
涵蓋規劃、檢索、反思、批判、綜合等多個環節
一個 RAG 系統之所以會失敗,通常不是因為大型語言模型(LLM)不夠智能,而是因為它的架構過於簡單。它試圖用一種線性的、一次性的方法來處理一個循環的、多步驟的問題。
許多複雜查詢需要推理、反思以及在何時採取行動方面的明智決策,這與我們面對問題時檢索信息的方式非常相似。這正是智能體驅動的操作在 RAG 流水線中發揮作用的地方。讓我們來看看一個典型的深度思考 RAG 流水線是什麼樣的……
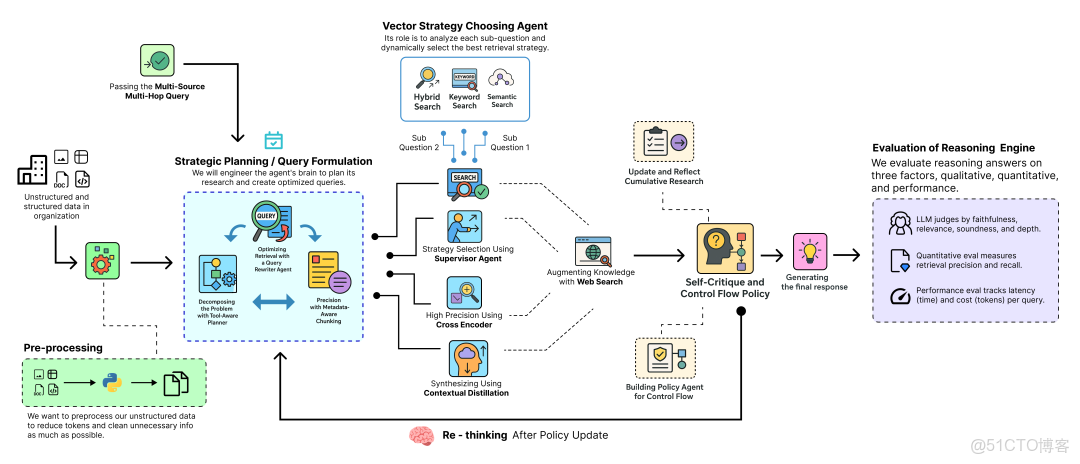
深度思考 RAG 流水線
- 規劃 (Plan): 首先,智能體將複雜的用户查詢分解為一個結構化的、多步驟的研究計劃,併為每一步決定需要使用哪種工具(內部文檔搜索或網絡搜索)。
- 檢索 (Retrieve): 對於每一步,它會執行一個自適應的多階段檢索漏斗,使用一個監督器(supervisor)來動態選擇最佳的搜索策略(向量、關鍵詞或混合搜索)。
- 精煉 (Refine): 接着,它使用一個高精度的交叉編碼器(cross-encoder)對初步結果進行重排序,並使用一個蒸餾智能體(distiller agent)將最佳證據壓縮為簡潔的上下文。
- 反思 (Reflect): 每一步之後,智能體都會總結其發現並更新其研究歷史,從而逐步建立對問題的累積理解。
- 批判 (Critique): 然後,一個策略智能體(policy agent)會檢查這段歷史,做出戰略決策:是繼續下一步研究,還是在遇到死衚衕時修正計劃,或是結束任務。
- 綜合 (Synthesize): 一旦研究完成,一個最終的智能體會將所有來源收集到的證據綜合成一個單一、全面且可引用的答案。
在本博客中,我們將實現整個深度思考 RAG 流水線,並將其與一個基礎的 RAG 流水線進行比較,以展示它如何解決複雜的多跳查詢(multi-hop queries)。
所有代碼和理論都可以在作者 GitHub 倉庫中找到:
https://github.com/FareedKhan-dev/deep-thinking-rag
環境設置
在開始編寫深度 RAG 流水線的代碼之前,我們需要一個堅實的基礎,因為一個生產級別的人工智能系統不僅關乎最終的算法,也關乎我們在設置過程中做出的審慎選擇。
我們將要實現的每一步對於最終系統的有效性和可靠性都至關重要。
當我們開始開發一個流水線並進行反覆試驗時,最好將配置定義為一個簡單的字典格式,因為後續當流水線變得複雜時,我們可以簡單地回顧這個字典來更改配置,並觀察其對整體性能的影響。
# 中央配置字典,用於管理所有系統參數config = { "data_dir": "./data", # 存儲原始和清理後數據的目錄 "vector_store_dir": "./vector_store", # 持久化向量存儲的目錄 "llm_provider": "openai", # 我們使用的 LLM 提供商 "reasoning_llm": "gpt-4o", # 用於規劃和綜合的強大模型 "fast_llm": "gpt-4o-mini", # 用於簡單任務(如基線 RAG)的更快速、更便宜的模型 "embedding_model": "text-embedding-3-small", # 用於創建文檔嵌入的模型 "reranker_model": "cross-encoder/ms-marco-MiniLM-L-6-v2", # 用於精確重排序的模型 "max_reasoning_iterations": 7, # 防止智能體陷入無限循環的安全措施 "top_k_retrieval": 10, # 初始廣泛召回的文檔數量 "top_n_rerank": 3, # 精確重排序後保留的文檔數量}這些鍵都相當容易理解,但有三個鍵值得一提:
- •
llm_provider:這是我們正在使用的 LLM 提供商,本文中使用 OpenAI。我使用 OpenAI 是因為在 LangChain 中可以輕鬆更換模型和提供商,但你可以選擇任何適合你需求的提供商,比如 Ollama。 - •
reasoning_llm:這必須是我們整個設置中最強大的模型,因為它將用於規劃和綜合。 - •
fast_llm:這應該是一個更快、更便宜的模型,因為它將用於像基線 RAG 這樣的簡單任務。
現在我們需要導入將在整個流水線中使用的庫,並將 API 密鑰設置為環境變量,以避免在代碼塊中暴露它們。
import os # 用於與操作系統交互(例如,管理環境變量)import re # 用於正則表達式操作,有助於文本清理import json # 用於處理 JSON 數據from getpass import getpass # 用於安全地提示用户輸入(如 API 密鑰),而不會在屏幕上回顯from pprint import pprint # 用於美觀地打印 Python 對象,使其更具可讀性import uuid # 用於生成唯一標識符from typing importList, Dict, TypedDict, Literal, Optional# 用於類型提示,以創建清晰、可讀和可維護的代碼# 輔助函數,用於在環境變量不存在時安全地設置它們def_set_env(var: str): # 檢查環境變量是否尚未設置 ifnot os.environ.get(var): # 如果未設置,則提示用户安全地輸入 os.environ[var] = getpass(f"Enter your {var}: ")# 設置我們將使用的服務的 API 密鑰_set_env("OPENAI_API_KEY") # 用於訪問 OpenAI 模型(GPT-4o, embeddings)_set_env("LANGSMITH_API_KEY") # 用於使用 LangSmith 進行追蹤和調試_set_env("TAVILY_API_KEY") # 用於網絡搜索工具# 啓用 LangSmith 追蹤,以獲取我們智能體執行的詳細日誌和可視化os.environ["LANGSMITH_TRACING"] = "true"# 在 LangSmith 中定義一個項目名稱,以組織我們的運行記錄os.environ["LANGSMITH_PROJECT"] = "Advanced-Deep-Thinking-RAG"我們還啓用了 LangSmith 進行追蹤。當你處理一個具有複雜、循環工作流的智能體系統時,追蹤不僅僅是一個錦上添花的功能,它至關重要。它能幫助你可視化正在發生的事情,並使調試智能體的思考過程變得更加容易。
知識庫溯源
一個生產級別的 RAG 系統需要一個既複雜又要求高的知識庫,才能真正展示其有效性。為此,我們將使用 NVIDIA 的 2023 年 10-K 文件,這是一份超過一百頁的綜合性文件,詳細説明了該公司的業務運營、財務表現以及披露的風險因素。
知識庫溯源
首先,我們將實現一個自定義函數,該函數以編程方式直接從美國證券交易委員會(SEC)的 EDGAR 數據庫下載 10-K 文件,解析原始 HTML,並將其轉換為適合我們 RAG 流水線攝入的乾淨、結構化的文本格式。現在讓我們來編寫這個函數。
import requests # 用於發起 HTTP 請求以下載文檔from bs4 import BeautifulSoup # 一個用於解析 HTML 和 XML 文檔的強大庫from langchain.docstore.document import Document # LangChain 中用於表示一段文本的標準數據結構defdownload_and_parse_10k(url, doc_path_raw, doc_path_clean): # 檢查清理後的文件是否已存在,以避免重複下載 if os.path.exists(doc_path_clean): print(f"Cleaned 10-K file already exists at: {doc_path_clean}") return print(f"Downloading 10-K filing from {url}...") # 設置一個 User-Agent 請求頭來模擬瀏覽器,因為一些服務器會阻止腳本訪問 headers = {'User-Agent': 'Mozilla/5.0'} # 向 URL 發起 GET 請求 response = requests.get(url, headers=headers) # 如果下載失敗(例如,404 Not Found),則拋出錯誤 response.raise_for_status() # 將原始 HTML 內容保存到文件中以便檢查 withopen(doc_path_raw, 'w', encoding='utf-8') as f: f.write(response.text) print(f"Raw document saved to {doc_path_raw}") # 使用 BeautifulSoup 解析和清理 HTML 內容 soup = BeautifulSoup(response.content, 'html.parser') # 從常見的 HTML 標籤中提取文本,並嘗試保留段落結構 text = '' for p in soup.find_all(['p', 'div', 'span']): # 獲取每個標籤的文本,去除多餘的空白,並添加換行符 text += p.get_text(strip=True) + '\n\n' # 使用正則表達式清理多餘的換行符和空格,以獲得更乾淨的最終文本 clean_text = re.sub(r'\n{3,}', '\n\n', text).strip() # 將 3 個及以上的換行符合併為 2 個 clean_text = re.sub(r'\s{2,}', ' ', clean_text).strip() # 將 2 個及以上的空格合併為 1 個 # 將最終清理後的文本保存到 .txt 文件中 withopen(doc_path_clean, 'w', encoding='utf-8') as f: f.write(clean_text) print(f"Cleaned text content extracted and saved to {doc_path_clean}")代碼相當容易理解,我們使用 beautifulsoup4 來解析 HTML 內容並提取文本。它幫助我們輕鬆地導航 HTML 結構,檢索相關信息,同時忽略像腳本或樣式這樣不必要的元素。
現在,讓我們執行它,看看效果如何。
print("Downloading and parsing NVIDIA's 2023 10-K filing...")# 執行下載和解析函數download_and_parse_10k(url_10k, doc_path_raw, doc_path_clean)# 打開清理後的文件並打印一個樣本以驗證結果withopen(doc_path_clean, 'r', encoding='utf-8') as f: print("\n--- Sample content from cleaned 10-K ---") print(f.read(1000) + "...")#### OUTPUT ####Downloading and parsing NVIDIA 202310-K filing...Successfully downloaded 10-K filing from https://www.sec.gov/Archives/edgar/data/1045810/000104581023000017/nvda-20230129.htmRaw document saved to ./data/nvda_10k_2023_raw.htmlCleaned text content extracted and saved to ./data/nvda_10k_2023_clean.txt# --- Sample content from cleaned 10-K ---Item 1. Business. OVERVIEW NVIDIA is the pioneer of accelerated computing. We are a full-stack computing company with a platform strategy that brings together hardware, systems, software, algorithms, libraries, and services to create unique value for the markets we serve. Our work in accelerated computing and AI is reshaping the worlds largest industries and profoundly impacting society. Founded in1993, we started as a PC graphics chip company, inventing the graphics processing unit, or GPU. The GPU was essential for the growth of the PC gaming market and has since been repurposed to revolutionize computer graphics, high performance computing, or HPC, and AI. The programmability of our GPUs made them ...我們只是簡單地調用這個函數,將所有內容存儲在一個 txt 文件中,這個文件將作為我們 RAG 流水線的上下文。
當我們運行上述代碼時,你可以看到它開始為我們下載報告,並且我們能看到下載內容的樣本是什麼樣的。
理解我們的多源、多跳查詢
為了測試我們實現的流水線並將其與基礎 RAG 進行比較,我們需要使用一個非常複雜的查詢,它涵蓋了我們正在處理的文檔的不同方面。
我們的複雜查詢:"根據 NVIDIA 的 2023 年 10-K 文件,找出其與競爭相關的關鍵風險。然後,查找關於 AMD 的 AI 芯片戰略的最新消息(文件發佈後,即 2024 年的新聞),並解釋這一新戰略如何直接應對或加劇了 NVIDIA 所陳述的風險之一。"讓我們來分析一下為什麼這個查詢對於一個標準的 RAG 流水線來説如此困難:
- 多跳推理 (Multi-Hop Reasoning): 它無法一步到位地回答。系統必須首先識別風險,然後找到關於 AMD 的新聞,最後將兩者綜合起來。
- 多源知識 (Multi-Source Knowledge): 所需信息存在於兩個完全不同的地方。風險在我們靜態的內部文檔(10-K 文件)中,而關於 AMD 的新聞則是外部的,需要訪問實時網絡。
- 綜合與分析 (Synthesis and Analysis): 查詢並非要求簡單地羅列事實。它要求解釋一組事實如何使另一組事實惡化,這是一項需要真正綜合能力的任務。
在下一節中,我們將實現一個基礎的 RAG 流水線,並實際看看簡單的 RAG 是如何在這個問題上失敗的。
構建一個註定會失敗的淺層 RAG 流水線
既然我們已經配置好了環境,並準備好了具有挑戰性的知識庫,我們下一個合乎邏輯的步驟就是構建一個標準的原生 RAG 流水線。這樣做有一個至關重要的目的……
通過首先構建最簡單的解決方案,我們可以用我們的複雜查詢來測試它,並確切地觀察它如何以及為何會失敗。
在本節中,我們將要做以下事情:
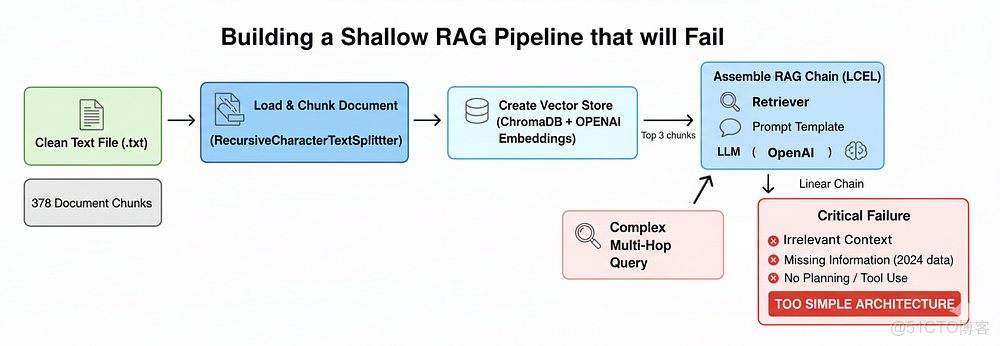
淺層 RAG 流水線
- • 加載並分塊文檔: 我們將攝入清理後的 10-K 文件,並將其分割成小的、固定大小的塊——這是一種常見但在語義上較為粗糙的方法。
- • 創建向量存儲: 然後,我們將對這些塊進行嵌入,並在 ChromaDB 向量存儲中建立索引,以實現基本的語義搜索。
- • 組裝 RAG 鏈: 我們將使用 LangChain 表達式語言(LangChain Expression Language, LCEL),它將我們的檢索器、提示模板和一個 LLM 連接成一個線性的流水線。
- • 展示關鍵失敗點: 我們將用我們的多跳、多源查詢來執行這個簡單的系統,並分析其不充分的響應。
首先,我們需要加載清理後的文檔並進行分割。我們將使用 RecursiveCharacterTextSplitter,這是 LangChain 生態系統中的一個標準工具。
from langchain_community.document_loaders import TextLoader # 一個用於 .txt 文件的簡單加載器from langchain.text_splitter import RecursiveCharacterTextSplitter # 一個標準的文本分割器print("Loading and chunking the document...")# 使用我們清理後的 10-K 文件的路徑初始化加載器loader = TextLoader(doc_path_clean, encoding='utf-8')# 將文檔加載到內存中documents = loader.load()# 使用定義的塊大小和重疊來初始化文本分割器# chunk_size=1000: 每個塊大約 1000 個字符長。# chunk_overlap=150: 每個塊將與前一個塊共享 150 個字符以保持一定的上下文。text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)# 將加載的文檔分割成更小、更易於管理的塊doc_chunks = text_splitter.split_documents(documents)print(f"Document loaded and split into {len(doc_chunks)} chunks.")#### OUTPUT ####Loading and chunking the document...Document loaded and split into 378 chunks.我們的主文檔被分成了 378 個塊,下一步是讓它們變得可搜索。為此,我們需要創建向量嵌入並將它們存儲在數據庫中。我們將使用 ChromaDB,一個流行的內存向量存儲,以及我們配置中定義的 OpenAI text-embedding-3-small 模型。
from langchain_community.vectorstores import Chroma # 我們將使用的向量存儲from langchain_openai import OpenAIEmbeddings # 用於創建嵌入的函數print("Creating baseline vector store...")# 使用我們配置中指定的模型初始化嵌入函數embedding_function = OpenAIEmbeddings(model=config['embedding_model'])# 從我們的文檔塊創建 Chroma 向量存儲# 這個過程會為每個塊創建一個嵌入,並將其索引化。baseline_vector_store = Chroma.from_documents( documents=doc_chunks, embedding=embedding_function)# 從向量存儲創建一個檢索器# 檢索器是實際執行搜索的組件。# search_kwargs={"k": 3}: 這告訴檢索器對於任何給定的查詢,返回最相關的 3 個塊。baseline_retriever = baseline_vector_store.as_retriever(search_kwargs={"k": 3})print(f"Vector store created with {baseline_vector_store._collection.count()} embeddings.")#### OUTPUT ####Creating baseline vector store...Vector store created with378 embeddings.Chroma.from_documents 組織了這個過程,並將所有向量存儲在一個可搜索的索引中。最後一步是使用 LangChain 表達式語言(LCEL)將它們組裝成一個單一、可運行的 RAG 鏈。
這個鏈將定義數據的線性流程:從用户的問題到檢索器,然後到提示,最後到 LLM。
from langchain_core.prompts import ChatPromptTemplate # 用於創建提示模板from langchain_openai import ChatOpenAI # OpenAI 聊天模型接口from langchain_core.runnable import RunnablePassthrough # 一個用於在鏈中傳遞輸入的工具from langchain_core.output_parsers import StrOutputParser # 用於將 LLM 的輸出解析為簡單字符串# 這個模板指示 LLM 如何行事。# {context}: 這裏我們將注入從檢索到的文檔中獲得的內容。# {question}: 這裏將放入用户的原始問題。template = """You are an AI financial analyst. Answer the question based only on the following context:{context}Question: {question}"""prompt = ChatPromptTemplate.from_template(template)# 我們使用配置中定義的 'fast_llm' 來完成這個簡單的任務llm = ChatOpenAI(model=config["fast_llm"], temperature=0)# 一個輔助函數,用於將檢索到的文檔列表格式化為單個字符串defformat_docs(docs): return"\n\n---\n\n".join(doc.page_content for doc in docs)# 使用 LCEL 的管道(|)語法定義的完整 RAG 鏈baseline_rag_chain = ( # 第一步是一個字典,定義了我們提示的輸入 {"context": baseline_retriever | format_docs, "question": RunnablePassthrough()} # context 是通過將問題傳遞給檢索器並格式化結果來生成的 # 原始問題則原封不動地傳遞下去 | prompt # 然後這個字典被傳遞給提示模板 | llm # 格式化後的提示被傳遞給語言模型 | StrOutputParser() # LLM 的輸出消息被解析為字符串)你可能已經注意到,我們將一個字典定義為第一步。它的 context 鍵由一個子鏈填充:輸入的問題進入 baseline_retriever,其輸出(一個 Document 對象列表)由 format_docs 格式化為單個字符串。question 鍵則通過使用 RunnablePassthrough 簡單地傳遞原始輸入來填充。
讓我們運行這個簡單的流水線,並理解它在哪些地方失敗了。
from rich.console import Console # 用於以 markdown 格式美觀地打印輸出from rich.markdown import Markdown# 初始化 rich 控制枱以獲得更好的輸出格式console = Console()# 我們的複雜、多跳、多源查詢complex_query_adv = "Based on NVIDIA's 2023 10-K filing, identify their key risks related to competition. Then, find recent news (post-filing, from 2024) about AMD's AI chip strategy and explain how this new strategy directly addresses or exacerbates one of NVIDIA's stated risks."print("Executing complex query on the baseline RAG chain...")# 使用我們具有挑戰性的查詢調用該鏈baseline_result = baseline_rag_chain.invoke(complex_query_adv)console.print("\n--- BASELINE RAG FAILED OUTPUT ---")# 使用 markdown 格式打印結果以提高可讀性console.print(Markdown(baseline_result))當你運行上述代碼時,我們會得到以下輸出。
#### OUTPUT ####Executing complex query on the baseline RAG chain...--- BASELINE RAG FAILED OUTPUT ---Based on the provided context, NVIDIA operates in an intensely competitive semiconductorindustry and faces competition from companies like AMD. The context mentionsthat the industry is characterized by rapid technological change. However, the provided documents do not contain any specific information about AMD's recent AI chip strategy from 2024 or how it might impact NVIDIA's stated risks.在這個失敗的 RAG 流水線及其輸出中,你可能已經注意到了三件事。
- • 不相關的上下文: 檢索器抓取了關於“NVIDIA”、“競爭”和“AMD”的一般性文本塊,但錯過了關於 2024 年 AMD 戰略的具體細節。
- • 信息缺失: 關鍵的失敗在於 2023 年的數據無法覆蓋 2024 年的事件。系統沒有意識到自己缺少關鍵信息。
- • 沒有規劃或工具使用: 將複雜查詢當作簡單問題處理。無法將其分解為步驟,也無法使用像網絡搜索這樣的工具來填補信息空白。
系統之所以失敗,不是因為 LLM 愚蠢,而是因為架構過於簡單。它是一個線性的、一次性的過程,卻試圖解決一個循環的、多步驟的問題。
既然我們已經理解了基礎 RAG 流水線的問題所在,現在我們可以開始實現我們的深度思考方法,並看看它能多好地解決我們的複雜查詢。
為中央智能體系統定義 RAG 狀態
要構建我們的推理智能體,我們首先需要一種管理其狀態的方法。在我們簡單的 RAG 鏈中,每一步都是無狀態的,但是……
一個智能的智能體需要記憶。它需要記住最初的問題、它創建的計劃以及到目前為止收集到的證據。
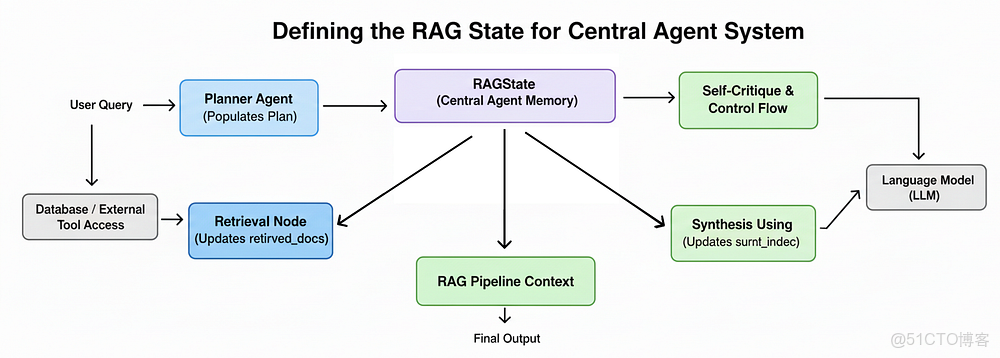
RAG 狀態
RAGState 將作為一箇中央記憶庫,在我們 LangGraph 工作流的每個節點之間傳遞。為了構建它,我們將定義一系列結構化的數據類,從最基本的構建塊開始:一個研究計劃中的單一步驟。
我們希望定義智能體計劃的原子單位。每個 Step 不僅必須包含一個要回答的問題,還必須包含其背後的推理,以及至關重要的,智能體應該使用的具體工具。這迫使智能體的規劃過程變得明確和結構化。
from langchain_core.documents import Documentfrom langchain_core.pydantic_v1 import BaseModel, Field# 用於表示智能體推理計劃中單一步驟的 Pydantic 模型class Step(BaseModel): # 此研究步驟的一個具體的、可回答的子問題 sub_question: str = Field(description="A specific, answerable question for this step.") # 智能體對為何此步驟是必要的的論證 justification: str = Field(description="A brief explanation of why this step is necessary to answer the main query.") # 此步驟要使用的具體工具:內部文檔搜索或外部網絡搜索 tool: Literal["search_10k", "search_web"] = Field(description="The tool to use for this step.") # 一系列關鍵關鍵詞,以提高搜索的準確性 keywords: List[str] = Field(description="A list of critical keywords for searching relevant document sections.") # (可選) 一個可能的文檔章節,用於執行更具針對性的、過濾後的搜索 document_section: Optional[str] = Field(description="A likely document section title (e.g., 'Item 1A. Risk Factors') to search within. Only for 'search_10k' tool.")我們的 Step 類使用 Pydantic BaseModel,作為我們規劃器智能體(Planner Agent)的嚴格契約。tool: Literal[...] 字段強制 LLM 在使用我們的內部知識(search_10k)和尋求外部信息(search_web)之間做出具體決策。
這種結構化的輸出遠比嘗試解析自然語言計劃要可靠得多。
現在我們已經定義了一個單獨的 Step,我們需要一個容器來存放整個步驟序列。我們將創建一個 Plan 類,它只是一個 Step 對象的列表。這代表了智能體完整的、端到端的研究策略。
# 用於表示整個計劃的 Pydantic 模型,它是一個包含多個獨立步驟的列表class Plan(BaseModel): # 一個 Step 對象的列表,概述了完整的系列研究計劃 steps: List[Step] = Field(description="A detailed, multi-step plan to answer the user's query.")我們編寫的 Plan 類將為整個研究過程提供結構。當我們調用我們的規劃器智能體時,我們會要求它返回一個符合此模式的 JSON 對象。這確保了智能體的策略在任何檢索操作執行之前都是清晰、有序且機器可讀的。
接下來,當我們的智能體執行其計劃時,它需要一種方式來記住它學到了什麼。我們將定義一個 PastStep 字典來存儲每個已完成步驟的結果。這將構成智能體的研究歷史或實驗筆記。
# 一個 TypedDict,用於在我們的研究歷史中存儲已完成步驟的結果class PastStep(TypedDict): step_index: int # 已完成步驟的索引(例如,1, 2, 3) sub_question: str # 在此步驟中解決的子問題 retrieved_docs: List[Document] # 為此步驟檢索和重排序的精確文檔 summary: str # 智能體對此步驟發現的一句話總結這個 PastStep 結構對於智能體的自我批判循環至關重要。在每一步之後,我們將填充一個這樣的字典並將其添加到我們的狀態中。然後,智能體將能夠審查這個不斷增長的摘要列表,以瞭解它所知道的內容,並決定是否擁有足夠的信息來完成其任務。
最後,我們將所有這些部分整合到主 RAGState 字典中。這是將流經我們整個圖的核心對象,它持有原始查詢、完整計劃、過去步驟的歷史,以及正在執行的當前步驟的所有中間數據。
# 將在我們 LangGraph 智能體所有節點之間傳遞的主狀態字典class RAGState(TypedDict): original_question: str # 用户發起的、啓動整個流程的初始複雜查詢 plan: Plan # 由規劃器智能體生成的多步驟計劃 past_steps: List[PastStep] # 已完成研究步驟及其發現的累積歷史 current_step_index: int # 正在執行的計劃中當前步驟的索引 retrieved_docs: List[Document] # 當前步驟中檢索到的文檔(廣泛召回的結果) reranked_docs: List[Document] # 當前步驟中經過精確重排序後的文檔 synthesized_context: str # 從重排序後的文檔中生成的簡潔、蒸餾的上下文 final_answer: str # 對用户原始問題的最終、綜合性答案這個 RAGState TypedDict 是我們智能體的完整心智。我們圖中的每個節點都將接收這個字典作為輸入,並返回一個更新後的版本作為輸出。
例如,plan_node 將填充 plan 字段,retrieval_node 將填充 retrieved_docs 字段,依此類推。這種共享的、持久的狀態使得我們簡單的 RAG 鏈所缺乏的複雜、迭代的推理成為可能。
隨着我們智能體記憶藍圖的定義完成,我們準備構建我們系統的第一個認知組件:將填充此狀態的規劃器智能體。
戰略規劃與查詢構建
在定義了我們的 RAGState 之後,我們現在可以構建我們智能體的第一個,也可以説是最關鍵的認知組件:它的規劃能力。這是我們的系統從一個簡單的數據獲取器躍升為真正的推理引擎的地方。我們的智能體不會天真地將用户的複雜查詢視為單次搜索,而是會首先停下來思考,並構建一個詳細的、分步的研究策略。
戰略規劃
本節分為三個關鍵的工程步驟:
- • 具備工具意識的規劃器 (The Tool-Aware Planner): 我們將構建一個由 LLM 驅動的智能體,其唯一的工作就是將用户的查詢分解為一個結構化的
Plan對象,併為每一步決定使用哪種工具。 - • 查詢重寫器 (The Query Rewriter): 我們將創建一個專門的智能體,將規劃器的簡單子問題轉化為高效、優化的搜索查詢。
- • 元數據感知的文本分塊 (Metadata-Aware Chunking): 我們將重新處理我們的源文檔,以添加章節級別的元數據,這是解鎖高精度、過濾式檢索的關鍵一步。
使用具備工具意識的規劃器分解問題
基本上,我們要構建我們操作的大腦。當這個大腦收到一個複雜問題時,它需要做的第一件事就是制定一個行動計劃。
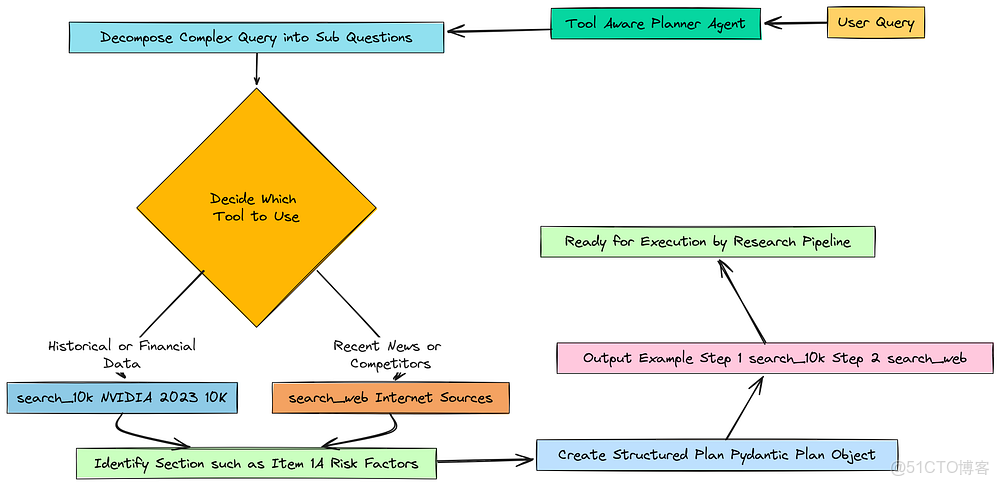
分解步驟
我們不能 просто 將整個問題扔給我們的數據庫,然後期望得到最好的結果。我們需要教會智能體如何將問題分解成更小、更易於管理的部分。
為此,我們將創建一個專門的規劃器智能體(Planner Agent)。我們需要給它一套非常清晰的指令,或者説是一個提示(prompt),告訴它它的工作究竟是什麼。
from langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIfrom rich.pretty import pprint as rprint# 指示 LLM 如何作為規劃器行事的系統提示planner_prompt = ChatPromptTemplate.from_messages([ ("system", """You are an expert research planner. Your task is to create a clear, multi-step plan to answer a complex user query by retrieving information from multiple sources.You have two tools available:1. `search_10k`: Use this to search for information within NVIDIA's 2023 10-K financial filing. This is best for historical facts, financial data, and stated company policies or risks from that specific time period.2. `search_web`: Use this to search the public internet for recent news, competitor information, or any topic that is not specific to NVIDIA's 2023 10-K.Decompose the user's query into a series of simple, sequential sub-questions. For each step, decide which tool is more appropriate.For `search_10k` steps, also identify the most likely section of the 10-K (e.g., 'Item 1A. Risk Factors', 'Item 7. Management's Discussion and Analysis...').It is critical to use the exact section titles found in a 10-K filing where possible."""), ("human", "User Query: {question}") # 用户的原始、複雜查詢])我們基本上是賦予 LLM 一個新的角色:專家級研究規劃師。我們明確告訴它它擁有兩種工具(search_10k 和 search_web),並指導它何時使用每一種。這就是“工具感知”的部分。
我們不只是要求它制定一個計劃,而是要求它創建一個直接映射到我們所構建能力的計劃。
現在我們可以初始化推理模型,並將其與我們的提示鏈接起來。這裏一個非常重要的步驟是告訴 LLM,它的最終輸出必須是我們 Pydantic Plan 類的格式。這使得輸出結構化且可預測。
# 初始化我們強大的推理模型,如配置中所定義reasoning_llm = ChatOpenAI(model=config["reasoning_llm"], temperature=0)# 通過將提示管道連接到 LLM 並指示其使用我們的結構化 'Plan' 輸出,來創建規劃器智能體planner_agent = planner_prompt | reasoning_llm.with_structured_output(Plan)print("Tool-Aware Planner Agent created successfully.")# 讓我們用我們的複雜查詢來測試規劃器智能體,看看它的輸出print("\n--- Testing Planner Agent ---")test_plan = planner_agent.invoke({"question": complex_query_adv})# 使用 rich 的 pretty print 功能來清晰、可讀地顯示 Pydantic 對象rprint(test_plan)我們將 planner_prompt 通過管道傳遞給我們強大的 reasoning_llm,然後使用 .with_structured_output(Plan) 方法。這告訴 LangChain 使用模型的功能調用能力,將其響應格式化為一個與我們的 Plan Pydantic 模式完美匹配的 JSON 對象。這比嘗試解析純文本響應要可靠得多。
讓我們看看當我們用我們的挑戰性查詢測試它時的輸出。
#### OUTPUT ####Tool-Aware Planner Agent created successfully.--- Testing Planner Agent ---Plan(│ steps=[│ │ Step(│ │ │ sub_question="What are the key risks related to competition as stated in NVIDIA's 2023 10-K filing?",│ │ │ justification="This step is necessary to extract the foundational information about competitive risks directly from the source document as requested by the user.",│ │ │ tool='search_10k',│ │ │ keywords=['competition', 'risk factors', 'semiconductor industry', 'competitors'],│ │ │ document_section='Item 1A. Risk Factors'│ │ ),│ │ Step(│ │ │ sub_question="What are the recent news and developments in AMD's AI chip strategy in 2024?",│ │ │ justification="This step requires finding up-to-date, external information that is not available in the 2023 10-K filing. A web search is necessary to get the latest details on AMD's strategy.",│ │ │ tool='search_web',│ │ │ keywords=['AMD', 'AI chip strategy', '2024', 'MI300X', 'Instinct accelerator'],│ │ │ document_section=None│ │ )│ ])如果我們看輸出,你會發現智能體不只是給了我們一個模糊的計劃,它產生了一個結構化的 Plan 對象。它正確地識別出查詢有兩個部分。
- 對於第一部分,它知道答案在 10-K 文件中,並選擇了
search_10k工具,甚至正確地猜到了正確的文檔章節。 - 對於第二部分,它知道“2024 年的新聞”不可能出現在 2023 年的文檔中,並正確地選擇了
search_web工具。這是我們的流水線在思考過程中至少會給出有希望結果的第一個跡象。
通過查詢重寫智能體優化檢索
好了,我們現在有了一個包含良好子問題的計劃。
但像“風險有哪些?”這樣的問題並不是一個好的搜索查詢。它太籠統了。搜索引擎,無論是向量數據庫還是網絡搜索,對於具體、關鍵詞豐富的查詢效果最好。
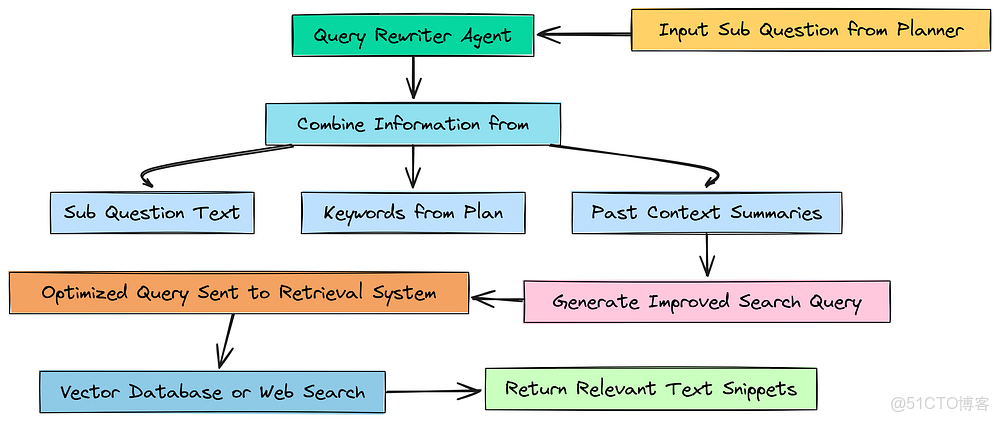
查詢重寫智能體
為了解決這個問題,我們將構建另一個小型的、專門化的智能體:查詢重寫器 (Query Rewriter)。它唯一的工作就是獲取當前步驟的子問題,並通過添加我們已經學到的相關關鍵詞和上下文,使其更適合搜索。
首先,讓我們為這個新智能體設計提示。
from langchain_core.output_parsers import StrOutputParser # 用於將 LLM 的輸出解析為簡單字符串# 我們查詢重寫器的提示,指示它扮演搜索專家的角色query_rewriter_prompt = ChatPromptTemplate.from_messages([ ("system", """You are a search query optimization expert. Your task is to rewrite a given sub-question into a highly effective search query for a vector database or web search engine, using keywords and context from the research plan.The rewritten query should be specific, use terminology likely to be found in the target source (a financial 10-K or news articles), and be structured to retrieve the most relevant text snippets."""), ("human", "Current sub-question: {sub_question}\n\nRelevant keywords from plan: {keywords}\n\nContext from past steps:\n{past_context}")])我們基本上是在告訴這個智能體要像一個搜索查詢優化專家一樣行事。我們給它三部分信息來處理:簡單的 sub_question、我們規劃器已經識別出的 keywords,以及來自任何先前研究步驟的 past_context。這為它構建一個更好的查詢提供了所有必要的原材料。
現在我們可以初始化這個智能體了。這是一個簡單的鏈,因為我們只需要一個字符串作為輸出。
# 通過將提示管道連接到我們的推理 LLM 和一個字符串輸出解析器來創建智能體query_rewriter_agent = query_rewriter_prompt | reasoning_llm | StrOutputParser()print("Query Rewriter Agent created successfully.")# 讓我們來測試重寫器智能體。我們將假裝已經完成了我們計劃的前兩個步驟。print("\n--- Testing Query Rewriter Agent ---")# 假設我們正處於一個需要前兩步上下文的最終綜合步驟。test_sub_q = "How does AMD's 2024 AI chip strategy potentially exacerbate the competitive risks identified in NVIDIA's 10-K?"test_keywords = ['impact', 'threaten', 'competitive pressure', 'market share', 'technological change']# 我們創建一些模擬的“過去上下文”來模擬智能體在真實運行中此時會知道什麼。test_past_context = "Step 1 Summary: NVIDIA's 10-K lists intense competition and rapid technological change as key risks. Step 2 Summary: AMD launched its MI300X AI accelerator in 2024 to directly compete with NVIDIA's H100."# 使用我們的測試數據調用智能體rewritten_q = query_rewriter_agent.invoke({ "sub_question": test_sub_q, "keywords": test_keywords, "past_context": test_past_context})print(f"Original sub-question: {test_sub_q}")print(f"Rewritten Search Query: {rewritten_q}")為了正確測試這個,我們必須模擬一個真實場景。我們創建了一個 test_past_context 字符串,它代表了智能體已經從其計劃的前兩個步驟中生成的摘要。然後我們將這個,連同下一個子問題,一起餵給我們的 query_rewriter_agent。
讓我們看看結果。
#### OUTPUT ####Query Rewriter Agent created successfully.--- Testing Query Rewriter Agent ---Original sub-question: How does AMD 2024 AI chip strategy potentially exacerbate the competitive risks identified in NVIDIA 10-K?Rewritten Search Query: analysis of how AMD 2024 AI chip strategy, including products like the MI300X, exacerbates NVIDIA's stated competitive risks such as rapid technological change and market share erosion in the data center and AI semiconductor industry原始問題是給分析師的,而重寫後的查詢是給搜索引擎的。它被賦予了諸如“MI300X”、“市場份額侵蝕”和“數據中心”等特定術語,所有這些都是從關鍵詞和過去的上下文中綜合出來的。
像這樣的查詢更有可能檢索到完全正確的文檔,使我們的整個系統更加準確和高效。這個重寫步驟將是我們主要智能體循環中的一個關鍵部分。
利用元數據感知的分塊實現精確檢索
所以,基本上,我們的規劃器智能體給了我們一個很好的機會。它不只是説找到風險,它給出了一個提示:在“Item 1A. Risk Factors”章節中尋找風險。
但目前,我們的檢索器無法使用這個提示。我們的向量存儲只是一個包含 378 個文本塊的龐大、扁平的列表。它根本不知道什麼是“章節”。
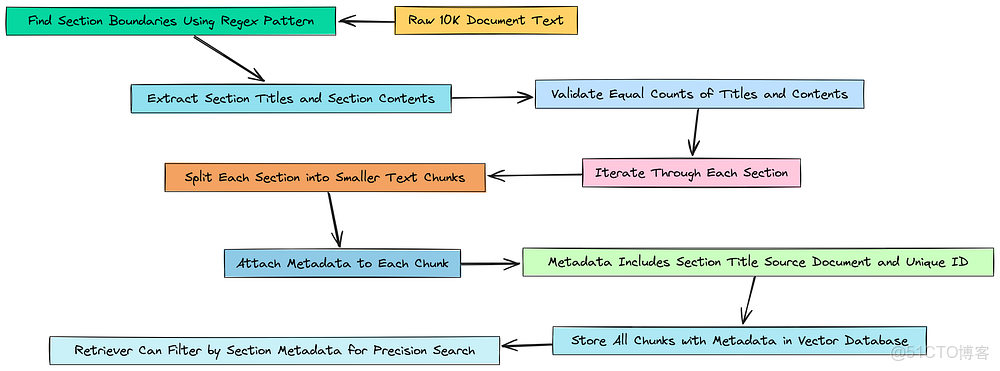
元數據感知的分塊
我們需要解決這個問題。我們將從頭開始重建我們的文檔塊。這一次,對於我們創建的每一個塊,我們都會添加一個標籤或標記——它的元數據——告訴我們的系統它究竟來自 10-K 文件的哪個章節。這將使我們的智能體能夠在之後執行高精度的、過濾後的搜索。
首先,我們需要一種方法來以編程方式找到每個章節在我們原始文本文件中的起始位置。如果我們查看文檔,可以發現一個清晰的模式:每個主要章節都以單詞“ITEM”開頭,後跟一個數字,如“ITEM 1A”或“ITEM 7”。這非常適合使用正則表達式來處理。
# 這個正則表達式旨在查找 10-K 文本中像 'ITEM 1A.' 或 'ITEM 7.' 這樣的章節標題。# 它尋找單詞 'ITEM',後跟一個空格、一個數字、一個可選的字母、一個句點,然後捕獲標題文本。# `re.IGNORECASE | re.DOTALL` 標誌使搜索不區分大小寫,並允許 '.' 匹配換行符。section_pattern = r"(ITEM\\s+\\d[A-Z]?\\.\\s*.*?)(?=\\nITEM\\s+\\d[A-Z]?\\.|$)"我們基本上是創建了一個模式,它將作為我們的章節探測器。它的設計應該足夠靈活,以捕捉不同的格式,同時又足夠具體,不會抓取錯誤的文本。
現在我們可以使用這個模式將我們的文檔切分成兩個獨立的列表:一個只包含章節標題,另一個包含每個章節內的內容。
# 我們將使用之前從 Document 對象中加載的原始文本raw_text = documents[0].page_content# 使用 re.findall 應用我們的模式,並將所有章節標題提取到一個列表中section_titles = re.findall(section_pattern, raw_text, re.IGNORECASE | re.DOTALL)# 一個快速的清理步驟,去除標題中任何多餘的空白或換行符section_titles = [title.strip().replace('\\n', ' ') for title in section_titles]# 現在,使用 re.split 在每個章節標題出現的地方將文檔分割開sections_content = re.split(section_pattern, raw_text, flags=re.IGNORECASE | re.DOTALL)# 分割結果是一個混合了標題和內容的列表,所以我們過濾它以只獲取內容部分sections_content = [content.strip() for content in sections_content if content.strip() andnot content.strip().lower().startswith('item ')]print(f"Identified {len(section_titles)} document sections.")# 這是一個至關重要的健全性檢查:如果標題的數量與內容塊的數量不匹配,説明出了問題。assertlen(section_titles) == len(sections_content), "Mismatch between titles and content sections"這是一種解析半結構化文檔的非常有效的方法。我們使用了兩次正則表達式模式:一次是為了獲得一個乾淨的所有章節標題列表,另一次是為了將主文本分割成一個內容塊列表。assert 語句讓我們相信我們的解析邏輯是可靠的。
好了,現在我們有了各個部分:一個標題列表和一個相應的內容列表。我們現在可以遍歷它們,創建我們最終的、富含元數據的文本塊。
import uuid # 我們將用它為每個塊賦予一個唯一的 ID,這是一個好習慣# 這個列表將存放我們新的、富含元數據的文檔塊doc_chunks_with_metadata = []# 使用 enumerate 遍歷每個章節的內容及其標題for i, content inenumerate(sections_content): # 獲取當前內容塊對應的標題 section_title = section_titles[i] # 使用和之前一樣的文本分割器,但這次,我們只在當前章節的內容上運行它 section_chunks = text_splitter.split_text(content) # 現在,遍歷從這一個章節創建的更小的塊 for chunk in section_chunks: # 為這個特定的塊生成一個唯一的 ID chunk_id = str(uuid.uuid4()) # 為這個塊創建一個新的 LangChain Document 對象 doc_chunks_with_metadata.append( Document( page_content=chunk, # 這是最重要的部分:我們附加元數據 metadata={ "section": section_title, # 這個塊所屬的章節 "source_doc": doc_path_clean, # 文檔來源 "id": chunk_id # 這個塊的唯一 ID } ) )print(f"Created {len(doc_chunks_with_metadata)} chunks with section metadata.")print("\n--- Sample Chunk with Metadata ---")# 為了證明它奏效了,我們找一個我們知道應該在'Risk Factors'章節的塊並打印出來sample_chunk = next(c for c in doc_chunks_with_metadata if"Risk Factors"in c.metadata.get("section", ""))print(sample_chunk)這是我們升級的核心。我們逐一遍歷每個章節。對於每個章節,我們創建我們的文本塊。但在將它們添加到我們的最終列表之前,我們創建一個 metadata 字典並附加上 section_title。這有效地為每一個塊都打上了其來源的標籤。
讓我們看看輸出,並比較一下差異。
#### OUTPUT ####Processing document and adding metadata...Identified 22 document sections.Created 381 chunks with section metadata.--- Sample Chunk with Metadata ---Document(│ page_content='Our industry is intensely competitive. We operate in the semiconductor\\nindustry, which is intensely competitive and characterized by rapid\\ntechnological change and evolving industry standards. We compete with a number of\\ncompanies that have different business models and different combinations of\\nhardware, software, and systems expertise, many of which have substantially\\ngreater resources than we have. We expect competition to increase from existing\\ncompetitors, as well as new and emerging companies. Our competitors include\\nIntel, AMD, and Qualcomm; cloud service providers, or CSPs, such as Amazon Web\\nServices, or AWS, Google Cloud, and Microsoft Azure; and various companies\\ndeveloping or that may develop processors or systems for the AI, HPC, data\\ncenter, gaming, professional visualization, and automotive markets. Some of our\\ncustomers are also our competitors. Our business could be materially and\\nadversely affected if our competitors announce or introduce new products, services,\\nor technologies that have better performance or features, are less expensive, or\\nthat gain market acceptance.',│ metadata={│ │ 'section': 'Item 1A. Risk Factors.',│ │ 'source_doc': './data/nvda_10k_2023_clean.txt',│ │ 'id': '...'│ })看看那個 metadata 塊。和之前相同的文本塊現在附加上了一段上下文信息:'section': 'Item 1A. Risk Factors.'。
現在,當我們的智能體需要尋找風險時,它可以告訴檢索器,“嘿,不要搜索全部 381 個塊。只搜索那些章節元數據是‘Item 1A. Risk Factors’的塊”。
這個簡單的改變將我們的檢索器從一個遲鈍的工具轉變為一個外科手術刀,這也是構建真正生產級別 RAG 系統的關鍵原則。
創建多階段檢索漏斗
到目前為止,我們已經設計了一個智能的規劃器,並用元數據豐富了我們的文檔。現在,我們準備構建我們系統的核心:一個複雜的檢索流水線。
一個簡單的、一次性的語義搜索已經不夠好了。對於一個生產級別的智能體,我們需要一個既自適應又多階段的檢索過程。
我們將我們的檢索過程設計成一個漏斗,其中每個階段都會精煉前一階段的結果:
多階段漏斗
- • 檢索監督器 (The Retrieval Supervisor): 我們將構建一個新的監督器智能體,它作為一個動態路由器,分析每個子問題並選擇最佳的搜索策略(向量、關鍵詞或混合搜索)。
- • 階段 1(廣泛召回): 我們將實現我們的監督器可以選擇的不同檢索策略,重點是撒下一張大網,捕捉所有可能相關的文檔。
- • 階段 2(高精度): 我們將使用一個交叉編碼器(Cross-Encoder)模型來重排序初步結果,剔除噪音並將最相關的文檔提升到頂部。
- • 階段 3(綜合): 最後,我們將創建一個蒸餾智能體 (Distiller Agent),將排名靠前的文檔壓縮成一個單一、簡潔的段落,作為我們下游智能體的上下文。
使用監督器動態選擇策略
基本上,並非所有的搜索查詢都是一樣的。像“‘計算與網絡’部門的收入是多少?”這樣的問題包含具體的、精確的術語。基於關鍵詞的搜索對此非常完美。
但像……
“公司對市場競爭的情緒如何?”這樣的問題是概念性的。基於語義的、向量的搜索會好得多。
監督智能體
我們不會硬編碼一種策略,而是將構建一個小型、智能的智能體,即檢索監督器,來為我們做這個決定。它唯一的工作就是查看搜索查詢,並決定我們的哪種檢索方法最合適。
首先,我們需要定義我們的監督器可以做出的可能決策。我們將使用一個 Pydantic BaseModel 來結構化其輸出。
class RetrievalDecision(BaseModel): # 選擇的檢索策略。必須是這三個選項之一。 strategy: Literal["vector_search", "keyword_search", "hybrid_search"] # 智能體對其選擇的理由。 justification: str監督器必須選擇這三種策略中的一種,並解釋其推理過程。這使其決策過程透明且可靠。
現在,讓我們創建將指導該智能體行為的提示。
retrieval_supervisor_prompt = ChatPromptTemplate.from_messages([ ("system", """You are a retrieval strategy expert. Based on the user's query, you must decide the best retrieval strategy.You have three options:1. `vector_search`: Best for conceptual, semantic, or similarity-based queries.2. `keyword_search`: Best for queries with specific, exact terms, names, or codes (e.g., 'Item 1A', 'Hopper architecture').3. `hybrid_search`: A good default that combines both, but may be less precise than a targeted strategy."""), ("human", "User Query: {sub_question}") # 重寫後的搜索查詢將在此處傳遞。])我們在這裏創建了一個非常直接的提示,告訴 LLM 它的角色是檢索策略專家,並清楚地解釋了其可用的每種策略在何時最為有效。
最後,我們可以組裝我們的監督器智能體。
# 通過將我們的提示傳遞給推理 LLM 並使用我們的 Pydantic 類結構化其輸出來創建智能體retrieval_supervisor_agent = retrieval_supervisor_prompt | reasoning_llm.with_structured_output(RetrievalDecision)print("Retrieval Supervisor Agent created.")# 讓我們用兩種不同類型的查詢來測試它,看看它的行為如何print("\n--- Testing Retrieval Supervisor Agent ---")query1 = "revenue growth for the Compute & Networking segment in fiscal year 2023"decision1 = retrieval_supervisor_agent.invoke({"sub_question": query1})print(f"Query: '{query1}'")print(f"Decision: {decision1.strategy}, Justification: {decision1.justification}")query2 = "general sentiment about market competition and technological innovation"decision2 = retrieval_supervisor_agent.invoke({"sub_question": query2})print(f"\nQuery: '{query2}'")print(f"Decision: {decision2.strategy}, Justification: {decision2.justification}")在這裏,我們將所有部分連接起來。
我們的 .with_structured_output(RetrievalDecision) 再次承擔了繁重的工作,確保我們從 LLM 那裏得到一個乾淨、可預測的 RetrievalDecision 對象。讓我們看看測試結果。
#### OUTPUT ####Retrieval Supervisor Agent created.# --- Testing Retrieval Supervisor Agent ---Query: 'revenue growth for the Compute & Networking segment in fiscal year 2023'Decision: keyword_search, Justification: The query contains specific keywords like 'revenue growth', 'Compute & Networking', and 'fiscal year 2023' which are ideal for a keyword-based search to find exact financial figures.Query: 'general sentiment about market competition and technological innovation'Decision: vector_search, Justification: This query is conceptual and seeks to understand sentiment and broader themes. Vector search is better suited to capture the semantic meaning of 'market competition' and 'technological innovation' rather than relying on exact keywords.我們可以看到,它正確地識別出第一個查詢充滿了特定術語,並選擇了 keyword_search。
對於第二個概念性和抽象性的查詢,它正確地選擇了 vector_search。在我們檢索漏斗開始時的這種動態決策,是對“一刀切”方法的一個很好的升級。
通過混合、關鍵詞和語義搜索實現廣泛召回
既然我們有了一個監督器來選擇我們的策略,我們就需要構建檢索策略本身。我們漏斗的這個第一階段完全是關於召回(Recall)——我們的目標是撒下一張大網,捕捉每一個可能相關的文檔,即使我們在此過程中會拾取一些噪音。
廣泛召回
為此,我們將實現三個我們的監督器可以調用的不同搜索函數:
- 向量搜索 (Vector Search): 我們的標準語義搜索,但現在升級為使用元數據過濾器。
- 關鍵詞搜索 (Keyword Search, BM25): 一種經典的、強大的算法,擅長查找包含特定、精確術語的文檔。
- 混合搜索 (Hybrid Search): 一種兩全其美的方法,它使用一種稱為倒數排序融合(Reciprocal Rank Fusion, RRF)的技術結合了向量搜索和關鍵詞搜索的結果。
首先,我們需要使用我們在上一節中創建的富含元數據的塊來創建一個新的、高級的向量存儲。
import numpy as np # Python 中用於數值運算的基礎庫from rank_bm25 import BM25Okapi # 用於實現 BM25 關鍵詞搜索算法的庫print("Creating advanced vector store with metadata...")# 我們創建一個新的 Chroma 向量存儲,這次使用我們富含元數據的塊advanced_vector_store = Chroma.from_documents( documents=doc_chunks_with_metadata, embedding=embedding_function)print(f"Advanced vector store created with {advanced_vector_store._collection.count()} embeddings.")這是一個簡單但關鍵的步驟。這個 advanced_vector_store 現在包含與我們基線相同的文本,但每個嵌入的塊都用其章節標題進行了標記,這解鎖了我們執行過濾搜索的能力。
接下來,我們需要為我們的關鍵詞搜索做準備。BM25 算法通過分析文檔中單詞的頻率來工作。要啓用此功能,我們需要通過將每個文檔的內容分割成一個單詞列表(tokens)來預處理我們的語料庫。
print("\nBuilding BM25 index for keyword search...")# 創建一個列表,其中每個元素都是來自一個文檔的單詞列表tokenized_corpus = [doc.page_content.split(" ") for doc in doc_chunks_with_metadata]# 創建一個包含所有唯一文檔 ID 的列表doc_ids = [doc.metadata["id"] for doc in doc_chunks_with_metadata]# 創建一個從文檔 ID 到完整 Document 對象的映射,以便於查找doc_map = {doc.metadata["id"]: doc for doc in doc_chunks_with_metadata}# 使用我們的分詞語料庫初始化 BM25Okapi 索引bm25 = BM25Okapi(tokenized_corpus)我們基本上是為我們的 BM25 索引創建了必要的數據結構。tokenized_corpus 是算法將要搜索的對象,而 doc_map 將允許我們在搜索完成後快速檢索完整的 Document 對象。
現在我們可以定義我們的三個檢索函數。
# 策略 1: 純向量搜索,帶元數據過濾defvector_search_only(query: str, section_filter: str = None, k: int = 10): # 這個字典定義了元數據過濾器。ChromaDB 只會搜索匹配此條件的文檔。 filter_dict = {"section": section_filter} if section_filter and"Unknown"notin section_filter elseNone # 執行相似性搜索,並可選地使用過濾器 return advanced_vector_store.similarity_search(query, k=k, filter=filter_dict)# 策略 2: 純關鍵詞搜索 (BM25)defbm25_search_only(query: str, k: int = 10): # 對傳入的查詢進行分詞 tokenized_query = query.split(" ") # 獲取查詢相對於語料庫中所有文檔的 BM25 分數 bm25_scores = bm25.get_scores(tokenized_query) # 獲取得分最高的 k 個文檔的索引 top_k_indices = np.argsort(bm25_scores)[::-1][:k] # 使用我們的 doc_map 返回得分最高的文檔的完整 Document 對象 return [doc_map[doc_ids[i]] for i in top_k_indices]# 策略 3: 混合搜索,採用倒數排序融合 (RRF)defhybrid_search(query: str, section_filter: str = None, k: int = 10): # 1. 執行關鍵詞搜索 bm25_docs = bm25_search_only(query, k=k) # 2. 執行帶元數據過濾的語義搜索 semantic_docs = vector_search_only(query, section_filter=section_filter, k=k) # 3. 使用倒數排序融合 (RRF) 合併並重新排序結果 # 獲取兩種搜索方法找到的所有文檔的唯一集合 all_docs = {doc.metadata["id"]: doc for doc in bm25_docs + semantic_docs}.values() # 從每個搜索結果中創建僅包含文檔 ID 的列表 ranked_lists = [[doc.metadata["id"] for doc in bm25_docs], [doc.metadata["id"] for doc in semantic_docs]] # 初始化一個字典來存儲每個文檔的 RRF 分數 rrf_scores = {} # 遍歷每個排名列表(BM25 和語義搜索) for doc_list in ranked_lists: # 遍歷列表中的每個文檔 ID 及其排名 (i) for i, doc_id inenumerate(doc_list): if doc_id notin rrf_scores: rrf_scores[doc_id] = 0 # RRF 公式:將 1 / (排名 + k) 加到分數上。我們使用 k=61 作為標準默認值。 rrf_scores[doc_id] += 1 / (i + 61) # 根據它們的最終 RRF 分數按降序對文檔 ID 進行排序 sorted_doc_ids = sorted(rrf_scores.keys(), key=lambda x: rrf_scores[x], reverse=True) # 根據融合後的排名返回前 k 個 Document 對象 final_docs = [doc_map[doc_id] for doc_id in sorted_doc_ids[:k]] return final_docsprint("\nAll retrieval strategy functions ready.")我們現在已經實現了我們自適應檢索系統的核心。
- •
vector_search_only函數是我們升級後的語義搜索。關鍵的增加是filter=filter_dict參數,它允許我們傳遞來自我們規劃器Step中的document_section,並強制搜索只考慮具有該元數據的塊。 - •
bm25_search_only函數是我們的純關鍵詞檢索器。對於查找語義搜索可能錯過的特定術語,它非常快速和有效。 - •
hybrid_search函數並行運行兩種搜索,然後使用 RRF 智能地合併結果。RRF 是一個簡單但強大的算法,它根據文檔在每個列表中的位置來排名,有效地給予在兩種搜索結果中都排名靠前的文檔更高的權重。
讓我們做一個快速測試,看看我們的關鍵詞搜索是如何工作的。我們將搜索我們的規劃器識別出的確切章節標題。
# 測試關鍵詞搜索,看它是否能精確找到特定章節print("\n--- Testing Keyword Search ---")test_query = "Item 1A. Risk Factors"test_results = bm25_search_only(test_query)print(f"Query: {test_query}")print(f"Found {len(test_results)} documents. Top result section: {test_results[0].metadata['section']}")
``````plaintext
#### OUTPUT ####Creating advanced vector store with metadata...Advanced vector store created with 381 embeddings.Building BM25 index for keyword search...All retrieval strategy functions ready.# --- Testing Keyword Search ---Query: Item 1A. Risk FactorsFound 10 documents. Top result section: Item 1A. Risk Factors.輸出正是我們想要的。BM25 搜索以關鍵詞為中心,僅通過搜索標題就能完美、即時地檢索到來自 Item 1A. Risk Factors 章節的文檔。
我們的監督器現在可以在查詢包含像章節標題這樣的特定關鍵詞時,選擇這個精確的工具。
隨着我們廣泛召回階段的構建完成,我們有了一個強大的機制來找到所有可能相關的文檔。然而,這張大網也可能帶來不相關的噪音。我們漏斗的下一個階段將專注於用高精度來過濾這些噪音。
使用交叉編碼器重排序器實現高精度
所以,我們第一階段的檢索在**召回(Recall)**方面做得很好。它提取了 10 份可能與我們子問題相關的文檔。
但問題在於,它們只是可能相關。將這 10 個文本塊全部直接餵給我們主要的推理 LLM 是低效且有風險的。
這會增加 token 成本,更重要的是,它可能會用嘈雜的、半相關的信息來混淆模型。
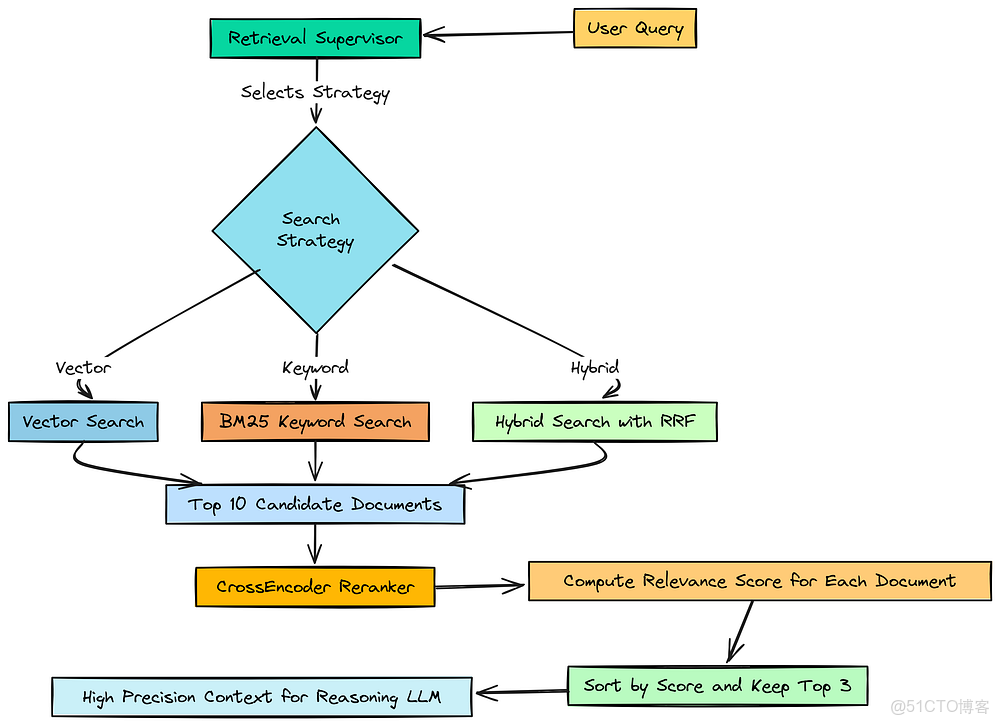
高精度
我們現在需要的是一個精度階段(Precision stage)。我們需要一種方法來檢查那 10 份候選文檔,並挑選出絕對最好的。這就是**重排序器(Reranker)**發揮作用的地方。
關鍵區別在於這些模型的工作方式。
- 我們最初的檢索使用雙編碼器(bi-encoder)(即嵌入模型),它獨立地為查詢和文檔創建向量。它速度快,非常適合在數百萬個項目中進行搜索。
- 而**交叉編碼器(cross-encoder)**則將查詢和單個文檔作為一個對(pair)一起處理,並進行更深入、更細緻的比較。它速度較慢,但準確得多。
所以,基本上,我們想構建一個函數,它接收我們檢索到的 10 份文檔,並使用一個交叉編碼器模型為每一份文檔給出一個精確的相關性分數。然後,我們將只保留我們 config 中定義的前 3 份。
首先,讓我們初始化我們的交叉編碼器模型。我們將使用 sentence-transformers 庫中一個小型但高效的模型,正如我們配置中所指定的。
from sentence_transformers import CrossEncoder # 使用交叉編碼器模型的庫print("Initializing CrossEncoder reranker...")# 使用我們中央配置字典中的名稱初始化 CrossEncoder 模型。# 如果模型沒有被緩存,庫將自動從 Hugging Face Hub 下載。reranker = CrossEncoder(config["reranker_model"])我們基本上是將預訓練的重排序模型加載到內存中。這隻需要做一次。我們選擇的模型 ms-marco-MiniLM-L-6-v2 在這項任務中非常受歡迎,因為它在速度和準確性之間提供了很好的平衡。
現在我們可以創建將執行重排序的函數。
def rerank_documents_function(query: str, documents: List[Document]) -> List[Document]: # 如果沒有文檔需要重排序,立即返回一個空列表。 ifnot documents: return [] # 創建交叉編碼器所需的 [查詢, 文檔內容] 對。 pairs = [(query, doc.page_content) for doc in documents] # 使用重排序器為每個對預測一個相關性分數。這將返回一個分數列表。 scores = reranker.predict(pairs) # 將原始文檔與它們的新分數結合起來。 doc_scores = list(zip(documents, scores)) # 根據分數按降序對 (文檔, 分數) 元組列表進行排序。 doc_scores.sort(key=lambda x: x[1], reverse=True) # 從排序後的前 N 個結果中僅提取 Document 對象。 # 要保留的文檔數量由我們配置中的 'top_n_rerank' 控制。 reranked_docs = [doc for doc, score in doc_scores[:config["top_n_rerank"]]] return reranked_docs這個函數 rerank_documents_function 是我們精度階段的主要部分。它接收來自我們召回階段的 query 和 10 份 documents 列表。最重要的步驟是 reranker.predict(pairs)。
在這裏,模型不是在創建嵌入,它是在對查詢與每個文檔內容進行全面比較,為每個文檔生成一個相關性分數。
在得到分數後,我們簡單地對文檔進行排序,並切片列表以只保留前 3 個。這個函數的輸出將是一個簡短、乾淨且高度相關的文檔列表——這是我們下游智能體的完美上下文。
這種漏斗式方法,從高召回率的第一階段過渡到高精度的第二階段,是生產級 RAG 系統的一個組成部分。它確保我們獲得最佳證據,同時最小化噪音和成本。
利用上下文蒸餾進行綜合
所以,我們的檢索漏斗工作得非常出色。我們從一個廣泛的搜索開始,得到了 10 個可能相關的文檔。然後,我們的高精度重排序器將其過濾到前 3 個最相關的文本塊。
我們現在處於一個好得多的位置,但在將這些信息交給我們的主要推理智能體之前,我們還可以做最後一個改進。目前,我們有三個獨立的文本塊。
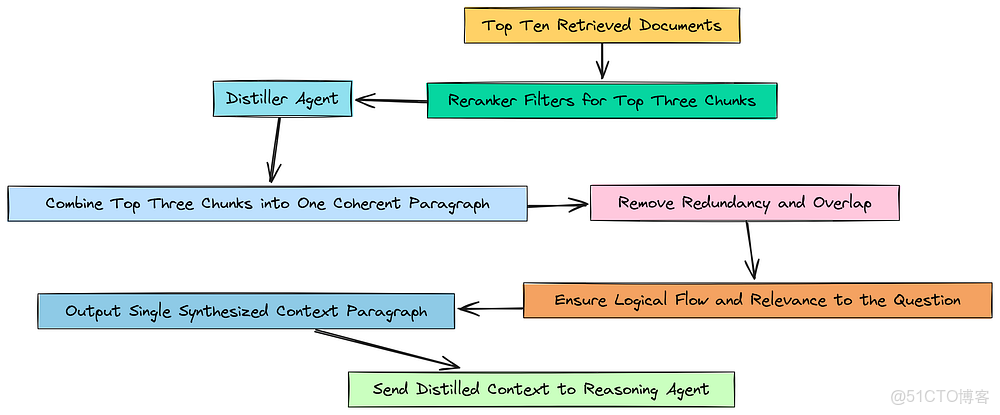
綜合
雖然它們都相關,但可能包含冗餘信息或重疊的句子。將它們作為三個獨立的塊呈現,對於 LLM 來説處理起來仍然有點笨拙。
我們檢索漏斗的最後階段是上下文蒸餾(Contextual Distillation)。目標很簡單:將我們排名前 3 的高度相關的文檔塊蒸餾成一個單一、乾淨、簡潔的段落。這消除了最後的冗餘,併為我們的下游智能體呈現了一份完美綜合的證據。
這個蒸餾步驟就像一個最終的壓縮層。它確保餵給我們更昂貴的推理智能體的上下文儘可能地密集和信息豐富,從而最大化信號並最小化噪音。
為此,我們將創建另一個小型的、專門的智能體,我們稱之為蒸餾智能體(Distiller Agent)。
首先,我們需要設計將指導其行為的提示。
# 我們蒸餾智能體的提示,指示它進行綜合並保持簡潔distiller_prompt = ChatPromptTemplate.from_messages([ ("system", """You are a helpful assistant. Your task is to synthesize the following retrieved document snippets into a single, concise paragraph.The goal is to provide a clear and coherent context that directly answers the question: '{question}'.Focus on removing redundant information and organizing the content logically. Answer only with the synthesized context."""), ("human", "Retrieved Documents:\n{context}") # 我們排名前 3 的重排序文檔內容將在此處傳遞])我們基本上是給這個智能體一個非常集中的任務。我們告訴它:“這裏有一些文本片段。你唯一的工作就是將它們合併成一個連貫的段落,來回答這個具體的問題”。“僅用綜合後的上下文作答”的指令很重要,它防止智能體添加任何對話性的廢話或試圖自己回答問題。它純粹是一個文本處理工具。
現在,我們可以組裝我們簡單的 distiller_agent。
# 通過將我們的提示管道連接到推理 LLM 和一個字符串輸出解析器來創建智能體distiller_agent = distiller_prompt | reasoning_llm | StrOutputParser()print("Contextual Distiller Agent created.")這是另一個直接的 LCEL 鏈。我們使用 distiller_prompt,將其通過管道傳遞給我們強大的 reasoning_llm 來執行綜合,然後使用 StrOutputParser 來獲得最終的、乾淨的文本段落。
隨着這個 distiller_agent 的創建,我們的多階段檢索漏斗現在已經完成。在我們主要的智能體循環中,每個研究步驟的流程將是:
- 監督器 (Supervisor): 選擇一種檢索策略(
vector、keyword或hybrid)。 - 召回階段 (Recall Stage): 執行所選策略以獲取前 10 份文檔。
- 精度階段 (Precision Stage): 使用
rerank_documents_function獲取前 3 份文檔。 - 蒸餾階段 (Distillation Stage): 使用
distiller_agent將前 3 份文檔壓縮成一個單一、乾淨的段落。
這個多階段過程確保了我們的智能體所使用的證據質量儘可能高。下一步是讓我們的智能體有能力超越其內部知識,去搜索網絡。
通過網絡搜索增強知識
所以,我們的檢索漏斗現在非常強大,但它有一個巨大的盲點。
它只能看到我們 2023 年 10-K 文件內部的內容。為了解決我們的挑戰性查詢,我們的智能體需要找到關於 AMD AI 芯片戰略的最新消息(文件發佈後,即 2024 年的新聞)。這些信息在我們的靜態知識庫中根本不存在。
要真正構建一個“深度思考”的智能體,它需要能夠認識到自身知識的侷限性,併到別處尋找答案。我們需要給它一扇通往外部世界的窗户。
通過網絡增強
在這一步,我們將用一個新工具來增強我們智能體的能力:網絡搜索 (Web Search)。這將我們的系統從一個特定於文檔的問答機器人轉變為一個真正的、多源的研究助理。
為此,我們將使用 Tavily 搜索 API。這是一個專門為 LLM 構建的搜索引擎,提供乾淨、無廣告、相關的搜索結果,非常適合 RAG 流水線。它還與 LangChain 無縫集成。
所以,基本上,我們需要做的第一件事是初始化 Tavily 搜索工具本身。
from langchain_community.tools.tavily_search import TavilySearchResults# 初始化 Tavily 搜索工具。# k=3: 這個參數指示工具為給定的查詢返回前 3 個最相關的搜索結果。web_search_tool = TavilySearchResults(k=3)我們基本上是創建了一個 Tavily 搜索工具的實例,我們的智能體可以調用它。k=3 參數是一個很好的起點,它提供了一些高質量的來源,而不會用太多信息壓垮智能體。
現在,一個原始的 API 響應並不完全是我們所需要的。我們的下游組件,即重排序器和蒸餾器,都是設計用來處理一種特定數據結構的:一個 LangChain Document 對象列表。為確保無縫集成,我們需要創建一個簡單的包裝函數。這個函數將接收一個查詢,調用 Tavily 工具,然後將原始結果格式化為標準的 Document 結構。
def web_search_function(query: str) -> List[Document]: # 使用提供的查詢調用 Tavily 搜索工具。 results = web_search_tool.invoke({"query": query}) # 將結果格式化為 LangChain Document 對象的列表。 # 我們使用列表推導式以實現簡潔易讀的實現。 return [ Document( # 搜索結果的主要內容放入 'page_content'。 page_content=res["content"], # 我們將源 URL 存儲在 'metadata' 字典中以便引用。 metadata={"source": res["url"]} ) for res in results ]這個 web_search_function 扮演了一個至關重要的適配器角色。它調用 web_search_tool.invoke,該函數返回一個字典列表,每個字典包含像 "content" 和 "url" 這樣的鍵。
- 列表推導式隨後遍歷這些結果,並將它們整齊地重新包裝成我們流水線所期望的
Document對象。 page_content獲取主要文本,並且重要的是,我們將url存儲在metadata中。- 這確保了當我們的智能體生成最終答案時,它可以正確地引用其網絡來源。
這使得我們的外部知識源看起來和感覺上都與我們的內部知識源完全一樣,允許我們對兩者使用相同的處理流水線。
函數準備就緒後,讓我們快速測試一下,確保它按預期工作。我們將使用一個與我們主要挑戰的第二部分相關的查詢。
# 使用關於 AMD 2024 年戰略的查詢測試網絡搜索功能print("\n--- Testing Web Search Tool ---")test_query_web = "AMD AI chip strategy 2024"test_results_web = web_search_function(test_query_web)print(f"Found {len(test_results_web)} results for query: '{test_query_web}'")# 打印第一個結果的片段,看看我們得到了什麼if test_results_web: print(f"Top result snippet: {test_results_web[0].page_content[:250]}...")
``````plaintext
#### OUTPUT ####Web search tool (Tavily) initialized.--- Testing Web Search Tool ---Found 3 results for query: 'AMD AI chip strategy 2024'Top result snippet: AMD has intensified its battle with Nvidia in the AI chip market with the release of the Instinct MI300X accelerator, a powerful GPU designed to challenge Nvidia's H100 in training and inference for large language models. Major cloud providers like Microsoft Azure and Oracle Cloud are adopting the MI300X, indicating strong market interest...輸出確認了我們的工具工作正常。它為我們的查詢找到了 3 個相關的網頁。頂部結果的片段正是我們的智能體所缺少的最新、外部信息。
它提到了 AMD 的“Instinct MI300X”及其與 NVIDIA“H100”的競爭——這正是解決我們問題後半部分所需的證據。
我們的智能體現在有了一扇通往外部世界的窗户,並且它的規劃器可以智能地決定何時通過它向外看。最後一塊拼圖是賦予智能體反思其發現並決定何時完成研究的能力。
自我批判與控制流策略
到目前
為止,我們已經構建了一個強大的研究機器。我們的智能體可以創建計劃、選擇正確的工具,並執行一個複雜的檢索漏斗。但還缺少一個關鍵部分:思考自身進展的能力。一個盲目地、一步一步遵循計劃的智能體並非真正的智能。它需要一個自我批判的機制。
自我批判與策略制定
在這裏,我們將構建我們智能體自主性的認知核心。在每個研究步驟之後,我們的智能體將暫停並反思。它會審視剛剛找到的新信息,將其與已知信息進行比較,然後做出戰略決策:我的研究完成了嗎,還是我需要繼續?
這個自我批判循環將我們的系統從一個腳本化的工作流提升為一個自主的智能體。正是這個機制讓它能夠決定何時收集了足夠的證據來自信地回答用户的問題。
我們將使用兩個新的專門智能體來實現這一點:
- 反思智能體 (The Reflection Agent): 這個智能體將接收一個已完成步驟中蒸餾出的上下文,並創建一個簡潔的、一句話的摘要。這個摘要隨後被添加到我們智能體的“研究歷史”中。
- 策略智能體 (The Policy Agent): 這是總策略師。在反思之後,它將檢查整個研究歷史與原始計劃的關係,並做出一個關鍵決策:
CONTINUE_PLAN或FINISH。
更新和反思累積的研究歷史
在我們的智能體完成一個研究步驟(例如,檢索並蒸餾關於 NVIDIA 風險的信息)之後,我們不希望只是簡單地繼續。我們需要將這些新知識整合到智能體的記憶中。
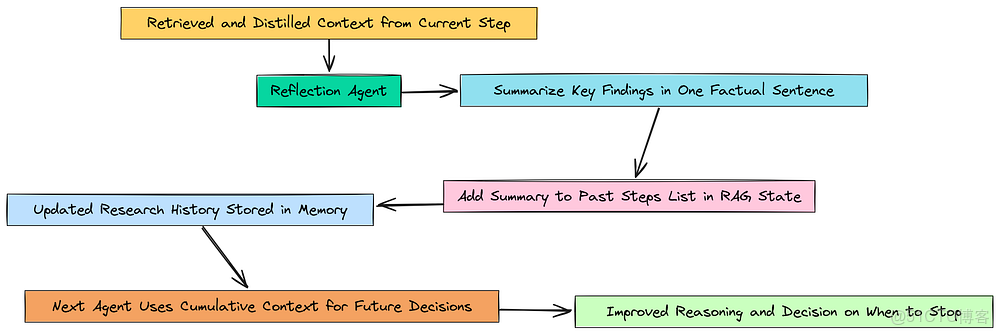
反思性累積
我們將構建一個反思智能體(Reflection Agent),其唯一的工作就是執行這種整合。它將接收當前步驟中豐富的、蒸餾過的上下文,並將其總結成一個單一的、事實性的句子。然後,這個摘要會被添加到我們 RAGState 的 past_steps 列表中。
首先,讓我們為這個智能體創建提示。
# 我們反思智能體的提示,指示它要簡潔和事實。reflection_prompt = ChatPromptTemplate.from_messages([ ("system", """You are a research assistant. Based on the retrieved context for the current sub-question, write a concise, one-sentence summary of the key findings.This summary will be added to our research history. Be factual and to the point."""), ("human", "Current sub-question: {sub_question}\n\nDistilled context:\n{context}")])我們告訴這個智能體要像一個勤奮的研究助理。它的任務不是要有創造性,而是要做一個好的筆記記錄者。它讀取 context 並寫下 summary。現在我們可以組裝智能體本身。
# 通過將我們的提示管道連接到推理 LLM 和一個字符串輸出解析器來創建智能體reflection_agent = reflection_prompt | reasoning_llm | StrOutputParser()print("Reflection Agent created.")這個 reflection_agent 是我們認知循環的一部分。通過創建這些簡潔的摘要,它建立了一個清晰、易讀的研究歷史。這段歷史將成為我們下一個,也是最重要的智能體的輸入:那個決定何時停止的智能體。
構建用於控制流的策略智能體
這是我們智能體自主性的大腦。在 reflection_agent 更新了研究歷史之後,**策略智能體(Policy Agent)**開始發揮作用。它充當整個操作的監督者。
它的工作是審視智能體所知道的一切——原始問題、初始計劃,以及已完成步驟的完整摘要歷史——並做出一個高層次的戰略決策。
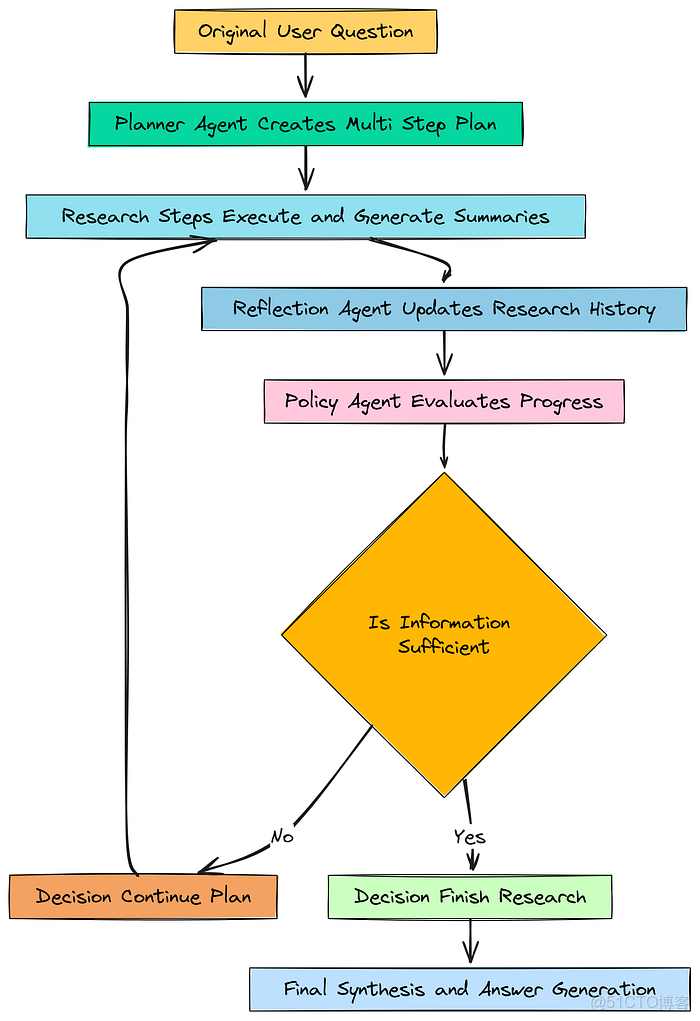
策略智能體
我們將首先使用一個 Pydantic 模型來定義其決策的結構。
class Decision(BaseModel): # 決策必須是這兩個動作之一。 next_action: Literal["CONTINUE_PLAN", "FINISH"] # 智能體必須為其決策提供理由。 justification: str這個 Decision 類強制我們的策略智能體做出一個清晰的、二元的選擇,並解釋其推理過程。這使其行為透明且易於調試。
接下來,我們設計將指導其決策過程的提示。
# 我們策略智能體的提示,指示它扮演總策略師的角色policy_prompt = ChatPromptTemplate.from_messages([ ("system", """You are a master strategist. Your role is to analyze the research progress and decide the next action.You have the original question, the initial plan, and a log of completed steps with their summaries.- If the collected information in the Research History is sufficient to comprehensively answer the Original Question, decide to FINISH.- Otherwise, if the plan is not yet complete, decide to CONTINUE_PLAN."""), ("human", "Original Question: {question}\n\nInitial Plan:\n{plan}\n\nResearch History (Completed Steps):\n{history}")])我們基本上是要求 LLM 進行一次元分析。它不是在回答問題本身;它是在推理研究過程的狀態。它將它所擁有的(history)與它所需要的(plan 和 question)進行比較,並做出判斷。
現在,我們可以組裝 policy_agent。
# 通過將我們的提示管道連接到推理 LLM 並使用我們的 Decision 類來結構化其輸出來創建智能體policy_agent = policy_prompt | reasoning_llm.with_structured_output(Decision)print("Policy Agent created.")# 現在,讓我們用我們研究過程的兩種不同狀態來測試策略智能體print("\n--- Testing Policy Agent (Incomplete State) ---")# 首先,一個只完成了步驟 1 的狀態。plan_str = json.dumps([s.dict() for s in test_plan.steps])incomplete_history = "Step 1 Summary: NVIDIA's 10-K states that the semiconductor industry is intensely competitive and subject to rapid technological change."decision1 = policy_agent.invoke({"question": complex_query_adv, "plan": plan_str, "history": incomplete_history})print(f"Decision: {decision1.next_action}, Justification: {decision1.justification}")print("\n--- Testing Policy Agent (Complete State) ---")# 其次,一個步驟 1 和步驟 2 都已完成的狀態。complete_history = incomplete_history + "\nStep 2 Summary: In 2024, AMD launched its MI300X accelerator to directly compete with NVIDIA in the AI chip market, gaining adoption from major cloud providers."decision2 = policy_agent.invoke({"question": complex_query_adv, "plan": plan_str, "history": complete_history})print(f"Decision: {decision2.next_action}, Justification: {decision2.justification}")為了正確測試我們的 policy_agent,我們模擬了我們智能體生命週期中的兩個不同時刻。在第一個測試中,我們提供給它一個只包含步驟 1 摘要的歷史。在第二個測試中,我們提供給它步驟 1 和步驟 2 的摘要。
讓我們在每種情況下檢查它的決策。
#### OUTPUT ####Policy Agent created.--- Testing Policy Agent (Incomplete State) ---Decision: CONTINUE_PLAN, Justification: The research has only identified NVIDIA's competitive risks from the 10-K. It has not yet gathered the required external information about AMD's 2024 strategy, which is the next step in the plan.--- Testing Policy Agent (Complete State) ---Decision: FINISH, Justification: The research history now contains comprehensive summaries of both NVIDIA's stated competitive risks and AMD's recent AI chip strategy. All necessary information has been gathered to perform the final synthesis and answer the user's question.讓我們理解一下輸出……
- • 在不完整的狀態下, 智能體正確地認識到它缺少關於 AMD 戰略的信息。它查看了它的計劃,看到下一步是使用網絡搜索,並正確地決定
CONTINUE_PLAN。 - • 在完整的狀態下, 在被給予了來自網絡搜索的摘要後,它再次分析了它的歷史。這一次,它認識到它已經擁有了謎題的所有部分——NVIDIA 的風險和 AMD 的戰略。它正確地決定它的研究已經完成,是時候
FINISH了。
有了這個 policy_agent,我們已經構建了我們自主系統的大腦。最後一步是將所有這些組件連接成一個完整、可執行的工作流,使用 LangGraph。
定義圖節點
我們已經設計了所有這些酷炫的、專門化的智能體。現在是時候把它們變成我們工作流的實際構建塊了。在 LangGraph 中,這些構建塊被稱為節點(nodes)。一個節點就是一個執行特定工作的 Python 函數。它以智能體的當前記憶(RAGState)作為輸入,執行其任務,然後返回一個包含對該記憶的任何更新的字典。
我們將為我們的智能體需要採取的每個主要步驟創建一個節點。
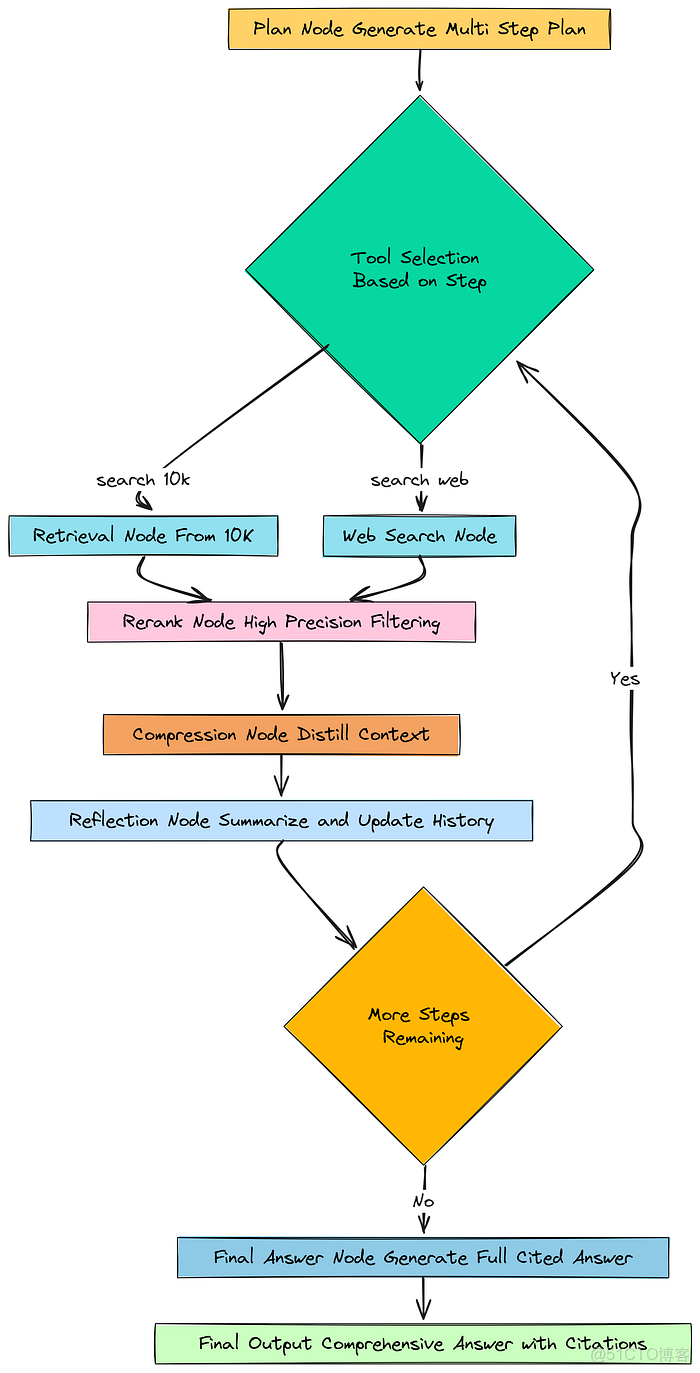
圖節點
首先,我們需要一個簡單的輔助函數。由於我們的智能體經常需要查看研究歷史,我們想要一種簡潔的方式將 past_steps 列表格式化為可讀的字符串。
# 一個輔助函數,用於為提示格式化研究歷史def get_past_context_str(past_steps: List[PastStep]) -> str: # 這將 PastStep 字典列表連接成一個單一的字符串。 # 每個步驟都清楚地標記出來,以便 LLM 理解上下文。 return "\\n\\n".join([f"Step {s['step_index']}: {s['sub_question']}\\nSummary: {s['summary']}" for s in past_steps])我們基本上是創建了一個實用工具,它將在我們的幾個節點內部使用,為我們的提示提供歷史上下文。
現在是我們的第一個真正的節點:plan_node。這是我們智能體推理的起點。它唯一的工作就是調用我們的 planner_agent 並填充我們 RAGState 中的 plan 字段。
# 節點 1: 規劃器def plan_node(state: RAGState) -> Dict: console.print("--- 🧠: Generating Plan ---") # 我們調用之前創建的 planner_agent,傳入用户的原始問題。 plan = planner_agent.invoke({"question": state["original_question"]}) rprint(plan) # 我們返回一個包含我們 RAGState 更新的字典。 # LangGraph 會自動將這個合併到主狀態中。 return {"plan": plan, "current_step_index": 0, "past_steps": []}這個節點啓動了一切。它從狀態中獲取 original_question,得到 plan,然後將 current_step_index 初始化為 0(從第一步開始),併為這次新的運行清除 past_steps 歷史。
接下來,我們需要實際去查找信息的節點。由於我們的規劃器可以在兩個工具之間選擇,我們需要兩個獨立的檢索節點。讓我們從用於搜索我們內部 10-K 文檔的 retrieval_node 開始。
# 節點 2a: 從 10-K 文檔中檢索defretrieval_node(state: RAGState) -> Dict: # 首先,獲取計劃中當前步驟的詳細信息。 current_step_index = state["current_step_index"] current_step = state["plan"].steps[current_step_index] console.print(f"--- 🔍: Retrieving from 10-K (Step {current_step_index + 1}: {current_step.sub_question}) ---") # 使用我們的查詢重寫器來優化用於搜索的子問題。 past_context = get_past_context_str(state['past_steps']) rewritten_query = query_rewriter_agent.invoke({ "sub_question": current_step.sub_question, "keywords": current_step.keywords, "past_context": past_context }) console.print(f" Rewritten Query: {rewritten_query}") # 獲取監督器關於哪個檢索策略最好的決定。 retrieval_decision = retrieval_supervisor_agent.invoke({"sub_question": rewritten_query}) console.print(f" Supervisor Decision: Use `{retrieval_decision.strategy}`. Justification: {retrieval_decision.justification}") # 根據決定,執行正確的檢索函數。 if retrieval_decision.strategy == 'vector_search': retrieved_docs = vector_search_only(rewritten_query, section_filter=current_step.document_section, k=config['top_k_retrieval']) elif retrieval_decision.strategy == 'keyword_search': retrieved_docs = bm25_search_only(rewritten_query, k=config['top_k_retrieval']) else: # hybrid_search retrieved_docs = hybrid_search(rewritten_query, section_filter=current_step.document_section, k=config['top_k_retrieval']) # 返回檢索到的文檔以添加到狀態中。 return {"retrieved_docs": retrieved_docs}這個節點做了很多智能的工作。它不僅僅是一個簡單的檢索器。它協調了一個微型流水線:重寫查詢,詢問監督器最佳策略,然後執行該策略。
現在,我們需要我們另一個工具:網絡搜索的相應節點。
# 節點 2b: 從網絡檢索defweb_search_node(state: RAGState) -> Dict: # 獲取當前步驟的詳細信息。 current_step_index = state["current_step_index"] current_step = state["plan"].steps[current_step_index] console.print(f"--- 🌐: Searching Web (Step {current_step_index + 1}: {current_step.sub_question}) ---") # 為網絡搜索引擎重寫子問題。 past_context = get_past_context_str(state['past_steps']) rewritten_query = query_rewriter_agent.invoke({ "sub_question": current_step.sub_question, "keywords": current_step.keywords, "past_context": past_context }) console.print(f" Rewritten Query: {rewritten_query}") # 調用我們的網絡搜索函數。 retrieved_docs = web_search_function(rewritten_query) # 返回結果。 return {"retrieved_docs": retrieved_docs}這個 web_search_node 更簡單,因為它不需要監督器,它只有一種搜索網絡的方式。但它仍然使用我們強大的查詢重寫器來確保搜索儘可能有效。
在我們檢索文檔(從任一來源)之後,我們需要運行我們的精度和綜合漏斗。我們將為每個階段創建一個節點。首先是 rerank_node。
# 節點 3: 重排序器def rerank_node(state: RAGState) -> Dict: console.print("--- 🎯: Reranking Documents ---") # 獲取當前步驟的詳細信息。 current_step_index = state["current_step_index"] current_step = state["plan"].steps[current_step_index] # 對我們剛剛檢索到的文檔調用我們的重排序函數。 reranked_docs = rerank_documents_function(current_step.sub_question, state["retrieved_docs"]) console.print(f" Reranked to top {len(reranked_docs)} documents.") # 用高精度文檔更新狀態。 return {"reranked_docs": reranked_docs}這個節點接收 retrieved_docs(我們廣泛召回的 10 份文檔),並使用交叉編碼器將它們過濾到前 3 份,將結果放在 reranked_docs 中。
接下來,compression_node 將接收那前 3 份文檔並進行蒸餾。
# 節點 4: 壓縮器 / 蒸餾器def compression_node(state: RAGState) -> Dict: console.print("--- ✂️: Distilling Context ---") # 獲取當前步驟的詳細信息。 current_step_index = state["current_step_index"] current_step = state["plan"].steps[current_step_index] # 將前 3 份文檔格式化為單個字符串。 context = format_docs(state["reranked_docs"]) # 調用我們的蒸餾器智能體將它們綜合成一個段落。 synthesized_context = distiller_agent.invoke({"question": current_step.sub_question, "context": context}) console.print(f" Distilled Context Snippet: {synthesized_context[:200]}...") # 用最終的、乾淨的上下文更新狀態。 return {"synthesized_context": synthesized_context}這個節點是我們檢索漏斗的最後一步。它接收 reranked_docs 併產生一個單一、乾淨的 synthesized_context 段落。
現在我們有了證據,我們需要反思它並更新我們的研究歷史。這是 reflection_node 的工作。
# 節點 5: 反思 / 更新步驟defreflection_node(state: RAGState) -> Dict: console.print("--- 🤔: Reflecting on Findings ---") # 獲取當前步驟的詳細信息。 current_step_index = state["current_step_index"] current_step = state["plan"].steps[current_step_index] # 調用我們的反思智能體來總結髮現。 summary = reflection_agent.invoke({"sub_question": current_step.sub_question, "context": state['synthesized_context']}) console.print(f" Summary: {summary}") # 創建一個包含此步驟所有結果的新 PastStep 字典。 new_past_step = { "step_index": current_step_index + 1, "sub_question": current_step.sub_question, "retrieved_docs": state['reranked_docs'], # 我們保存重排序後的文檔以供最終引用 "summary": summary } # 將新步驟附加到我們的歷史中,並增加步驟索引以移至下一步。 return {"past_steps": state["past_steps"] + [new_past_step], "current_step_index": current_step_index + 1}這個節點是我們智能體的記賬員。它調用 reflection_agent 來創建摘要,然後將當前研究週期的所有結果整齊地打包成一個 new_past_step 對象。然後它將此添加到 past_steps 列表中,並遞增 current_step_index,為智能體的下一個循環做好準備。
最後,當研究完成時,我們需要最後一個節點來生成最終答案。
# 節點 6: 最終答案生成器deffinal_answer_node(state: RAGState) -> Dict: console.print("--- ✅: Generating Final Answer with Citations ---") # 首先,我們需要收集我們從所有過去步驟中收集到的所有證據。 final_context = "" for i, step inenumerate(state['past_steps']): final_context += f"\\n--- Findings from Research Step {i+1} ---\\n" # 我們包含每個文檔的來源元數據(章節或 URL)以啓用引用。 for doc in step['retrieved_docs']: source = doc.metadata.get('section') or doc.metadata.get('source') final_context += f"Source: {source}\\nContent: {doc.page_content}\\n\\n" # 我們創建一個專門用於生成最終、可引用答案的新提示。 final_answer_prompt = ChatPromptTemplate.from_messages([ ("system", """You are an expert financial analyst. Synthesize the research findings from internal documents and web searches into a comprehensive, multi-paragraph answer for the user's original question.Your answer must be grounded in the provided context. At the end of any sentence that relies on specific information, you MUST add a citation. For 10-K documents, use [Source: <section title>]. For web results, use [Source: <URL>]."""), ("human", "Original Question: {question}\n\nResearch History and Context:\n{context}") ]) # 我們為這個最終任務創建一個臨時智能體並調用它。 final_answer_agent = final_answer_prompt | reasoning_llm | StrOutputParser() final_answer = final_answer_agent.invoke({"question": state['original_question'], "context": final_context}) # 用最終答案更新狀態。 return {"final_answer": final_answer}這個 final_answer_node 是我們的大結局。它將 past_steps 歷史中每一步的所有高質量、重排序的文檔整合到一個巨大的上下文中。然後,它使用一個專門的提示來指示我們強大的 reasoning_llm 將這些信息綜合成一個全面的、多段落的、包含引用的答案,從而成功地結束我們的研究過程。
隨着所有節點的定義完成,我們現在擁有了我們智能體的所有構建塊。下一步是定義連接它們並控制圖流程的“線路”。
定義條件邊
我們已經構建了所有的節點。我們有規劃器、檢索器、重排序器、蒸餾器和反思器。可以把它們想象成一個房間裏的一羣專家。現在我們需要定義對話的規則。誰在什麼時候發言?我們如何決定下一步做什麼?
這就是 LangGraph 中邊(edges)的工作。簡單的邊很直接,“在節點 A 之後,總是去節點 B”。但真正的智能來自於條件邊(conditional edges)。
一個條件邊是一個函數,它查看智能體的當前記憶(
RAGState)並做出決策,根據情況將工作流路由到不同的路徑。
我們的智能體需要兩個關鍵的決策函數:
- 一個工具路由器 (
route_by_tool): 在計劃制定後,這個函數將查看計劃的當前步驟,並決定是將工作流發送到retrieve_10k節點還是retrieve_web節點。 - 主控制循環 (
should_continue_node): 這是最重要的一個。在每個研究步驟完成並反思之後,這個函數將調用我們的policy_agent來決定是繼續計劃的下一步,還是結束研究並生成最終答案。
首先,讓我們構建我們簡單的工具路由器。
# 條件邊 1: 工具路由器def route_by_tool(state: RAGState) -> str: # 獲取我們當前所處步驟的索引。 current_step_index = state["current_step_index"] # 從計劃中獲取當前步驟的完整詳情。 current_step = state["plan"].steps[current_step_index] # 返回為此步驟指定的工具名稱。 # LangGraph 將使用這個字符串來決定下一個要去的節點。 return current_step.tool這個函數非常簡單,但至關重要。它就像一個總機。它從狀態中讀取 current_step_index,在 plan 中找到相應的 Step,並返回其 tool 字段的值(將是 "search_10k" 或 "search_web")。當我們連接我們的圖時,我們會告訴它使用這個函數的輸出來選擇下一個節點。
現在我們需要創建一個控制我們智能體主要推理循環的函數。這就是我們的 policy_agent 發揮作用的地方。
# 條件邊 2: 主控制循環defshould_continue_node(state: RAGState) -> str: console.print("--- 🚦: Evaluating Policy ---") # 獲取我們即將開始的步驟的索引。 current_step_index = state["current_step_index"] # 首先,檢查我們的基本停止條件。 # 條件 1: 我們是否已完成計劃中的所有步驟? if current_step_index >= len(state["plan"].steps): console.print(" -> Plan complete. Finishing.") return"finish" # 條件 2: 我們是否已超過我們設定的迭代次數安全限制? if current_step_index >= config["max_reasoning_iterations"]: console.print(" -> Max iterations reached. Finishing.") return"finish" # 一個特例:如果上一步的檢索未能找到任何文檔, # 那麼進行反思就沒有意義了。最好直接進入下一步。 if state.get("reranked_docs") isnotNoneandnot state["reranked_docs"]: console.print(" -> Retrieval failed for the last step. Continuing with next step in plan.") return"continue" # 如果沒有滿足任何基本條件,就該詢問我們的策略智能體了。 # 我們將歷史和計劃格式化為字符串以用於提示。 history = get_past_context_str(state['past_steps']) plan_str = json.dumps([s.dict() for s in state['plan'].steps]) # 調用策略智能體以獲取其戰略決策。 decision = policy_agent.invoke({"question": state["original_question"], "plan": plan_str, "history": history}) console.print(f" -> Decision: {decision.next_action} | Justification: {decision.justification}") # 根據智能體的決策,返回適當的信號。 if decision.next_action == "FINISH": return"finish" else: # CONTINUE_PLAN return "continue"這個 should_continue_node 函數是我們智能體控制流的認知核心。它在每個 reflection_node 之後運行。
- 它首先檢查簡單的、硬編碼的停止標準。計劃是否已用完所有步驟?我們是否達到了
max_reasoning_iterations的安全限制?這些可以防止智能體無限運行。 - 如果這些檢查通過,它就會調用我們強大的
policy_agent。它為策略智能體提供了所需的所有上下文:原始目標(question)、完整plan,以及已完成工作的history。 - 最後,它接收
policy_agent的結構化輸出(CONTINUE_PLAN或FINISH),並返回簡單的字符串"continue"或"finish"。LangGraph 將使用這個字符串來決定是循環回來進行另一個研究週期,還是前進到final_answer_node。
隨着我們的節點(專家)和條件邊(對話規則)的定義完成,我們已經擁有了所需的一切。
是時候將所有這些部分組裝成一個完整、能正常工作的
StateGraph了。
組裝深度思考 RAG 機器
我們已經準備好了所有獨立的組件:
- 我們的節點 (工作者)
- 我們的條件邊 (管理者)。
現在是時候將它們全部連接成一個單一、內聚的系統了。
我們將使用 LangGraph 的 StateGraph 來定義我們智能體的完整認知架構。在這裏,我們將勾勒出我們智能體思考過程的藍圖,精確定義信息如何從一個步驟流向下個步驟。
我們需要做的第一件事是創建一個 StateGraph 的實例。我們將告訴它,它將傳遞的“狀態”是我們的 RAGState 字典。
from langgraph.graph import StateGraph, END # 導入主要的圖組件# 實例化圖,告訴它使用我們的 RAGState TypedDict 作為其狀態模式。graph = StateGraph(RAGState)我們現在有了一個空的圖。下一步是添加我們之前定義的所有節點。.add_node() 方法接受兩個參數:節點的唯一字符串名稱,以及該節點將執行的 Python 函數。
# 將我們所有的 Python 函數添加為圖中的節點graph.add_node("plan", plan_node) # 創建初始計劃的節點graph.add_node("retrieve_10k", retrieval_node) # 內部文檔檢索的節點graph.add_node("retrieve_web", web_search_node) # 外部網絡搜索的節點graph.add_node("rerank", rerank_node) # 執行精確重排序的節點graph.add_node("compress", compression_node) # 蒸餾上下文的節點graph.add_node("reflect", reflection_node) # 總結髮現並更新歷史的節點graph.add_node("generate_final_answer", final_answer_node) # 綜合最終答案的節點現在我們所有的專家都已就位。最後也是最關鍵的一步是定義連接它們的“線路”。在這裏,我們使用 .add_edge() 和 .add_conditional_edges() 方法來定義控制流。
# 我們圖的入口點是 "plan" 節點。每次運行都從這裏開始。graph.set_entry_point("plan")# 在 "plan" 節點之後,我們使用我們的第一個條件邊來決定使用哪個工具。graph.add_conditional_edges( "plan", # 源節點 route_by_tool, # 做出決策的函數 { # 一個將函數輸出字符串映射到目標節點的字典 "search_10k": "retrieve_10k", "search_web": "retrieve_web", },)# 從 10-K 或網絡檢索之後,流程在一段時間內是線性的。graph.add_edge("retrieve_10k", "rerank") # 內部檢索後,總是轉到重排序。graph.add_edge("retrieve_web", "rerank") # 網絡檢索後,也總是轉到重排序。graph.add_edge("rerank", "compress") # 重排序後,總是轉到壓縮。graph.add_edge("compress", "reflect") # 壓縮後,總是轉到反思。# 在 "reflect" 節點之後,我們遇到我們的主條件邊,它控制着推理循環。graph.add_conditional_edges( "reflect", # 源節點 should_continue_node, # 調用我們策略智能體的函數 { # 一個將決策映射到下一步的字典 "continue": "plan", # 如果決策是 "continue",我們循環回到 "plan" 節點以路由下一步。 "finish": "generate_final_answer", # 如果決策是 "finish",我們繼續生成最終答案。 },)# "generate_final_answer" 節點是結束前的最後一步。graph.add_edge("generate_final_answer", END) # 生成答案後,圖結束。print("StateGraph constructed successfully.")這是我們智能體大腦的藍圖。讓我們追蹤一下流程:
- 它總是從
plan開始。 - 然後,
route_by_tool條件邊作為一個開關,將流程導向retrieve_10k或retrieve_web。 - 無論哪個檢索器運行,輸出總是通過
rerank->compress->reflect流水線進行處理。 - 這就到了最重要的部分:
should_continue_node條件邊。這是我們循環推理的核心。
- • 如果策略智能體説
CONTINUE_PLAN,邊會將工作流一直送回plan節點。我們回到plan(而不是直接到下一個檢索器),這樣route_by_tool就可以正確地路由計劃中的下一個步驟。 - • 如果策略智能體説
FINISH,邊會打破循環,並將工作流發送到generate_final_answer節點。 - • 最後,在生成答案之後,圖在
END處終止。
我們已經成功地定義了我們深度思考智能體的完整、複雜和循環的架構。唯一剩下要做的就是將這個藍圖編譯成一個可運行的應用程序,並將其可視化,看看我們構建了什麼。
編譯和可視化迭代工作流
在我們的圖完全連接好之後,組裝過程的最後一步是編譯它。.compile() 方法將我們對節點和邊的抽象定義轉化為一個具體的、可執行的應用程序。
然後,我們可以使用一個內置的 LangGraph 實用工具來生成我們圖的圖表。可視化工作流對於理解和調試複雜的智能體系統非常有幫助。它將我們的代碼轉化為一個直觀的流程圖,清晰地展示了智能體可能的推理路徑。
所以,基本上,我們正在將我們的藍圖變成一台真正的機器。
# .compile() 方法接收我們的圖定義並創建一個可運行的對象。deep_thinking_rag_graph = graph.compile()print("Graph compiled successfully.")# 現在,讓我們可視化我們構建的架構。try: from IPython.display import Image, display # 我們可以得到圖結構的 PNG 圖像。 png_image = deep_thinking_rag_graph.get_graph().draw_png() # 在我們的 notebook 中顯示圖像。 display(Image(png_image))except Exception as e: # 如果 pygraphviz 及其系統依賴項未安裝,這可能會失敗。 print(f"Graph visualization failed: {e}. Please ensure pygraphviz is installed.")deep_thinking_rag_graph 對象現在是我們功能齊全的智能體。然後,可視化代碼調用 .get_graph().draw_png() 來生成我們構建的狀態機的視覺表示。
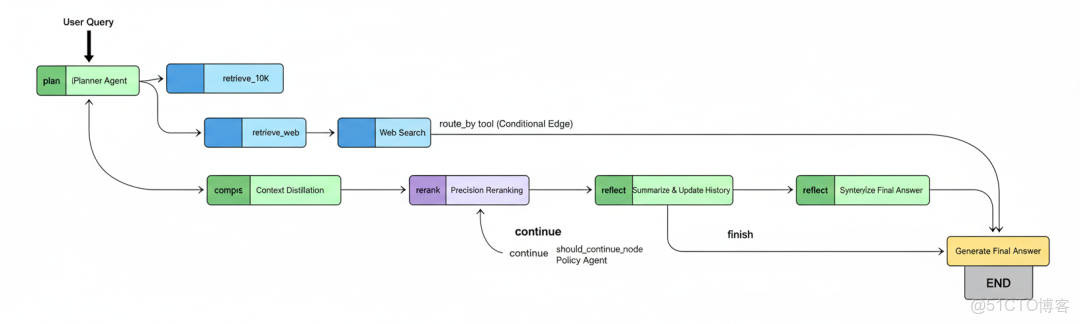
深度思考簡化流水線流程
我們可以清楚地看到:
- • 初始的分支邏輯,其中
route_by_tool在retrieve_10k和retrieve_web之間選擇。 - • 每個研究步驟的線性處理流水線 (
rerank->compress->reflect)。 - • 關鍵的反饋循環,其中
should_continue邊將工作流送回plan節點以開始下一個研究週期。 - • 一旦研究完成,通往
generate_final_answer的最終“出口匝道”。
這是一個能夠思考的系統的架構。現在,讓我們來測試一下它。
運行深度思考流水線
我們已經設計了一個推理引擎。現在是時候看看它是否能成功地完成我們基線系統慘敗的任務了。
我們將使用完全相同的多跳、多源挑戰性查詢來調用我們編譯好的 deep_thinking_rag_graph。我們將使用 .stream() 方法來獲取智能體執行的實時、分步追蹤,觀察它在解決問題時的“思考過程”。
本節的計劃如下:
- • 調用圖: 我們將運行我們的智能體,觀察它執行計劃,在工具之間切換,並建立其研究歷史。
- • 分析最終輸出: 我們將檢查最終的、綜合的答案,看看它是否成功地整合了來自 10-K 文件和網絡的信息。
- • 比較結果: 我們將進行最終的並排比較,以明確地突出我們深度思考智能體的架構優勢。
我們將設置我們的初始輸入,這只是一個包含 original_question 的字典,然後調用 .stream() 方法。stream 方法對於調試和觀察非常棒,因為它在每個節點完成工作後都會產生圖的狀態。
# 這將保存運行完成後圖的最終狀態。final_state = None# 我們圖的初始輸入,包含原始用户查詢。graph_input = {"original_question": complex_query_adv}print("--- Invoking Deep Thinking RAG Graph ---")# 我們使用 .stream() 來實時觀察智能體的過程。# "values" 模式意味着我們在每一步之後都會得到完整的 RAGState 對象。for chunk in deep_thinking_rag_graph.stream(graph_input, stream_mode="values"): # 流中的最後一個塊將是圖的最終狀態。 final_state = chunkprint("\n--- Graph Stream Finished ---")這個循環是我們智能體煥發生機的地方。在每次迭代中,LangGraph 執行工作流中的下一個節點,更新 RAGState,並將新狀態提供給我們。我們嵌入在節點內部的 rich 庫的 console.print 語句將為我們提供智能體行動和決策的實時解説。
#### OUTPUT ####--- Invoking Deep Thinking RAG Graph ------ 🧠: Generating Plan ---plan: steps: - sub_question: What are the key risks related to competition as stated in NVIDIA's 2023 10-K filing? tool: search_10k ... - sub_question: What are the recent news and developments in AMD's AI chip strategy in2024? tool: search_web ...--- 🔍: Retrieving from10-K (Step 1: ...) --- Rewritten Query: key competitive risks for NVIDIA in the semiconductor industry... Supervisor Decision: Use `hybrid_search`. ...--- 🎯: Reranking Documents --- Reranked to top 3 documents.--- ✂️: Distilling Context --- Distilled Context Snippet: NVIDIA operates in the intensely competitive semiconductor industry...--- 🤔: Reflecting on Findings --- Summary: According to its 202310-K, NVIDIA operates in an intensely competitive semiconductor industry...--- 🚦: Evaluating Policy --- -> Decision: CONTINUE_PLAN | Justification: The first step...has been completed. The next step...is still pending...--- 🌐: Searching Web (Step 2: ...) --- Rewritten Query: AMD AI chip strategy news and developments 2024...--- 🎯: Reranking Documents --- Reranked to top 3 documents.--- ✂️: Distilling Context --- Distilled Context Snippet: AMD has ramped up its challenge to Nvidia in the AI accelerator market with its Instinct MI300 series...--- 🤔: Reflecting on Findings --- Summary: In 2024, AMD is aggressively competing with NVIDIA in the AI chip market through its Instinct MI300X accelerator...--- 🚦: Evaluating Policy --- -> Decision: FINISH | Justification: The research history now contains comprehensive summaries of both NVIDIA's stated risks and AMD's recent strategy...--- ✅: Generating Final Answer with Citations ------ Graph Stream Finished ---你可以看到我們設計的執行過程。智能體:
- 規劃: 它創建了正確的兩步、多工具計劃。
- 執行步驟 1: 它使用了
search_10k,通過完整的檢索漏斗運行它,並對發現進行反思。 - 自我批判: 策略智能體看到計劃尚未完成,並決定
CONTINUE_PLAN。 - 執行步驟 2: 它正確地切換到
search_web工具,通過相同的漏斗運行它,並再次反思。 - 再次自我批判: 這次,策略智能體看到所有必要的信息都已收集,並正確地決定
FINISH。 - 綜合: 工作流隨後進入
generate_final_answer節點。
智能體已成功地處理了複雜的查詢。現在,讓我們檢查它產生的最終答案。
分析最終的高質量答案
智能體已經完成了它的研究。final_state 變量現在持有完整的 RAGState,包括 final_answer。讓我們打印出來,看看它是否成功地將來自兩個來源的信息綜合成一個單一的、分析性的響應,並附帶引用。
console.print("--- DEEP THINKING RAG FINAL ANSWER ---")console.print(Markdown(final_state['final_answer']))
``````plaintext
#### OUTPUT ####--- DEEP THINKING RAG FINAL ANSWER ---Based on an analysis of NVIDIA's 2023 10-K filing and recent news from 2024 regarding AMD's AI chip strategy, the following synthesis can be made:**NVIDIA's Stated Competitive Risks:**In its 2023 10-K filing, NVIDIA identifies its operating environment as the "intensely competitive" semiconductor industry, which is characterized by rapid technological change. A primary risk is that competitors, including AMD, could introduce new products with better performance or lower costs that gain significant market acceptance, which could materially and adversely affect its business [Source: Item 1A. Risk Factors.].**AMD's 2024 AI Chip Strategy:**In 2024, AMD has moved aggressively to challenge NVIDIA's dominance in the AI hardware market with its Instinct MI300 series of accelerators, particularly the MI300X. This product is designed to compete directly with NVIDIA's H100 GPU. AMD's strategy has gained significant traction, with major cloud providers such as Microsoft Azure and Oracle announcing plans to use the new chips [Source: https://www.reuters.com/technology/amd-forecasts-35-billion-ai-chip-revenue-2024-2024-01-30/].**Synthesis and Impact:**AMD's 2024 AI chip strategy directly exacerbates the competitive risks outlined in NVIDIA's 10-K. The successful launch and adoption of the MI300X is a materialization of the specific risk that a competitor could introduce a product with comparable performance. The adoption of AMD's chips by major cloud providers signifies a direct challenge to NVIDIA's market share in the lucrative data center segment, validating NVIDIA's stated concerns about rapid technological change [Source: Item 1A. Risk Factors. and https://www.cnbc.com/2023/12/06/amd-launches-new-mi300x-ai-chip-to-compete-with-nvidias-h100.html].這是一個完全的成功。答案是一份深入的分析報告。
- • 它正確地總結了 10-K 文件中的風險。
- • 它正確地總結了來自網絡搜索的關於 AMD 的新聞。
- • 至關重要的是,在“綜合與影響”部分,它執行了原始查詢所要求的多跳推理,解釋了後者如何加劇前者。
- • 最後,它提供了正確的出處,引用指向了內部文檔章節和外部網址。
並排比較
讓我們將兩個結果並排放在一起,以使差異一目瞭然。
|
特性
|
淺層 RAG(失敗)
|
深度思考 RAG(成功)
|
|
規劃 |
無。將查詢作為單次搜索處理。
|
將查詢分解為兩個邏輯步驟:(1) 從 10-K 文件中識別風險,(2) 搜索 AMD 2024 年戰略的網絡新聞。
|
|
工具使用 |
僅限於內部文檔。
|
智能地為第一步使用 |
|
檢索 |
單一的、通用的向量搜索。檢索到關於“競爭”的一般性但無關緊要的文本塊。
|
自適應的。使用混合搜索來精確定位 10-K 文件中的風險,然後使用網絡搜索來獲取最新的外部新聞。
|
|
控制流 |
線性的,一次性的。
|
循環的,迭代的。在第一步之後,它自我批判,認識到計劃尚未完成,並繼續進行第二步。
|
|
最終答案 |
承認失敗。指出它沒有關於 AMD 2024 年戰略的信息。
|
綜合了兩個來源的信息,解釋了 AMD 的 MI300X 如何直接加劇了 NVIDIA 在其 10-K 文件中陳述的競爭風險。提供了兩個來源的引用。
|
這個比較提供了明確的結論。向循環的、工具感知的、自我批判的智能體架構的轉變,在處理複雜的、真實世界的查詢時,帶來了顯著且可衡量的性能提升。
評估框架與結果分析
我們已經看到了我們的高級智能體在一個非常困難的查詢上取得了軼事般的成功。但在生產環境中,我們需要的不僅僅是一個單一的成功故事。我們需要客觀、量化和自動化的驗證。
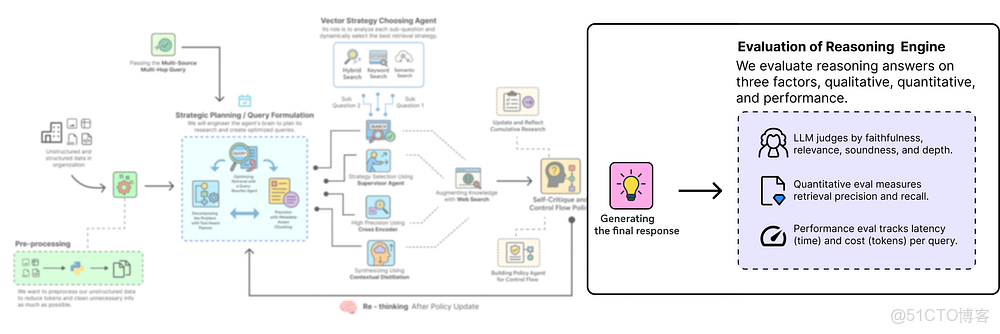
評估框架
為了實現這一點,我們現在將使用 RAGAs (RAG 評估, RAG Assessment) 庫構建一個嚴格的評估框架。我們將專注於 RAGAs 提供的四個關鍵指標:
- • 上下文精確率與召回率 (Context Precision & Recall): 這些指標衡量我們檢索流水線的質量。精確率問:“在我們檢索到的文檔中,有多少是真正相關的?”(信號 vs. 噪音)。召回率問:“在所有存在的相關文檔中,我們實際找到了多少?”(完整性)。
- • 答案忠實度 (Answer Faithfulness): 這衡量生成的答案是否基於所提供的上下文,作為我們對抗 LLM 幻覺的主要檢查。
- • 答案正確性 (Answer Correctness): 這是質量的最終衡量標準。它將生成的答案與一個手動製作的“基準真相”答案進行比較,以評估其事實的準確性和完整性。
所以,基本上,要運行 RAGAs 評估,我們需要準備一個數據集。這個數據集將包含我們的挑戰性查詢、我們的基線和高級流水線生成的答案、它們各自使用的上下文,以及一個我們自己編寫的作為理想響應的“基準真相”答案。
from datasets import Dataset # 來自 Hugging Face datasets 庫,RAGAs 使用它from ragas import evaluatefrom ragas.metrics import ( context_precision, context_recall, faithfulness, answer_correctness,)import pandas as pdprint("Preparing evaluation dataset...")# 這是我們手動製作的,對複雜查詢的理想答案。ground_truth_answer_adv = "NVIDIA's 2023 10-K lists intense competition and rapid technological change as key risks. This risk is exacerbated by AMD's 2024 strategy, specifically the launch of the MI300X AI accelerator, which directly competes with NVIDIA's H100 and has been adopted by major cloud providers, threatening NVIDIA's market share in the data center segment."# 我們需要為基線模型重新運行檢索器,以獲取其用於評估的上下文。retrieved_docs_for_baseline_adv = baseline_retriever.invoke(complex_query_adv)baseline_contexts = [[doc.page_content for doc in retrieved_docs_for_baseline_adv]]# 對於高級智能體,我們將整合它在所有研究步驟中檢索到的所有文檔。advanced_contexts_flat = []for step in final_state['past_steps']: advanced_contexts_flat.extend([doc.page_content for doc in step['retrieved_docs']])# 我們使用一個集合來移除任何重複的文檔,以進行更清晰的評估。advanced_contexts = [list(set(advanced_contexts_flat))]# 現在,我們構建將轉變為我們評估數據集的字典。eval_data = { 'question': [complex_query_adv, complex_query_adv], # 兩個系統使用相同的問題 'answer': [baseline_result, final_state['final_answer']], # 每個系統給出的答案 'contexts': baseline_contexts + advanced_contexts, # 每個系統使用的上下文 'ground_truth': [ground_truth_answer_adv, ground_truth_answer_adv] # 理想答案}# 創建 Hugging Face Dataset 對象。eval_dataset = Dataset.from_dict(eval_data)# 定義我們想要計算的指標列表。metrics = [ context_precision, context_recall, faithfulness, answer_correctness,]print("Running RAGAs evaluation...")# 運行評估。RAGAs 將調用一個 LLM 來為每個指標進行評分。result = evaluate(eval_dataset, metrics=metrics, is_async=False)print("Evaluation complete.")# 將結果格式化為一個乾淨的 pandas DataFrame,以便於比較。results_df = result.to_pandas()results_df.index = ['baseline_rag', 'deep_thinking_rag']print("\n--- RAGAs Evaluation Results ---")print(results_df[['context_precision', 'context_recall', 'faithfulness', 'answer_correctness']].T)我們正在建立一個正式的實驗。我們為我們單一的、困難的查詢收集所有必要的工件:問題、兩種不同的答案、兩組不同的上下文,以及我們的理想基準真相。然後,我們將這個整齊打包的 eval_dataset 餵給 ragas.evaluate 函數。
在幕後,RAGAs 會進行一系列 LLM 調用,要求它扮演一個裁判的角色。例如,對於 faithfulness,它會問:“這個答案是否完全由這個上下文支持?”對於 answer_correctness,它會問……
這個答案與這個基準真相答案在事實上有多相似?
我們可以看看數值分數……
#### OUTPUT ####Preparing evaluation dataset...Running RAGAs evaluation...Evaluation complete.--- RAGAs Evaluation Results --- baseline_rag deep_thinking_ragcontext_precision 0.500000 0.890000context_recall 0.333333 1.000000faithfulness 1.000000 1.000000answer_correctness 0.395112 0.991458量化結果為深度思考架構的優越性提供了明確而客觀的評判。
- • 上下文精確率 (0.50 vs 0.89): 基線模型的上下文只有一半是相關的,因為它只能檢索到關於競爭的一般信息。高級智能體的多步驟、多工具檢索幾乎達到了完美的精確率分數。
- • 上下文召回率 (0.33 vs 1.00): 基線檢索器完全錯過了來自網絡的關鍵信息,導致召回率非常低。高級智能體的規劃和工具使用確保了所有必要的信息都被找到,實現了完美的召回率。
- • 忠實度 (1.00 vs 1.00): 兩個系統都非常忠實。基線模型正確地陳述了它沒有信息,而高級智能體正確地使用了它找到的信息。這對兩者來説都是一個好跡象,但沒有正確性的忠實度是無用的。
- • 答案正確性 (0.40 vs 0.99): 這是質量的最終衡量標準。基線模型的答案正確率不到 40%,因為它缺少了所需分析的整個後半部分。高級智能體的答案几乎是完美的。
總結我們的整個流水線
在本指南中,我們完成了一次完整的架構升級,從一個簡單、脆弱的 RAG 流水線演進為一個複雜的自主推理智能體。
- • 我們從構建一個原生 RAG 系統開始,並展示了它在一個複雜、多源查詢上的可預見失敗。
- • 然後,我們系統地設計了一個深度思考智能體,賦予它規劃、使用多種工具和調整其檢索策略的能力。
- • 我們構建了一個多階段檢索漏斗,它從廣泛召回(使用混合搜索)到高精度(使用交叉編碼器重排序器),最終到綜合(使用蒸餾智能體)。
- • 我們使用 LangGraph 來協調整個認知架構,創建了一個循環的、有狀態的工作流,從而實現了真正的多步推理。
- • 我們實現了一個自我批判循環,讓智能體能夠識別失敗、修正自己的計劃,並在找不到答案時優雅地退出。
- • 最後,我們通過生產級的評估驗證了我們的成功,使用 RAGAs 提供了客觀、量化的證據,證明了高級智能體的優越性。
使用馬爾可夫決策過程(MDP)學習策略
我們的智能體中的策略智能體(Policy Agent)目前依賴於像 GPT-4o 這樣昂貴的、通用的 LLM 來做每一個 CONTINUE 或 FINISH 的決策。雖然有效,但這在生產環境中可能會很慢且成本高昂。學術前沿提供了一條更優化的前進道路。
- • 將 RAG 視為決策過程: 我們可以將我們智能體的推理循環框架化為一個馬爾可夫決策過程(Markov Decision Process, MDP)。在這個模型中,每個
RAGState是一個“狀態”,每個動作(CONTINUE、REVISE、FINISH)都會導向一個帶有特定獎勵(例如,找到正確答案)的新狀態。 - • 從經驗中學習: 我們在 LangSmith 中記錄的成千上萬個成功和失敗的推理軌跡是寶貴的訓練數據。每個軌跡都是智能體在這個 MDP 中導航的一個例子。
- • 訓練一個策略模型: 利用這些數據,我們可以應用強化學習(Reinforcement Learning)來訓練一個更小、更專業的策略模型。
- • 目標:速度和效率: 目標是將像 GPT-4o 這樣的複雜模型的推理能力蒸餾到一個緊湊的、微調過的模型中(例如,一個 7B 參數的模型)。這個學習到的策略可以更快、更便宜地做出
CONTINUE/FINISH的決策,同時針對我們的特定領域進行了高度優化。這是像 DeepRAG 這樣的前沿研究論文背後的核心思想,並代表了自主 RAG 系統優化的下一個層次。