
目錄
一、基本概念與特性
1.1 基本概念
1.2、核心特徵(“獨立”和“共享”)
二、線程的優點
三、線程異常
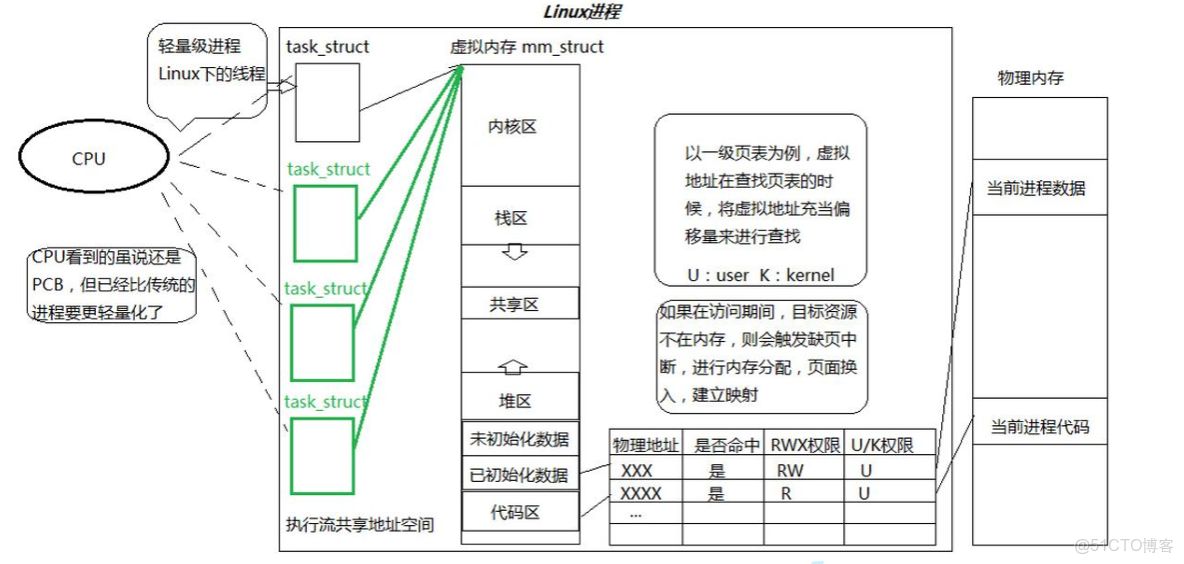
四、線程的本質:輕量化進程
4.1 什麼是輕量化進程
3.2 核心特性
3.3 實現原理
3.4 線程與“輕量化進程”
五、POSIX線程庫
5.1 線程管理接口
5.2 創建多線程
六、線程ID與進程地址空間佈局
七、線程封裝
一、基本概念與特性
1.1 基本概念
在 Linux 操作系統中,線程(Thread) 是進程(Process)內的一個獨立執行單元,是操作系統進行任務調度和資源分配的基本單位之一。它與進程共享大部分資源(如內存空間、文件描述符等),同時又能獨立執行代碼,是實現 “併發執行” 的核心技術之一。

理解線程時我們需要注意以下幾點:
- 一個進程必須至少有一個線程執行流
- 線程在進程中運行,準確來講是在進程地址空間中運行
1.2、核心特徵(“獨立”和“共享”)
線程的核心特點可以概括為 “共享進程資源,獨立執行邏輯”。
1. 線程與所屬進程所屬進程的其他線程共享大部分資源,無需額外複製
- 虛擬地址空間:共享進程的代碼段、數據段、堆,線程間訪問內存無需通過 IPC(進程間通信),直接讀寫即可。
- 文件描述符表:共享進程打開的所有文件、網絡連接、管道等(如一個進程打開一個 socket,其下所有線程都能使用該 socket 收發數據)。
- 進程級屬性:如進程 ID(PID)、用户 ID(UID)、組 ID(GID)、信號處理器(Signal Handler)、工作目錄等。
- 其他資源:如共享內存段、消息隊列、信號量等進程級 IPC 資源。
這裏需要注意的是線程作為進程內部的執行流對同一個進程的虛擬地址空間是共享的,而虛擬地址空間是資源分配的窗口,通過虛擬地址空間線程就能進行資源間的共享。
2.線程獨立擁有的資源:
為了實現 “獨立執行”,每個線程必須有自己的專屬上下文,避免與其他線程的執行邏輯衝突:
- 線程 ID(TID):Linux 內核中每個線程都有唯一的 TID(不同於進程的 PID),用於內核識別和調度。
- 寄存器集合:存儲線程執行時的臨時數據(如 CPU 寄存器中的值),切換線程時需保存 / 恢復這部分數據。
- 棧空間(Stack):每個線程有獨立的用户棧(默認大小通常為 8MB,可通過
ulimit -s查看 / 修改),用於存儲局部變量、函數調用棧幀(避免多線程棧數據混亂)。 - 信號掩碼(Signal Mask):線程可獨立屏蔽部分信號(如線程 A 屏蔽 SIGINT,不影響線程 B 接收該信號)。
關鍵點:線程具有自己的上下文和獨立的棧空間
二、線程的優點
1.創建一個新線程的代價遠小於創建一個新進程
理解這一點的關鍵在於理解線程的複用機制,線程作為進程內的執行單元,會直接複用所屬進程的大部分資源,包括:
- 共享進程的虛擬內存空間(代碼、數據、堆),無需重新分配。
- 共享進程的文件描述符、信號處理方式等。
- 僅需新增少量私有資源,如線程控制塊(TCB)、獨立的棧空間(用於函數調用),資源開銷極低。
而創建一個新進程時操作系統會必須為其分配一整套獨立資源,包括但不限於:
- 獨立的虛擬內存空間(代碼段、數據段、堆、棧)。
- 獨立的文件描述符表、信號處理表、進程控制塊(PCB)。
- 這些資源的分配和初始化需要消耗大量 CPU 時間和內存空間。
2.與進程之間的切換相比,線程之間的切換需要操作系統做的工作要少很多
這一點可以從兩方面來理解:
- 線程本身就是進程的一部分,線程之間共享一個虛擬地址空間在切換的時候不需要更改頁表。而進程切換涉及大量的寄存器內容的切換,這就導致了大量的性能損耗。
- 線程切換不會影響CPU的緩存機制,例如TLB快表與cache緩存。但是進程切換導致頁表的切換使得TLB的內容全被刷新使得在內存映射在一段時間內變得相當低效。
線程佔用的資源要比進程少很多並且能充分利用多處理器的可並行數量,在等待慢速I/O操作結束的同時,程序可執行其他的計算任務。
三、線程異常
單個線程如果出現除零,野指針問題導致線程崩潰,進程也會隨着崩潰
線程是進程的執行分支,線程出異常,就類似進程出異常,進而觸發信號機制,終止進程,進程 終止,該進程內的所有線程也就隨即退出
四、線程的本質:輕量化進程
4.1 什麼是輕量化進程
在Linux內核中並不存在“線程”的概念,只有輕量化進程。輕量化進程( LWP) 是內核級線程的實現方式,本質上是一種由內核管理的、共享部分資源的執行單元。它是 Linux 對 “線程” 概念的具體實現
也就是在用户層面我們將輕量化進程叫做線程,在內核層面不存在線程這種概念或特殊的數據結構只有輕量化進程的概念。我們理解了輕量化進程的核心特點與概念我們就從底層角度“吃透了線程”。
3.2 核心特性
LWP 本質是 Linux 內核對 “線程” 的實現,其核心特性圍繞 “共享資源 + 獨立執行” 展開:
1. 同一個進程中的輕量級進程共享大部分資源:
多個 LWP 屬於同一個 “進程組”,共享以下關鍵資源:
- 地址空間:代碼段(.text)、數據段(.data/.bss)、堆(heap)由所有 LWP 共享,因此一個 LWP 修改堆內存,其他 LWP 可見;
- 文件描述符表:打開的文件、socket、管道等文件描述符(fd)由所有 LWP 共享,一個 LWP 打開的文件,其他 LWP 可通過相同 fd 操作;
- 信號處理:信號的處理方式(如忽略、捕獲、默認動作)由進程組統一配置,內核會將信號發送到 “目標 LWP”(如指定 LWP 或空閒 LWP);
- 進程環境變量:
environ變量由所有 LWP 共享,修改環境變量對整個進程組生效; - 用户 / 組權限:UID、GID 等權限信息屬於進程組,所有 LWP 權限一致
2. 擁有獨立的執行上下文
- 每個 LWP 有自己的
task_struct(PCB),包含獨立的執行相關數據,確保能獨立被內核調度: - 寄存器集合:包含通用寄存器(如 eax)、狀態寄存器,切換 LWP 時需保存 / 恢復這些寄存器;
- 內核棧:每個 LWP 有獨立的內核棧(默認 8KB),用於執行內核態代碼(如系統調用);
- 用户棧:雖然地址空間共享,但每個 LWP 有獨立的用户棧(通常在堆的下方或通過
mmap分配),用於執行用户態代碼,避免函數調用棧衝突; - PID:每個 LWP 有獨立的 PID(進程 ID),用於內核唯一標識(注意:用户態通過
getpid()獲取的是tgid,即進程組 ID,而非 LWP 的 PID)。
3. 內核級調度與多核支持
- LWP 是 Linux 內核調度的基本單位(即 “調度實體”):
- 內核會將每個 LWP 視為獨立的 “可調度單元”,根據調度策略分配 CPU 時間片;
- 多個 LWP 可同時在不同 CPU 核心上執行(並行),充分利用多核資源
- 當一個 LWP 因 I/O 阻塞(如
read、sleep)時,內核會調度其他 LWP 執行,不會導致整個進程組阻塞(這是 LWP 相比傳統進程的核心優勢)。
3.3 實現原理
與其他操作系統不同的是,Linux操作系統在設計輕量化進程的時候主要參考了進程的設計思想,這樣的好處是代碼複用可以大大減少開發設計週期,還能保證操作系統的協調性。
Linux 內核通過 task_struct(PCB)的兩個關鍵字段實現 LWP 與進程的區分:
tgid:標識 LWP 所屬的 “進程組”。對於傳統進程,tgid等於自身的pid;對於 LWP,多個 LWP 的tgid相同(指向進程組的 “領頭進程” PID)。mm:指向進程的地址空間描述符。傳統進程的mm是獨立的;多個 LWP 共享同一個mm,因此共享地址空間。
因為輕量化進程是線程操作系統中的底層實現,所以操作系統不提供“線程”的系統調用而是隻提供輕量化進程的系統調用,比如clone()表示創建一個輕量化進程,當我們執行clone()系統調用是,操作系統會執行以下操作:
- 複製一個新的
task_struct(但比fork()輕量化,因為不復制mm、文件描述符表等資源); - 將新
task_struct的tgid設置為父 LWP 的tgid(加入同一進程組); - 將新
task_struct的mm指向父 LWP 的mm(共享地址空間),並將mm的引用計數加 1; - 為新 LWP 分配獨立的內核棧和用户棧;
- 將新 LWP 加入內核調度隊列,等待被調度執行。
3.4 線程與“輕量化進程”
Linux操作系統只提供輕量化進程的系統調用,那麼我們對線程進行一系列控制操作該使用什麼接口呢,難道用的是輕量化進程的系統調用嗎?答案是:是也不是
我們所講的線程準確來説應該是“用户級線程”,而輕量化進程的系統調用更加觸及內核而且涉及到的系統調用大多比較複雜,比如clone() 需要傳入一系列標誌位(如 CLONE_VM 共享地址空間、CLONE_FILES 共享文件描述符等)來控制資源共享範圍,普通用户很難正確設置這些標誌。同時,Linux操作系統提供的系統調用並不能完全覆蓋線程控制的各個接口,比如線程同步( mutex、條件變量)、線程屬性(優先級、棧大小)、線程銷燬等功能內核無法提供相關接口。
為了解決這些問題,Linux系統將輕量化進程提供語言庫的封裝來實現“用户級線程”,這個庫就是Linux 的 pthread 庫(POSIX 線程庫)。pthread庫提供標準化、易用的線程接口,屏蔽內核細節,同時補充同步、生命週期管理等核心功能,讓開發者能輕鬆編寫可移植的多線程程序。
五、POSIX線程庫
5.1 線程管理接口
1. pthread_create(創建線程)
int pthread_create(
pthread_t *restrict thread, // 輸出參數:新線程的ID(唯一標識)
const pthread_attr_t *restrict attr, // 輸入參數:線程屬性(NULL表示默認屬性)
void *(*start_routine)(void *), // 輸入參數:線程入口函數(函數指針)
void *restrict arg // 輸入參數:傳給入口函數的參數
);返回值:
- 成功:
0 - 失敗:非 0 錯誤碼(如
EAGAIN資源不足、EINVAL屬性無效)
#include <pthread.h>
#include<iostream>
#include <cstdio>
#include<unistd.h>
void Showid(pthread_t tid)
{
printf("tid: %ld\n",tid);
}
// 線程入口函數:接收一個整數參數並打印
void *print_num(void *arg) {
std::string name=static_cast<const char*>(arg);// 解析參數
int cnt=5;
while(cnt)
{
std::cout<<"我是一個新線程,我的名字是:"<<name<<std::endl;
sleep(1);
cnt--;
}
return NULL;
}
int main() {
pthread_t tid; // 用於存儲新線程ID
int ret;
// 創建線程:使用默認屬性,入口函數為print_num,參數為&arg
ret = pthread_create(&tid, NULL, print_num, (void*)"thread-1");
id_t pid = getpid(); // 獲取當前進程PID
printf("當前進程的PID是:%d\n", pid);
Showid(tid);
if (ret != 0) {
printf("pthread_create failed: %d\n", ret); // 錯誤處理
return 1;
}
pthread_join(tid, NULL); // 等待線程結束
return 0;
}thread參數會被填充新線程的 ID,後續可用pthread_join等函數操作該線程。arg是傳給線程的參數,若傳遞多個參數需用結構體封裝。
此時我們執行如下命令查詢進程code:
ps axj | head -1 && ps axj |grep code
然後我們查詢
ps -aL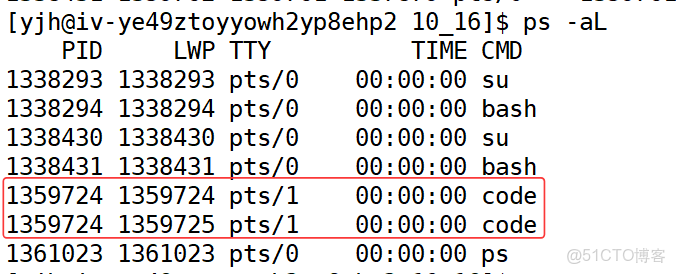
這裏的兩個code的PID相同表示兩個線程同屬於code進程,LWP小的表示主線程另一個表示我們創建的新線程,主線程的LWP與PID相同。這裏我們就會發現創建的線程的打印的tid(140331056272960)與自己的LWP(1359725)並不相同。
怎麼理解這個“tid”呢?這個“tid”是pthread庫給每個線程定義的進程內唯⼀標識,是pthread庫維持的。 由於每個進程有自己獨立的內存空間,故此“tid”的作用域是進程級而非系統級(內核不認識)。LWP是什麼呢?LWP得到的才是內核中真正的線程ID。
我們前面説過在Linux系統中線程由底層的輕量級進程模擬,所以線程又叫用户級線程。在一般情況下輕量級進程的相關概念並不會向用户暴漏,核心原因是操作系統通過抽象層隱藏了底層線程實現細節,讓用户無需關注內核級線程管理,只需聚焦上層業務邏輯,大大降低了編程難度。
2. pthread_join(等待線程結束)
int pthread_join(
pthread_t thread, // 輸入參數:目標線程ID(由pthread_create返回)
void **retval // 輸出參數:接收線程的返回值(pthread_exit的參數)
);- 成功:
0 - 失敗:非 0 錯誤碼(如
EINVAL線程不可 join、ESRCH線程不存在)
#include <pthread.h>
#include <stdio.h>
void *return_value(void *arg) {
static int result = 456; // 用static避免棧內存釋放
return &result; // 線程返回值
}
int main() {
pthread_t tid;
void *ret; // 用於接收線程返回值
int ret_code;
pthread_create(&tid, NULL, return_value, NULL);
ret_code = pthread_join(tid, &ret); // 阻塞等待線程結束
if (ret_code != 0) {
printf("pthread_join failed: %d\n", ret_code);
return 1;
}
printf("Thread returned: %d\n", *(int*)ret); // 打印返回值456
return 0;
}這裏需要注意的是,在進程join的時候並沒有異常相關的字段。這時因為,要是進程出異常main線程相應就會退出,所以討論線程異常沒有意義。
3. pthread_detach(設置線程為分離態)
線程默認都是需要等待的如果主線程不再關心新線程的返回情況,想讓新線程結束的時候自動回收相應資源就將新線程設置為分離狀態。
設置的方式主要有兩種:一種是主動分離,二是被動分離
主動分離是指新線程在內部通過調用接口將自己設置為分離狀態,而被動分離通常是指主線程將其他線程設置為分離狀態。
int pthread_detach(pthread_t thread); // 輸入參數:目標線程ID功能:將其他線程thread設置為分離狀態或將自己設置為分離狀態
- 成功:
0 - 失敗:非 0 錯誤碼(如
ESRCH線程不存在
被動分離:
#include <pthread.h>
#include <stdio.h>
void *detached_thread(void *arg) {
printf("This is a detached thread\n");
return NULL;
}
int main() {
pthread_t tid;
int ret;
pthread_create(&tid, NULL, detached_thread, NULL);
ret = pthread_detach(tid); // 將tid設置為分離態
if (ret != 0) {
printf("pthread_detach failed: %d\n", ret);
return 1;
}
// 分離態線程無需pthread_join,主線程可直接退出
return 0;
}主動分離:
#include <pthread.h>
#include <stdio.h>
void *detached_thread(void *arg) {
printf("This is a detached thread\n");
ret = pthread_detach(pthread_salf()); // 將自己設置為分離態
if (ret != 0) {
printf("pthread_detach failed: %d\n", ret);
return 1;
}
return NULL;
}
int main() {
pthread_t tid;
int ret;
pthread_create(&tid, NULL, detached_thread, NULL);
// 分離態線程無需pthread_join,主線程可直接退出
return 0;
}分離態線程結束後自動釋放資源,無需調用pthread_join,否則會報錯。
4.pthread_exit&pthread_cancel(線程終止)
在一般情況下,當我們通過pthread_create創建新線程後會通過函數中return來説明函數調用結束,線程終止。但是我們也可以通過POSIX庫中的接口來主動終止本線程或者某一線程。
pthread_exit是線程主動終止自身執行的函數,常用於線程完成任務後正常退出。
#include <pthread.h>
void pthread_exit(void *retval);- 參數:
retval是線程的退出狀態(返回值),類型為void*,可被其他線程通過pthread_join獲取。 - 返回值:無返回值(線程調用後直接終止)。
關鍵注意事項
retval的有效性:retval不能指向線程的局部變量(線程退出後局部變量會被釋放),通常使用全局變量、動態分配內存或NULL。- 與
return的區別:在線程函數中return相當於隱式調用pthread_exit(返回值作為retval),但在子函數中return僅退出子函數,不終止線程;而pthread_exit無論在何處調用,都會直接終止當前線程。 - 分離線程的
retval:若線程被標記為 “分離態”,retval會被忽略(無法通過pthread_join獲取)。
代碼實例:
#include <stdio.h>
#include <pthread.h>
void *thread_func(void *arg) {
int result = 100; // 局部變量(注意:此處僅示例,實際不應返回局部變量地址)
printf("子線程執行完畢,準備退出\n");
pthread_exit((void*)&result); // 主動退出,返回狀態
}
int main() {
pthread_t tid;
pthread_create(&tid, NULL, thread_func, NULL);
void *retval;
pthread_join(tid, &retval); // 獲取子線程退出狀態
printf("子線程返回值:%d\n", *(int*)retval); // 輸出:100
return 0;
}pthread_cancel用於一個線程請求終止另一個線程(被動取消),但目標線程是否響應、何時響應,取決於其自身的 “取消設置”,默認為允許取消。
#include <pthread.h>
int pthread_cancel(pthread_t thread);- 參數:
thread是目標線程的 ID(pthread_t類型)。 - 返回值:成功返回
0;失敗返回非 0 錯誤碼(如ESRCH表示目標線程不存在)。
如果線程被取消,返回值默認為-1(PTHREAD_CANCELED)。
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
void *thread_func(void *arg) {
printf("子線程啓動,允許取消(延遲模式)\n");
// 延遲取消(默認),會在sleep(取消點)響應取消請求
sleep(10); // 若被取消,此處不會執行完10秒
printf("子線程正常結束(不會執行)\n");
return NULL;
}
int main() {
pthread_t tid;
pthread_create(&tid, NULL, thread_func, NULL);
sleep(2); // 等待2秒後取消子線程
printf("主線程發送取消請求\n");
pthread_cancel(tid);
void *retval;
pthread_join(tid, &retval);
if (retval == PTHREAD_CANCELED) {
printf("子線程被取消\n"); // 輸出:子線程被取消
}
return 0;
}5.2 創建多線程
在這一小節我們試着創建多線程,代碼如下:
void* routine(void* args)
{
char* name=static_cast<char*>(args);
int cnt=5;
std::cout<<"我是一個新線程,我的名字是:"<<name<<std::endl;
sleep(5);
return nullptr;
}
int main()
{
std::vector<pthread_t> arr;
int num=10;
for(int i=0;i<num;i++)
{
pthread_t tid;
char name[64];
snprintf(name,sizeof(name),"thread-%d",i);
int ret=pthread_create(&tid,nullptr,routine,name);
if(ret!=0)
{
std::cout<<"pthread_create fail!"<<std::endl;
exit(-1);
}
arr.push_back(tid);
}
for(int i=0;i<10;i++)
{
pthread_join(arr[i],nullptr);
}
return 0;
}運行代碼後我們執行查詢操作:
ps -aL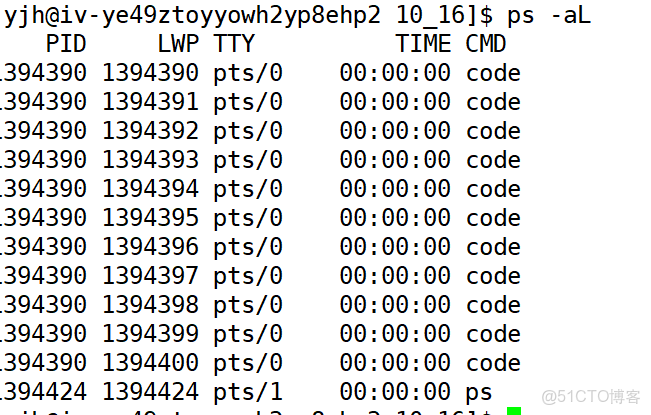
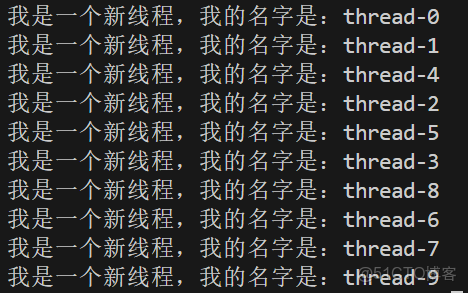
此時我們一共創建了10個新線程,算上主線程一共11個線程。上面代碼的運行結果如下:

此時我們可以發現一個問題那就是每個線程的名字並沒有按照我們的設想thread-0,thread-1,thread-2......thread-9按順序分配起來,這時因為在代碼中傳遞給線程的名字是主線程棧上的局部變量,棧上的局部變量的地址通常是相同的且被循環重複修改,導致線程讀取時數據已被覆蓋。
解決方法就是要讓每個線程拿到獨立且持久的名字,需避免 “共享棧上的臨時變量”,我們可以為每個線程在堆上動態分配一塊內存空間用來存儲線程名字,此時雖然內存空間對所有線程是可見的但是隻有本線程才能拿到自己的內存地址。這樣就避免了多線程訪問公共資源導致的線程安全的問題。
void* routine(void* args)
{
char* name=static_cast<char*>(args);
std::cout<<"我是一個新線程,我的名字是:"<<name<<std::endl;
free(args);
sleep(10);
return nullptr;
}
int main()
{
std::vector<pthread_t> arr;
int num=10;
for(int i=0;i<num;i++)
{
pthread_t tid;
char* name=(char*)malloc(64);
snprintf(name,64,"thread-%d",i);
int ret=pthread_create(&tid,nullptr,routine,name);
if(ret!=0)
{
std::cout<<"pthread_create fail!"<<std::endl;
exit(-1);
}
arr.push_back(tid);
}
for(int i=0;i<10;i++)
{
pthread_join(arr[i],nullptr);
}
return 0;
}運行結果:
六、線程ID與進程地址空間佈局
在Linux系統中,實際上並不存在獨立的線程概念,而是通過輕量級進程來實現線程功能。系統僅提供輕量級進程的相關接口,如vfork、clone等。需要注意的是,我們通常所説的"線程"實際上是由輕量級進程模擬實現的。具體來説,POSIX線程庫通過封裝輕量級進程的接口和概念,為開發者提供了一套完整的線程操作函數和抽象概念
我們注意到POSIX線程庫並未向用户暴露輕量級進程的概念。例如,通過查詢新線程的tid和LWP可以看到兩者並不一致。這是因為LWP是Linux系統的內部概念,而tid則是POSIX線程庫封裝後的標識符。這種設計隱藏了底層線程的實現細節,使開發者無需關心內核級線程管理,能夠專注於業務邏輯開發,從而顯著降低了編程複雜度。
在這一小節,我們將討論一下POSIX線程庫中tid的底層細節,以及POSIX線程庫在進程地址空間中與用户代碼和數據的交互與鏈接:
當我們編譯與POSIX線程庫有關的可執行文件時必須在編譯指令後加上-lpthread否則就會導致未定義行為。這是提前告訴動態鏈接器待編譯文件需要pthread動態庫,這時當我們編譯可執行文件時就會將pthread加載入內存,並進行動態地址鏈接與動態地址重定向。
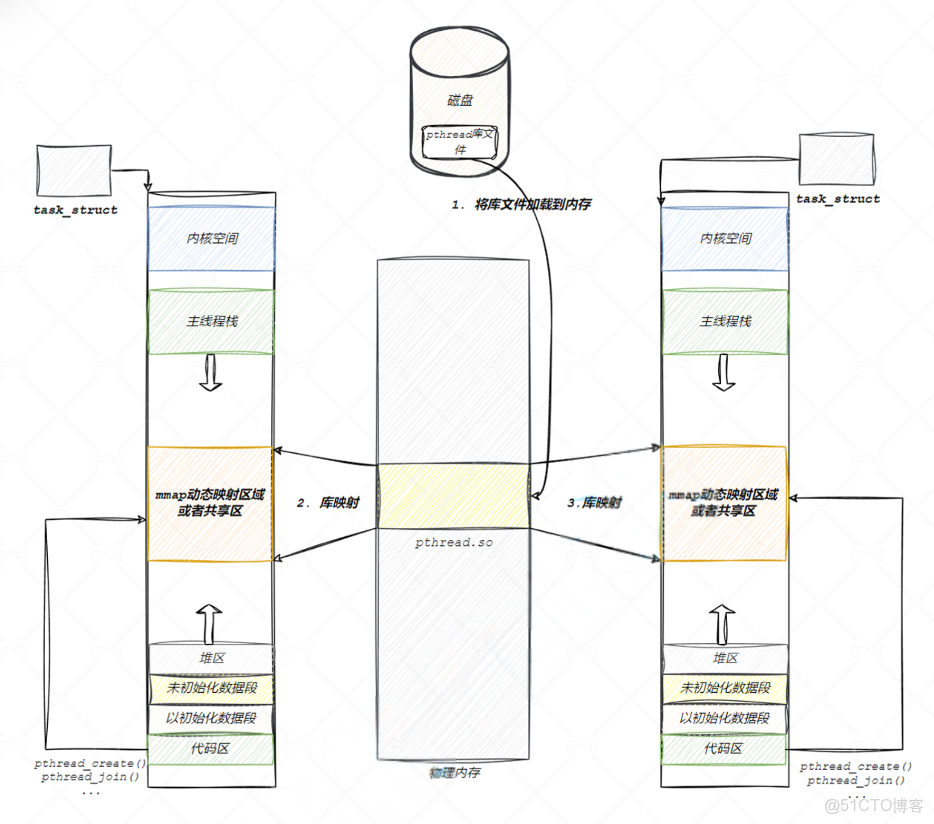
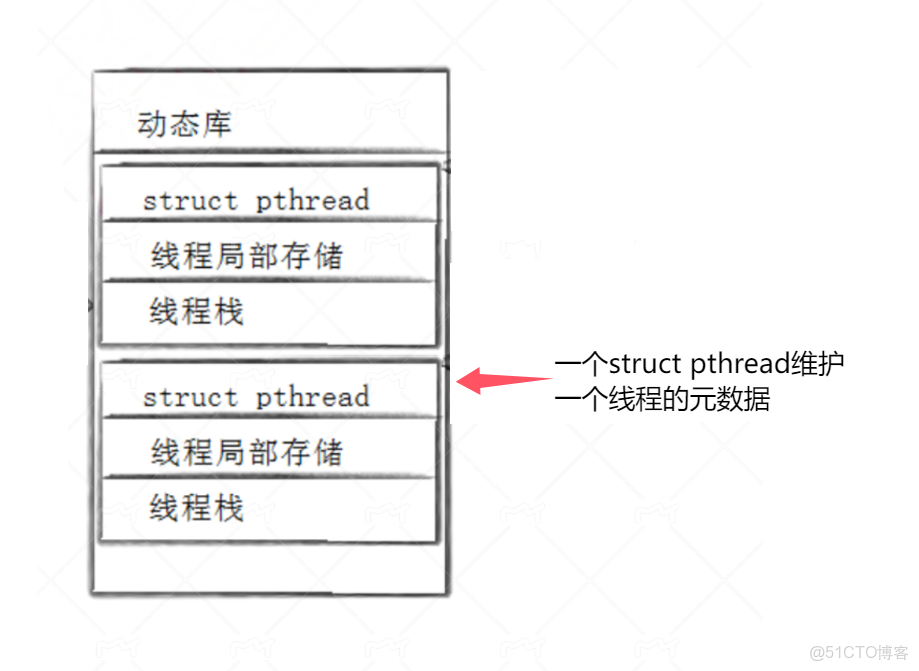
線程的大部分概念都在庫中維護,當我們創建多線程時庫中就需要維護多個線程。與系統維護進程信息類似在pthread庫中會存在一個線程控制塊TCB(通常對應struct pthread結構體)用來管理單個線程的相關元數據包含以下信息:
- 線程 ID 與進程 ID
- 線程狀態
- 內存與棧信息
- 執行上下文與狀態
- 鏈表與同步
其中線程 ID 與進程 ID包括了內核中輕量級進程的LWP,所屬進程的PID還有庫中維護的pthread_t類型的tid。從底層角度理解,這個pthread_t tid就是庫中對應線程的控制塊TCB(也就是struct pthread結構體)的起始虛擬地址,它通過這種方式標識了庫中的唯一一個線程。如圖:
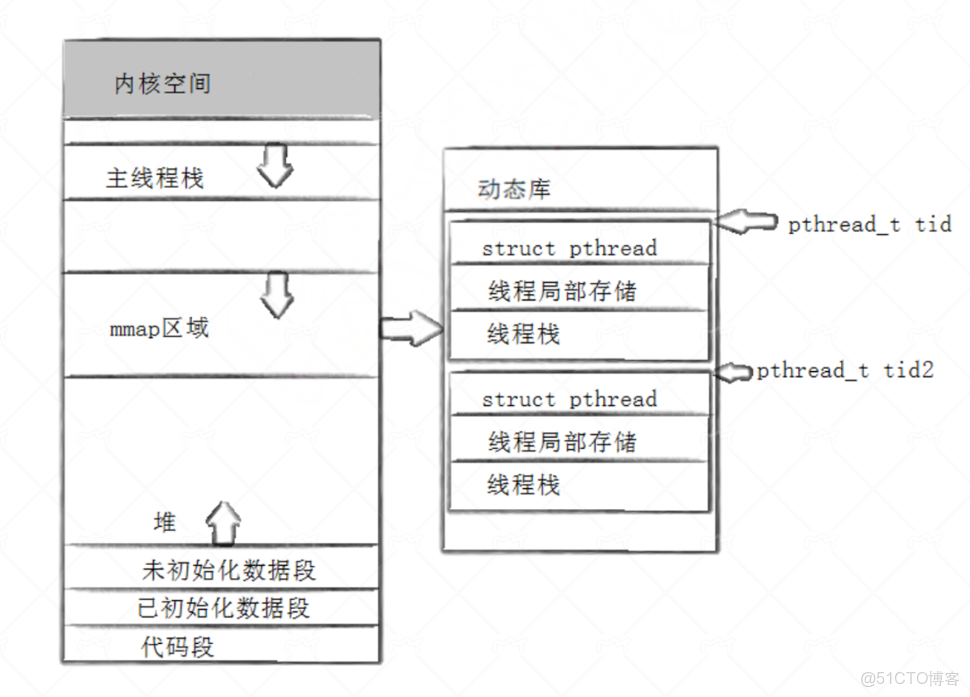
當創建的新線程退出時會將退出信息寫入線程控制塊TCB中,此時雖然線程推出了但是對應的TCB並沒有完全銷燬,此時就需要主線程調用pthread_join回收新線程的退出信息,這時傳遞給pthread_join的pthread_t類型的參數就是待回收線程的TCB的起始虛擬地址,當拿到TCB中的退出信息後就會將待回收線程的TCB徹底銷燬避免內存泄漏等問題。
前面我們説,線程是POSIX線程庫對輕量級進程再封裝後提出來的概念。我們又講線程是調度的基本單位,但是我們在POSIX線程庫的TCB中找不到關於調度相關的字段,那麼它在哪裏呢?其實當通過pthread_create創建一個新線程時除了在POSIX線程庫中創建TCB外其還會調用系統調用(如clone)創建輕量級進程PCB。
此時pthread_create會將線程需要執行的方法,以及線程的棧結構告訴輕量級進程。當輕量級進程被CPU調度執行的時候我們實現設定的方法就會被執行,相關的臨時變量就會存儲在對應的棧結構之中了。
所以用户視角看到的是POSIX線程庫中的線程概念,而真正在內核中調度的是輕量級進程。
七、線程封裝
#include <pthread.h>
#include <iostream>
#include <string>
#include <functional>
std::uint32_t cnt = 1;
using threadfunc_t = std::function<void()>;
enum class TSTATUS
{
THREAD_NEW,
THREAD_RUNNING,
THREAD_STOP
};
class Thread
{
static void* run(void* arg)
{
Thread* self=static_cast<Thread*>(arg);
pthread_setname_np(pthread_self(), self->name.c_str());
if(self->status==TSTATUS::THREAD_NEW)
{
//設置線程狀態:
self->status=TSTATUS::THREAD_RUNNING;
}
//如果設置成了分離那就調用分離函數
if(!(self->joined))
{
pthread_detach(pthread_self());
}
//調用相關函數:
self->func();
return nullptr;
}
public:
void Setname()
{
this->name="thread-"+std::to_string(cnt);
cnt++;
}
std::string Getname()
{
return name;
}
Thread(threadfunc_t rout)
: func(rout), status(TSTATUS::THREAD_NEW), joined(true)
{
Setname();
}
bool Start()
{
//一個線程不能連續運行兩次
//如果已經是運行狀態就返回
if(status==TSTATUS::THREAD_RUNNING)
{
return;
}
//靜態成員函數訪問不了非靜態成員函數所以傳this指針
int n=pthread_create(&tid,NULL,run,this);
if(n!=0)
{
std::cout<<"thread_creat fail!"<<std::endl;
return false;
}
return true;
}
void EnableDetach()
{
if(status==TSTATUS::THREAD_NEW)
joined=false;
}
void EnableJoined()
{
if(status==TSTATUS::THREAD_NEW)
joined=true;
}
bool join()
{
if(joined)
{
int n=pthread_join(tid,nullptr);
if(n>0)
return true;
else
return false;
}
return false;
}
private:
// 線程名字:
std::string name;
// 線程id
pthread_t tid;
// 線程狀態:
TSTATUS status;
// joinable
bool joined;
// 線程關聯的函數:
threadfunc_t func;
};