

今天給大家介紹一個強大的算法模型,CNN
卷積神經網絡(CNN)是一類專門用於處理具有網格結構數據(如圖像、語音、視頻等) 的深度學習模型。
CNN 的設計靈感來自於生物學中的視覺皮層結構,能夠自動、有效地從原始數據中學習空間層次特徵,這極大地減少了人工特徵工程的需要。
CNN 已成為計算機視覺、語音識別、自然語言等領域的基礎模型。
核心原理
CNN的設計靈感來源於生物的視覺皮層,它通過模擬人眼識別圖像的過程,讓網絡能夠自動、有效地從原始數據中學習和提取空間特徵。其核心思想是局部感知、參數共享和層級特徵提取。
1.局部感知
傳統的全連接網絡在處理圖像時,會將圖像的所有像素點展平為一維向量,導致參數量巨大且丟失了像素間的空間關係。
CNN 借鑑了生物視覺系統,認為一個神經元不需要感知整個輸入圖像,只需要關注輸入的一個局部區域(即局部感知野)。
例如,在識別一張臉時,一個神經元可能只負責識別鼻子,另一個識別眼睛。
這極大地減少了需要訓練的參數數量,並能更好地捕捉局部特徵(如邊緣、角點、紋理)。
2.參數共享
對於一個特徵圖(Feature Map),它由一個卷積核掃描整個輸入圖像而得到。
在掃描過程中,同一個卷積核中的所有神經元共享同一組權重和偏置。
這大大減少了模型的參數數量(無論圖像有多大,只要卷積核的大小確定,所需要的參數量是固定的),降低了計算複雜度,並使模型具有平移不變性。
3.層級特徵提取
CNN 通常由多個卷積層、激活層、池化層堆疊而成。
- 淺層學習簡單的、局部的特徵,如邊緣、角點和紋理。
- 深層通過組合淺層特徵,學習更復雜、更抽象的語義特徵,如物體的部位或完整的物體。
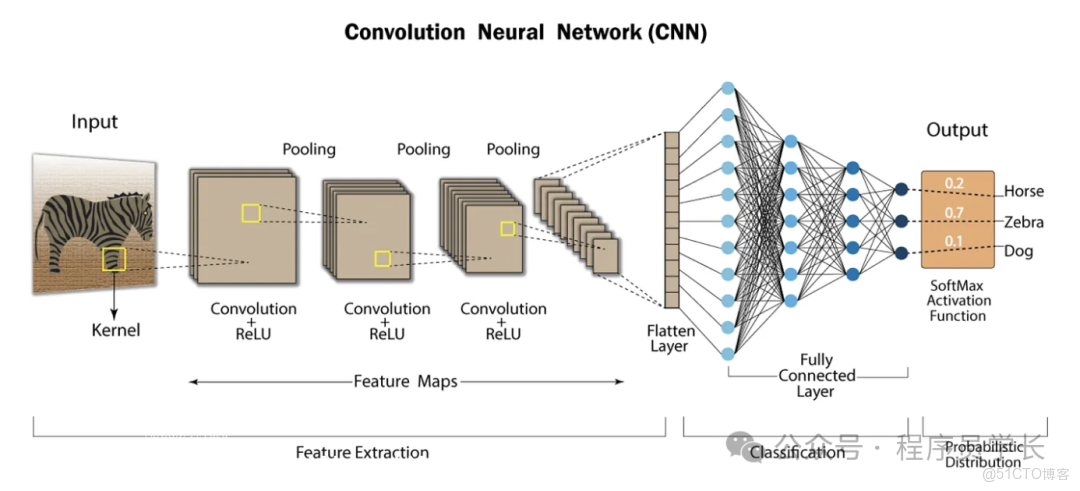
CNN 的架構
CNN 主要由以下幾個核心層組成:卷積層、激活函數層、池化層,以及全連接層。
1.卷積層
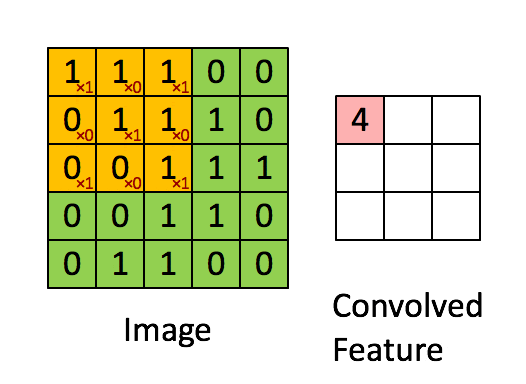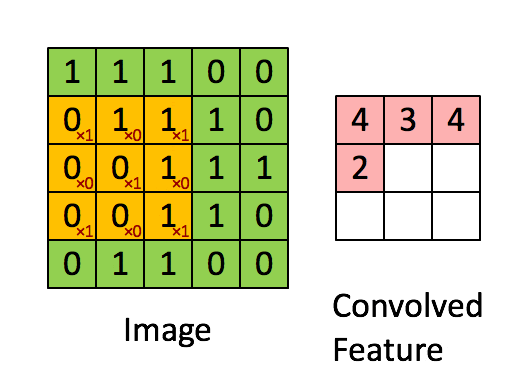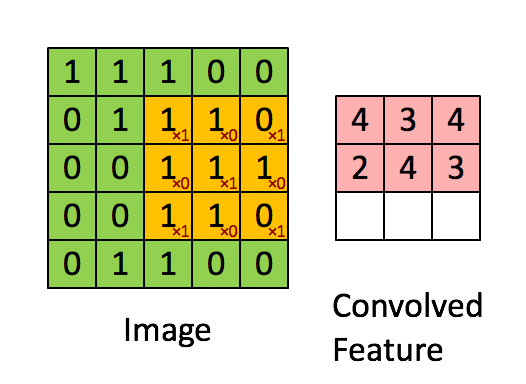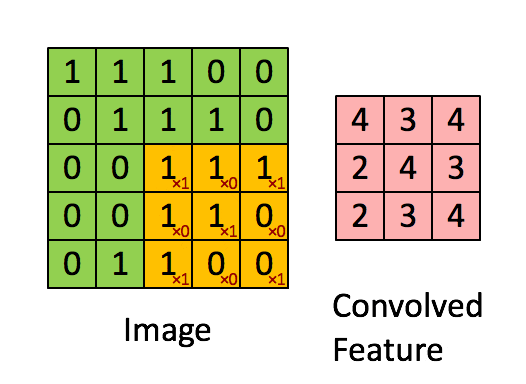
卷積層是 CNN 的核心。它通過在輸入數據上進行卷積操作來提取局部特徵。
卷積操作本質上是使用一個卷積核(或濾波器)在輸入數據(如圖像)上進行滑動,對局部區域執行點積運算,生成一個特徵圖。
一個卷積層通常有多個卷積核,每個卷積核提取輸入數據的不同類型的局部特徵(如邊緣、紋理、顏色等),從而生成多個特徵圖。
關鍵參數
- 卷積核大小:決定了局部感受野的大小(如 , )。
- 卷積核數量:決定了輸出特徵圖的數量。
- 步幅:卷積核在輸入上移動的步長。步幅越大,輸出的特徵圖尺寸越小。
- 填充:在輸入圖像邊緣周圍添加額外的像素(通常為 0)。常用於:
- 防止信息丟失(邊緣像素被多次卷積)。
- 保持輸出特徵圖的尺寸與輸入尺寸相同(稱為 "Same" Padding)。
2.激活函數層
在卷積操作之後,通常會引入一個非線性激活函數。
激活函數的作用是引入非線性,使得網絡可以學習和逼近任何複雜的函數,而不是僅僅是線性組合。
最常用的激活函數是 ReLU
3.池化層
池化層位於連續的卷積層之間,用於減小特徵圖的維度,減少計算量,並提高模型的魯棒性。
- 降維:減少特徵圖的空間尺寸,從而減少參數和計算量。
- 平移不變性增強:通過聚合局部區域的統計信息(如最大值),使得模型對輸入的小幅度平移具有更大的容忍度。
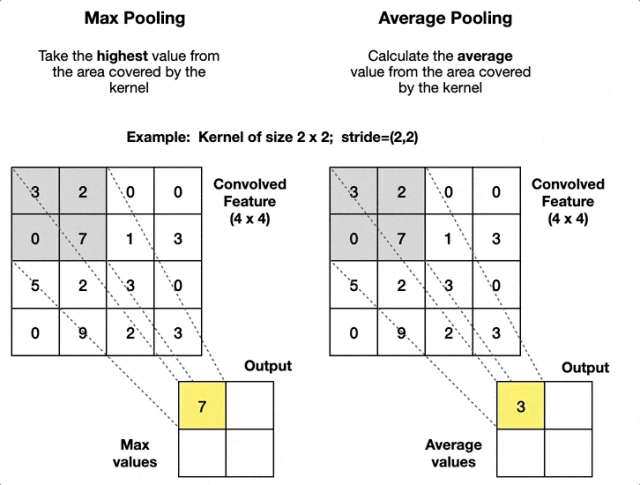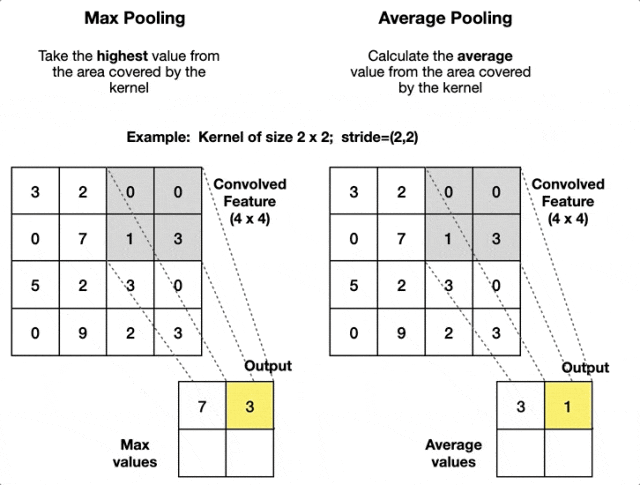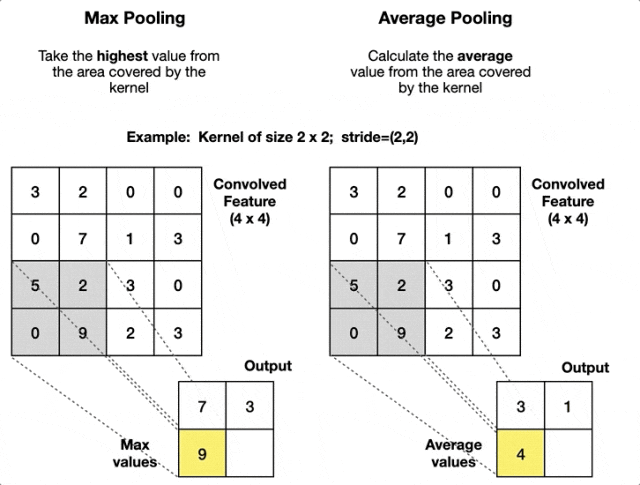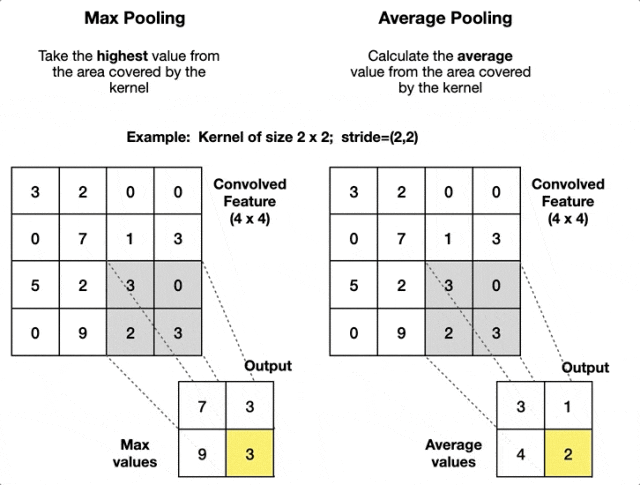
常見的池化操作有
- 最大池化:在局部區域內取最大值。這是最常用的池化方式,它能保留最顯著的特徵。
- 平均池化:在局部區域內取平均值。常用於網絡的更深層或作為輸出前的全局池化。
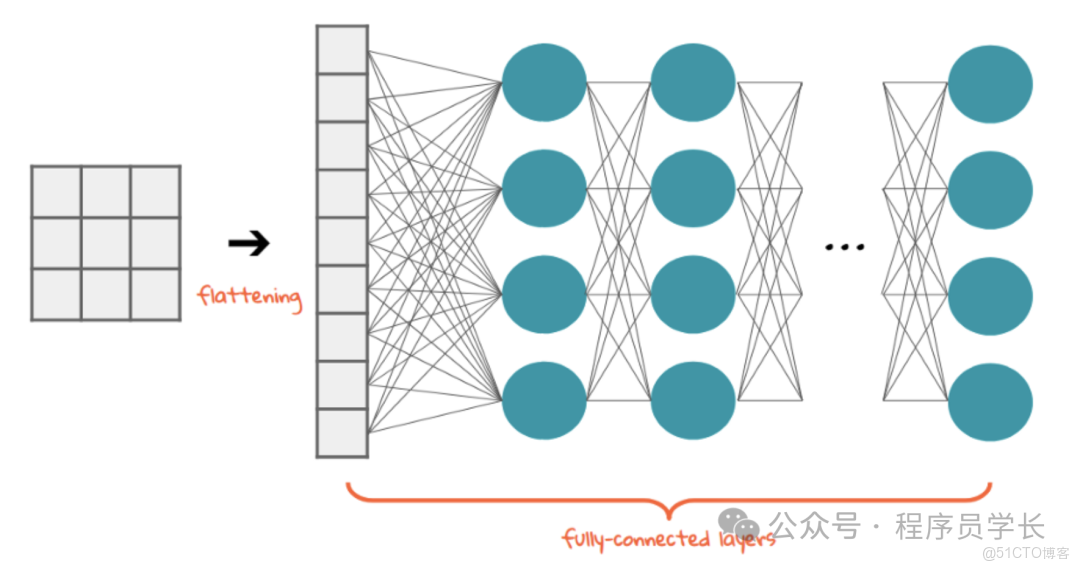
4. 全連接層
在經過多個卷積和池化層提取高級特徵後,特徵圖會被展平成一個向量,然後輸入到一個或多個全連接層。
全連接層將前面提取到的局部特徵整合起來,用於最終的分類或迴歸任務。
訓練過程
CNN 的訓練過程與傳統神經網絡類似,主要依賴於反向傳播算法和梯度下降算法。
- 前向傳播:輸入數據通過 CNN 得到輸出結果 。
- 計算損失:根據輸出結果 和真實標籤 計算損失函數 (例如交叉熵損失)。
- 反向傳播:利用鏈式法則計算損失函數 對每個權重 和偏置 的梯度 和 。
- 參數更新
使用優化器(如 Adam, SGD 等)根據梯度調整權重 。
CNN的優勢
- 參數量少:權值共享機制極大地減少了需要學習的參數數量,使得網絡更容易訓練,並減輕了過擬合的風險。
- 平移不變性: 能夠識別圖像中特徵的位置變化,增強了模型的魯棒性。
- 層次化特徵提取:淺層學習簡單的特徵(如邊緣),深層逐漸組合這些簡單特徵,學習更復雜、抽象的語義特徵。
案例分享
下面是一個使用 PyTorch 實現卷積神經網絡(CNN)進行手寫數字識別(MNIST 數據集)的完整示例代碼。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# --- 1. 數據加載與預處理 ---
# 定義數據轉換:轉換為Tensor並進行標準化
transform = transforms.Compose([
transforms.ToTensor(), # 將PIL Image或numpy.ndarray轉換為FloatTensor. HWC to CHW
transforms.Normalize((0.1307,), (0.3081,)) # 對圖像進行標準化,平均值為0.1307,標準差為0.3081 (MNIST數據集的統計值)
])
# 下載並加載MNIST訓練集
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 下載並加載MNIST測試集
test_dataset = datasets.MNIST('./data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)
print("MNIST 數據集加載完成。")
# --- 2. CNN 模型定義 ---
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一個卷積層
# 輸入通道為1 (灰度圖像), 輸出通道為32, 卷積核大小為3x3
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
# 批量歸一化層,可以加速訓練並提高穩定性
self.bn1 = nn.BatchNorm2d(32)
# 第二個卷積層
# 輸入通道為32, 輸出通道為64, 卷積核大小為3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
# 最大池化層,窗口大小為2x2,步長為2
self.pool = nn.MaxPool2d(2, 2)
# Dropout層,用於防止過擬合
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
# 全連接層
# 經過兩個conv+pool後,圖像尺寸從28x28變為7x7
# 64個特徵圖,每個7x7
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10) # 10個輸出類別 (0-9)
def forward(self, x):
# 輸入x: [batch_size, 1, 28, 28]
# Conv1 -> BN -> ReLU -> Pool
x = self.pool(torch.relu(self.bn1(self.conv1(x))))
# x: [batch_size, 32, 14, 14]
# Conv2 -> BN -> ReLU -> Pool
x = self.pool(torch.relu(self.bn2(self.conv2(x))))
# x: [batch_size, 64, 7, 7]
# Flatten 操作,將特徵圖展平為一維向量
x = x.view(-1, 64 * 7 * 7) # -1 表示自動計算batch_size
# x: [batch_size, 64*7*7]
# Dropout -> FC1 -> ReLU -> Dropout -> FC2
x = self.dropout1(x)
x = torch.relu(self.fc1(x))
x = self.dropout2(x)
x = self.fc2(x)
# x: [batch_size, 10]
return x
# 實例化模型
model = SimpleCNN()
print("\nCNN 模型結構:\n", model)
# 定義損失函數和優化器
criterion = nn.CrossEntropyLoss() # 交叉熵損失適用於多分類問題
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam優化器
# 檢查是否有GPU可用,並選擇設備
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
model.to(device)
print(f"\n模型將運行在 {device} 上。")
# --- 3. 訓練過程 ---
num_epochs = 10
train_losses = []
test_accuracies = []
print("\n開始訓練...")
for epoch in range(num_epochs):
model.train() # 設置模型為訓練模式
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 將數據移動到指定設備
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向傳播
loss = criterion(output, target) # 計算損失
loss.backward() # 反向傳播
optimizer.step() # 更新權重
running_loss += loss.item()
avg_train_loss = running_loss / len(train_loader)
train_losses.append(avg_train_loss)
# 在每個epoch結束後進行測試
model.eval() # 設置模型為評估模式 (關閉Dropout等)
correct = 0
total = 0
with torch.no_grad(): # 不計算梯度,節省內存和計算
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, 1) # 獲取最大概率對應的類別
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
test_accuracies.append(accuracy)
print(f"Epoch {epoch+1}/{num_epochs}, "
f"Train Loss: {avg_train_loss:.4f}, "
f"Test Accuracy: {accuracy:.2f}%")
print("\n訓練完成!")
# --- 4. 測試與結果可視化 ---
print("\n開始進行最終測試結果可視化...")
model.eval() # 設置模型為評估模式
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples) # 獲取一個批次的測試數據
with torch.no_grad():
example_data = example_data.to(device)
output = model(example_data)
_, predicted_labels = torch.max(output.data, 1)
# 將圖像和標籤從CUDA移回CPU進行可視化
example_data_cpu = example_data.cpu()
predicted_labels_cpu = predicted_labels.cpu()
example_targets_cpu = example_targets.cpu()
fig = plt.figure(figsize=(12, 8))
# 選取前12張圖片進行展示
for i in range(12):
plt.subplot(3, 4, i+1)
plt.tight_layout()
# 圖像反標準化,以便正確顯示
# 注意:這裏我們做的是一個近似的反標準化,因為原始標準化的均值和方差是針對整個數據集的
# 對於單張圖片,簡單乘以0.3081並加上0.1307可能無法完全還原到0-1範圍
# 但對於可視化,通常直接顯示歸一化後的圖像也是可以接受的
img = example_data_cpu[i][0] * 0.3081 + 0.1307
plt.imshow(img, cmap='gray', interpolation='none')
plt.title(f"Pred: {predicted_labels_cpu[i].item()}\nTrue: {example_targets_cpu[i].item()}")
plt.xticks([])
plt.yticks([])
plt.suptitle("手寫數字識別結果示例", fontsize=16)
plt.show()
# 繪製訓練損失和測試準確率曲線
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, label='Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss per Epoch')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), test_accuracies, label='Test Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Test Accuracy per Epoch')
plt.legend()
plt.grid(True)
plt.show()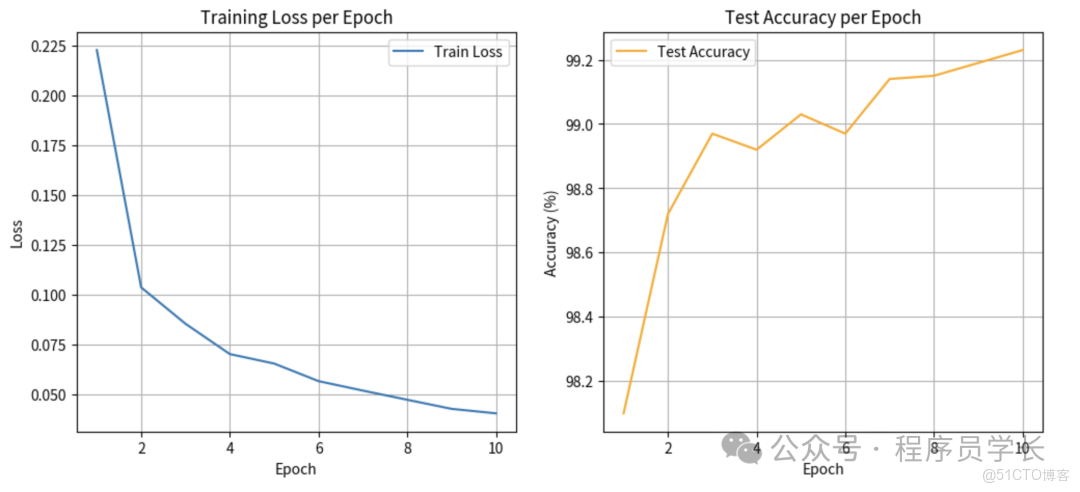
最後