily 執行網絡搜索。我們可以在此處獲取您的 Token,每個月可以免費1000次搜索,對於實驗demo足夠了
該工具非常簡單:
def tavily_search(query, include_raw_content=True, max_results=5):
tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily_client.search(query,
include_raw_content=include_raw_content,
max_results=max_results)每次函數調用將返回最多 max_results 條網絡搜索結果,每條搜索結果將返回:
- 搜索結果的標題。
- 搜索結果的 URL。
- 內容的摘要。
- 如果可能,返回頁面的完整內容。我們希望獲得完整內容以獲得最佳結果。
一旦我們從 Web 搜索工具中獲取結果,我們可以直接將其添加到全局狀態中,無需調用任何 LLM,但我們需要確保我們正在更新段落列表中的適當元素。
基本上,考慮到我們定義的結構:
{
"report_title": "報告標題",
"paragraphs": [
{
"title": "段落標題",
"content": "段落內容",
"research": <...>
},
{
"title": "段落標題",
"content": "段落內容",
"research": <...>
}
]
}並且考慮到我們正在研究第 i 個段落,我們需要更新 STATE.paragraphs[i].research 字段。
回顧研究字段的結構:
"search_history": [{"url": "某個 URL", "content": "某個內容"}],
"latest_summary": "組合搜索歷史的摘要",
"reflection_iteration": 1
}下面是一個方便的函數,它將根據 Tavily 搜索結果、段落索引和狀態對象正確更新狀態。
def update_state_with_search_results(search_results, idx_paragraph, state):
for search_result in search_results["results"]:
search = Search(url=search_result["url"], content=search_result["raw_content"])
state.paragraphs[idx_paragraph].research.search_history.append(search)
return state我們將追加到搜索歷史中。latest_summary 和 reflection_iteration 字段需要 LLM 的一些處理,將在第五部分:反思中討論。
第四部分:規劃搜索
為了規劃第一次搜索,我發現以下提示詞能持續產生良好的結果:
input_schema_first_search = {
"type":"object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}
output_schema_first_search = {"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SEARCH = f"""
你是一個深度研究助手。你將獲得一份報告中的一個段落,其標題和預期的內容,遵循以下 JSON 模式定義:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_first_search, indent=2)}
</INPUT JSON SCHEMA>
你可以使用一個網絡搜索工具,它接受“search_query”作為參數。
你的任務是反思這個主題,並提供最優的網絡搜索查詢來豐富你當前的知識。
使用以下 JSON 模式定義來格式化輸出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_first_search, indent=2)}
</OUTPUT JSON SCHEMA>確保輸出是一個 JSON 對象,並符合上面定義的輸出 JSON 模式。
只返回 JSON 對象,不需要任何解釋或額外文本。
"""我們在輸出模式中請求推理,只是為了強制模型對查詢進行更多思考。雖然這對於推理模型來説可能有些大材小用,但對於普通 LLM 來説可能是一個好主意。儘管我們正在為此使用 DeepSeek R1,但我們不一定需要。推理模型在深度研究智能體的第一步(需要規劃報告結構)中特別有用。
鑑於我們現在已經規劃好了一系列包含內容和描述的段落,我們可以將第三部分的輸出直接輸入到提示詞中,其形式如下:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_FIRST_SEARCH},{"role":"user","content":json.dumps(STATE.paragraphs[0])}],
temperature=1
)
print(response.choices[0].message.content)STATE.paragraphs[0] 指向第一個段落的狀態,其中 research 字段仍然為空。
我為我的第一個搜索計劃得到了以下內容:
{"search_query": "智人特徵 基本生物學特徵 認知能力 行為特徵"}我可以直接將查詢輸入到我的搜索工具中:
tavily_search("智人特徵 基本生物學特徵 認知能力 行為特徵")第五部分:第一次總結
第一次總結與即將到來的反思步驟不同,因為還沒有可供反思的內容,而這一步將產生反思的起點。以下提示詞效果相對較好:
input_schema_first_summary = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"search_query": {"type": "string"},
"search_results": {
"type": "array",
"items": {"type": "string"}
}
}
}
output_schema_first_summary= {
"type": "object",
"properties": {
"paragraph_latest_state": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SUMMARY = f"""
你是一個深度研究助手。你將獲得一個搜索查詢、搜索結果以及你正在研究的報告段落,遵循以下 JSON 模式定義:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_first_summary, indent=2)}
</INPUT JSON SCHEMA>
你的任務是作為一名研究員撰寫該段落,使用搜索結果來與段落主題保持一致,並將其適當地組織以包含在報告中。
使用以下 JSON 模式定義來格式化輸出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_first_summary, indent=2)}
</OUTPUT JSON SCHEMA>
確保輸出是一個 JSON 對象,並符合上面定義的輸出 JSON 模式。
只返回 JSON 對象,不需要任何解釋或額外文本。
"""我們現在需要以以下格式向 LLM 提供數據:
{
"title": "標題","content": "內容",
"search_query": "搜索查詢",
"search_results": []
}我們可以從已有的數據構建 JSON。
根據以下搜索結果:
search_results = tavily_search("智人特徵 基本生物學特徵 認知能力 行為特徵")JSON 將如下所示:
input = {
"title": "人類適應性簡介","content": "人類擁有獨特的適應能力,這對於他們在各種環境中生存和佔據主導地位至關重要。本簡介將為探索人類適應性的各個方面奠定基礎。",
"search_query": "智人特徵 基本生物學特徵 認知能力 行為特徵",
"search_results": [result["raw_content"][0:20000] for result in search_results["results"] if result["raw_content"]]
}然後我們可以運行:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_FIRST_SUMMARY},\
{"role":"user","content":json.dumps(input)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))您將得到類似以下內容:
{
"paragraph_latest_state": "智人,即現代人類所屬的物種,代表了地球生命進化史中獨特而迷人的一章。作為智人屬中唯一現存的物種,智人以其生物學、認知和行為特徵的結合而區別於其他靈長類動物和已滅絕的人類近親。我們的生物學特徵包括一個龐大且結構先進的大腦,其新皮層與我們的進化祖先相比顯著擴張。這種解剖學發展使得卓越的認知能力成為可能,例如複雜的解決問題、抽象思維以及語言和符號交流的能力。在行為方面,智人展現出複雜的社會結構、文化習俗和技術創新,這些在塑造我們適應各種環境和作為一個物種繁榮的能力方面至關重要。這些特徵共同強調了定義人類狀況的生物學和行為之間複雜的相互作用。"
}這正是我們將用於更新 STATE.paragraphs[0].research.latest_summary 字段的內容。在第六部分中,我們也將反思段落摘要的不斷更新的最新狀態。
第六部分:反思
我們現在擁有報告段落內容的最新狀態,並將利用它來改進內容,通過提示我們的 LLM 反思文本,並尋找它在起草該段落時可能遺漏的任何角度。
以下提示詞做得非常出色:
input_schema_reflection = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
output_schema_reflection = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_REFLECTION = f"""
你是一名深度研究助手。你負責為研究報告構建全面的段落。你將獲得段落標題和計劃內容摘要,以及你已經創建的段落的最新狀態,所有這些都遵循以下 JSON 模式定義:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_reflection, indent=2)}
</INPUT JSON SCHEMA>
你可以使用一個網絡搜索工具,它接受“search_query”作為參數。你的任務是反思當前段落文本的狀態,思考你是否遺漏了主題的某些關鍵方面,並提供最優的網絡搜索查詢來豐富最新狀態。
使用以下 JSON 模式定義來格式化輸出:
<OUTPUT JSON SCHEMA>
{json.dumps(output_schema_reflection, indent=2)}
</OUTPUT JSON SCHEMA>
確保輸出是一個 JSON 對象,並符合上面定義的輸出 JSON 模式。
只返回 JSON 對象,不需要任何解釋或額外文本。
"""對於我們當前正在實現的運行,輸入將如下所示:
input = {"paragraph_latest_state": "智人,即現代人類所屬的物種,代表了地球生命進化史中獨特而迷人的一章。作為智人屬中唯一現存的物種,智人以其生物學、認知和行為特徵的結合而區別於其他靈長類動物和已滅絕的人類近親。我們的生物學特徵包括一個龐大且結構先進的大腦,其新皮層與我們的進化祖先相比顯著擴張。這種解剖學發展使得卓越的認知能力成為可能,例如複雜的解決問題、抽象思維以及語言和符號交流的能力。在行為方面,智人展現出複雜的社會結構、文化習俗和技術創新,這在塑造我們適應各種環境和作為一個物種繁榮的能力方面至關重要。這些特徵共同強調了定義人類狀況的生物學和行為之間複雜的相互作用。",
"title": "引言",
"content": "人類物種,智人,是地球上最獨特和迷人的物種之一。本節將介紹人類的基本特徵,併為探索該物種的有趣方面奠定基礎。"}像之前一樣,我們運行以下代碼:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REFLECTION},\
{"role":"user","content":json.dumps(input)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))輸出如下:
{
"search_query": "關於智人進化的最新研究、與其他人類物種的互動以及促成其成功的因素",
"reasoning": "當前段落很好地概述了智人的特徵,但缺乏進化史以及與其他物種互動方面的深度。納入這些主題的最新研究將增強段落的全面性並提供最新信息。"
}現在我們運行查詢,將新結果附加到段落狀態,並將新結果與最新的段落狀態結合起來。
第七部分:通過反思搜索結果豐富最新段落狀態
在運行反思步驟的搜索查詢後:
search_results = tavily_search("關於智人進化的最新研究、與其他人類物種的互動以及促成其成功的因素")我們可以通過以下方式更新段落的搜索狀態:
update_state_with_search_results(search_results, idx_paragraph, state)現在我們將步驟 6. 和 7. 循環執行指定次數的反思步驟。
第八部分:總結並生成報告
我們對在第二部分中規劃的每個段落重複執行第四部分到第七部分的步驟。一旦所有段落的最終狀態都準備好,我們就可以將所有內容整合起來。我們將使用一個大模型(LLM)來完成這項工作,並生成一個格式精美的 Markdown 文檔。以下是提示詞:
input_schema_report_formatting = {
"type": "array",
"items": {
"type": "object",
"properties": {"title": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
}
SYSTEM_PROMPT_REPORT_FORMATTING = f"""你是一名深度研究助手。你已經完成了研究,並構建了報告中所有段落的最終版本。
你將以以下 JSON 格式獲取數據:
<INPUT JSON SCHEMA>
{json.dumps(input_schema_report_formatting, indent=2)}
</INPUT JSON SCHEMA>
你的任務是精美地格式化報告,並以 Markdown 格式返回。
如果報告中沒有“結論”段落,請根據其他段落的最新狀態將其添加到報告末尾。
"""運行:
report_data = [{"title": paragraph.title, "paragraph_latest_state": paragraph.research.latest_summary} for paragraphin STATE.paragraphs]
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REPORT_FORMATTING},\
{"role":"user","content":json.dumps(report_data)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))就這樣,我們就獲得了一份關於所提供主題的深度研究報告。
結論
此外,還有許多細微之處需要考慮,可以使系統更加穩定:
- 讓系統持續生成格式良好的 JSON 輸出並不容易,因為推理模型在結構化輸出方面並非總能表現最佳。
- 考慮到上述情況,在系統拓撲中為不同任務使用不同模型可能更有意義,我們主要在第一步(需要規劃報告結構)中真正需要推理模型。
- 在如何搜索網絡以及如何對檢索到的結果進行排序方面,還有許多可以改進的地方。
- 反思步驟的次數可以配置為動態,由 LLM 判斷是否需要更多反思。
- 我們可以返回在網絡搜索中使用的鏈接,並在報告中為每個段落提供參考文獻。
- ……
運行DeepResearch
為了更好看到Deepresearch執行的狀態,我用大模型幫我寫了一個streamlit應用,功能很簡單就是輸入研究主題,然後生成研究報告:
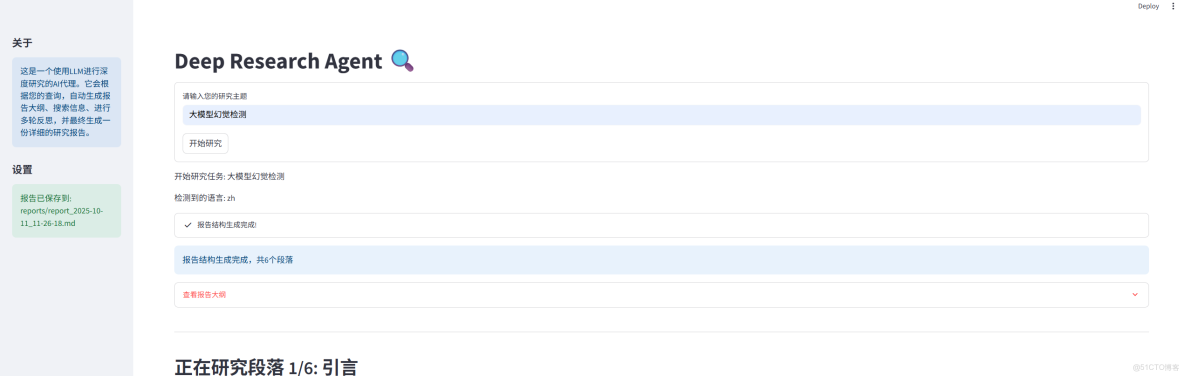
因為之前開源的代碼是英文的,我加了一個語言檢測的小邏輯,用來判斷是否使用中文提示語以及生成結果為中文。
修改之後的代碼在這:https://github.com/yanqiangmiffy/Agent-Tutorials-ZH/blob/main/deep_research_agent/app.py
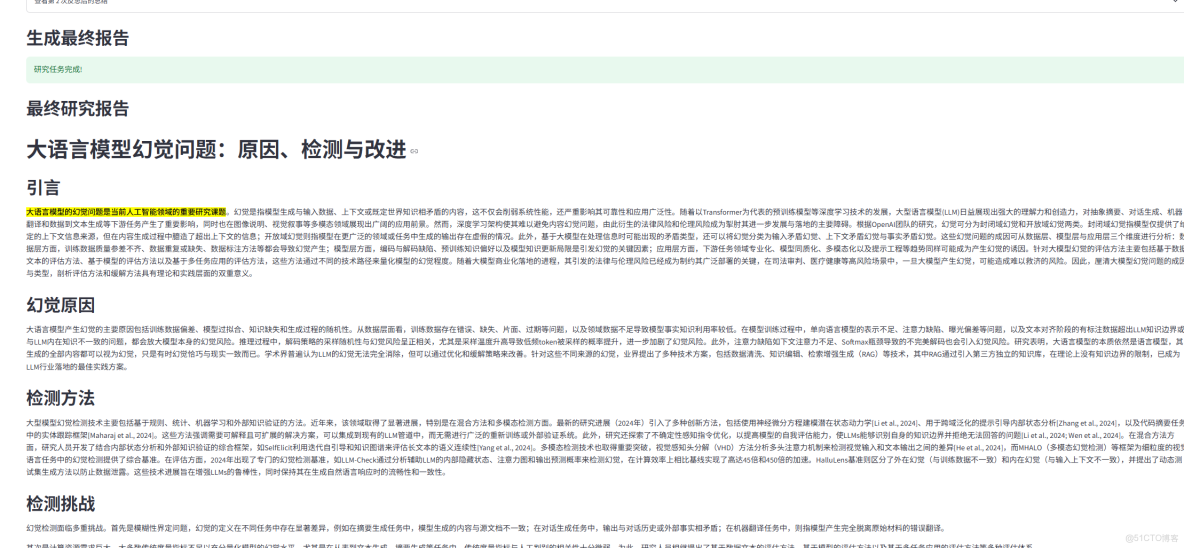
下面給大家分享一個執行的案例,
- 生成報告結構:第一步生成報告的大綱目錄以及每個部分的研究計劃
- 搜索與反思:第二步圍繞每個章節搜索內容以及生成相關總結

- 生成研究報告:基於上面研究結果生成最後報告內容
參考資料
- https://github.com/swirl-ai/ai-angineers-handbook/tree/main/building_agents_from_scratch/deep_research_agent






