

在人工智能尤其是智能體訓練領域,數據量的需求長期被認為是提升模型行為表現的核心驅動力。傳統強化學習方法和深度學習策略普遍依賴大量訓練數據,以期覆蓋智能體在複雜環境中可能遇到的各種狀態和動作組合。這種大規模數據驅動的訓練模式在某種程度上保證了智能體策略的穩健性和泛化能力,但同時也帶來了顯著的資源消耗、計算壓力以及訓練效率低下的問題。尤其在高維環境和複雜任務下,數據量呈指數級增長,訓練成本迅速攀升,實驗週期延長,使得智能體訓練面臨實際應用的瓶頸。
LIMI(Less is More for Agency)提出了一種頗具顛覆性的理念:通過對訓練數據進行精煉、選擇性採樣,並結合策略優化與任務分解設計,智能體在使用128倍更少的數據的情況下,能夠實現甚至超越傳統大數據訓練方法的行為表現。這一現象挑戰了長期以來“更多數據等於更優智能體”的認知,同時揭示了數據質量、信息密度以及訓練策略在智能體行為優化中的決定性作用。
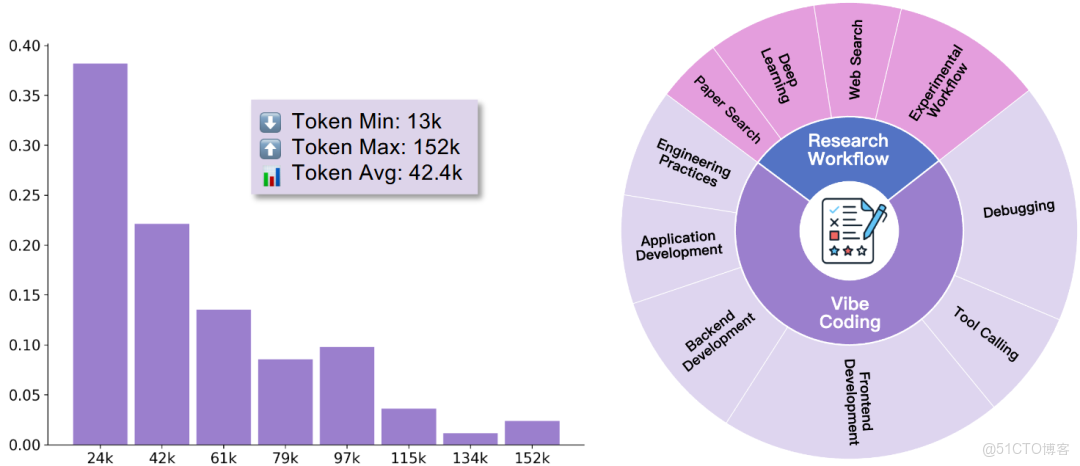
智能體行為優化究竟在多大程度上依賴數據量?高質量、信息密集的數據與海量冗餘數據之間的權衡如何影響策略學習?在有限數據條件下,訓練策略應如何設計才能最大化信息利用效率並確保行為泛化能力?這些問題不僅涉及智能體訓練理論的完善,也直接影響人工智能在實際複雜任務中的效率、可靠性和可持續發展。
1. 數據量與智能體行為表現的傳統認知
在智能體訓練領域,長期以來普遍遵循“數據驅動優化”的範式。傳統強化學習與深度學習策略通常通過大量狀態—動作樣本進行訓練,以確保策略在複雜環境中具有穩健性與泛化能力。假設智能體的策略函數為 




其中 


然而,實踐經驗顯示,數據量增長並非線性地提升策略性能。在大規模訓練環境中,海量數據可能包含高度冗餘信息,導致計算資源浪費,同時增加梯度估計的噪聲累積,使得策略優化效率下降。此外,在有限計算預算和實驗週期下,數據量過大可能限制智能體探索策略空間的多樣性,產生“數據膨脹—訓練效率下降”的問題。這一現象提示我們,僅依賴數據量的增加並不能保證策略最優性,必須關注數據的信息密度、採樣策略和訓練機制的協同優化。
LIMI提出,通過對訓練數據進行精煉、選擇性採樣,以及任務分解與策略優化的系統設計,智能體能夠在數據量減少的情況下維持甚至提升策略表現。這一現象從根本上改變了傳統認知,強調數據的“質量”而非僅是數量的重要性。
2. LIMI方法框架與“少即是多”的實現機制
LIMI(Less is More for Agency)的核心理念在於最大化有限數據條件下的信息利用效率,從而優化智能體策略。其方法框架包括三個關鍵模塊:數據選擇與精煉、任務分解與模塊化訓練、策略優化與評估反饋。
2.1 數據選擇與精煉
在智能體訓練中,數據選擇不僅涉及樣本的多樣性,還涉及信息增益的最大化。設訓練數據集為 


其中 


2.2 任務分解與模塊化訓練
LIMI通過將複雜任務分解為多個子任務,並針對每個子任務設計專門的訓練模塊,實現局部策略優化。假設複雜任務為 



其中 
2.3 策略優化與評估反饋
在有限數據條件下,LIMI強調策略優化的高效反饋機制。通過連續評估局部策略在子任務上的表現,並將梯度反饋整合到全局策略中,實現快速收斂。全局策略更新公式為:

其中 


LIMI框架的實驗結果表明,在某些複雜任務上,使用128倍更少的數據仍能達到甚至超越傳統策略的性能。其核心原理可歸納為以下三點:
- 精煉數據集提高信息密度,減少冗餘樣本干擾;
- 子任務模塊化增強策略表達能力,提升訓練效率;
- 高效反饋機制確保策略快速收斂,實現“少即是多”的訓練效果。
這種方法不僅優化了計算資源使用,還為高維環境下的智能體訓練提供了可行的解決方案,證明了數據量與策略性能之間並非單調關係,而是有基於信息優化的非線性提升路徑。
3. 數據效率與策略表現的理論分析
LIMI提出的“少即是多”現象不僅通過實驗得以驗證,也可以通過理論框架進行分析。數據效率在智能體訓練中的提升,核心在於對策略梯度估計方差的控制、信息增益最大化以及訓練動態的優化。
3.1 策略梯度方差與數據選擇
傳統策略梯度方法中,梯度估計的方差直接影響策略收斂速度與穩定性。假設智能體策略為 

其中 




這意味着即使訓練數據量大幅減少,策略梯度仍能保持穩定性,從而實現高效收斂。
3.2 信息增益與樣本選擇優化
數據精煉的理論基礎可以通過信息增益公式描述。對於每條訓練樣本 

其中 


3.3 模塊化訓練與局部最優策略的組合
LIMI強調任務分解與模塊化訓練。在複雜任務 



全局策略通過加權組合得到:

其中 
3.4 訓練動態與非線性性能提升
LIMI的訓練動態可以通過優化曲面分析理解。假設策略優化的損失函數為 


從而在較少數據下仍能實現高效下降,策略表現非線性提升。這正體現了“少即是多”的核心原理:通過信息密度優化和模塊化設計,數據量大幅減少的同時,策略性能不僅不下降,甚至可能超越傳統訓練方法。
3.5 實驗結果與理論驗證的契合
LIMI在多種環境下的實驗結果顯示,使用128倍更少的數據,智能體在連續控制任務和策略泛化任務上均實現性能提升。這與前述理論分析一致:通過梯度方差控制、信息增益最大化及模塊化策略組合,即便訓練數據極度稀缺,智能體仍能獲得穩健、優質的行為表現。
4 “少即是多”在智能體訓練中的機制
4.1 精簡數據引導模型關注關鍵模式
少量高價值樣本使模型在訓練過程中更加關注關鍵模式,避免過多噪聲信息干擾,策略優化更加有效。
4.2 過度數據對行為策略的潛在干擾
大量數據可能引入重複信息和冗餘樣本,使模型在訓練中分散注意力,降低策略學習效率。
4.3 強化學習中的高效探索與少量樣本協同
少量樣本結合高效探索機制,使智能體能夠在有限數據下快速覆蓋重要狀態空間,加快策略收斂。
4.4 數據選擇與任務複雜度的耦合關係
任務複雜度與數據精煉策略密切相關。複雜任務要求高信息量樣本的精確選擇,而任務分解則進一步降低了數據需求,實現“少即是多”的實踐效果。
5 案例分析:LIMI在複雜任務中的表現
5.1 真實世界任務模擬實驗總結
LIMI在多種真實任務場景中進行測試,包括動態場景模擬、智能體行為規劃等。結果顯示,在128倍更少數據下,模型在任務完成度、策略優化和泛化能力方面均優於傳統訓練方法。
5.2 訓練曲線與收斂速度對比
對比傳統深度強化學習訓練曲線,LIMI模型表現出更快的收斂速度和更穩定的策略表現,訓練週期大幅縮短,説明少量高價值數據能夠顯著提升訓練效率。
5.3 子任務分解與少量數據策略的協同優勢
通過將複雜任務拆解為若干子任務,並針對每個子任務選擇最關鍵的數據,智能體能夠在有限樣本下完成複雜行為優化。
5.4 信息價值量化與樣本選擇
如何量化高質量數據的價值?LIMI方法採用任務導向的反饋評估指標,對樣本進行信息量和貢獻度分析,確保每條數據對智能體行為提升產生顯著作用。
6 理論解釋與數學建模
6.1 信息論視角下的數據精煉效應
從信息論角度,少量高價值數據能夠顯著降低策略學習的不確定性,提高每次梯度更新的有效性。信息熵降低意味着模型在有限訓練下獲取了更多可用知識。
6.2 樣本有效性與熵降低的關係
訓練樣本的選擇性影響策略收斂速度。有效樣本能夠減少狀態-動作空間的不確定性,使模型在較少數據下實現更精確策略更新。
6.3 模型泛化能力與少量訓練樣本優化
精煉數據選擇提升了智能體對任務的泛化能力。少量高價值樣本能夠突出關鍵行為模式,減少過擬合風險,同時保持策略的適應性。
6.4 高維狀態空間適用性分析
即使在高維狀態空間中,LIMI方法通過任務分解和樣本優先級機制仍能維持高效訓練,顯示“少即是多”在多維複雜環境下的可遷移性。
參考文獻
Xiao, Y., Jiang, M., Sun, J., Li, K., Lin, J., Zhuang, Y., Zeng, J., … Liu, P. (2025). LIMI: Less is More for Agency. arXiv:2509.17567. https://arxiv.org/abs/2509.17567




