
1.關鍵字提取:
關鍵詞抽取就是從文本里面把跟這篇文檔意義最相關的一些詞抽取出來。這個可以追溯到文獻檢索初期,當時還不支持全文搜索的時候,關鍵詞就可以作為搜索這篇論文的詞語。因此,目前依然可以在論文中看到關鍵詞這一項。
除了這些,關鍵詞還可以在文本聚類、分類、自動摘要等領域中有着重要的作用。比如在聚類時將關鍵詞相似的幾篇文檔看成一個團簇,可以大大提高聚類算法的收斂速度;從某天所有的新聞中提取出這些新聞的關鍵詞,就可以大致瞭解那天發生了什麼事情;或者將某段時間內幾個人的微博拼成一篇長文本,然後抽取關鍵詞就可以知道他們主要在討論什麼話題。
目前大多數領域無關的關鍵詞抽取算法(領域無關算法的意思就是無論什麼主題或者領域的文本都可以抽取關鍵詞的算法)和它對應的庫都是基於後者的。從邏輯上説,後者比前着在實際使用中更有意義。
從算法的角度來看,關鍵詞抽取算法主要有兩類:
- 有監督學習算法,將關鍵詞抽取過程視為二分類問題,先抽取出候選詞,然後對於每個候選詞劃定標籤,要麼是關鍵詞,要麼不是關鍵詞,然後訓練關鍵詞抽取分類器。當新來一篇文檔時,抽取出所有的候選詞,然後利用訓練好的關鍵詞抽取分類器,對各個候選詞進行分類,最終將標籤為關鍵詞的候選詞作為關鍵詞;
- 無監督學習算法,先抽取出候選詞,然後對各個候選詞進行打分,然後輸出topK個分值最高的候選詞作為關鍵詞。根據打分的策略不同,有不同的算法,例如TF-IDF,TextRank等算法;
2.TF-IDF算法:
TF-IDF(term frequency–inverse document frequency,詞頻-逆向文件頻率)是一種用於信息檢索(information retrieval)與文本挖掘(text mining)的常用加權技術。
TF-IDF是一種統計方法,用以評估一字詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨着它在文件中出現的次數成正比增加,但同時會隨着它在語料庫中出現的頻率成反比下降。
- TF-IDF的主要思想是:如果某個單詞在一篇文章中出現的頻率TF高,並且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類。
- TF是詞頻(Term Frequency):詞頻(TF)表示詞條(關鍵字)在文本中出現的頻率。
- 逆向文件頻率 (IDF) :某一特定詞語的IDF,可以由總文件數目除以包含該詞語的文件的數目,再將得到的商取對數得到。如果包含詞條t的文檔越少, IDF越大,則説明詞條具有很好的類別區分能力。
- TF-IDF實際上是:TF *IDF。某一特定文件內的高詞語頻率,以及該詞語在整個文件集合中的低文件頻率,可以產生出高權重的TF-IDF。因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。
- (1)計算詞頻

(2)計算逆文檔頻率
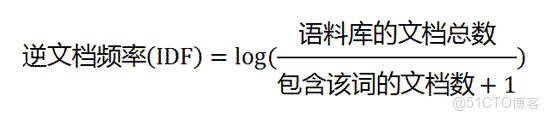
(3)計算TF-IDF
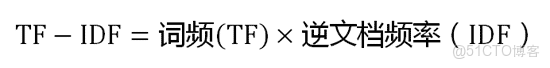
3.TextRank算法:
此種算法的一個重要特點是可以脱離語料庫的背景,僅對單篇文檔進行分析就可以提取該文檔的關鍵詞。基本思想來源於Google的PageRank算法。這種算法是1997年,Google創始人拉里.佩奇和謝爾蓋.布林在構建早期的搜索系統原型時提出的一種鏈接分析算法,基本思想有兩條:
1)鏈接數量。一個網頁被越多的其他網頁鏈接,説明這個網頁越重要.
2)鏈接質量。一個網頁被一個越高權值的網頁鏈接,也能表明這個網頁越重要.
TextRank 用於關鍵詞提取的算法如下:
(1)把給定的文本 T 按照完整句子進行分割,即:T=[S1,S2,…,Sm]
(2)對於每個句子,進行分詞和詞性標註處理,並過濾掉停用詞,只保留指定詞性的單詞,如名詞、動詞、形容詞,其中 ti,j 是保留後的候選關鍵詞。Si=[ti,1,ti,2,...,ti,n]
(3)構建候選關鍵詞圖 G = (V,E),其中 V 為節點集,由(2)生成的候選關鍵詞組成,然後採用共現關係(Co-Occurrence)構造任兩點之間的邊,兩個節點之間存在邊僅當它們對應的詞彙在長度為K 的窗口中共現,K表示窗口大小,即最多共現 K 個單詞。
(4)根據 TextRank 的公式,迭代傳播各節點的權重,直至收斂。
(5)對節點權重進行倒序排序,從而得到最重要的 T 個單詞,作為候選關鍵詞。
(6)由(5)得到最重要的 T 個單詞,在原始文本中進行標記,若形成相鄰詞組,則組合成多詞關鍵詞。
TextRank & PageRank
如果一個網頁被很多其他網頁鏈接到的話説明這個網頁比較重要,也就是PageRank值會相對較高
如果一個PageRank值很高的網頁鏈接到一個其他的網頁,那麼被鏈接到的網頁的PageRank值會相應地因此而提高
與TF-IDF需要在語料庫上計算IDF(逆文檔頻率)不同,TextRank利用一篇文檔內部的詞語間的共現信息(語義)便可以抽取關鍵詞。
二、利用sklearn實現tfidf算法
1.一個完整的例子
# coding:utf-8
import jieba
import jieba.posseg as pseg
import os
import sys
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus=["我 來到 北京 清華大學",
"他 來到 了 網易 杭研 大廈",
"小明 碩士 畢業 與 中國 科學院",
"我 愛 北京 天安門"]
vectorizer=CountVectorizer() #該類會將文本中的詞語轉換為詞頻矩陣,矩陣元素a[i][j] 表示j詞在i類文本下的詞頻
transformer=TfidfTransformer() #該類會統計每個詞語的tf-idf權值
X=vectorizer.fit_transform(corpus) #將文本轉為詞頻矩陣
tfidf=transformer.fit_transform(X) #計算tf-idf,
word=vectorizer.get_feature_names() #獲取詞袋模型中的所有詞語
weight=tfidf.toarray() #將tf-idf矩陣抽取出來,元素a[i][j]表示j詞在i類文本中的tf-idf權重
for i in range(len(weight)): #打印每類文本的tf-idf詞語權重
print("-------這裏輸出第",i,u"類文本的詞語tf-idf權重------" )
#for j in range(len(word)):
print(list(zip(word,weight[i])))控制枱輸出:
-------這裏輸出第 0 類文本的詞語tf-idf權重------
[('中國', 0.0), ('北京', 0.5264054336099155), ('大廈', 0.0), ('天安門', 0.0), ('小明', 0.0), ('來到', 0.5264054336099155), ('杭研', 0.0), ('畢業', 0.0), ('清華大學', 0.6676785446095399), ('碩士', 0.0), ('科學院', 0.0), ('網易', 0.0)]
-------這裏輸出第 1 類文本的詞語tf-idf權重------
[('中國', 0.0), ('北京', 0.0), ('大廈', 0.5254727492640658), ('天安門', 0.0), ('小明', 0.0), ('來到', 0.41428875116588965), ('杭研', 0.5254727492640658), ('畢業', 0.0), ('清華大學', 0.0), ('碩士', 0.0), ('科學院', 0.0), ('網易', 0.5254727492640658)]
-------這裏輸出第 2 類文本的詞語tf-idf權重------
[('中國', 0.4472135954999579), ('北京', 0.0), ('大廈', 0.0), ('天安門', 0.0), ('小明', 0.4472135954999579), ('來到', 0.0), ('杭研', 0.0), ('畢業', 0.4472135954999579), ('清華大學', 0.0), ('碩士', 0.4472135954999579), ('科學院', 0.4472135954999579), ('網易', 0.0)]
-------這裏輸出第 3 類文本的詞語tf-idf權重------
[('中國', 0.0), ('北京', 0.6191302964899972), ('大廈', 0.0), ('天安門', 0.7852882757103967), ('小明', 0.0), ('來到', 0.0), ('杭研', 0.0), ('畢業', 0.0), ('清華大學', 0.0), ('碩士', 0.0), ('科學院', 0.0), ('網易', 0.0)]2.根據語料庫統計idf(每個詞語的逆文檔頻率),並存持久化存儲到文件中,以便下次輸入一篇文檔即可返回相應關鍵詞
#-*-coding:utf-8-*-
import numpy as np
import math
from sklearn.feature_extraction.text import CountVectorizer
_trainText=[]
with open('sohu_train.txt', encoding='utf-8') as trainText:
for line in trainText:
id,catgre,body= line.split('^_^')
#print id,catgre
_trainText.append(body)
# for doc in _trainText[:10]:
# print(doc)
#將文本中的詞語轉換為詞頻矩陣
vectorizer = CountVectorizer()
#計算個詞語出現的次數
X = vectorizer.fit_transform(_trainText[:10000])
words = vectorizer.get_feature_names()
X_mat=X.toarray()
doc_num=X.shape[0]
# print(X.shape[0])
# print(X.toarray()[:,1])
# doc_num=len(X_mat[:,1])
print(X.shape)
fw=open('idf.txt', 'w', encoding='utf-8')
for index in range(len(words)):
# print(np.sign(X_mat[:,index]),X_mat[:,index])
idf=math.log(doc_num/(sum(np.sign(X_mat[:,index]))+1))
fw.write(words[index]+' '+str(idf)+'\n')
# print(words[index],math.log(doc_num/(sum(np.sign(X_mat[:,index]))+1)))
fw.close()
print('procesing completed')問題:詞頻矩陣非常稀疏矩陣,矩陣太大(文檔數量×詞彙數量),實際計算中文檔有59萬餘條,出現內存錯誤memoryerror,可以將語料分成多片分別進行計算,但這樣效率並不高,下面手動進行詞頻統計
三、用python3實現tfidf提取關鍵詞
手動計算詞頻,計算tfidf值
#利用搜狐新聞語料庫計算每個詞語的idf值,
#-*-coding:utf-8-*-
import numpy as np
import math
from collections import defaultdict
doc_num=0
doc_frequency=defaultdict(int)
with open('sohu_train.txt', encoding='utf-8') as trainText:
for line in trainText:
id,catgre,body= line.split('^_^')
# if doc_num>100000:break
doc_num+=1
for word in set(body.split(' ')):
word=word.replace('\n','').strip()
# if word in stopword :continue
if word =='' or word =='' :continue
doc_frequency[word]+=1
fw=open('idf-1.txt', 'w', encoding='utf-8')
for word in doc_frequency:
idf=math.log(doc_num/(doc_frequency[word]+1))
fw.write(word+' '+str(idf)+'\n')
print(word,doc_frequency[word])
fw.close()
print('procesing completed')
#加載已經訓練好的idf值,計算部分文章的tfidf,返回相應關鍵詞
idf_dict=defaultdict(int)
with open('idf-1.txt', encoding='utf-8') as idf_dict_text:
for line in idf_dict_text:
word,value= line.split(' ')
idf_dict[word]=float(value)
doc_num=0
with open('sohu_train.txt', encoding='utf-8') as trainText:
for line in trainText:
id,catgre,body= line.split('^_^')
#僅抽取前5篇文檔的關鍵詞
if doc_num>5:break
else:doc_num+=1
word_num=0
word_frequency=defaultdict(int)
for word in body.split(' '): #每篇文檔中詞頻統計
word=word.replace('\n','').strip()
if word =='' or word =='' :continue
word_frequency[word]+=1
word_num+=1
for word in word_frequency: #計算當前文章中每個詞的tfidf值
# print(idf_dict[word],type(idf_dict[word]))
tfidf=idf_dict[word]*word_frequency[word]/word_num
word_frequency[word]=tfidf
word_sorted=sorted(word_frequency.items(),key=lambda x:x[1],reverse=True)
print('document:',body.strip().replace(' ',''))
print('keywords:',word_sorted[:5])輸出前5篇文檔的關鍵詞:
document: 主題:Re:包子老公終於早飯了主題:Re:包子老公終於早飯了
keywords: [('包子', 0.9596168091464351), ('早飯', 0.9041355597752955), ('Re', 0.8966839785996794), ('老公', 0.6378780519245452), ('主題', 0.474942714460621)]
document: 主題:不管孩子多少,只要有一對無恥的兒子媳婦,老人就完蛋這次回老家,去看姑姑。姑姑老的不成樣子,身體極差,姑父身體還行,就是因為腦袋做過手術,説話有點稀裏糊塗的。姑姑有4個孩子,有三個生活非常不錯。但有一個兒子,生活很不好,這個兒子和我還是同學。特別是這個兒子的媳婦,那是超級的愣貨,我姑姑以前那麼要強的人,現在被這個兒子和媳婦逼的無路可走。
keywords: [('姑姑', 0.32601072973252054), ('兒子', 0.23452820867879176), ('媳婦', 0.18669451156212183), ('姑父', 0.0983996538992101), ('無路可走', 0.09541412728971811)]
document: 主題:[原創]家長自檢:你的孩子有這些錯誤的飲食習慣嗎?最近一直馬不停蹄的忙着中心和婦聯一起主辦的公益測評活動,雖然每天都很忙很緊張但是對於我還是有收穫的,希望對家長和孩子們都是有收穫的。因為下午還要出發,所以就大概給寶媽們總結一下我這段時間和孩子家長的閒聊中總結的一些兒童飲食錯誤:問題 1 :用方便麪代替正餐有的家長説早上沒有時間給孩子做早餐就用方便麪 給孩子當早餐,以為加上蔬菜和雞蛋就可以成為一份“營養”的早餐。這樣的認為是錯誤的,方便麪在營養師的眼中是最不營養的東西。它以麪粉為主,經過高温油炸,蛋白質、維生素、礦物質均嚴重不足,營養價值較低,還常常存在脂肪氧化的問題,熱量非常高,常常食用方便麪會導致營養不良。問題 2 :多吃營養滋補品有的家長説孩子太瘦,挑食,既然孩子吃得少那就給孩子吃醉營養的滋補品這樣就能彌補孩子缺失的營養了,錯誤。孩子的生活飲食習慣是家長一定要孩子養成的,而且孩子生長髮育所需要的熱能、蛋白質、維生素和礦物質主要也完全可以通過一日三餐獲得的。各種滋補營養品的攝入量本來就 很小,其中對身體真正有益的成分僅是微量,有些甚至具有副作用,增加孩子提前發育的風險。問題 3 :用乳飲料代替牛奶,用果汁飲料代替水果很多家長問我 “ 鈣奶、果奶 ” 之類的乳飲料代替牛奶 是不是會更好更營養。殊不知,兩者之間有着天壤之別,飲料根本無法代替牛奶和水果帶給孩子的營養和健康。在以前的帖子裏我也具體和大家説過,這裏就不再仔細説了。問題 4 :用甜飲料解渴,餐前必 喝飲料現在的孩子很多都和我是同一時期的人, 80 後習慣飲料當水解渴的習慣其實不好,現在升級做爸爸媽媽的應該不要把這個習慣再傳給我們的孩子。為了自己也為了孩子少喝飲料多喝水。甜飲料中 含糖達 10% 以上,飲後具有飽腹感,妨礙孩子正餐時的食慾。若要解渴,最好飲用白開水,它不僅容易吸收,而且可以幫助身體排除廢物,不增加腎臟的負擔。現在我們吃的多數都是“精米”“精面”其實長期進食精細食物並不好,不僅會因減少 B 族維生素的攝入而影響神經系統發育,還有可能因為鉻元素缺乏 “ 株連 ” 視力。鉻含量不足會使胰島素的活性減退,調節血糖的能力下降,致使食物中的糖分不能正常代謝而滯留於血液中,導致眼睛屈光度改變,最終造成近視。適當給孩子吃點粗糧其實是有好處的。
keywords: [('孩子', 0.14306680068891997), ('飲料', 0.07809347155812614), ('營養', 0.07489176669532517), ('家長', 0.0663471334581201), ('方便麪', 0.05927245295450419)]
document: 創建新論壇
keywords: [('創建', 1.9655444474558943), ('論壇', 1.573322421854069), ('新', 0.8736738323593722)]
document: 羽西當歸透白瑩潤精華液產品名稱:規格及價格:30ml/300 元羽西當歸透白瑩潤精華液藴含精純當歸素,它具有強力抗氧化功效和完全不粘配方,有效減退黯黃的同時抑制酪氨酸酶的活性,有 效美白肌膚。同時又擁 有晶瑩凝露觸感,使用感舒適。高濃度當歸循採淨白精萃有效淨膚排濁,配合精純乙基維生素C,有效隱褪黯黃,由內綻放純淨明亮。肌膚日漸透白瑩潤。使用説明:每日早晚在調理液後使用,之後進行當歸透白日常護膚。產品特點:"當歸循採淨白精萃"有效淨膚排濁,由內煥發勻白透潤。適合各種肌膚類型 每日早晚在調理液後使用,之後進行當透白日常護膚請直立放置。一款根據中國的環境狀況,為中國女性特殊的色素體系和美白需求度身定做的產品。羽西研究發現,中國女性的黑色素細胞樹突組織更長,因此黑色素傳導更易、更快、更多,使中國女性比其他國家女性更易變黑,羽西首度在美白產品中使用具有廣譜抗氧化作用的阿魏酸,結合天然藥用植物成分牡丹皮和維他命CG,幫助減緩黑色素傳導,從根源謁制黑色素生成。精華露首創生態美白系統,屏蔽大環境傷害,營造肌膚美白小環境,不只是減褪色斑,更從根源抑制黑色素。產品功效肌膚只在有血氣充盈的情況下才能白皙紅潤,要想肌膚明淨剔透,白皙健康,就要活血養血,使血流順暢,血管恢復到健康狀態。養血聖品--當歸其味甘而重,故專能補血,其氣輕而辛,故又能行血,補中有動,行中有補,誠血中之氣藥,亦血中之聖藥也。--《本草正》羽西首創氣血養白,中國系美白秘訣。養血聖品--當歸:排濁養血雙管齊下,祛 黃呈白,令肌膚通透粉潤。精選自1800餘種藥材,養血聖品當歸獨佔鰲頭,高科技萃取當歸循採淨白精粹。提升150%淨膚排濁功效,抗氧化力2.6倍於維生素CG,抗氧化力10倍於桑葉提取物。
keywords: [('當歸', 0.1866405240746113), ('羽西', 0.1265844668824549), ('排濁', 0.11178060976116114), ('黑色素', 0.09857243570844379), ('養血', 0.09812099637850542)]
document: 我可能感興趣的試用常見問題Q:為什麼我提交不了試用申請 A:試用申請必須同時滿足以下全 部條件:1、必須是搜狐試用頻道 的註冊會員;2、個人資料完成度 100%;3、非試用中心黑名單用 户;Q:為什麼我的試用報告不通過 A:試用報告提交後需經過編輯審核,合格的試用報告字數應該在100字以上,並且附有產品圖及試用體驗過程圖。試用報告字數過少或抄襲,都會被編輯審核為不通過;Q:什麼是試用報告? A:試用報告是收到試用產品後,按照時間規定在試用平台提交的一份關於產品使用的心得和體會。優秀的試用心得必須是圖文並茂;
keywords: [('試用', 0.7254374717517048), ('報告', 0.15653977634270186), ('Q', 0.12711201927875215), ('字數', 0.1132682062893399), ('提交', 0.11185601553931523)]四、利用jieba中的tfidf提取關鍵詞,並自定義idf詞典
jieba分詞中已經對tfidf進行了實現,並預先統計出了漢語中每個詞的逆文檔頻率(idf),存儲目錄為C:\Python37\Lib\site-packages\jieba\analyse\idf.txt
jieba默認使用以上路徑的idf詞典,並計算輸入文檔的tf(文本詞頻)值,進而求出tfidf提取關鍵詞
jieba允許用户使用set_idf_path方法自定義idf詞典
本文首先使用默認的idf詞典提取測試文檔的關鍵詞,然後使用set_idf_path將idf詞典設置為上一節中訓練的idf-1.txt再提取關鍵字,並進行前後對比
PS D:\> python3
Python 3.7.1 (v3.7.1:260ec2c36a, Oct 20 2018, 14:57:15) [MSC v.1915 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from jieba import analyse
>>> tfidf = analyse.extract_tags
>>> text ="""關鍵詞抽取就是從文本里面把跟這篇文檔意義最相關的一些詞抽取出來。這個可以追溯到文獻檢索初期,當時還不支持全文搜索的時候,關鍵詞就可以作為搜索這篇論文的詞語。因此,目前依然可以在論文中看到關鍵詞這一項。
... 除了這些,關鍵詞還可以在文本聚類、分類、自動摘要等領域中有着重要的作用。比如在聚類時將關鍵詞相似的幾篇文檔看成一個團簇,可以大大提高聚類算法的收斂速度;從某天所有的新聞中提取 出這些新聞的關鍵詞,就可以大致瞭解那天發生了什麼事情;或者將某段時間內幾個人的微博拼成一篇長文本,然後抽取關鍵詞就可以知道他們主要在討論什麼話題。
... 總之,關鍵詞就是最能夠反映出文本主題或者意思的詞語。但是網絡上寫文章的人不會像寫論文那樣告訴你本文的關鍵詞是什麼,這個時候就需要利用計算機自動抽取出關鍵詞,算法的好壞直接決定 了後續步驟的效果。"""
>>>
>>> keywords = tfidf(text) #使用結巴默認的idf文件(C:\Python37\Lib\site-packages\jieba\analyse\idf.txt)
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\zh\AppData\Local\Temp\jieba.cache
Loading model cost 0.878 seconds.
Prefix dict has been built succesfully.
>>> print(keywords) #採用默認idf文件提取的關鍵詞
['關鍵詞', '抽取', '聚類', '文本', '可以', '論文', '文檔', '詞語', '這篇', '算法', '搜索', '自動', '微博', '新聞', '文獻檢索', '某天', '什麼', '利用計算機', '拼成', '或者']
>>>
>>> analyse.set_idf_path('D:/idf-1.txt') #使用自定義idf文件,由搜狐新聞預料庫訓練得到
>>> keywords = tfidf(text)
>>> print(keywords)
['關鍵詞', '聚類', '抽取', '論文', '文本', '詞語', '可以', '文檔', '算法', '這篇', '一個團', '什麼', '拼成', '幾篇', '寫文章', '利用計算機', '某天', '文獻檢索', '新聞', '看成']
>>>五、TextRank算法提取關鍵字
TextRank算法提取關鍵字採用了PageRank算法的思想,僅文章本身便可以提取關鍵詞from jieba import analyse
textrank = analyse.textrank #引入jieba中的TextRank
text="""關鍵詞抽取就是從文本里面把跟這篇文檔意義最相關的一些詞抽取出來。這個可以追溯到文獻檢索初期,當時還不支持全文搜索的時候,關鍵詞就可以作為搜索這篇論文的詞語。因此,目前依然可以在論文中看到關鍵詞這一項。
除了這些,關鍵詞還可以在文本聚類、分類、自動摘要等領域中有着重要的作用。比如在聚類時將關鍵詞相似的幾篇文檔看成一個團簇,可以大大提高聚類算法的收斂速度;從某天所有的新聞中提取出這些新聞的關鍵詞,就可以大致瞭解那天發生了什麼事情;或者將某段時間內幾個人的微博拼成一篇長文本,然後抽取關鍵詞就可以知道他們主要在討論什麼話題。
總之,關鍵詞就是最能夠反映出文本主題或者意思的詞語。但是網絡上寫文章的人不會像寫論文那樣告訴你本文的關鍵詞是什麼,這個時候就需要利用計算機自動抽取出關鍵詞,算法的好壞直接決定了後續步驟的效果。"""
keywords = textrank(text)
print(keywords)
輸出:
['關鍵詞', '文本', '抽取', '聚類', '自動', '算法', '發生', '時候', '搜索', '文檔', '主題', '後續', '寫文章', '利用計算機', '決定', '相似', '詞語', '好壞', '摘要', '能夠']