

在 PostgreSQL 18 中,你會在 EXPLAIN ANALYZE 的輸出結果中看到 “Index Searches”(索引搜索次數)相關行。如果你和我一樣好奇這些行到底是什麼意思,那這篇文章就是為你準備的。
標準情況
標準情況是 “Index Searches: 1”,表示對索引進行一次遍歷。如果所需數據都集中在索引的同一區域,這種情況可能非常高效。但如果所需條目並非集中存儲,那麼掃描過程中會包含大量不滿足查詢條件的條目,效率就會很低。後面會詳細説明這一點!
當索引搜索次數大於 1 時是什麼情況
在 Postgres 17 中,有一項不錯的優化,允許“讓 btree 索引更高效地查找一組值,例如 IN 子句提供的值”。這項優化基於 Postgres 9.2 中“讓 btree 原生處理 ScalarArrayOpExpr 子句”以及更早時針對(僅限)位圖索引掃描的優化成果。
文檔中提供了一個示例,位圖索引掃描的結果顯示索引被搜索了 4 次,IN 列表中的每個值對應一次搜索。以下是 PostgreSQL 18 中的輸出結果,能看到 Index Searches 字段:
EXPLAIN ANALYZE
SELECT * FROM tenk1 WHERE thousand IN (1, 500, 700, 999);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=9.45..73.44 rows=40 width=244) (actual time=0.012..0.028 rows=40.00 loops=1)
Recheck Cond: (thousand = ANY (''::integer[]))
Heap Blocks: exact=39
Buffers: shared hit=47
-> Bitmap Index Scan on tenk1_thous_tenthous (cost=0.00..9.44 rows=40 width=0) (actual time=0.009..0.009 rows=40.00 loops=1)
Index Cond: (thousand = ANY (''::integer[]))
Index Searches: 4
Buffers: shared hit=8
Planning Time: 0.029 ms
Execution Time: 0.034 ms
在這種情況下,一次索引搜索(針對同一個索引)需要掃描更多的緩衝區,因為它還需要掃描包含 1 到 999 之間未列出的其他 995 個值的頁面。
在此之前,我們無法從 EXPLAIN ANALYZE 的輸出結果中確定是否使用了該優化。我們只能通過一些線索推測,比如執行時間縮短、緩衝區使用減少,但無法獲得明確的索引搜索次數。不過,你可以在幾個系統視圖中查看相關數據,例如 pg_stat_user_indexes 表中的 idx_scan 列會統計這些單獨的索引搜索次數。
在 PostgreSQL 18 中,除了在 EXPLAIN 輸出中添加索引搜索次數字段外,還新增了對 btree 樹索引 “跳躍掃描”(skip scans)的支持。
文檔中同樣提供了一個清晰的示例,僅索引掃描的結果顯示索引被搜索了 3 次,範圍條件中的每個值對應一次搜索:
EXPLAIN ANALYZE
SELECT four, unique1 FROM tenk1 WHERE four BETWEEN 1 AND 3
AND unique1 = 42;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using tenk1_four_unique1_idx on tenk1 (cost=0.29..6.90 rows=1 width=8) (actual time=0.006..0.007 rows=1.00 loops=1)
Index Cond: ((four >= 1) AND (four <= 3) AND (unique1 = 42))
Heap Fetches: 0
Index Searches: 3
Buffers: shared hit=7
Planning Time: 0.029 ms
Execution Time: 0.012 ms
請注意,儘管 1、2 和 3 是列 “four” 的連續值,但它們對應的 unique1=42 的記錄在按 (“four", "unique1") 這個順序建立的索引中,(極大概率)不會互相靠近。因此,使用 3 次單獨的索引下降(descent)來獲取它們,會比一次性掃描整個索引高效得多。多次下降的開銷遠遠低於“掃描大量 unique1 <> 42 的無用元組”所帶來的低效。當然,如果下降次數變得非常多,這種優勢就會減弱。因此,當第一列中的值相對較少,且 WHERE 條件非常嚴格時,這種優化效果最為顯著。
我特別喜歡這類優化 —— 它們無需我們做任何改動,就能利用現有索引加速已有的查詢!
增加索引搜索是好是壞?
一般來説,最高效的掃描是對最優索引進行一次遍歷,這樣能最大限度地減少緩衝區讀取次數。
但是,為每個查詢都建立最優索引的做法並不理想,因為每增加一個索引都會帶來一定的代價。這些代價包括(但不限於)寫入放大、丟失熱點更新(針對之前未建立索引的列)以及共享緩衝區空間競爭加劇。
因此,如果您正在優化一個重要的查詢,並且願意為其創建和維護索引,那麼 “索引搜索次數> 1” 可能意味着存在更優的解決方案。
一個簡單的例子
以下是我認為最簡單的演示方法:
CREATE TABLE example (
integer_field bigint NOT NULL,
boolean_field bool NOT NULL);
INSERT INTO example (integer_field, boolean_field)
SELECT random () * 10_000,
random () < 0.5
FROM generate_series(1, 100_000);
CREATE INDEX bool_int_idx
ON example (boolean_field, integer_field);
VACUUM ANALYZE example;
因此,我們創建了一個包含兩列的表,插入了 10 萬行數據。其中一列的基數很低(布爾值均勻分佈),另一列的基數高得多(0 到 10k 之間的隨機整數)。
我們在兩列上都添加了索引,布爾列排在前(列的順序很重要)。最後,我們運行了 VACUUM ANALYZE 命令來更新可見性映射並收集統計信息。
如果我們現在運行一個僅根據索引中的第二列進行篩選的查詢,我們預計在 Postgres 18 中使用跳躍掃描會得到一個效率更高的查詢計劃。
如果先在 Postgres 17 上運行,我們會得到以下查詢計劃:
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using bool_int_idx on public.example (cost=0.29..1422.39 rows=10 width=1) (actual time=0.579..1.931 rows=18 loops=1)
Output: boolean_field
Index Cond: (example.integer_field = 5432)
Heap Fetches: 0
Buffers: shared hit=168
Planning Time: 0.197 ms
Execution Time: 1.976 ms
雖然我們執行的是僅索引掃描,但請注意,它讀取了 168 個緩衝區,卻只返回了 18 行。它實際上是在掃描我們的整個索引(168 * 8KB = 1344KB)。
SELECT pg_size_pretty(pg_indexes_size('example'));
pg_size_pretty
----------------
1344 kB
如果我們在 Postgres 18 上運行同樣的操作,會得到以下查詢計劃:
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using bool_int_idx on public.example (cost=0.29..13.04 rows=10 width=1) (actual time=0.230..0.274 rows=5.00 loops=1)
Output: boolean_field
Index Cond: (example.integer_field = 5432)
Heap Fetches: 0
Index Searches: 4
Buffers: shared hit=9
Planning Time: 0.240 ms
Execution Time: 0.323 ms
有三點需要注意:
- 緩衝區使用量大幅減少,從 168 個降至 9 個
- 執行時間更短(得益於更少的緩衝區讀取)
- 索引搜索次數:4
這是一項很棒的優化,能更高效地利用索引!
等等,為什麼會有四次索引搜索?可能你和我一樣,原本以為只有兩次,TRUE 和 FALSE 各一次。我一開始也百思不得其解,最後在性能郵件列表裏提問。感謝 Peter Geoghegan 的解答。原來,在一般情況下,邊界條件和 NULL 值(當然!)總是需要考慮的,所以當無法排除這些情況時,就會產生一到兩次額外的索引搜索。
由於我知道這些優化非常靈活,我想知道是否可以通過顯式篩選“僅”包含 TRUE 或 FALSE 的值來進行兩次索引搜索:
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432
AND boolean_field IN (true, false);
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using bool_int_idx on public.example (cost=0.29..8.79 rows=10 width=1) (actual time=0.060..0.077 rows=12.00 loops=1)
Output: boolean_field
Index Cond: ((example.boolean_field = ANY (''::boolean[])) AND (example.integer_field = 5432))
Heap Fetches: 0
Index Searches: 2
Buffers: shared hit=5
Planning Time: 0.265 ms
Execution Time: 0.115 ms
搞定!現在我們只進行了兩次索引搜索,這正是我們所期望的。這使得緩衝區讀取次數更少(僅 5 次),執行速度也更快。這得益於 Postgres 17 的優化工作。但是修改查詢並非總是可行,如果我們認為原始查詢對我們的工作負載至關重要,我們很樂意為其添加一個最優索引。這樣能做得更好嗎?
CREATE INDEX int_bool_idx ON example (integer_field, boolean_field);
EXPLAIN (ANALYZE, BUFFERS, VERBOSE, SETTINGS)
SELECT boolean_field FROM example WHERE integer_field = 5432;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Index Only Scan using int_bool_idx on public.example (cost=0.29..4.47 rows=10 width=1) (actual time=0.042..0.047 rows=12.00 loops=1)
Output: boolean_field
Index Cond: (example.integer_field = 5432)
Heap Fetches: 0
Index Searches: 1
Buffers: shared hit=3
Planning Time: 0.179 ms
Execution Time: 0.078 ms
由於我們新索引的列順序顛倒了,相關的元組現在位於同一位置,這意味着掃描可以高效地執行一次索引下降(索引搜索:1),從而產生最少的緩衝區讀取(3),並因此實現最快的執行速度。
以下是我嘗試用可視化方式展現列的順序如何影響條目的共存位置:
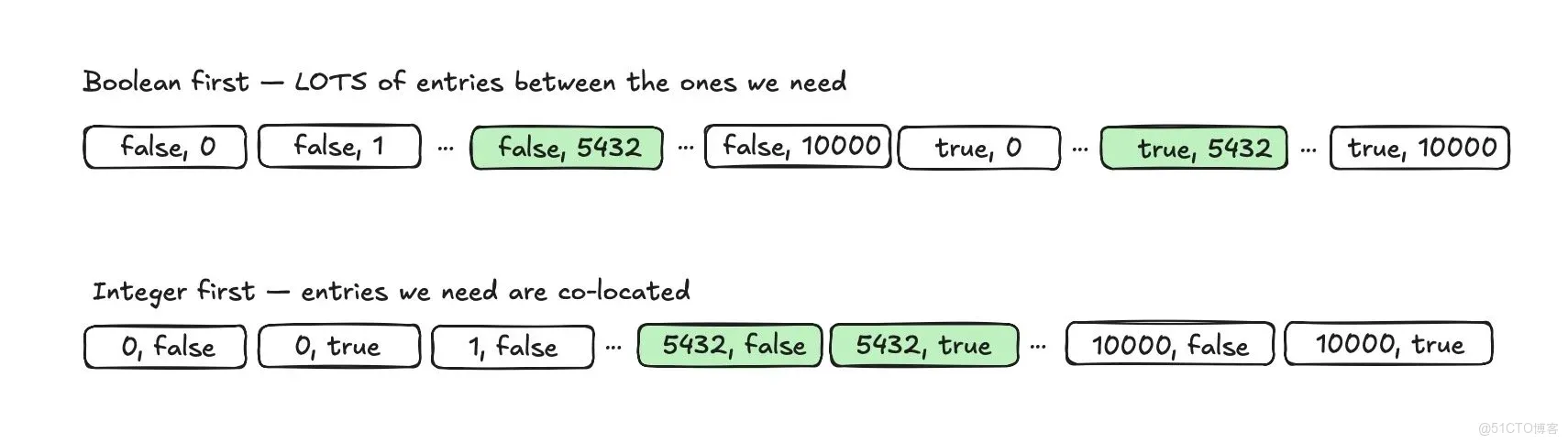
最後,這裏是通過 pgMustard 保存和可視化的最後四個查詢計劃。
我們是否已開始使用索引搜索來獲取提示信息?
到目前為止,我們還沒有直接將索引搜索次數用於 pgMustard 的優化建議中。但在某些有幫助的場景下,會在 “操作詳情” 中顯示該字段。
當索引掃描效率特別低時,如果緩衝區讀取次數遠多於返回的行數,您仍然會看到“讀取效率”提示;如果 Postgres 報告説很大比例的行正在被過濾,您仍然會看到“索引效率”提示。
一旦我們瞭解到實際應用中這類問題的常見程度,以及優化潛力的大小,可能會添加更具體的相關建議!
一些實用建議
首先,如果你在優化重要查詢時發現 “索引搜索次數> 1”,可能存在更適合該查詢的索引定義。
我的主要建議是,仍然要關注所有常規事項,例如篩選行、緩衝區和計時。
如果您認為某些不太重要(或優化程度較低)的查詢可能會受益於這些改進,請考慮升級到(或至少測試)Postgres 18。
如果你願意,現在或許可以減少索引的數量。可以先擴大搜索範圍,查找冗餘/重疊的索引,包括那些列相同但順序不同的索引。這樣或許可以刪除一兩個索引,而對讀取延遲的影響在可接受的範圍內。
作者:Michael Christofides
原文鏈接:
https://www.pgmustard.com/blog/what-do-index-searches-in-explain-mean