
前言
“ RAG的架構雖然有所不同,但其原理都是相同的,都是通過檢索來增強模型的生成能力,只不過在不同的環節做了不同的優化。”
從事RAG技術的工作也有一兩年時間了,但在此之間都是這學一點那學一點,感覺自己好像什麼都會,但從來沒有對整個RAG系統進行過梳理。
所以,今天就從RAG的迭代過程開始梳理一下RAG的架構升級過程,瞭解不同種類RAG的區別和聯繫,以及適用場景。
RAG的幾種類型
從技術的本質來説,RAG就是檢索增強生成,重要的就是檢索和生成;但技術畢竟在不斷的發展和迭代,因此RAG的架構也經過多次迭代。
以下是RAG迭代過程中的幾種架構類型:
Naive RAG:基礎RAG
Advanced RAG:高級RAG
Modular RAG:模塊化RAG
- Graph RAG:圖RAG
- Agentic RAG :智能體RAG
這幾種RAG雖然從架構和實現上有所區別,但其本質上還是一樣的;所以我們需要學習不同RAG架構之間的區別,但也要通過表象看到RAG的本質。
Naive Rag
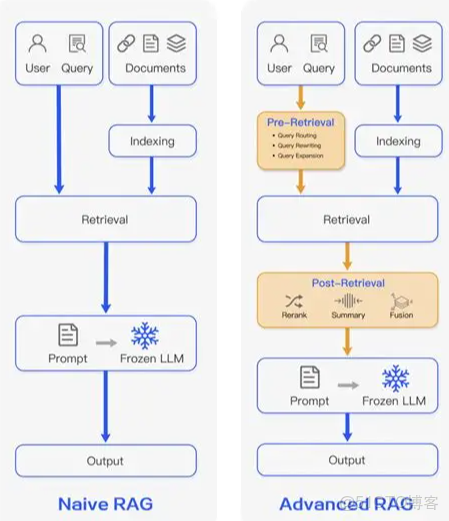
其實想了解RAG的技術原理,基礎RAG是最好的選擇,因為其是RAG最初的版本;但受限於當時的技術和理論,因此基礎RAG現在已經很少使用了,可能也就在剛開始學習的時候瞭解一下。
基礎RAG的流程就是,通過相似度檢索的方式召回相關數據,然後丟給模型進行增強生成;但這裏有個問題就是,基礎RAG的召回策略和生成過程都很簡單,在真實的業務場景中測試效果都不怎麼好。
Advanced Rag
高級RAG是在Naive Rag的基礎之上做了功能升級;比如説剛開始學習RAG的時候,就知道把問題直接向量化,然後丟給向量庫進行相似度檢索;但在實際場景中發現召回率不足,也不準確。
因此,高級RAG就是在Naive Rag的基礎之上做了優化;比如説召回優化,增加問題改寫,知識庫優化,提升文檔的拆分質量,以及生成優化,把召回的文檔進行重排序,格式化等操作。
Modular Rag
模塊化Rag其實就更好理解了,在基於RAG的智能問答場景中,我們發現文檔不但來源複雜,而且格式也很複雜;而且在不同的業務場景中需要使用不同的文檔處理流程和召回策略。
比如説有些場景的主要文檔格式是word/pdf,而有些場景的文檔格式是excel/csv,還有是一些數據庫和API。
這時,為了降低系統的開發和維護成本,就需要對不同的功能進行模塊化開發,這樣在不同的場景中選擇不同的模塊即可,而不用每次都重新開發。
Graph Rag
圖Rag和上面的幾種RAG架構的唯一區別就是其存儲介質的不同,Graph Rag使用的是基於知識圖譜的方式來組織和存儲數據;這種方式在某些業務場景中具有更好的效果,比如説查詢家庭成員關係,組織架構等。
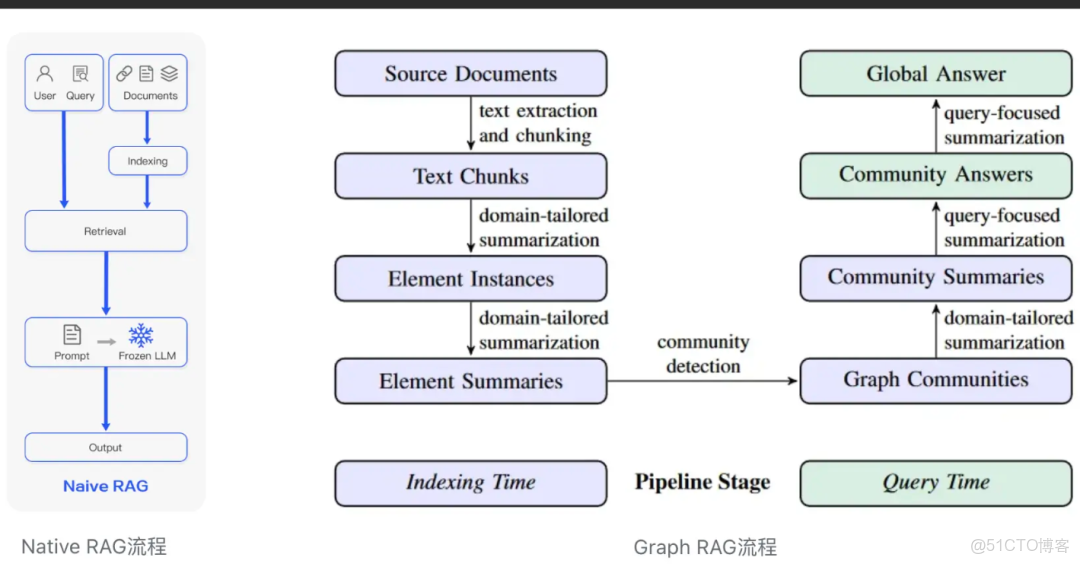
由於圖結構天生適合處理這種複雜的數據關係,因此Graph Rag在這種場景中具備天然的優勢。
Agentic Rag
智能體RAG又被稱為主動式RAG,上面幾種RAG不論怎麼設計,其都是基於根據用户問題進行數據召回,然後根據召回結果進行增強生成,這個流程是固定的。
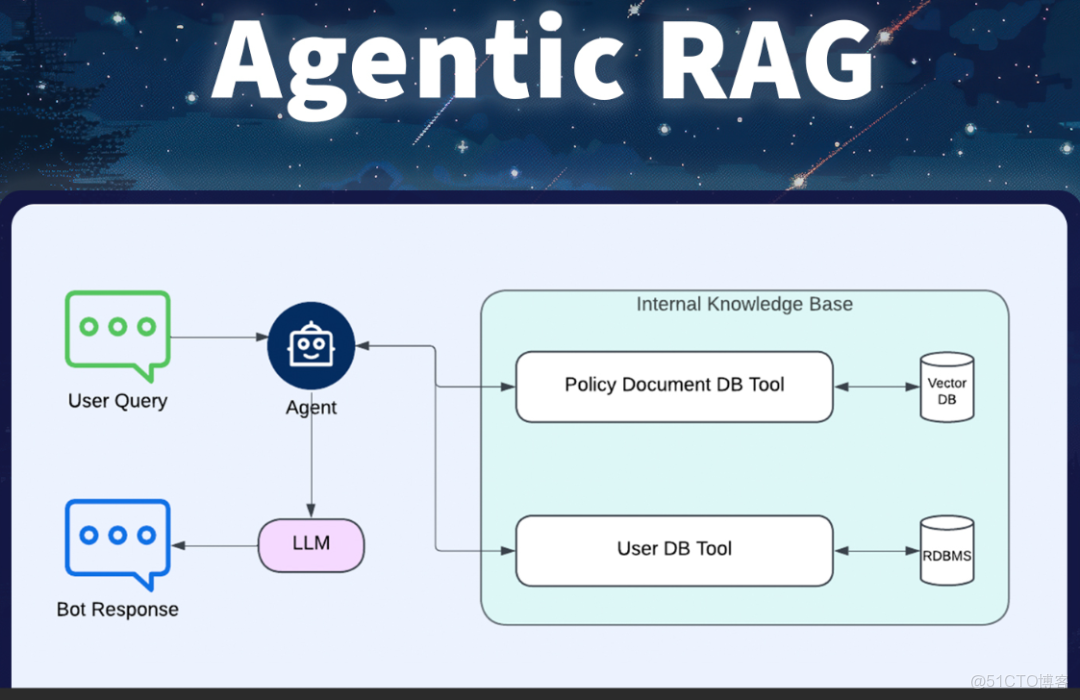
但Agentic Rag是基於智能體實現的架構模式,其主要就是利用大模型獨立思考和規劃的能力,可以根據用户的問題自行判斷是否需要進行數據召回。如果遇到一些簡單的問題或者模型能夠自己解決的問題,那麼就可以避免召回的過程,以提升用户體驗和響應速度。
因此,以上幾種RAG架構,並沒有跳出RAG的基本理論範疇,只不過在不同的環節上對RAG進行了優化,最終的目的都是為了提升模型的生成效果,解決用户問題。
但雖然RAG有多種不同的技術架構,但這些架構之間並不是非此即彼的關係,不同的架構之間可以互相協調,以此增強RAG的效果。