
目錄
- 一個Snapshot
- 目標函數分析
- 初步認識目標函數
- 用泰勒展開來近似我們原來的目標:
- 樹的複雜度
- 改寫目標函數
- 最(極)值求解
- 收縮學習率和列採樣
- 打分函數計算示例
- 枚舉不同樹結構的貪心法
- 貪心法
- 端到端的模型評估
- XGBoost的實現
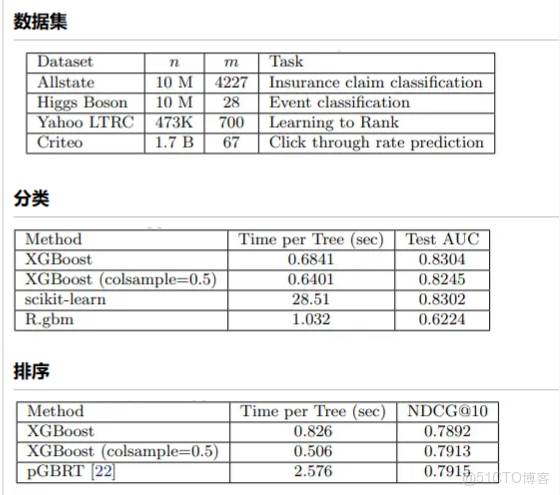
- 數據集
- 分類
- 排序
- Out-of-core
- 分佈式
本系列文章將會梳理Boosting算法的發展,從Boosting算法入手,介紹Adaboost,GBDT/GBRT算法,XGBoost算法,LightGBM算法,CATBoost算法,Thunder GBM算法等,介紹Boosting算法族的原理,框架,推導等,Boosting算法的前世今生(上篇)將介紹AdaBoost算法和梯度提升樹算法,中篇(本文)將會詳細介紹陳天奇教主提出的XGBoost算法,下篇將會介紹LightGBM算法,CATBoost算法,Thunder GBM算法等。XGBoost是在2014年由華盛頓大學的陳天奇(教主)提出的,對損失函數進行了二階泰勒展開,在優化時用到了一階導數和二階導數,而且採用結構損失最小化的原則,在損失函數中引入了關於樹模型複雜度的函數。
一個Snapshot
- XGBoost是GDBT的一個變種,最大的區別是XGBoost通過對目標函數做二階泰勒展開,從而求出下一步要擬合的樹的葉子結點權重(需要先確定樹的結構),從而根據損失函數求出每一次分裂結點的損失減小的大小,從而根據分裂損失選擇合適的屬性進行分裂。
- 這個利用二階展開得到的損失函數公式與分裂結點的過程是息息相關的。先遍歷所有結點的所有屬性進行分裂,假設選擇了這個a屬性的一個取值作為分裂結點,根據泰勒展開求得的公式可計算該樹結構各個葉子結點的權重,從而計算損失減小的程度,從而綜合各個屬性選擇使得損失減小最大的那個特徵作為當前結點的分裂屬性。依此類推,直到滿足終止條件。
目標函數分析
初步認識目標函數
- 目標函數:

其中,Obj代表第t步迭代的目標函數,Ω(ft)為正則項,包括L1正則項,L2正則項,constant為常數項。
用泰勒展開來近似我們原來的目標:
- 泰勒展開:f(x+Δx)≃f(x)+f′(x)Δx+12f′′(x)Δx2
- 定義:


- 那麼目標函數可以寫為(公式1):

- 利用泰勒展開目標函數後,可以清晰地看到,最終的目標函數只依賴於每個數據點在誤差函數上的一階導數和二階導數。暫且把這個目標函數放在這裏,我們接下來短暫地研究一下樹結構,以便弄清楚正則項Ω(ft)的表達式。
- x=(x1,x2,...,xn)∈X⊂Rn為數據點,f為樹結構的映射,它將數據點映射為一個數:
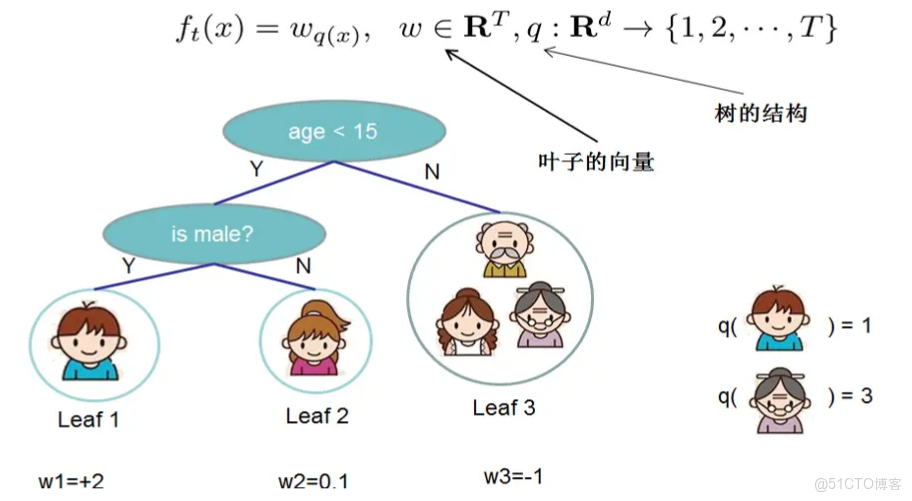

樹的複雜度
- 接下來定義樹的複雜度。
- 對於f的定義做一下細化,把樹拆分成結構部分q和葉子權重部分w。下圖是一個具體的例子,我會從下圖開始,詳細講講如何將映射f轉化為一個由w和q表示的映射。結構函數q把輸入x映射到葉子的索引號上,而w給定了索引號對應的葉子結點的葉子分數。
- 舉例説明一下,藍色衣服的小男孩記為樣本點x1,由於q是將數據點映射為葉子索引點號的函數,所以q(x1)為1(對應着Leaf 1),w將索引號映射為索引號對應的葉子結點分數,所以w(1)=+2,將這兩步複合起來就是w(q(x))=w(1)=2。
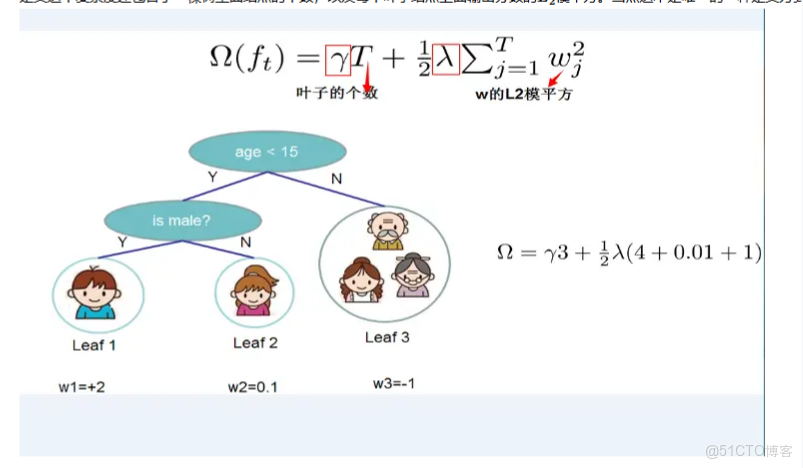
- 定義這個複雜度還包含了一棵樹裏面結點的個數,以及每個葉子結點上面輸出分數的L2模平方。當然這不是唯一的一種定義方式,不過這一定義方式學習出的樹效果一般都比較不錯。下圖還給出了複雜度計算的一個例子。
- 説明一下上圖,這棵樹包含3個葉子結點,所以複雜度Ω(ft)的第一項γT=3γ,第二項12λ∑Tj=1w2j=12λ×((+2)2+(0.1)2+(−1)2)=12λ×(4+0.01+1)
- 將弄清楚的正則項代入到之前的公式1中,我們可以改寫目標函數,以便目標函數和樹結構的聯繫更為緊密。
改寫目標函數
- 忽略常數項,目標函數可以改寫為:

- 再將映射f用w和q表示:

- 引入每個葉子上面的樣本點集合I,比如上圖的Leaf 3包含3個樣本點,分別是穿圍裙的媽媽,爺爺和奶奶,所以I3就是包含3個樣本點{穿圍裙的媽媽,爺爺和奶奶}的集合。將樣本點的求和指標換成葉子結點的求和指標:(此處也許需要較長時間理解,看不懂可以先跳過)

- 寫成這一形式後,目標包含了T個相互獨立的單變量二次函數,我們可以定義

- (類似於梯度和Hessian),最終公式可以化簡為

最(極)值求解
- 為了求解目標函數的最值(極值),也就是對目標函數進行最小化(極小值),那麼我們需要對目標函數關於wj進行求導(導數為零是目標函數取極值的必要條件,如果目標函數是凸函數,那麼導數為零是目標函數取極值的充要條件,比較邊界情況可以確定出最值),可以得到:

- 然後把wj最優解代入得到:

收縮學習率和列採樣
- XGBoost除了使用正則項防止過擬合外,還使用了收縮和列抽樣。收縮再次添加權重因子η到每一步樹boosting的過程中,這個過程和隨機優化中的學習速率相似,收縮減少每棵單獨樹的影響並且為將形成的樹預留了空間(提高了模型的效果)。特徵(列)抽樣(在隨機森林中使用)(相對於遍歷每個特徵,獲取所有可能的Gain消耗大)找到近似最優的分割點,列抽樣防止過擬合,並且可以加速並行化。
打分函數計算示例
- Obj代表了當我們指定一個樹的結構的時候,我們在目標上面最多減少多少,我們可以把它叫做結構分數(Structure Score)。
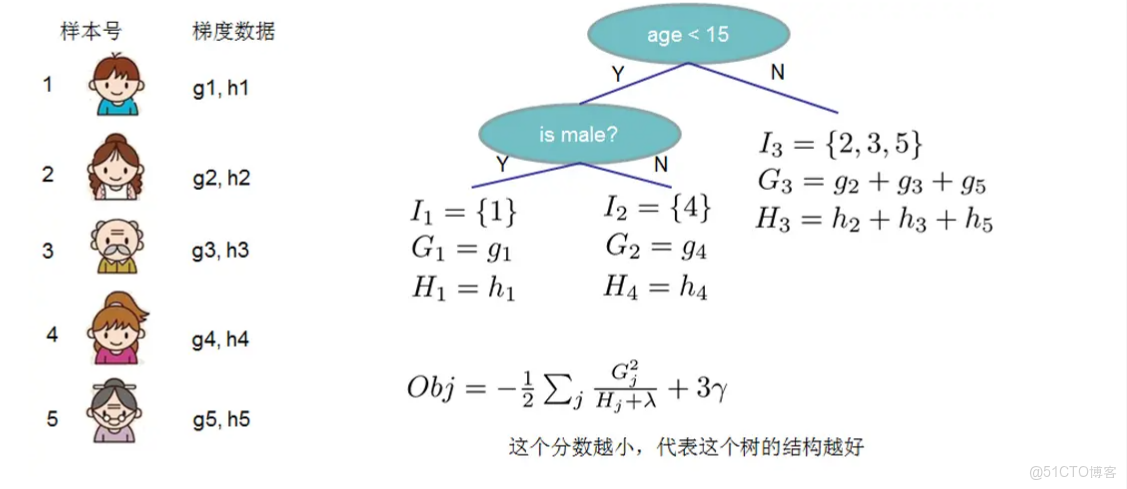
- 下圖描述了結構分數的計算方法:
- 計算好結構分數之後,我們就可以去構造XGBoost算法中的單棵樹了,接下來只需要説清楚我們是怎麼分裂結點生成單棵樹的,這是通過貪心法實現的。
枚舉不同樹結構的貪心法
貪心法
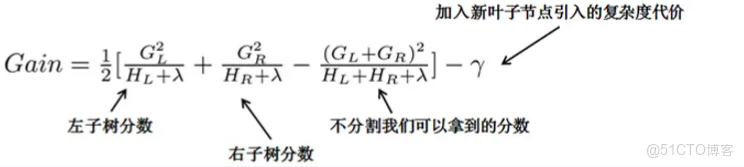
- 每一次嘗試去對已有的葉子加入一個分割:

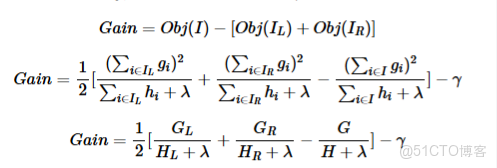
- 對於每次擴展,我們還是要枚舉所有可能的分割方案,如何高效地枚舉所有的分割呢?我假設我們要枚舉所有x<a這樣的條件,對於某一個特定的分割a,我們要計算a左邊的導數和右邊的導數和。
- 在構造樹結構時,每一次嘗試對已有的葉子結點加入一個分割,選擇具有最佳增益的分割對結點進行分裂。對於一個具體的分割方案,我們可以獲得的增益可以由如下公式計算:



- 其中I代表該結點下的所有樣本集合(分割前),設IL代表左子樹,IR代表右子樹,也就有I=IL∪IR
- 我們可以發現對於所有的a,我們只要做一遍從左到右的掃描就可以枚舉出所有分割的梯度和GL和GR。然後用上面的公式計算每個分割方案的分數就可以了。
- 觀察這個目標函數,大家會發現第二個值得注意的事情就是引入分割不一定會使得情況變好,因為我們有一個引入新葉子的懲罰項。優化這個目標對應了樹的剪枝, 當引入的分割帶來的增益小於一個閥值的時候,我們可以剪掉這個分割。大家可以發現,當我們正式地推導目標的時候,像計算分數和剪枝這樣的策略都會自然地出現,而不再是一種因為heuristic(啓發式)而進行的操作了。
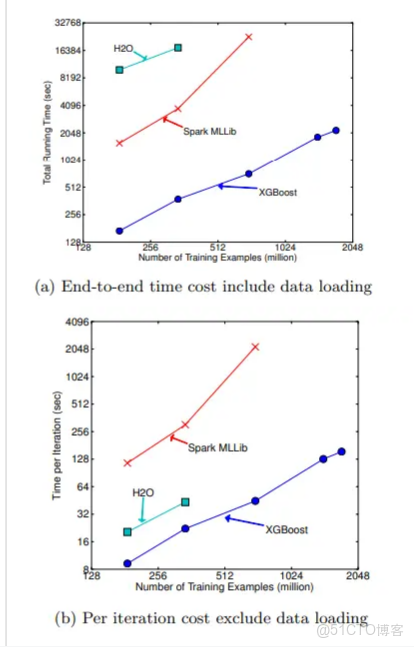
端到端的模型評估
XGBoost的實現
- XGBoost主要提供權重分類、排序目標函數,支持python、R、Julia,集成到了本地的數據管道如sklean。在分佈式系統中,XGboost也支持Hadoop、MPI、Flink、spark
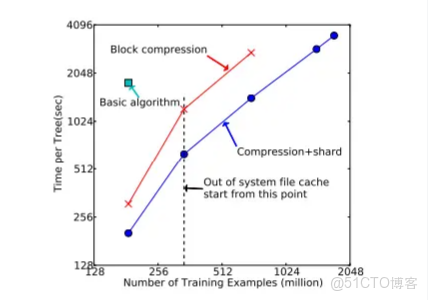
Out-of-core
分佈式
本文章為轉載內容,我們尊重原作者對文章享有的著作權。如有內容錯誤或侵權問題,歡迎原作者聯繫我們進行內容更正或刪除文章。