
一、量化
1.1、目的
大模型量化的主要目的是壓縮模型參數,降低計算複雜度,提高推理效率。
存儲優化:將高精度的浮點型參數轉換為低精度的整數參數,減少模型存儲空間。
計算加速:使用低精度整數進行計算,降低計算複雜度,提高推理速度。
硬件適配:某些硬件(如嵌入式設備、移動端芯片)對低精度計算支持更好,量化可以提高 適配性。
|
精度
|
存儲位數
|
結構
|
|
Float32 (FP32)
|
32 位
|
1位符號位,8位指數位,23位尾數位
|
|
Float16 (FP16)
|
16 位
|
1位符號位,5位指數位,10位尾數位
|
|
Bfloat16 (BF16)
|
16 位
|
1位符號位,8位指數位,7位尾數位
|
|
Int8
|
8 位
|
僅整數,無指數部分
|
|
Int4
|
4 位
|
僅整數,無指數部分
|
舉例:7B(70億參數)的大模型在不同精度下的存儲大小:
- FP16:約 14GB
- INT8:約 8GB
- INT4:約 4GB
1.2、量化分類
量化方法可以根據是否使用額外數據進行校準,分為兩大類:
在線量化 (On Quantization):使用額外的數據集進行量化,主要目的是減少精度損失, 保證模型效果。
離線量化 (Off Quantization):直接對已有的模型進行量化,可能使用少量或不使用額外 數據。
1.3、量化的優缺點
|
類別 |
優點 |
侷限性 |
|
減少存儲 |
顯著減少模型權重的存儲空間。
|
-
|
|
推理速度 |
降低計算開銷,適用於移動設備和雲端推理。
|
-
|
|
節約能耗 |
降低計算功耗,使模型適用於嵌入式設備。
|
-
|
|
精度損失 |
-
|
可能導致模型推理精度下降,尤其是大規模 LLM。
|
|
訓練開銷 |
-
|
某些量化方法需要額外的訓練或微調。
|
|
硬件支持 |
-
|
低精度計算(如 INT4、NF4)需要特定硬件支持。
|
1.4、量化的應用場景
邊緣計算:在移動設備、智能攝像頭上運行高效 AI 模型。
服務器部署:減少 GPU/TPU 顯存佔用,提高吞吐量。
模型壓縮:降低存儲需求,便於模型分發。
1.5、量化計算方式


反量化(Dequantization)主要用於將量化後的整數值恢復為浮點數,以便進行更精確的計 算,尤其是在推理過程中。
在大模型推理時,量化的參數(如 INT8 或 INT4)用於計算,以提高推理效率。但最終模型的 某些計算(如 Softmax、LayerNorm)仍然需要浮點精度,因此需要在適當的地方進行反量化。
import torch
float_tensor = torch.tensor([2.5, -3.1, 7.6, -1.2, 5.8], dtype=torch.float32)
# x_int = round(x_float / scale + zero_point)
quantized_tensor = torch.quantize_per_tensor(float_tensor, scale=0.1, zero_point=0, dtype=torch.qint8)
print("Float32:", float_tensor)
print("Int8:", quantized_tensor.int_repr())
# Float32: tensor([ 2.5000, -3.1000, 7.6000, -1.2000, 5.8000])
# Int8: tensor([ 25, -31, 76, -12, 58], dtype=torch.int8)注意: 離羣值(outliers)可能會影響 scale,導致大部分數據的量化誤差增加。 解決方案包括截斷離羣值,或者使用更復雜的分組量化方法。
import torch
import torch.nn as nn
import os
# 創建 FP16 模型
fp16_model = nn.Sequential(
nn.Linear(1280, 1280),
nn.Linear(1280, 1280)
).to(torch.float16).to(0)
# 保存 FP16 模型
torch.save(fp16_model.state_dict(), "model_fp16.pt")
# 進行動態量化
quantized_model = torch.quantization.quantize_dynamic(
fp16_model, # 原始模型
{nn.Linear}, # 需要量化的層
dtype=torch.qint8 # 量化為 INT8
)
# 保存 INT8 量化模型
torch.save(quantized_model.state_dict(), "model_int8.pt")
# 計算文件大小
size_fp16 = os.path.getsize("model_fp16.pt")
size_int8 = os.path.getsize("model_int8.pt")
print("Model: FP16\tSize (KB):", size_fp16 / 1e3)
print("Model: INT8\tSize (KB):", size_int8 / 1e3)
print("Compression Ratio: {:.2f}x".format(size_fp16 / size_int8))
'''
Model: FP16 Size (KB): 6560.872
Model: INT8 Size (KB): 3285.412
Compression Ratio: 2.00x
'''二、GPTQ量化
GPTQ:ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS(用於生成式預訓練變換器的高精度訓練後量化)
GPTQ :[2210.17323] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
GPTQ (GPT Quantization) 是一種訓練後量化 (Post-Training Quantization, PTQ) 方法,旨 在將預訓練的 Transformer 模型權重精確地量化到低精度,而無需額外的訓練數據。GPTQ 的 核心思想來源於 Optimal Brain Damage (OBD) 及其後續的優化方法。即其核心思想源自 Optimal Brain Damage (OBD),隨後經過 OBS、 OBQ等優化,最終形成 GPTQ。
OBD (剪枝) -> OBS (剪枝) -> OBQ (量化) -> GPTQ (量化)。

逐層獨立的量化(Layer-wise Independent Quantization)
GPTQ 不是一次性量化整個模型,而是逐層進行。
貪婪量化(Greedy Quantization based on Loss Minimization)
GPTQ 採用 逐個權重量化 的方式,而不是同時量化所有權重。
分組量化(Group-wise Quantization)
GPTQ 不是一個權重一個權重地量化,而是按小組(group)進行量化
int4 / fp16 混合精度量化 (W4A16)
GPTQ 採用了一種 混合精度(Mixed Precision)策略:
|
組件
|
精度
|
説明
|
|
權重(Weights) |
int4 (4-bit 整數) |
體積減少 8 倍,節省存儲和計算。
|
|
激活值(Activations) |
fp16 (16-bit 浮點數) |
保持一定的計算精度,避免信息丟失。
|
GPTQ 加速了 OBQ,減少計算複雜度,使 Transformer 量化可行,兼顧效率和精度,成為高效 的 LLM 量化方案。
# 安裝 auto-gptq 庫,用於執行 GPTQ 量化
# pip install auto-gptq
# 升級 accelerate, optimum 和 transformers 庫,確保使用最新版本以獲得最佳兼容性和功能
# pip install --upgrade accelerate optimum transformers
# 從 transformers 庫導入必要的類
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
# 指定要量化的預訓練模型的 ID (這裏是 Facebook 的 OPT-125m 模型)
model_id = "facebook/opt-125m"
# 使用 AutoTokenizer 加載與指定模型 ID 對應的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 配置 GPTQ 量化的參數
gptq_config = GPTQConfig(
bits=4, # 將模型權重進行 4 比特量化
dataset="c4", # 使用 "c4" 數據集進行量化校準
tokenizer=tokenizer # 將加載的 tokenizer 傳遞給 GPTQ 配置
) # GPTQ 量化 參數
# 使用 AutoModelForCausalLM 加載預訓練模型,並應用 GPTQ 量化
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto", # 自動將模型分配到可用的設備 (GPU 或 CPU)
quantization_config=gptq_config # 應用之前定義的 GPTQ 配置
) # 進行 量化 操作
# 保存量化後的模型到本地目錄 "opt-125m-gptq"
quantized_model.save_pretrained("opt-125m-gptq") # 保存 量化 後 的 模型
# 保存模型的 tokenizer 到相同的本地目錄
tokenizer.save_pretrained("opt-125m-gptq") # 保存 模型 字典 文件三、AWQ量化
AWQ:Activation-aware Weight Quantization for LLM Compression and Acceleration(用於 LLM 壓縮和加速的激活感知權重的量化)。
原論文地址:https://arxiv.org/pdf/2306.00978。
源碼:https://github.com/mit-han-lab/llm-awq。
AWQ發現,模型的權重並不同等重要,權重中有一小部分突出的權重(salient weights)對模型精度至關重要。只要跳過這一部分權重的量化,就可以很大程度上提高量化後的模型精度。作者發現僅保留0.1%-1%的權重通道為FP16格式,可以顯著提高量化模型的性能。這表明基於激活分佈選擇關鍵權重是有效的。
所以如何來找到這0.1%-1%的權重通道是至關重要的:


在FP16中保持較小的權重分數(0.1%-1%),在四捨五入到最近(RTN)上顯著提高了量化模型的性能。只有當我們通過觀察激活分佈而不是權重分佈來選擇 FP16 中的重要權重時,它才有效。我們用128的組大小使用INT3量化並測量了維基文本困惑度(↓)。
因此,基於激活值分佈挑選顯著權重是最為合理的方式。只要把這部分權重保持FP16精度,對其他權重進行低比特量化,就可以在保持精度幾乎不變的情況下,大幅降低模型內存佔用,並提升推理速度。
為了避免方法在實現上過於複雜,在挑選顯著權重時,並非在“元素”級別進行挑選,而是在“通道(channel)”級別進行挑選,即權重矩陣的一行作為一個單位(attention是linear層)。在計算時,首先將激活值對每一列求絕對值的平均值,然後把平均值較大的一列對應的通道視作顯著通道,保留FP16精度。對其他通道進行低比特量化,如下圖:
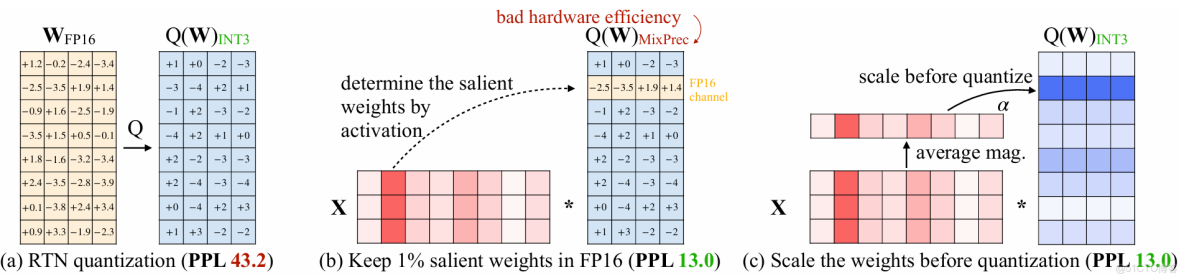
我們觀察到,我們可以在LLMs基於激活分佈(中)中找到1%的顯著權重。保持FP16中的顯著權重可以顯著提高量化性能(PPL從43.2(左)到13.0(中)),但混合精度格式的硬件效率不高。我們遵循激活意識原則並提出AWQ(右)。AWQ執行每通道縮放頂保護突出權重和減少量化誤差。我們測量OPT-6.7BunderINT3-g128量化的困惑度