
目錄
- 背景
- 模型結構
- 模型效果
- 實現代碼
- 背景
- 模型結構
- 訓練過程
- 實現代碼
前言
本文主要介紹知識蒸餾原理,並以BERT為例,介紹兩篇BERT蒸餾論文及代碼,第一篇論文是在下游任務中使用BiLSTM對BERT蒸餾,第二篇是對Transformer蒸餾,即TinyBert。
https://github.com/xiaopp123/knowledge_distillationgithub.com
知識蒸餾
https://arxiv.org/pdf/1503.02531.pdfarxiv.org
由於大模型參數量巨大,線上部署不僅對機器資源要求比較高而且推理速度慢,因此需要對模型進行壓縮加速,知識蒸餾便是模型壓縮的一種形式。
知識蒸餾(Knowledge Distillation)基於“教師-學生網絡”思想,將已經訓練好的大模型(教師)中的知識遷移到小模型(學生)訓練中。
知識蒸餾分為兩步:
- 在數據集上訓練大模型(教師)
- 在高温T下,對大模型進行蒸餾,將大模型學習到的知識遷移到小模型(學生)上
編輯切換為全寬
下面介紹知識蒸餾在分類任務中的做法:
一般分類任務處理邏輯是通過softmax層將輸出層輸出的logits轉化成概率分類,然後計算預估概率與真實標籤的交叉熵作為損失進行梯度更新。
知識蒸餾是希望讓小模型能夠學到大模型的輸出,為什麼是輸出呢?
因為真實標籤是one-hot形式表示,計算預估概率與真實標籤的交叉熵時無法學習到其他類目的知識,通過讓小模型擬合大模型的輸出,比單純擬合真實標籤能學到更多的知識。
大模型的輸出有兩種,分別是logits和經softmax層後概率,下面將分別介紹蒸餾中這兩種輸出的擬合方式。
擬合softmax
softmax層後得到的是各類目的概率分佈,由於使用指數函數會放大logits,使類目的概率差異變大,知識蒸餾時使用温度(T)對logits放縮,從而使softmax後的概率分佈不要有太大的差異,即能學到原始類目間關係。
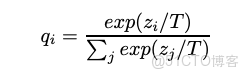
編輯
高温蒸餾的損失函數為

。

為學生網絡(Net-S)在相同高温(T)下經softmax後產出的概率分佈與教師網絡(Net-T)輸出(soft target)的交叉熵,即
")
,其中

是教師網絡輸出,
}{\textstyle\sum_{k}^n exp(v_{k}/T)}")

q_{i} 是學生網絡輸出,
}{\textstyle\sum_{k}^n exp(z_{k}/T)}")
。

")
,其中

是真實標籤。
擬合logits
與擬合softmax層相比,這種方式較簡單,最小化的目標函數是教師網絡和學生網絡輸出logits的平方差,即
^{2}")
關於温度的理解
温度影響softmax層的輸出,當T比較大時, 每個類的輸出概率會比較接近,這樣能學習到能過其他類目的信息。
温度高低代表對負標籤的關注程度,温度越高,負標籤的值相對較大,學生網絡能學習到更多負標籤信息。
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
回到頂部
背景
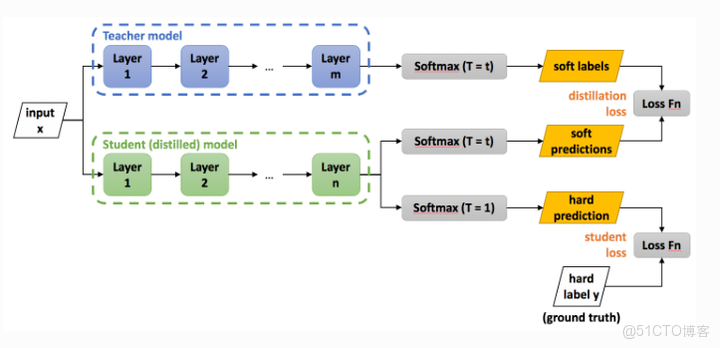
BERT模型在下游任務fine-tuning後,由於參數量巨大,計算比較耗時,很難真正上線使用,該論文提出使用簡單神經網絡(單層BiLSTM)對fine-tuned BERT進行蒸餾,蒸餾後的BiLSTM模型與ELMo效果相同,但是參數量減少100倍且推理時間減少15倍。
https://arxiv.org/pdf/1903.12136.pdfarxiv.org
回到頂部
模型結構
以在訓練集上fine-tune後的BERT模型作為teacher網絡,BiLSTM作為student網絡進行蒸餾訓練,整體訓練過程如下:
- 先用fine-tuning後的bert對訓練數據進行預估,得到bert輸出概率
- 然後使用BiLSTM網絡對訓練數據進行建模,得到BiLSTM輸出概率
- 最後計算hard loss(BiLSTM輸出概率分佈與真實標籤的交叉熵)和soft loss(BiLSTM與Bert輸出logits的均方誤差),加權作為損失
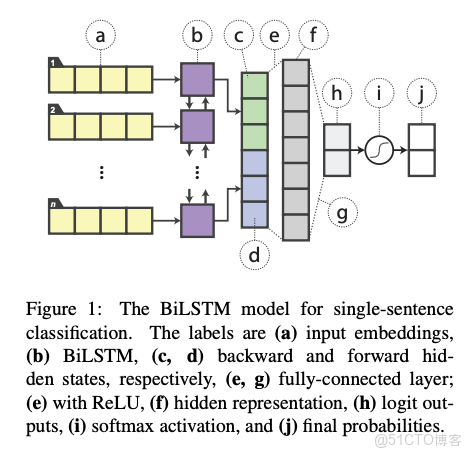
使用BiLSTM進行分類的結構如下,使用BiLSTM(b)對序列(a)進行學習,將前向(c)和後向(d)最後隱層向量拼接後連接帶有relu激活函數的全連接層(efg)得到logit輸出(h),再經softmax(i)得到概率分佈(j)。
編輯
與原始BiLSTM相比,蒸餾bert是用fine-tuned Bert對文本(a)的輸出logits與BiLSTM的學習的logits(h)做均方誤差,使Bert能將知識轉移給BiLSTM,也就是BiLSTM的輸出與bert的輸出接近,這便是teacher與student的含義。
損失函數如下:
 L_{MSE} \\ &= - \alpha \textstyle\sum_{i=1}^n t_{i}log{y_{i}^{(S)}} + (1-\alpha) ||z^{(T)}-z^{(S)}||_{2}^{2} \end{aligned}")
回到頂部
模型效果
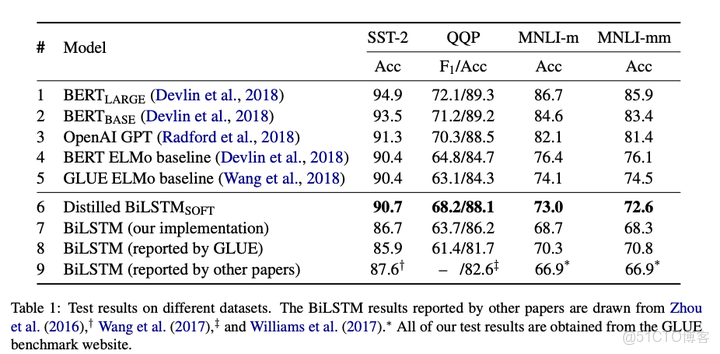
蒸餾後的BiLSTM在GLUE語料上的效果均優於普通的BiLSTM,在SST-2和QQP任務上效果與ELMo類似。
編輯切換為全寬
回到頂部
實現代碼
https://github.com/xiaopp123/knowledge_distillation
TinyBERT: Distilling BERT for Natural Language Understanding
回到頂部
背景
為提高bert的推理和計算性能,論文提出使用Transformer蒸餾方式將Bert蒸餾至TinyBert,另外,論文還提出兩階段的學習框架,即預訓練階段和fine-tuning階段都對Bert蒸餾。蒸餾後的TinyBert在GLUE任務集上能達到原始Bert的96.8%,模型大小比原來減少到7.5倍,推理性能提高到9.4倍。
回到頂部
模型結構
Transformer包含兩部分:MHA(多頭注意力層)和FFN(前饋神經網絡)。如圖所示,Transformer蒸餾方式正是基於MHA和FFN隱藏狀態進行蒸餾的。
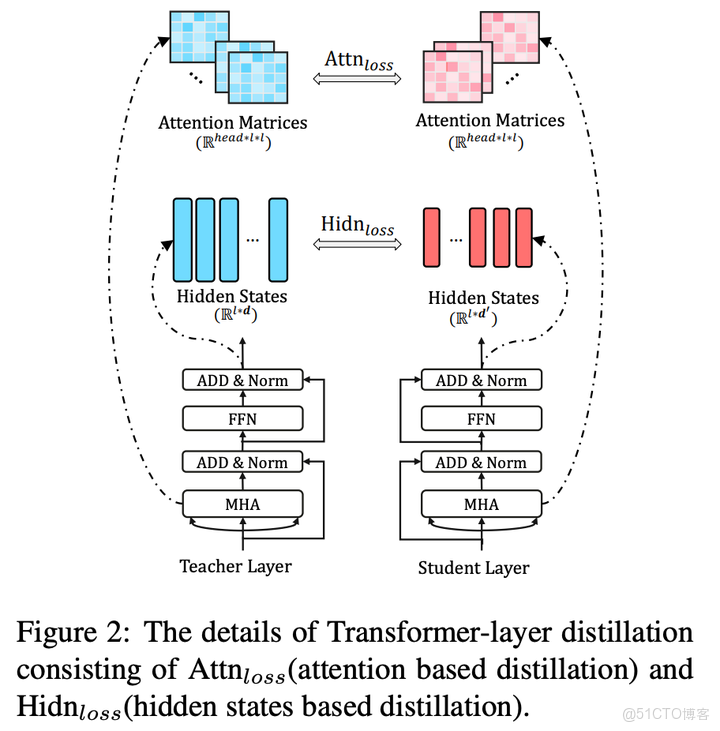
編輯切換為全寬
attention層蒸餾的損失函數如下,其中

表示head number,

表示第

i 個head的注意力矩陣,維度為

,

表示序列長度,這個損失函數的作用是使學生模型能學到教師模型中的注意力矩陣。
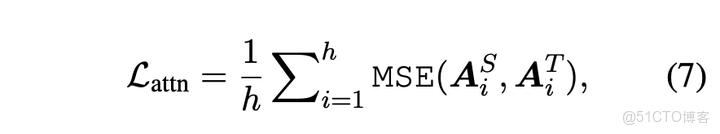
編輯切換為全寬
FNN隱藏蒸餾的損失函數如下,其中

表示教師模型FNN網絡的輸出,維度為

,

表示學生模型FNN網絡的輸出,維度為

,一般情況下,


表示映射矩陣,維度為

,即將學生網絡輸出映射到教師網絡輸出向量維度上。
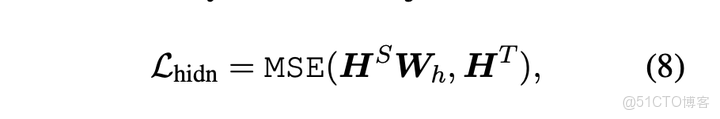
編輯切換為全寬
與FNN層蒸餾方式相同,論文對embedding層也進行蒸餾,損失函數如下所示:
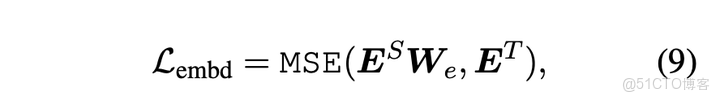
編輯切換為全寬
輸出層蒸餾
論文計算教師網絡和學生網絡輸出logits的交叉熵作為輸出層蒸餾損失函數
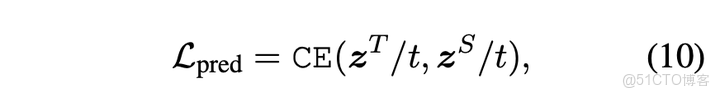
編輯切換為全寬
輸出層蒸餾損失函數
綜上,模型的蒸餾函數為:
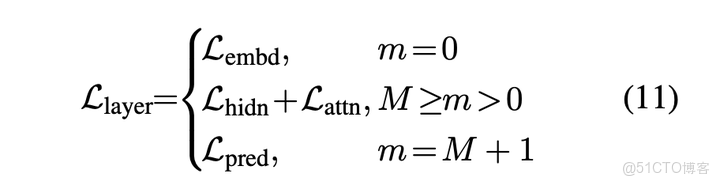
編輯切換為全寬
回到頂部
訓練過程
TinyBert學習過程分為兩步:General Distillation和Task-specific Distillation。
Generation Distillation是指預訓練階段蒸餾,這部分使用的是通用數據集故稱為General Distillation。
預訓練階段訓練的TinyBert由於參數較少,與原始Bert相比在下游任務中的效果必然有損,因此論文提出針對下游任務的Task-specific Distillation,該過程以原始Bert作為教師模型,TinyBert作為學生模型在特定數據集上進行蒸餾學習。
回到頂部
實現代碼
在下文fine-tuning任務,分兩步進行訓練,第一步是蒸餾Transformer,第二步是蒸餾下游任務輸出層
Transormer蒸餾

# Transformer蒸餾
# 教師網絡層數大於學生網絡
teacher_layer_num = len(teacher_atts)
student_layer_num = len(student_atts)
assert teacher_layer_num % student_layer_num == 0
layers_per_block = int(teacher_layer_num / student_layer_num)
# attention層蒸餾
# 學生網絡第i層學習教師網絡第i * layers_per_block + layers_per_block - 1層
# 若學生網絡是3,教師網絡為12,則第0層學習第3層,第1層學第7層
new_teacher_atts = [teacher_atts[i * layers_per_block + layers_per_block - 1]
for i in range(student_layer_num)]
for student_att, teacher_att in zip(student_atts, new_teacher_atts):
student_att = torch.where(student_att <= -1e2, torch.zeros_like(student_att).to(device),
student_att)
teacher_att = torch.where(teacher_att <= -1e2, torch.zeros_like(teacher_att).to(device),
teacher_att)
# attention層蒸餾損失為均方誤差
tmp_loss = loss_mse(student_att, teacher_att)
att_loss += tmp_loss
# 前饋神經網絡層和Embedding層蒸餾
# 學生第0層學習教師第0層,第0層是embedding層輸出
# 第i層學習第layers_per_block * i層
new_teacher_reps = [teacher_reps[i * layers_per_block] for i in range(student_layer_num + 1)]
new_student_reps = student_reps
# 前饋神經網絡層和Embedding層蒸餾均方誤差
for student_rep, teacher_rep in zip(new_student_reps, new_teacher_reps):
tmp_loss = loss_mse(student_rep, teacher_rep)
rep_loss += tmp_loss
loss = rep_loss + att_loss
輸出層蒸餾

# 輸出層蒸餾
# 分類任務是教師網絡和學生網絡輸出logits交叉熵
if output_mode == "classification":
cls_loss = soft_cross_entropy(student_logits / args.temperature,
teacher_logits / args.temperature)
elif output_mode == "regression":
loss_mse = MSELoss()
cls_loss = loss_mse(student_logits.view(-1), label_ids.view(-1))
loss = cls_loss
這裏重點講一下如何針對具體下游任務進行fine-tuning:
數據準備
這裏可以是自己的數據集,也可以是GLUE任務。
預訓練模型
需要下載Bert預訓練模型和TinyBert預訓練模型。
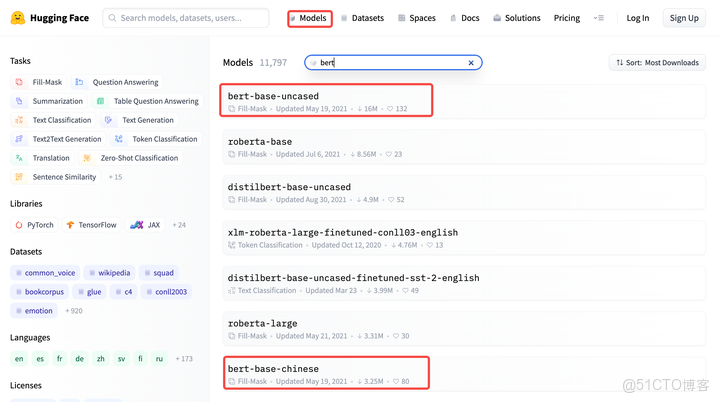
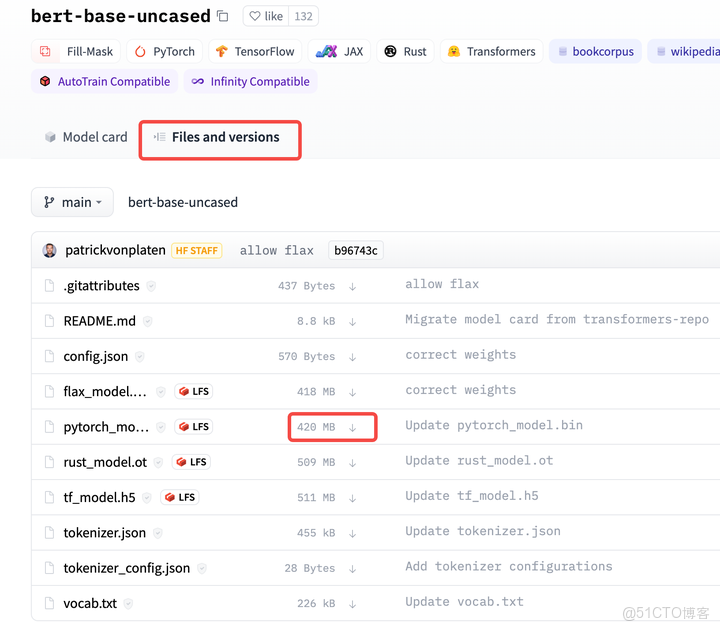
Bert預訓練模型在HuggingFace官網“Model”模塊輸入bert,找到適合自己的bert預訓練模型,在“Files and versions”選擇自己需要模型和文件下載,目前好像只能一個一個文件下載。
編輯切換為全寬
編輯切換為全寬
TinyBert預訓練模型:huawei-noah (HUAWEI Noah's Ark Lab)
Transformer蒸餾

python task_distill.py --teacher_model ${FT_BERT_BASE_DIR}$ \
--student_model ${GENERAL_TINYBERT_DIR}$ \
--data_dir ${TASK_DIR}$ \
--task_name ${TASK_NAME}$ \
--output_dir ${TMP_TINYBERT_DIR}$ \
--max_seq_length 128 \
--train_batch_size 32 \
--num_train_epochs 10 \
--aug_train \
--do_lower_case
輸出層蒸餾

python task_distill.py --pred_distill \
--teacher_model ${FT_BERT_BASE_DIR}$ \
--student_model ${TMP_TINYBERT_DIR}$ \
--data_dir ${TASK_DIR}$ \
--task_name ${TASK_NAME}$ \
--output_dir ${TINYBERT_DIR}$ \
--aug_train \
--do_lower_case \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--eval_step 100 \
--max_seq_length 128 \
--train_batch_size 32
參考
- https://github.com/airaria/TextBrewer
- https://github.com/qiangsiwei/bert_distill
- https://towardsdatascience.com/simple-tutorial-for-distilling-bert-99883894e90a