
長期以來,Lucene在搜索領域的壟斷地位無人能及,基於Lucene之上的Elastic Search與Solr 也是家喻户曉的產品;錄信數據庫最初的版本也是基於Lucene來實現的,在設計之初經常會遇到跟solr、es同樣的問題。如面對幾十億的數據就遇到內存爆掉的問題,此時CPU與IO都飆到系統極限;100億的數據就需要100多台512G的大內存與SSD盤的硬件支撐,內存參數略微調不好就出現節點掉片,內存OOM的情況。
Lucene在檢索上的設計缺點
目前Lucene只能對單列建立倒排索引,並不支持多列聯合索引,所以在搜索多個條件進行匹配的時候,需要多個查詢Query一起進行檢索,最終通過doclist與bitset 方式實現多條件查詢結果的AND與OR關係的歸併。跳躍表歸併存在較大的io浪費,也會因跳躍表的隨機讀降低檢索性能。
其次Lucene倒排索引的實現是基於FST的BLOCK TREE,這個數據結構官方給的描述是為了節省內存,實則只是相對而言,因每次打開索引就需要將tip文件全部加載到內存裏,在萬億規模下,一個表會有很多個數據列,這種加載方式非常的慢,而且內存使用量也非常高;另外在檢索的時候FST這種類型需要申請大量的數組,雖然是臨時使用,但沒有采用對象池,每次垃圾回收,會造成非常大的GC壓力,GC停頓時間很長。而錄信數據庫需要在一百台128G內存的硬件上支撐上萬億的數據,內存使用規模上行不通。
Lucene在統計上的設計缺點
Lucene進行分組統計時就需要依賴Lucene的docvalue;docvalue不是有序存儲,需將ord文件加載到內存裏,做ord映射;這種設計只要數據規模一大,效率就很差,就會出現爆內存的問題;而且因為是隨機讀,磁盤IO會飆的非常的高;ES經常遇到的頻繁掉片和崩掉的問題都跟docvalue自身的設計有很大的關係。
Lucene的倒排表雖然也可以做單列統計,但歸根結底是為了用於實現檢索功能,其本身的設計並不是為了大範圍掃描(Scan)與統計而設計的;
首先倒排表的TermStat因為要引用doc,pos,pay等一系列文件,沒有任何的壓縮,如果數據的值太多(Term太多),TermStat本身的IO會高於原始數據很多倍,在統計的時候會變得更慢,如果出現大範圍的掃描將會出現致命的問題(如掃描一個大範圍的手機號139*)。
最後Lucene還有另外一個功能,可以用來實現數據統計加速,即payload。這個設計非常巧妙,但缺點是數據沒有經過任何壓縮,會導致一旦使用了payload,數據膨脹率很高,雖然在某些程度上能構造一些順序讀取,但是文件體積過大,一般不適合存儲太大的數據。
其他列統計場景存在的問題
面對海量數據的OLAP需求,為了減少存儲費用、提高統計性能,數據庫系統採用壓縮和列存儲的方法來保存數據。
傳統的列存儲是針對單列存儲,多列之間並未建立關聯,數據也沒有按照順序排列,數據庫壓縮比不高;
因數據存儲不連續,存在大量的跳躍訪問和隨機訪問,嚴重影響查詢性能。統計的時候,也會因數據不連續、同組數據不相鄰,需每條數據一條一條的計算,效率較差。
因此需對數據進行存儲干預,並支持多列聯合索引,數據經過多列排序干預後,查詢可以變為連續讀取,這樣壓縮比會非常高;在統計計算的時候可以一批一批的算;且由於數據之間存在關聯,在多條件檢索與關係分析上也可以節省很多IO。
多列聯合索引
鑑於上述原因,我們重新實現了Lucene的索引部分,以解決上面存在的問題。
1. 多列聯合倒排索引的設計目標
- 加快統計與檢索場景的速度。
- 實現多層次關係分析。
- 提升Top N排序速度。
- 加快數據導出的速度。
2. 多列聯合倒排索引的實現特點
- 每列之間採用列存儲,會根據數據特點自動選擇合適的壓縮算法。
- 預先干預數據的排序分佈,讓列存儲的壓縮更有效。
- 依據查詢構造順序讀取。
- 多個列之間存在層次關係。
- 結合分塊存儲,可以隨機訪問。
- 使用極少的內存。
- 對象內存重用,減少GC壓力。
- 可以壓縮的payloads。
3. 應用場景
1:統計與檢索。
2:多層次的關係分析。
3:TOP N排序。
4:因存儲連續,適合數據導出。
4. 基本原理圖
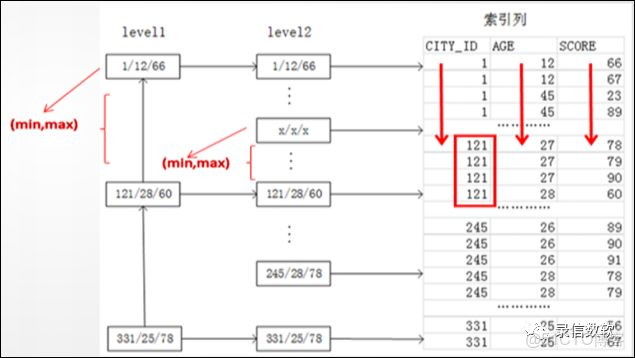
使用方法
1. 基本概念
(1) olap_key:
1) 按照olap_key預先干預數據的分佈
2) olap_key的每一列均是列存儲
3) olap_key的每一列採用多種不同的壓縮算法
4) 儘量將識別率高的列排在前面
① 如用來過濾篩選的手機號,雖然壓縮比一般,可以有效利用索引先過濾;
② 或者那些重複值很高的列,如性別,省份,協議等 可以有非常高的壓縮比。
(2) olap_value:
1) 跟隨着olap_key後面存儲,連續存儲
2) 可以存儲多個值,但並非按列存儲,壓縮方法採用lz4
3) 一般用來存儲一些長文本數據
4) 不可以進行scan過濾
2. 建表方法
create table olap_test(
s_high y_string_is,
s_middle y_string_is,
s_low y_string_is,
l_high y_long_is,
l_middle y_long_is,
l_low y_int_is,
d_high y_double_is,
d_middle y_double_is,
d_low y_double_is,
hlll_1 y_ldrill_imp 'olap_key@s_high,s_low,l_low,d_low' 'olap_value@l_high,d_high',
hmll_2 y_ldrill_imp 'olap_key@l_high,l_middle,l_low,s_low' ,
mlll_1 y_ldrill_imp 'olap_key@s_middle,s_low,l_low,d_low' 'olap_value@l_high,d_high',
mmll_2 y_ldrill_imp 'olap_key@d_middle,l_middle,l_low,s_low' ,
lllh_1 y_ldrill_imp 'olap_key@s_low,l_low,d_low,s_high' 'olap_value@s_low,d_high',
llmh_2 y_ldrill_imp 'olap_key@l_low,s_low,l_middle,l_high' ,
lllm_1 y_ldrill_imp 'olap_key@s_low,l_low,d_low,s_middle' 'olap_value@s_low,d_high',
llmm_2 y_ldrill_imp 'olap_key@l_low,s_low,d_middle,l_middle' ,
hl_1 y_ldrill_imp 'olap_key@s_high,s_low' 'olap_value@l_high,d_high',
hm_2 y_ldrill_imp 'olap_key@l_high,l_middle' ,
ml_1 y_ldrill_imp 'olap_key@s_middle,s_low' 'olap_value@l_high,d_high',
mm_2 y_ldrill_imp 'olap_key@d_middle,l_middle' ,
ll_1 y_ldrill_imp 'olap_key@s_low,l_low' 'olap_value@d_low',
ll_2 y_ldrill_imp 'olap_key@l_low,s_low'
);也可以結合列簇,將不同的列分開,存儲到不同的存儲介質中:
create columnfamily olap_test (
default at 'index@true' 'store@false'
,hlll_1 at 'fields@hlll_1' 'index@true' 'store@false'
,hmll_2 at 'fields@hmll_2' 'index@true' 'store@false'
,mlll_1 at 'fields@mlll_1' 'index@true' 'store@false'
,mmll_2 at 'fields@mmll_2' 'index@true' 'store@false'
,lllh_1 at 'fields@lllh_1' 'index@true' 'store@false'
,llmh_2 at 'fields@llmh_2' 'index@true' 'store@false'
,lllm_1 at 'fields@lllm_1' 'index@true' 'store@false'
,llmm_2 at 'fields@llmm_2' 'index@true' 'store@false'
,hl_1 at 'fields@llmm_2' 'index@true' 'store@false'
,hm_2 at 'fields@llmm_2' 'index@true' 'store@false'
,ml_1 at 'fields@llmm_2' 'index@true' 'store@false'
,mm_2 at 'fields@llmm_2' 'index@true' 'store@false'
,ll_1 at 'fields@llmm_2' 'index@true' 'store@false'
,ll_2 at 'fields@llmm_2' 'index@true' 'store@false'
);
3. 查詢使用方法
(1) 測試數據如下:
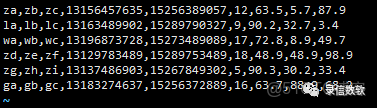
(2) 導入語句如下:
sh load.sh -t olap_test -p all_50yi_002 -tp txt -local -f /wyh/ldrill.log -sp , -fl s_high,s_middle,s_low,l_high,l_middle,l_low,d_high,d_middle,d_low(3) 查看錶數據:
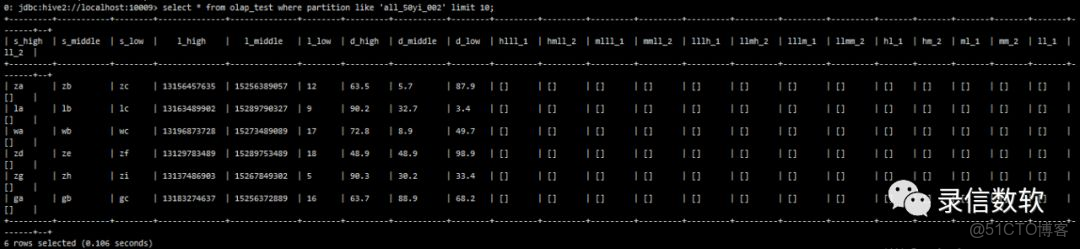
(4) 僅掃描olap_key(按列存儲,不需要的列不掃描)
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' limit 20;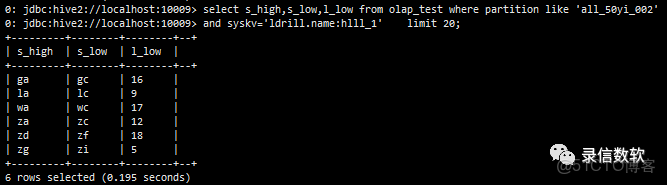
(5) 同時掃描olap_key與olap_value
注:olap_value不同的是整體壓縮,查一個列與查詢所有的列,IO是一樣的,且Olap_value裏面的列不能參與過濾,他也會加載doclist文件,速度略慢,但因為是順序讀,且有lz4壓縮,性能一般也比docvalues快。
select s_high,s_low,l_high from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:hlll_1' limit 20;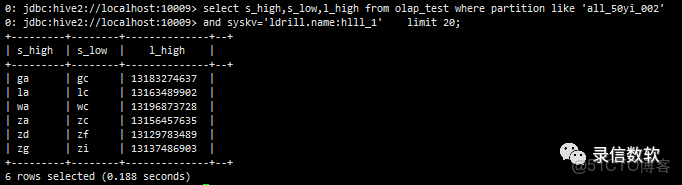
(6) 帶檢索條件 from to,如果from==to相當於等值查詢,儘量將需要過濾的列放在第一位,適合http協議那種根據key直接導出一批大的結果
--等值查詢
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:hlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['za']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['za']@SYS_URL_ENCODE'
limit 20;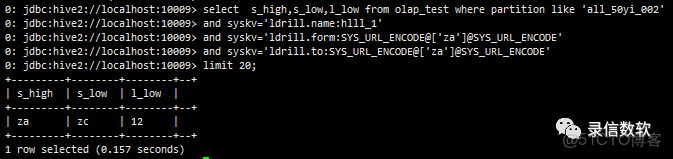
--範圍查詢
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:hlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['za']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['zd']@SYS_URL_ENCODE'
limit 20;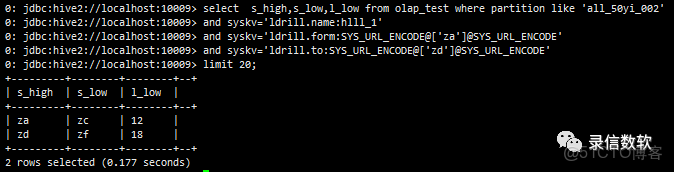
(7) 通配符*的使用
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:hlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['*','zc']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['*','zc']@SYS_URL_ENCODE'
limit 20;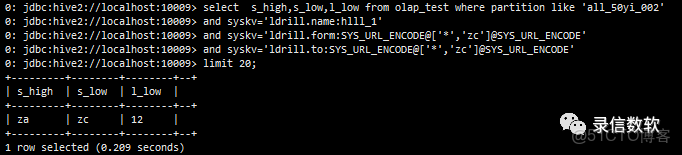
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:hlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['*','*','9']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_UR L_ENCODE@['*','*','16']@SYS_URL_ENCODE'
limit 20;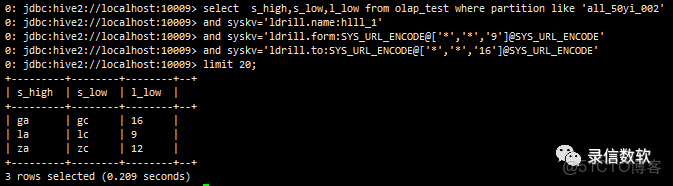
(8) 也可以與其他檢索條件組合使用,但是要藉助doclist進行bitset比對,會有doclist的額外開銷,性能相對於純粹的from to會差一些。
select s_high,s_low,l_low from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:hlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['*','*','9']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['*','*','16']@SYS_URL_ENCODE'
and s_low='zc'
limit 20;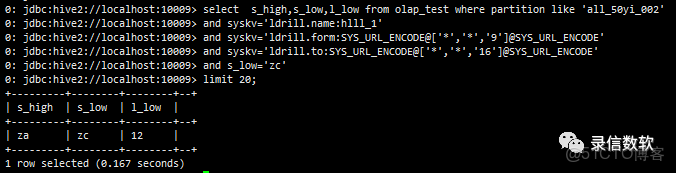
(9) 統計
select l_low,count(*) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:ll_1' group by l_low limit 20;
(10) ldrill的統計是可以多列的,這是它的特點
select s_low,l_low,count(*) from olap_test where partition like 'all_50yi_002' and syskv='ldrill.name:ll_1' group by s_low,l_low limit 20;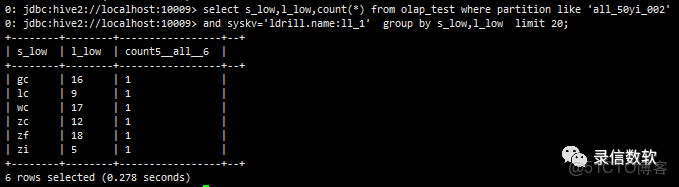
(11) 對於某一個篩選值下面的統計,如篩選某一手機號,統計某一局部數據,這樣篩選範圍數據量就少了,而且這些數據還是連續存儲
select d_middle,l_middle,count(*) from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:mm_2'
and syskv='ldrill.form:SYS_URL_ENCODE@['30.0']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['50.0']@SYS_URL_ENCODE'
group by d_middle,l_middle
limit 20;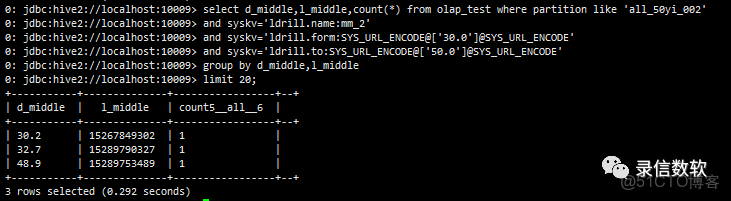
select l_middle,count(*),avg(d_middle),max(d_middle),min(d_middle),sum(d_middle)
from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:mm_2'
and syskv='ldrill.form:SYS_URL_ENCODE@['*','15256372889']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['*','15289790327']@SYS_URL_ENCODE'
group by l_middle
limit 20;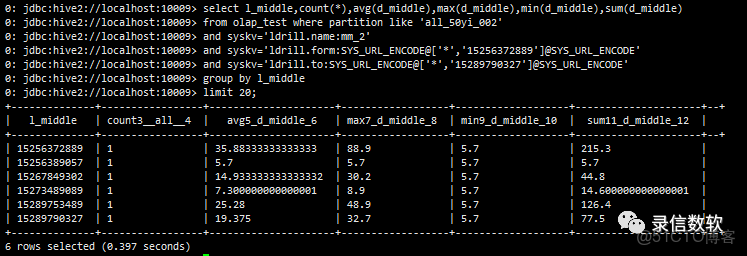
select d_middle,count(*),avg(l_middle),max(l_middle),min(l_middle),sum(l_middle)
from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:mm_2'
and syskv='ldrill.form:SYS_URL_ENCODE@['30.0']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['50.0']@SYS_URL_ENCODE'
group by d_middle limit 20;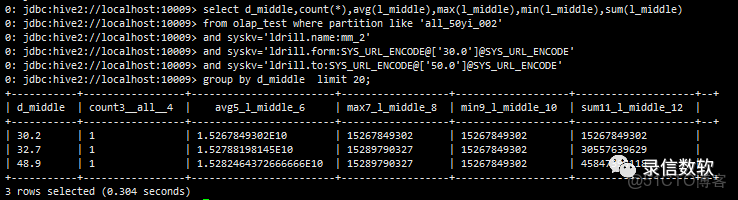
(12) 數據導出,僅導出olap_key
export json overwrite /data/export/test2 select s_middle,s_low,l_low,d_low
from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:mlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['zb']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['ze']@SYS_URL_ENCODE';
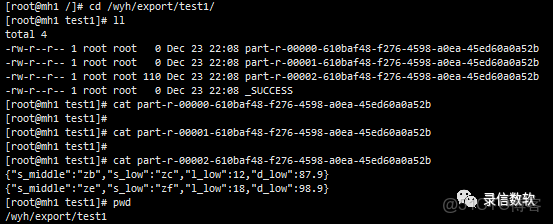
注:該處測試所用的LSQL為單機版,故導出後文件存放在本地指定路徑(如為集羣版,則存放在HDFS上)。導出的文件數量與executor數有關。
(13) 數據導出,很多時候,往往需要將olap_value中的大塊的值也導出去,這個時候只能讀doclist,但是好在是順序讀取
export json overwrite /wyh/export/test2 select s_middle,s_low,l_low,d_low,l_high,d_high
from olap_test where partition like 'all_50yi_002'
and syskv='ldrill.name:mlll_1'
and syskv='ldrill.form:SYS_URL_ENCODE@['zb']@SYS_URL_ENCODE'
and syskv='ldrill.to:SYS_URL_ENCODE@['ze']@SYS_URL_ENCODE';
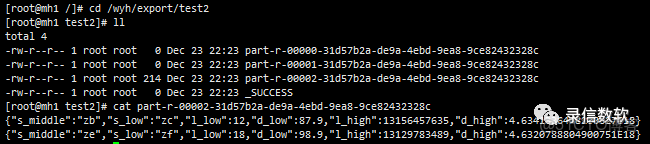
(14) group by只能做一種請求,如果一次請求要返回多種彙總數據,可以藉助facet
--不返回數據明細
select * from olap_test where partition like 'all_50yi_002'
and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_1','fl':'s_low,l_low','from':['*'],'to':['*']}@SYS_URL_ENCODE'
and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_2','fl':'l_low,s_low','from':['*'],'to':['*']}@SYS_URL_ENCODE'
limit 0;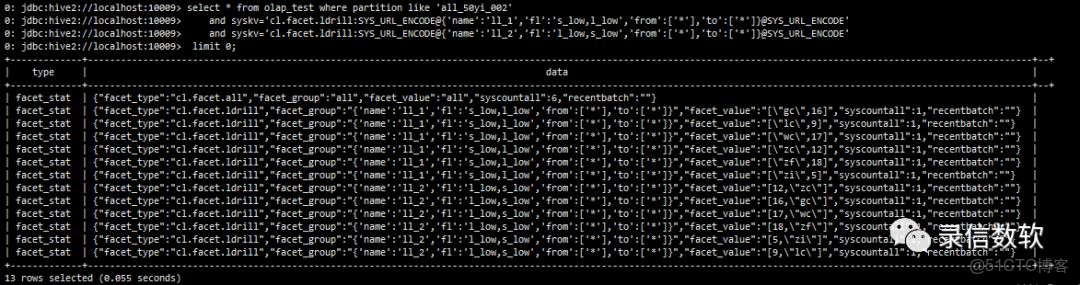
結合過濾篩選的facet:
select * from olap_test where partition like 'all_50yi_002'
and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_1','fl':'s_low,l_low','from':['zc','5'],'to':['zi','12']}@SYS_URL_ENCODE'
and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_1','fl':'s_low,l_low','from':['zc','12'],'to':['zf','18']}@SYS_URL_ENCODE'
and syskv='cl.facet.ldrill:SYS_URL_ENCODE@{'name':'ll_2','fl':'l_low','from':['9'],'to':['17']}@SYS_URL_ENCODE'
limit 0;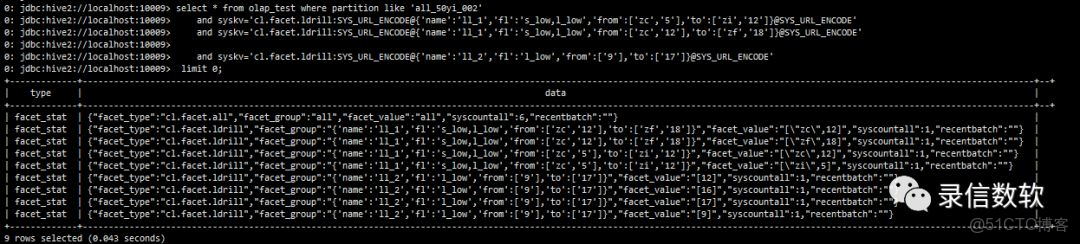
LSQL基於Lucene實現多列聯合索引機制,建立多個列之間的聯繫,在高緯值關係分析場景中大幅提升統計分析與top N排序性能,因多列數據連續存儲也可滿足大規模數據的快速導出。