
看到huggingface上有個大模型課程,其中有個章節是講如何構建推理大模型,下面是對應的學習內容。
接下來會用最通俗易懂的方式介紹RL,就算之前完全沒接觸過也能看懂。會拆解核心概念,看看為什麼RL在大語言模型(LLMs)領域變得這麼重要。
什麼是強化學習(RL)?
想象一下訓練一隻狗。想教它坐下。可能會説"坐下!",如果狗坐下了,就給它零食和誇獎。如果沒坐下,可能輕輕引導它或者再試一次。時間長了,狗就學會了把坐下這個動作和正面獎勵(零食和誇獎)聯繫起來,下次聽到"坐下!"就更可能照做。在強化學習裏,這種反饋被稱為獎勵(reward)。
這就是強化學習的基本思路!只不過這裏不是狗,而是語言模型(在強化學習中稱為智能體 agent),也不是人在訓練,而是**環境(environment)**在給反饋。
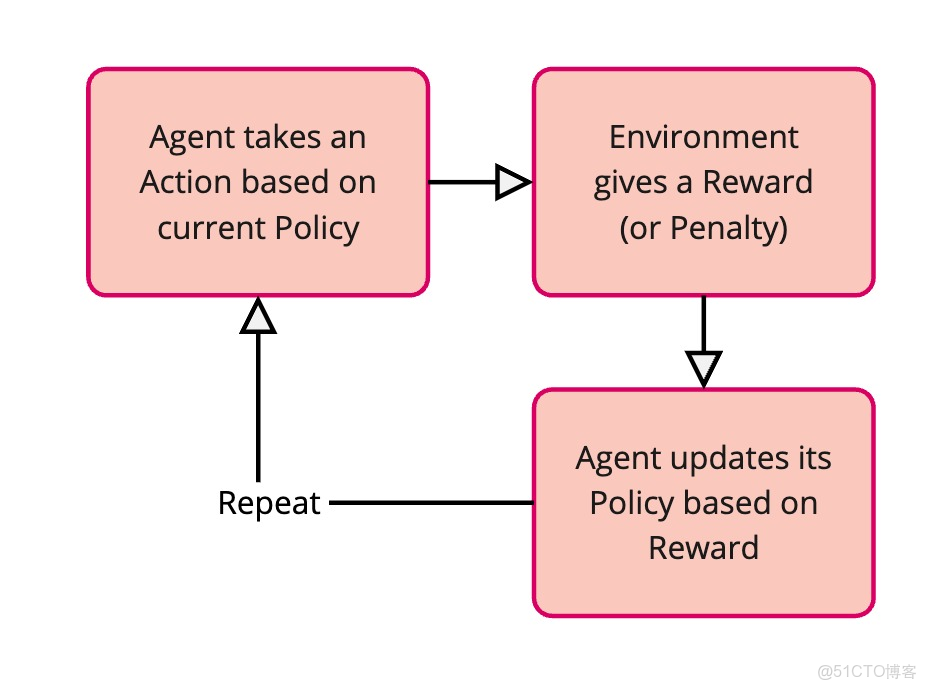
下面拆解一下RL的幾個關鍵組成部分:
智能體(Agent)
這是學習者。在訓狗的例子裏,狗就是智能體。在大語言模型的場景下,LLM本身就成了要訓練的智能體。智能體負責做決策,並從環境和獎勵中學習。
環境(Environment)
這是智能體生存和互動的世界。對狗來説,環境就是家裏還有主人。對LLM來説,環境就比較抽象了——可能是與它互動的用户,或者專門為它設置的模擬場景。環境會給智能體提供反饋。
動作(Action)
這是智能體在環境中可以做的選擇。狗的動作包括"坐下"、“站立”、"叫"等等。對LLM來説,動作可能是生成句子中的單詞、選擇回答問題的答案,或者決定如何在對話中迴應。
獎勵(Reward)
這是環境在智能體執行動作後給出的反饋。獎勵通常是數字。
正向獎勵就像零食和誇獎——告訴智能體"幹得好,做對了!"。
負向獎勵(或懲罰)就像輕聲説"不對"——告訴智能體"這不太對,試試別的"。對狗來説,零食就是獎勵。
對LLM來説,獎勵被設計成反映它在特定任務上的表現——比如回答是否有幫助、真實、或者無害。
策略(Policy)
這是智能體選擇動作的策略。就像狗理解當聽到"坐下!"時該做什麼。在RL中,策略才是真正要學習和改進的東西。它是一套規則或函數,告訴智能體在不同情況下該採取什麼動作。一開始,策略可能是隨機的,但隨着智能體學習,策略會越來越擅長選擇能帶來更高獎勵的動作。
RL的過程:試錯學習
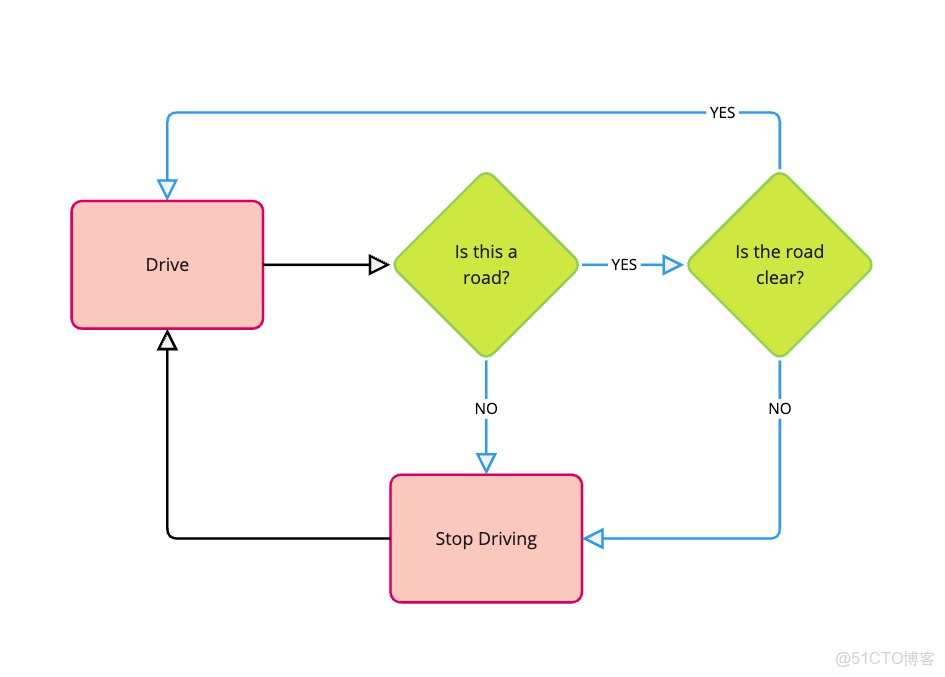
強化學習通過試錯過程進行:
|
步驟
|
過程
|
描述
|
|
1. 觀察
|
智能體觀察環境
|
智能體獲取當前狀態和周圍環境的信息
|
|
2. 動作
|
智能體根據當前策略採取動作
|
使用已學習的策略,智能體決定下一步做什麼
|
|
3. 反饋
|
環境給智能體一個獎勵
|
智能體收到關於其動作好壞的反饋
|
|
4. 學習
|
智能體根據獎勵更新策略
|
智能體調整策略——強化那些帶來高獎勵的動作,避免那些帶來低獎勵的動作
|
|
5. 迭代
|
重複這個過程
|
這個循環不斷繼續,讓智能體持續改進決策能力
|
想想學騎自行車。一開始可能會搖搖晃晃摔倒(負向獎勵!)。但當成功保持平衡並順利踩踏板時,感覺很好(正向獎勵!)。會根據這些反饋調整動作——稍微傾斜、蹬快一點等等——直到學會騎得很好。RL也類似——通過互動和反饋來學習。
RL在大語言模型(LLMs)中的作用
那麼,為什麼RL對大語言模型這麼重要?
訓練真正優秀的LLM其實挺棘手的。可以用互聯網上的海量文本訓練它們,讓它們很擅長預測句子中的下一個詞。這樣它們就學會了生成流暢且語法正確的文本,這在第2章中有講到。
但是,僅僅流暢是不夠的。大家希望LLM不只是會把詞串在一起。還希望它們能夠:
- 有幫助: 提供有用且相關的信息。
- 無害: 避免生成有毒、有偏見或有害的內容。
- 符合人類偏好: 以人類覺得自然、有幫助且吸引人的方式迴應。
主要依靠從文本數據預測下一個詞的預訓練LLM方法,在這些方面有時會達不到要求。
雖然監督訓練在生成結構化輸出方面很出色,但在生成有幫助、無害且符合偏好的響應方面效果可能不太好。這部分在第11章有探討。
微調後的模型可能會生成流暢且結構化的文本,但這些文本仍然可能存在事實錯誤、帶有偏見,或者沒有真正以有幫助的方式回答用户的問題。
強化學習就派上用場了! RL提供了一種方法來微調這些預訓練的LLM,讓它們更好地達成這些期望的品質。就像給LLM這隻狗進行額外訓練,讓它成為一個表現良好且有幫助的夥伴,而不只是一隻會流暢叫喚的狗!
基於人類反饋的強化學習(RLHF)
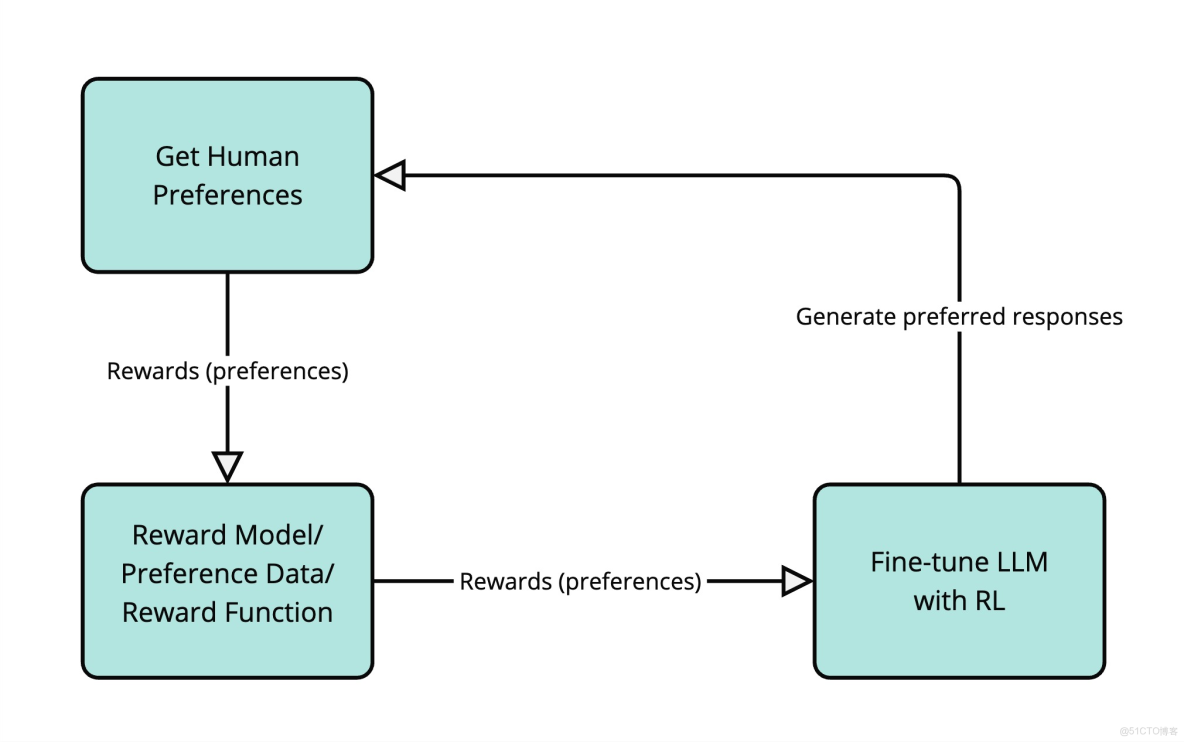
一種非常流行的對齊語言模型的技術叫做基於人類反饋的強化學習(RLHF)。在RLHF中,人類反饋被用作RL中"獎勵"信號的代理。工作原理如下:
- 獲取人類偏好: 可能會讓人類比較LLM對同一輸入提示生成的不同響應,並告訴哪個響應更好。比如,可能會給人類展示"法國的首都是什麼?“這個問題的兩個不同答案,然後問"哪個答案更好?”。
- 訓練獎勵模型: 使用這些人類偏好數據來訓練一個單獨的模型,叫做獎勵模型。這個獎勵模型學習預測人類會偏好哪種響應。它學會根據有幫助性、無害性以及與人類偏好的對齊程度來給響應打分。
- 用RL微調LLM: 現在把獎勵模型當作LLM智能體的環境。LLM生成響應(動作),獎勵模型給這些響應打分(提供獎勵)。本質上,是在訓練LLM生成獎勵模型(它從人類偏好中學習)認為好的文本。
從整體角度看,在LLM中使用RL的好處:
|
好處
|
描述
|
|
更好的控制
|
RL讓大家對LLM生成的文本類型有更多控制。可以引導它們生成更符合特定目標的文本,比如更有幫助、更有創意或更簡潔。
|
|
更好地與人類價值觀對齊
|
特別是RLHF,幫助讓LLM與複雜且往往主觀的人類偏好對齊。很難寫出"什麼是好答案"的規則,但人類可以輕鬆判斷和比較響應。RLHF讓模型從這些人類判斷中學習。
|
|
減少不良行為
|
RL可以用來減少LLM的負面行為,比如生成有毒語言、傳播錯誤信息或表現出偏見。通過設計懲罰這些行為的獎勵,可以促使模型避免它們。
|
基於人類反饋的強化學習已經被用於訓練當今許多最流行的LLM,比如OpenAI的GPT-4、谷歌的Gemini和DeepSeek的R1。RLHF有很多種技術,複雜程度和精細度各不相同。在這一章節中,會重點介紹羣組相對策略優化(GRPO),這是一種RLHF技術,已被證明能有效訓練出有幫助、無害且與人類偏好對齊的LLM。
為什麼要關注GRPO(羣組相對策略優化)?
RLHF有很多技術,但這門課程聚焦於GRPO,因為它代表了語言模型強化學習的重大進步。
簡單看看另外兩種流行的RLHF技術:
- 近端策略優化(PPO)
- 直接偏好優化(DPO)
近端策略優化(PPO)是最早的高效RLHF技術之一。它使用策略梯度方法,根據單獨的獎勵模型給出的獎勵來更新策略。
直接偏好優化(DPO)後來作為一種更簡單的技術被開發出來,它直接使用偏好數據,不需要單獨的獎勵模型。本質上,把問題框架化為在被選擇和被拒絕的響應之間的分類任務。
DPO和PPO本身是複雜的強化學習算法,這門課程不會涉及。如果想深入瞭解,可以看看以下資源:
- 近端策略優化
- 直接偏好優化
與DPO和PPO不同,GRPO把相似的樣本分組在一起,作為一個組進行比較。這種基於組的方法與其他方法相比,提供了更穩定的梯度和更好的收斂特性。
GRPO不像DPO那樣使用偏好數據,而是使用來自模型或函數的獎勵信號來比較相似樣本的組。
GRPO在獲取獎勵信號方面很靈活——它可以像PPO那樣使用獎勵模型,但並不嚴格要求必須有獎勵模型。這是因為GRPO可以整合來自任何能夠評估響應質量的函數或模型的獎勵信號。
比如,可以使用長度函數來獎勵更短的響應,用數學求解器來驗證解決方案的正確性,或者用事實正確性函數來獎勵更準確的響應。這種靈活性使得GRPO特別適合不同類型的對齊任務。









