
1. 總述
Focal loss主要是為了解決one-stage目標檢測中正負樣本比例嚴重失衡的問題。該損失函數降低了大量簡單負樣本在訓練中所佔的權重,也可理解為一種困難樣本挖掘。
2. 損失函數形式
Focal loss是在交叉熵損失函數基礎上進行的修改,首先回顧二分類交叉上損失:
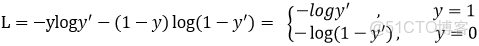
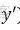
是經過激活函數的輸出,所以在0-1之間。可見普通的交叉熵對於正樣本而言,輸出概率越大損失越小。對於負樣本而言,輸出概率越小則損失越小。此時的損失函數在大量簡單樣本的迭代過程中比較緩慢且可能無法優化至最優。那麼Focal loss是怎麼改進的呢?
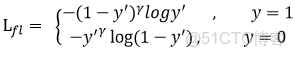
首先在原有的基礎上加了一個因子,其中gamma>0使得減少易分類樣本的損失。使得更關注於困難的、錯分的樣本。
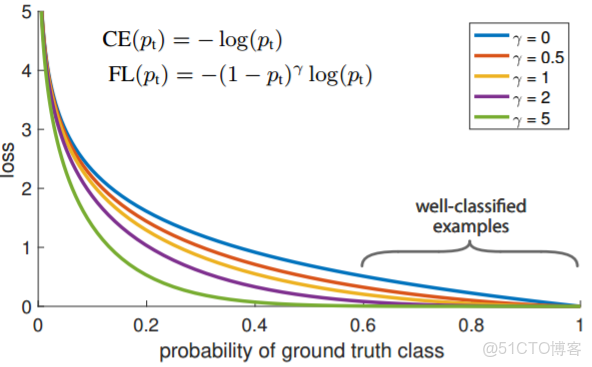
例如gamma為2,對於正類樣本而言,預測結果為0.95肯定是簡單樣本,所以(1-0.95)的gamma次方就會很小,這時損失函數值就變得更小。而預測概率為0.3的樣本其損失相對很大。對於負類樣本而言同樣,預測0.1的結果應當遠比預測0.7的樣本損失值要小得多。對於預測概率為0.5時,損失只減少了0.25倍,所以更加關注於這種難以區分的樣本。這樣減少了簡單樣本的影響,大量預測概率很小的樣本疊加起來後的效應才可能比較有效。
此外,加入平衡因子alpha,用來平衡正負樣本本身的比例不均:文中alpha取0.25,即正樣本要比負樣本佔比小,這是因為負例易分。
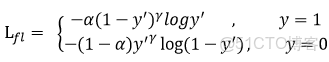
只添加alpha雖然可以平衡正負樣本的重要性,但是無法解決簡單與困難樣本的問題。
gamma調節簡單樣本權重降低的速率,當gamma為0時即為交叉熵損失函數,當gamma增加時,調整因子的影響也在增加。實驗發現gamma為2是最優。
3. 總結
作者認為one-stage和two-stage的表現差異主要原因是大量前景背景類別不平衡導致。作者設計了一個簡單密集型網絡RetinaNet來訓練在保證速度的同時達到了精度最優。在雙階段算法中,在候選框階段,通過得分和nms篩選過濾掉了大量的負樣本,然後在分類迴歸階段又固定了正負樣本比例,或者通過OHEM在線困難挖掘使得前景和背景相對平衡。而one-stage階段需要產生約100k的候選位置,雖然有類似的採樣,但是訓練仍然被大量負樣本所主導。