
步驟:
- 預加重, 高頻信號更容易衰減,預加重是個一階高通濾波器,可以提高信號高頻部分的能量
- 分幀, 語音信號短時平穩性,這個短時間一般取 10-30ms,因此在進行語音信號處理時,為減少語音信號整體的非穩態、時變的影響,從而對語音信號進行分段處理,其中每一段稱為一幀,幀長一般取 25ms。為了使幀與幀之間平滑過渡,保持其連續性,分幀一般採用交疊分段的方法,保證相鄰兩幀相互重疊一部分。相鄰兩幀的起始位置的時間差稱為幀移,我們一般在使用中幀移取值為 10ms。
- 加窗, 一般選擇漢明窗作為窗函數,它能使信號在窗邊界的值近似為 0,從而使得信號趨近於是一個週期信號.
- 快速傅里葉變換 FFT, 將每個窗口內的數據從時域信號轉為頻域信號
- 梅爾濾波器組, 從 FFT 出來的結果是每個頻帶上面的幅值,然而人類對不同頻率語音有不同的感知能力.梅爾刻度(Mel Scale,其中 Mel 取自單詞 melody)是一種非線性刻度單位,表示人耳對音高(pitch)變化的感官,基於頻率定義。在 Mel 頻域內,人的感知能力為線性關係,如果兩段語音的 Mel 頻率差兩倍,則人在感知上也差兩倍.一般是40個梅爾濾波器.
- 取log 即得到fbank
- 離散餘弦變換 DCT, 即得到mfcc
------------------------------------------------------------------------------------------------------------------------------------------------------
本文主要講述如何根據音頻信號提取 MFCC 和 FBank 特徵,這也是目前在語音識別任務中使用最廣泛的兩種特徵。
人類的語音信號的頻率大部分在 10000Hz 以下,根據奈奎斯特採樣定理,20000Hz 的採樣率就足夠了。電話傳輸的帶寬只有 4000Hz,因此電話信號的採樣率為 8000Hz,如 Switchboard 語料。我們通常使用麥克風進行音頻錄製的採樣率為 16000Hz,一個採樣點使用 16bit 來存儲。
下圖是特徵提取的整個過程,我們現在就按照這流程來講述一遍。

預加重
在音頻錄製過程中,高頻信號更容易衰減,而像元音等一些因素的發音包含了較多的高頻信號的成分,高頻信號的丟失,可能會導致音素的共振峯並不明顯,使得聲學模型對這些音素的建模能力不強。預加重是個一階高通濾波器,可以提高信號高頻部分的能量,給定時域輸入信號

,預加重之後信號為:

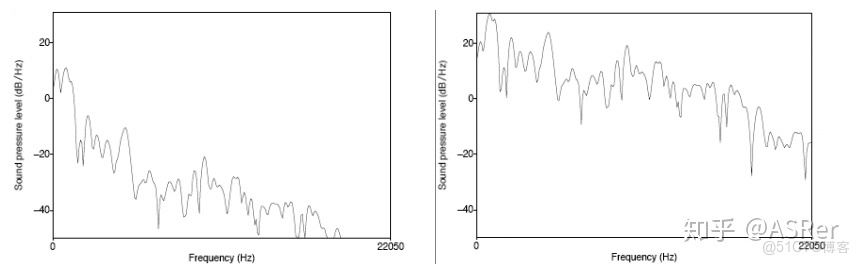
如下圖所示,元音音素 /aa/ 原始的頻譜圖(左)和經過預加重之後的頻譜圖(右)。
分幀加窗
分幀
語音信號是一個非穩態的、時變的信號。但在 短時間 範圍內可以認為語音信號是穩態的、時不變的。這個短時間一般取 10-30ms,因此在進行語音信號處理時,為減少語音信號整體的非穩態、時變的影響,從而對語音信號進行分段處理,其中每一段稱為一幀,幀長一般取 25ms。為了使幀與幀之間平滑過渡,保持其連續性,分幀一般採用交疊分段的方法,保證相鄰兩幀相互重疊一部分。相鄰兩幀的起始位置的時間差稱為幀移,我們一般在使用中幀移取值為 10ms。
對於一個 16000Hz 採樣的音頻來説,幀長有 16000 * 0.025 = 400 個點,幀移有 16000 * 0.01 = 160 個點。使用 num_samples、frame_len、frame_shift 分別代表 音頻的數據點數、幀長和幀移,那麼 i 幀的數據需要的點數為

,所以一個有 n 個點的音頻,總共能得到

幀數據。
加窗
因為後面會對信號做 FFT,而 FFT 變換的要求為:信號要麼從 -∞ 到 +∞ ,要麼為週期信號。現實世界中,不可能採集時間從 -∞ 到 +∞ 的信號,只能是有限時間長度的信號。由於分幀後的信號是非週期的,進行 FFT 變換之後會有頻率泄露的問題發生,為了將這個泄漏誤差減少到最小程度(注意我説是的減少,而不是消除),我們需要使用加權函數,也叫窗函數。加窗主要是為了使時域信號似乎更好地滿足 FFT 處理的週期性要求,減少泄漏。
如下圖所示,若週期截斷,則 FFT 頻譜為單一譜線。若為非週期截斷,則頻譜出現拖尾,如圖中部所示,可以看出泄漏很嚴重。為了減少泄漏,給信號施加一個窗函數(如圖中上部紅色曲線所示),原始截斷後的信號與這個窗函數相乘之後得到的信號為上面右側的信號。可以看出,此時,信號的起始時刻和結束時刻幅值都為0,也就是説在這個時間長度內,信號為週期信號,但是隻有一個週期。對這個信號做FFT分析,得到的頻譜如下部右側所示。相比較之前未加窗的頻譜,可以看出,泄漏已明顯改善,但並沒有完全消除。因此,窗函數只能減少泄漏,不能消除泄漏。
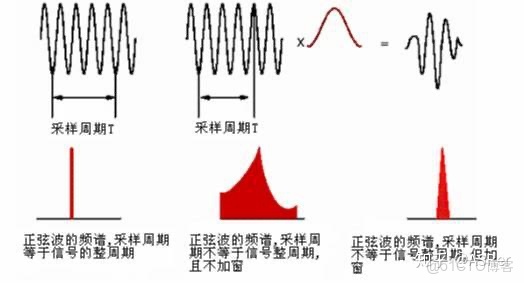
頻譜泄露就是分析結果中,出現了本來沒有的頻率分量。比如説,50Hz 的純正弦波,本來只有一種頻率分量,分析結果卻包含了與50Hz頻率相近的其它頻率分量。https://blog.csdn.net/zhaomengszu/article/details/72627750
在語音識別中,一般選擇漢明窗作為窗函數,它能使信號在窗邊界的值近似為 0,從而使得信號趨近於是一個週期信號,該窗函數如下:
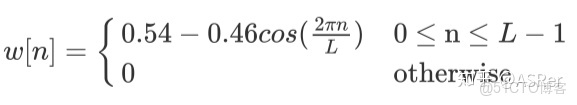
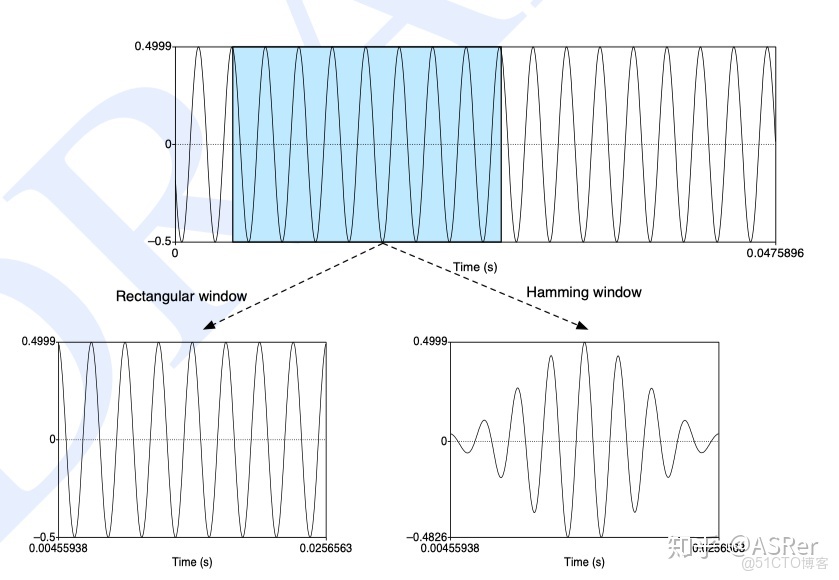
分別使用矩形窗和漢明窗作用於信號,他們的區別可以從下圖中看出來。
DFT
接下來的操作是 離散傅里葉變換(Discrete Fourier Transform,縮寫為 DFT),將每個窗口內的數據從時域信號轉為頻域信號。DFT 的變換公式如下:


是窗口中每個數據點的值,

是自然底數,

。根據歐拉公式,我們可以轉換如下的形式:

我們將復指數的形式轉換成為了實部和虛部的形式,

是 DFT 第 m 個輸出,

是輸入的時域信號。首先我們説一下分析頻率的概念。假設我們對一個頻率為 500 的信號做 16 點的 DFT 變換,那麼基礎的頻率分隔就是

,X(m) 所表示的分析頻率是 31.25 的整數倍。比如説 X(0) 的分析頻率為 0 * 31.25 = 0Hz,X(1) 的分析頻率為 1 * 31.25 = 31.25Hz,依次類推,最後的 X(15) 的分析頻率為 15 * 31.25 = 468.75Hz。N 點 DFT 的分析頻率用該公式表示

。
在上面的例子中,X(0) 表示的是時域信號中 0Hz DC(direct current) 的幅值,通常我們稱 X(0) 的值為直流分量,X(1) 表示的是時域信號中 31.25Hz 的幅值,後面的也是以此類推。
通常 X(m) 包含了兩層意思,分別是幅值(magnitude)和功率(power,中文也有成為能量的),下面我們就看看這幾個定義在複平面上面的表達。
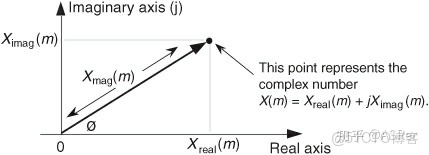
對於任意一個 DFT 的輸出

,根據它的實部和虛部,寫作如下形式:


的幅值為:


的相位角度

:


的功率,即功率譜(power spectrum),等於幅值的平方:

下面讓我們對一個包含了 1kHz 和 2kHz 的連續信號進行 8 個點的 DFT,且 2kHz 的相位角為 135°,信號表達如下:

對該連續信號使用

進行採樣,所以每個採樣點的時間間隔是

,有如下表達式:

假設我們將採樣率設置為 8000Hz,那麼這個 8 個採樣點的值如下:

下面我們計算 m = 1 這個 DFT 的輸出,

表示這個 8 個數據點在 1kHz 上面的幅值:

計算過程我是直接從《Understanding Digital Signal Processing》書中第三章導出的圖片,大家可以從這本書裏面看到更多的細節:
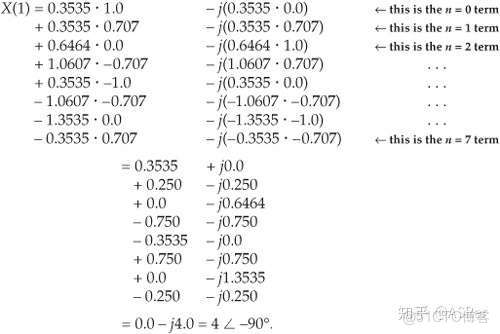
從計算結果得知,x(n) 在 1kHz 上面的幅值為 4,功率為 16,相位角度為 -90 度。下面,我將這 8 個點 DFT 的計算結果圖片列出來:
上圖中,我們主要關注圖(a),可以看到

,

等一些頻率上面的值是相等的。這個特性稱為 DFT 的對稱性,對於

,有

。由於對稱性,如果我們對信號做 512 點 DFT,只需要取前 257 個點(第一個點是直流分量)就行,在語音識別的信號中,一般也是做的 512 點 DFT,然而我們分幀後的一個窗只有 400 個點,這個時候在後面補上 112 個零數據點就行。從 DFT 的計算公式來看,DFT 的時間複雜度為

,在實際中使用的是快速傅里葉變換(Fast Fourier Transform,縮寫為 FFT),其時間複雜度是

,具體的過程大家可以查看 Understanding Digital Signal Processing 書中第四章。
梅爾濾波器組
從 FFT 出來的結果是每個頻帶上面的幅值,然而人類對不同頻率語音有不同的感知能力:對1kHz以下,與頻率成線性關係,對1kHz以上,與頻率成對數關係。頻率越高,感知能力就越差。
梅爾刻度(Mel Scale,其中 Mel 取自單詞 melody)是一種非線性刻度單位,表示人耳對音高(pitch)變化的感官,基於頻率定義。在 Mel 頻域內,人的感知能力為線性關係,如果兩段語音的 Mel 頻率差兩倍,則人在感知上也差兩倍。下圖則是頻率刻度到 Mel 刻度的轉換:
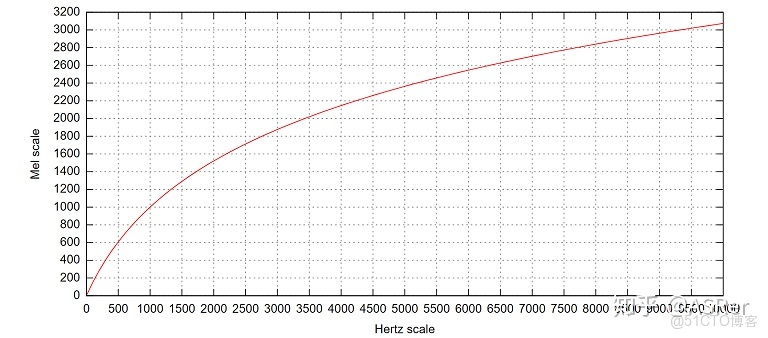
Mel 頻率與頻率 Hz 轉換的公式如下:

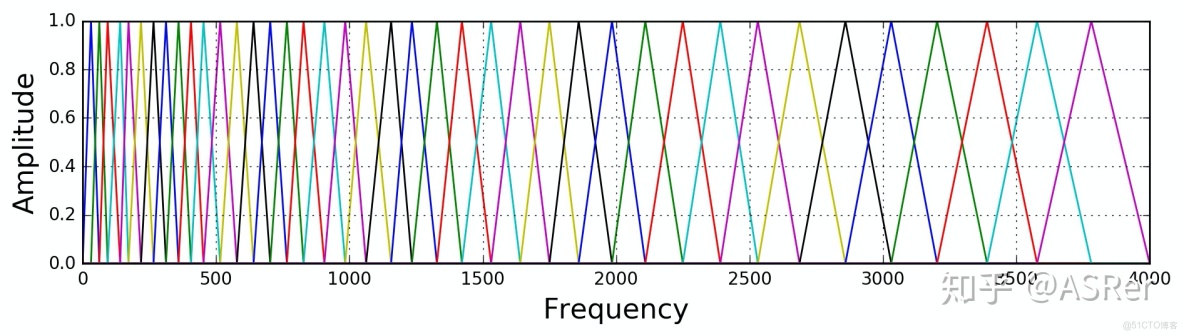
下圖是 40 個梅爾濾波器在頻率軸上面的示意圖,要注意的是,上一個濾波器的中間頻率是下一個濾波器的開始頻率(存在 overlap)。將梅爾域上每個三角濾波器的起始、中間和截止頻率轉換線性頻率域,並對 DFT 之後的譜特徵進行濾波,得到 40 個濾波器組能量,再進行 log 操作,就得到了 40 維的 Fbank(Filter Bank)特徵。
IDFT
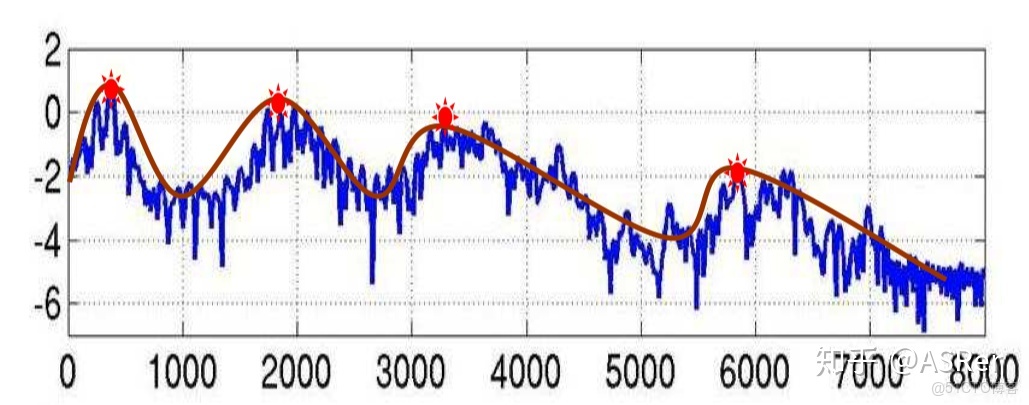
FBank 特徵的頻譜圖大概長下面這個樣子,圖中四個紅點表示的是共振峯,是頻譜圖的主要頻率,在語音識別中,根據共振峯來區分不同的音素(phone),所以我們可以把圖中紅線表示的特徵提取出來就行,移除藍色的影響部分。其中紅色平滑曲線將各個共振峯連接起來,這條紅線,稱為譜包絡(Spectral Envelope),藍色上下震盪比較多的線條稱為譜細節(Spectral details)。
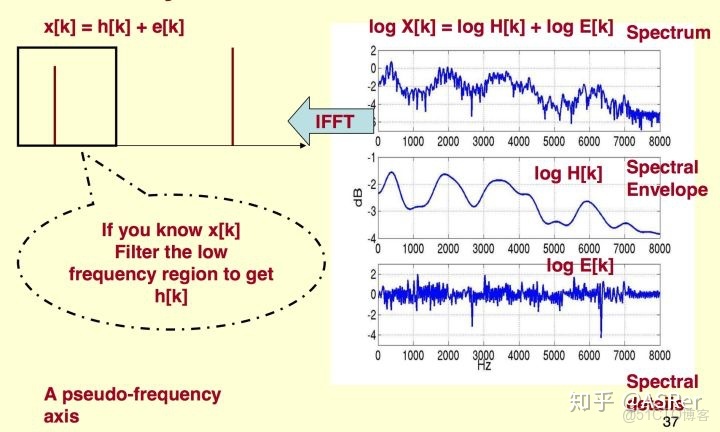
要實現上述操作,需要使用倒譜(Cepstrum)的技術,倒譜的定義是對數譜的譜(spectrum of the log of the spectrum),表示在對數譜上做 DFT,在頻譜上面做 DFT 的操作被稱為逆離散傅里葉變換(IDFT,Inverse Discrete Fourier Transform)。下面,我們闡述一下生成倒譜系數的原理和流程。
首先,人類發出的聲音可以理解為通過聲帶振動,經過腔體(包括舌頭、牙齒等等),形成各種不同的發音。其中聲帶產生的頻譜是很簡單的,主要就是腔體的形狀和體積等條件決定着各個音素的頻譜。所以如果我們知道腔體的形狀等信息,就可以準確的對音素進行描述。顯然的,腔體的形狀對應着上面圖中的譜包絡,揭示了共振峯的走向。
讓我們繼續看着這張圖,假想橫座標表示的不是頻率而是時間,可以發現紅線的頻率是比較低的,在圖裏只有 4 個 peak,而藍色的頻率則明顯高很多。如果我們對圖中的頻譜再做一次傅里葉變換,是不是就能將低頻率的譜包絡和高頻率的譜細節給分開呢?答案是肯定可以的。
在頻域上,我們假設聲帶產生振動後的信號為

,然後經過了腔體,這時候腔體可以看成一個濾波器,使用

來描述,生成的聲音信號為

,我們只關注頻譜的能量,忽略相位信息有

,接下來取對數運算

,最後作傅里葉逆變換,就可以得到倒譜系數

。需要注意的是,此處的 IDFT 變換為離散餘弦變換(DCT,Discrete Cosine Transform),由於 DCT 具有最優的去相關性的性能,所以倒譜系數之間沒有相關性。
該過程可以使用下圖來表示,對頻譜進行 IDFT 後的域稱為 quefrency domain,和時間域類似但不完全一樣。在得到頻譜的倒譜系數(x[k])後,我們只需要取低位的係數,就可以獲得頻譜的包絡信息。假設我們從 FBank 出來的特徵維度是 40 維,那麼我們得到的 MFCC(Mel-Frequency Cepstral Coefficients) 係數也是 40 維,這個時候我們再取第 1~k 個係數,輸出的就是 k 維的 MFCC。
參考
什麼是泄漏
什麼是窗函數
DFT(離散傅里葉變換)與FFT(快速傅里葉變換)初識
形象展示傅里葉變換
Topic: Spectrogram, Cepstrum and Mel-Frequency Analysis
Cepstral analysis
Understanding Digital Signal Processing 第三章和第四章
Speech and Language Processing 第九章
知乎 RegendesSommers 的回答
/home/aispeech/Pictures/feature_extract/1.jpg