核心原理
SHAP 的理論基礎來源於合作博弈論中的 Shapley 值。
在一個合作博弈中,有若干個參與者(玩家),他們通過合作獲得一個整體收益。Shapley 值用於衡量每個玩家對整體收益的平均邊際貢獻。
在機器學習中:
- 玩家對應於特徵;
- 整體收益對應於模型預測結果;
因此,Shapley 值可以度量每個特徵在所有可能的特徵組合中對預測結果的邊際貢獻。
Shapley 值的數學公式
對於一個特徵 ,其 Shapley 值 的計算公式如下
其中
- 表示所有特徵的集合。
- 表示不包含 的特徵子集
- 表示只使用特徵子集 進行預測的模型輸出;
- 表示當特徵 被添加到集合 中時,模型的預測值。
- 表示特徵 對模型輸出的邊際貢獻
- 是一個權重,這個係數代表:在所有特徵加入的 種排列中,有多少排列是使得集合 的所有特徵先於特徵 加入的概率。它確保了對邊際貢獻的平均計算
加性解釋模型
SHAP 將模型解釋成一個加性解釋模型
其中
- 是樣本 的實際模型預測值。
- 是基線值,通常是所有訓練樣本的平均預測值(即 ,其中 是數據集中隨機抽取的樣本)。
- 是特徵 的 SHAP 值,表示特徵 對預測值從基線值 變化到 的貢獻。
- 是特徵的總數。
實際應用中的挑戰
直接計算 Shapley 值的複雜度為 (M 為特徵數),對於高維特徵空間是不可行的。
因此,在實踐中,SHAP 提供了多種高效近似算法。
- Kernel SHAP
它使用加權線性迴歸近似原始 Shapley 值,適用於任意模型。 - Tree SHAP
專為決策樹、隨機森林、梯度提升機(如 XGBoost, LightGBM)設計。
它利用樹的結構,通過遍歷樹的路徑來高效地計算 Shapley 值,避免了對所有 個子集的評估。 - Deep SHAP
用於深度學習模型,利用梯度信息來近似 Shapley 值。
如何使用 SHAP 進行解釋
一旦計算出每個樣本的 SHAP 值,就可以進行兩種主要的解釋。
1.局部解釋(單個樣本)
Force Plot
直觀地展示每個特徵是如何將預測值從基準值推向最終預測值的。
- 紅色箭頭表示使預測值增加的特徵。
- 藍色箭頭表示使預測值降低的特徵。
2. 全局解釋(所有樣本)
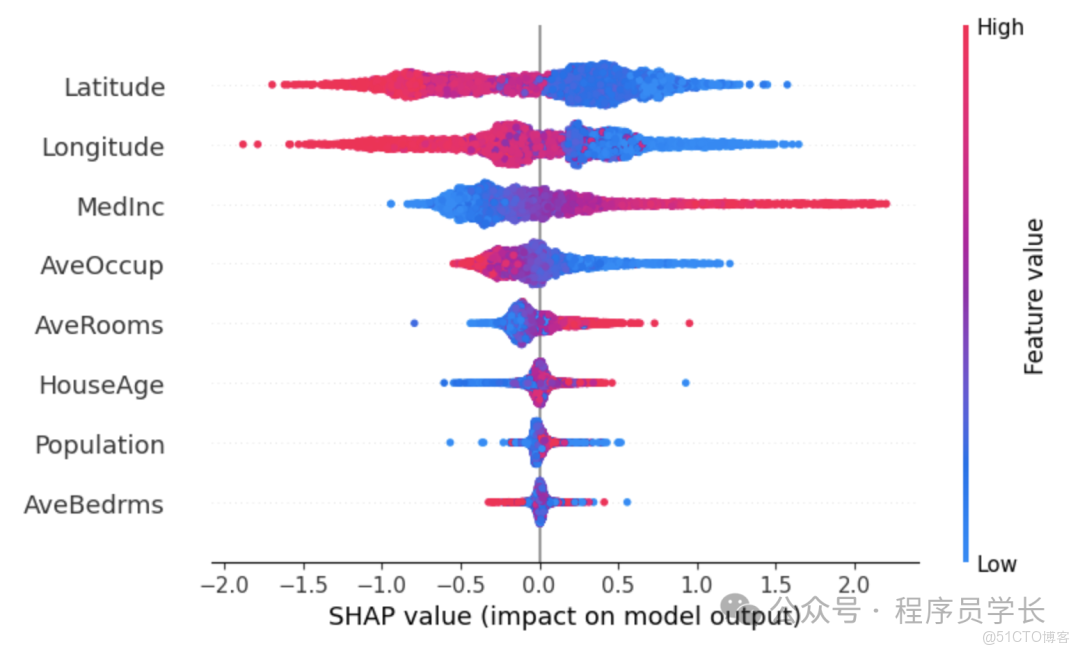
- 特徵重要性圖 Summary Plot
通過取所有樣本的 SHAP 值的絕對值平均來衡量特徵的全局重要性 - 特徵依賴圖 Dependence Plot
展示了單個特徵的 SHAP 值(即該特徵的邊際影響)如何隨着該特徵本身的數值變化而變化。
這有助於發現特徵與模型輸出之間的非線性關係。 - 交互作用圖 Interaction Plot
通過二階項分析,展示兩個特徵共同作用對模型輸出的影響。
案例分享
下面是一個使用 SHAP 分析機器學習模型(以 XGBoost 分類模型為例)的完整示例代碼。
該示例代碼包括模型訓練、SHAP 值計算與多種可視化圖形展示。
import xgboost
import shap
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加載加州房價數據集
data = fetch_california_housing()
X, y = data.data, data.target
feature_names = data.feature_names
# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 訓練XGBoost迴歸模型
model = xgboost.XGBRegressor(objective='reg:squarederror', n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 預測及評價
y_pred = model.predict(X_test)
print("測試集均方誤差:", mean_squared_error(y_test, y_pred))
# 初始化SHAP解釋器(TreeExplainer針對樹模型)
explainer = shap.TreeExplainer(model)
# 計算測試集樣本的SHAP值
shap_values = explainer.shap_values(X_test)可視化第一個測試樣本的SHAP值
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0,:], X_test[0,:], feature_names=feature_names)
畫整體特徵重要性條形圖
shap.summary_plot(shap_values, X_test, feature_names=feature_names)