

面試 Java 基礎八股文十問十答第四期
作者:程序員小白條,個人博客
相信看了本文後,對你的面試是有一定幫助的!
⭐點贊⭐收藏⭐不迷路!⭐
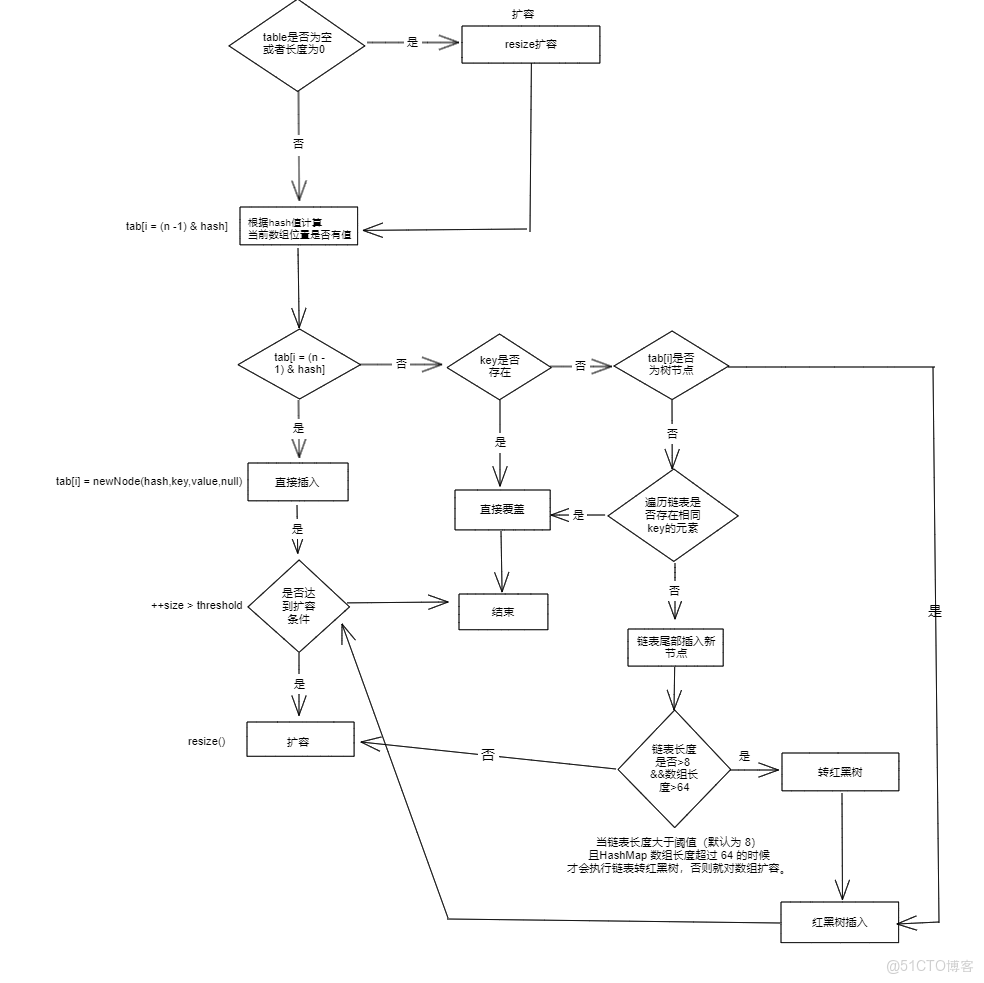
31.HashMap的put 方法執行過程
HashMap 只提供了 put 用於添加元素,putVal 方法只是給 put 方法調用的一個方法,並沒有提供給用户使用。
對 putVal 方法添加元素的分析如下:
- 如果定位到的數組位置沒有元素 就直接插入。
- 如果定位到的數組位置有元素就和要插入的 key 比較,如果 key 相同就直接覆蓋,如果 key 不相同,就判斷 p 是否是一個樹節點,如果是就調用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)將元素添加進入。如果不是就遍歷鏈表插入(插入的是鏈表尾部)。
32.ConcurrentHashMap的put方法
- 根據 key 計算出 hashcode 。
- 判斷是否需要進行初始化。
- 即為當前 key 定位出的 Node,如果為空表示當前位置可以寫入數據,利用 CAS 嘗試寫入,失敗則自旋保證成功。
- 如果當前位置的 hashcode == MOVED == -1,則需要進行擴容。
- 如果都不滿足,則利用 synchronized 鎖寫入數據。
- 如果數量大於 TREEIFY_THRESHOLD 則要執行樹化方法,在 treeifyBin 中會首先判斷當前數組長度 ≥64 時才會將鏈表轉換為紅黑樹。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能為空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目標位置元素
Node<K,V> f; int n, i, fh;// fh 後面存放目標位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 數組桶為空,初始化數組桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶內為空,CAS 放入,不加鎖,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加鎖加入節點
synchronized (f) {
if (tabAt(tab, i) == f) {
// 説明是鏈表
if (fh >= 0) {
binCount = 1;
// 循環加入新的或者覆蓋節點
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 紅黑樹
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}33.hashmap子類知道多少?

34.對於多態的理解是什麼?
1.父類的引用指向子類的對象
子類重寫父類的方法:子類可以繼承父類的方法,並對其進行重寫。當通過父類的引用調用這個方法時,實際執行的是子類重寫後的方法。
比如Person person = new Student Person是父類 Student ,都有一個工作的方法,student重寫工作方法,比如上學。
2.接口的引用指向實現類的對象
- List list = new ArrayList(); 2) ArrayList list= new ArrayList()
在第一種情況下,無法使用ArrayList特有的方法,因為聲明的是一個List類型的變量,只能使用List接口中定義的方法。而在第二種情況下,聲明瞭一個ArrayList類型的變量,可以使用ArrayList特有的方法。
3.方法的重載
方法的重載:方法重載指的是在同一個類中定義多個同名但參數列表不同的方法。在調用這個方法時,編譯器會根據參數的類型和數量來確定具體調用哪個方法。
4.方法重寫
4.1子類中的方法必須與父類中的方法具有相同的名稱。
4.2子類中的方法必須具有相同的參數列表(參數的類型、順序和數量)。
4.3子類中的方法的返回類型可以是父類方法返回類型的子類型(也稱為協變返回類型)。
4.4子類中的方法不能縮小父類方法的訪問權限(即不能將父類方法的訪問權限由public改為private),不能更加嚴格,但是可以擴大訪問權限。
5.向上轉型和向下轉型
5.1向上轉型(Upcasting):將一個子類對象轉換為父類類型。這是一個隱式的轉型過程,不需要顯式地進行類型轉換。
5.2向下轉型(Downcasting):將一個父類對象轉換為子類類型。這是一個顯式的轉型過程,需要使用強制類型轉換符進行類型轉換。需要注意進行類型檢查,避免類型轉換異常。
35.對於static變量的理解?static變量分配內存的時候發生在哪個環節?
static變量是一種靜態變量,它在程序執行期間保持不變。它被所有類的對象所共享,這意味着無論創建多少個類的對象,靜態變量只有一個副本。
靜態變量在類定義時被聲明,而不是在對象創建時分配內存。內存分配發生在程序加載時,在程序的生命週期內只會分配一次。
靜態變量是在類加載階段的第二階段連接(第二階段準備階段)從方法區取出內存,進行靜態變量的默認初始化,真正被賦值的時候是第三階段初始化。
36.JDK1.8對於方法區的實現是?(元空間)元空間還會存放什麼東西?
- 為什麼永久代(HotSpot虛擬機)要改成方法區(元數據區)?
因為永久代的垃圾回收條件苛刻,所以容易導致內存不足,而轉為元空間,使用本地內存,極大減少了 OOM 異常,畢竟,現在電腦的內存足以支持 Java 的允許。
- 只有 Hotspot 才有永久代。BEA JRockit、IBMJ9 等來説,是不存在永久代的概念的。
- 必要性:1.為永久代設置空間大小是很難確定的 2.對永久代進行調優是很困難的。
元數據區(MetaSpace)存放:1.運行時常量池和靜態常量池(字符串常量池放在堆中) 2.類元信息(類的二進制字節碼文件,類的名稱,父類,接口,成員變量,方法,靜態變量,常量,常量池的符號引用和指向其他類的引用) 3.方法元信息(方法訪問修飾符,返回類型,參數類型,異常類型)
37.為什麼String要設計成Final類?
只有當字符串是不可變的,字符串池才有可能實現
字符串池的實現可以在運行時節約很多heap空間,因為不同的字符串變量都指向池中的同一個字符串。但如果字符串是可變的,那麼String interning將不能實現(注:String interning是指對不同的字符串僅僅只保存一個,即不會保存多個相同的字符串。),因為這樣的話,如果變量改變了它的值,那麼其它指向這個值的變量的值也會一起改變。
如果字符串是可變的,那麼會引起很嚴重的安全問題
譬如,數據庫的用户名、密碼都是以字符串的形式傳入來獲得數據庫的連接,或者在socket編程中,主機名和端口都是以字符串的形式傳入。因為字符串是不可變的,所以它的值是不可改變的,否則們可以鑽到空子,改變字符串指向的對象的值,造成安全。
因為字符串是不可變的,所以是多線程安全的
同一個字符串實例可以被多個線程共享。這樣便不用因為線程安全問題而使用同步。字符串自己便是線程安全的。
類加載器要用到字符串,不可變性提供了安全性,以便正確的類被加載
譬如你想加載java.sql.Connection類,而這個值被改成了myhacked.Connection,那麼會對你的數據庫造成不可知的破壞。
作為Map的key,提高了訪問效率
因為字符串是不可變的,所以在它創建的時候hashcode就被緩存了,不需要重新計算。這就使得字符串很適合作為Map中的鍵,字符串的處理速度要快過其它的鍵對象。這就是HashMap中的鍵往往都使用字符串。因為Map使用得也是非常之多,所以一舉兩得
38.什麼情況下會導致元數據區溢出?
1.加載的類的數量過多(比如CGLIB不斷生成代理類)
2.類的大小過大,包含大量靜態屬性或常量
3.元數據區的參數設置不當,內存給的太小
堆在什麼時候會內存溢出?
堆內存存在大量對象,且對象都有被引用,創建對象不合理。
棧在什麼時候會溢出?
遞歸調用沒有寫好結束條件,導致棧溢出。
頻繁FullGC的幾種原因?
拓展:新生代佔比堆的三分之一,而老年代佔比堆的三分之二。1:2
新生代佔比:Eden8,S0,S1 各佔1份,8:1:1
① 系統承載高併發請求,或者處理數據量過大,導致YoungGC很頻繁,而且每次YoungGC過後存活對象太多,內存分配不合理,Survivor區域過小,導致對象頻繁進入老年代,頻繁觸發FullGC
② 系統一次性加載過多數據進內存,搞出來很多大對象,導致頻繁有大對象進入老年代,然後頻繁觸發FullGC
③ 系統發生了內存泄漏,創建大量的對象,始終無法回收,一直佔用在老年代裏,必然頻繁觸發FullGC
④ Metaspace 因為加載類過多觸發FullGC
⑤ 誤調用 System.gc() 觸發 FullGC
39.Java的常量優化機制
數值常量優化機制
1、給一個變量賦值,如果“=”號右邊是常量的表達式沒有一個變量,那麼就會在編譯階段計算該表達式的結果。
2、然後判斷該表達式的結果是否在左邊類型所表示範圍內。
3、如果在,那麼就賦值成功,如果不在,那麼就賦值失敗。
byte b1 = 1 + 2;
System.out.println(b1);
// 輸出結果 3這個就是典型的常量優化機制,1 和 2 都是常量,編譯時可以明顯確定常量結果,所以直接把 1 和 2 的結果賦值給 b1 了。(和直接賦值 3 是一個意思)
編譯器對 String 的常量也有優化機制
String s1 = "abc";
String s2 = "a"+"b"+"c";
System.out.println(s1 == s2); // true
String a = "a1";
String b = "a" + 1; // 常量+基礎數據類型
System.out.println((a == b)); //result = true
String a = "atrue";
String b = "a" + true;
System.out.println((a == b)); //result = true
String a = "a3.4";
String b = "a" + 3.4;
System.out.println((a == b)); //result = true
String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c"; // 變量+常量
System.out.println(s3 == s2); // false
final String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c"; //變量相加
System.out.println(s2 == s3); // true40.Comparable和Comparator接口區別和對比使用場景
1、Comparable 接口簡介
Comparable接口:位於java.lang包下,需要重寫public int compareTo(T o);
Comparable 是排序接口。若一個類實現了Comparable接口,就意味着“該類支持排序”。
“實現Comparable接口的類的對象”可以用作“有序映射(如TreeMap)”中的鍵或“有序集合(TreeSet)”中的元素,而不需要指定比較器。
它強行將實現它的每一個類的對象進行整體排序-----稱為該類的自然排序,實現此接口的對象列表和數組可以用Collections.sort(),和Arrays.sort()進行自動排序;
接口中通過compareTo(T o)來比較x和y的大小。若返回負數,意味着x比y小;返回零,意味着x等於y;返回正數,意味着x大於y。
2、Comparator 接口簡介
Comparator接口:位於java.util包下,需要重寫int compare(T o1, T o2);
Comparator 是比較器接口。我們若需要控制某個類的次序,而該類本身不支持排序(即沒有實現Comparable接口);
它是針對一些本身沒有比較能力的對象(數組)為它們實現比較的功能,所以它叫做比較器,是一個外部的東西,通過它定義比較的方式,再傳到Collection.sort()和Arrays.sort()中對目標排序,而且通過自身的方法compare()定義比較的內容和結果的升降序;
int compare(T o1, T o2) 和上面的x.compareTo(y)類似,定義排序規則後返回正數,零和負數分別代表大於,等於和小於。
總結:
1.只要涉及對象大小的比較,就可以實現這兩個接口的任意一個。
Comparable接口:通過對象調用重寫後的compareTo()
Comparator接口:通過對象調用重寫後的compare()
2.如果要調用sort進行排序
Comparable接口:自然排序
Comparator接口:定製排序-->屬於臨時性的排序規則
3.compare和compareTo方法的對比
compareTo:是拿調這個方法的對象和形參比大小
compare:直接讓兩個形參比大小