

作者:Gal Krispel
翻譯:黃鵬程 阿里雲實時計算 Flink 版產品負責人
閲讀時間:11分鐘 · 2025年10月19日
譯者注:
本博客文章探討了 Apache Flink 中的混合 API 方法如何幫助克服 Flink SQL 的一些固有限制,特別是在與 Apache Kafka 集成時。文章深入探討了兩個常見挑戰:
- 對格式錯誤記錄的有效錯誤處理;
- Avro 的 Enum 和 TimestampMicros 類型在數據類型映射方面的限制。
DataStream API 和 ProcessFunction API 憑藉其更底層的控制能力,可用於強大的模式驗證和死信隊列(DLQ)實現。這種預處理步驟通過優雅地處理損壞的記錄而不導致應用程序重啓,保護了輸入 Flink SQL 的數據完整性。
此外,Flink SQL 的數據類型映射問題可以通過將 Flink Table 轉換回DataStream<GenericRecord> 並應用自定義 RichMapFunction 來緩解。這允許對序列化進行精確控制,從而在將數據寫回 Kafka 時正確處理 Avro Enum 和 TimestampMicros 類型。
雖然 Flink SQL 提供了高度聲明性和用户友好的接口,但將其與 DataStream API 的細粒度控制相結合,為複雜的現實世界流式挑戰提供了強大而靈活的解決方案。鼓勵 Flink 用户考慮如何在應用程序中戰略性地切換這些 API,以解鎖更大的健壯性、靈活性和控制力,從而構建更具彈性和功能豐富的數據管道。
Apache Flink 是一個強大的數據處理框架,它提供了一個高吞吐量、低延遲的運行時環境,能夠以統一的方式處理無界流數據和有界批數據。Flink 提供了多種 API,從類似 SQL 的聲明式接口到基於操作符的底層接口,使團隊能夠構建從實時分析管道到事件驅動應用程序的各種應用,並精確控制所需的功能級別。
Apache Flink 提供了多種實現作業的接口。最受歡迎的接口是 DataStream API,這是一種用於流作業的命令式、底層接口,可對操作符、狀態、序列化和錯誤處理提供強有力的控制。它還提供了插入自定義連接器的能力,以進一步提高靈活性,從而擴展了社區支持的開源連接器的種類。
第二個流行的接口是 Flink SQL(由 Table API 驅動),這是一種更高級別的聲明式語法,允許用户使用 ANSI 標準 SQL語法定義數據處理管道。眾多連接器支持 Table API,大大簡化了編寫數據處理作業複雜代碼的開銷。這一特性被技術背景較弱的用户或不需要掌握 Apache Flink 專業知識的自助服務場景廣泛採用。假設每個業務利益相關者都對 Apache Flink 有超出基本水平的理解,那麼 Flink SQL 可能就不會像今天這樣被廣泛採用。然而,現實中並非如此,其聲明式語法和易用性使其對沒有軟件工程背景的數據分析專業人員特別有吸引力。如前所述,它也可用於自助服務場景。
使用Flink SQL的隱藏陷阱
對於流式用例,一個流行的選擇是將 Table API 與 Apache Kafka 結合使用,並採用 avro-confluent 格式以確保嚴格的模式保證。Confluent Schema Registry 確保了減少的有效載荷大小、模式一致性和兼容性,以及用於與註冊表交互的簡單 REST 接口。
Flink SQL 為原生流式 Kafka Consumer & Producer 流程或 Kafka Streams 應用程序提供了一種簡單的替代方案。這些應用程序從主題讀取流數據,通過連接、過濾、聚合和窗口等數據操作對其進行處理,然後將輸出生成到另一個流中進行進一步處理。這些應用程序帶有技術和操作開銷——它們需要對 Apache Kafka 有深入的理解,並處理應用程序狀態優化。
與編寫完整的 Kafka Streams 應用程序相比,Flink SQL 接口允許您以聲明方式定義管道,就像使用 SQL 一樣。雖然這聽起來很理想,但生產用例往往會達不到這種期望。
將 Flink SQL 與 Apache Kafka 結合使用的兩個常見挑戰是:
1. 缺乏有效的錯誤處理模式,例如死信隊列(DLQ)。在 Apache Kafka 主題中處理模式不兼容記錄的情況並不少見,因為模式兼容性沒有被強制執行,或者僅僅是因為生產者應用程序的 bug 導致為主題生成了錯誤的模式。當 Table API 消費者遇到由於故障記錄導致的反序列化錯誤時,它會立即使用快速失敗策略並重啓應用程序。不幸的是,這種策略在處理壞記錄時是無效的,因為它在設置"avro"或"confluent-avro"格式時無法跳過故障記錄。應用程序將陷入重啓模式,手動干預是唯一能從這種情況中恢復的方法。由於 Kafka 連接器中的 Avro 反序列化不支持 skip-on-error 標誌,Flink SQL 缺乏任何真正的錯誤處理選項。
2. 數據類型映射限制,因為 Flink SQL 類型可能無法精確表示原生 Avro 類型。Flink SQL 的一個顯著限制是 Enum 類型處理——所有 Enum 字段都被解釋為字符串。從處理端來看,Enum 字段與 String 字段無法區分是有道理的,但在嘗試將該字段作為 Enum 類型重新生成到 Apache Kafka 時會產生序列化錯誤,因為 Flink SQL 中沒有官方支持 Enum 數據類型。Avro LogicalType 的 TimestampMicros 也存在類似問題,因為 Flink SQL 不支持按原樣讀寫 timestamp 字段,而只能作為 BIGINT。
混合接口方法
如前所述,由於 DataStream API 和 ProcessFunction API 的底層特性,它們比 Flink SQL 接口具有更豐富的功能集。同時,Flink SQL 接口對於沒有深入瞭解 Apache Flink 的用户來説更加友好和易於使用。在 Apache Flink 運行時中,可以在兩種 API 之間切換,這在通用應用程序中是有意義的。
想象一個提供自助服務的應用程序,該應用程序的用户輸入將是基於 Table API 的 SQL 進行數據處理,而接收器連接器將使用 DataStream API 或 ProcessFunction API 進行優化寫入目標。甚至可能存在來回切換API的用例。
在下面的部分中,將提供一個如何將 Table API 與底層 API 的更深層次功能相結合的演練,例如使用 RichMapFunction 實時轉換記錄以克服 Enum 序列化問題,以及使用 ProcessFunction 處理壞記錄並將其轉移到側輸出。
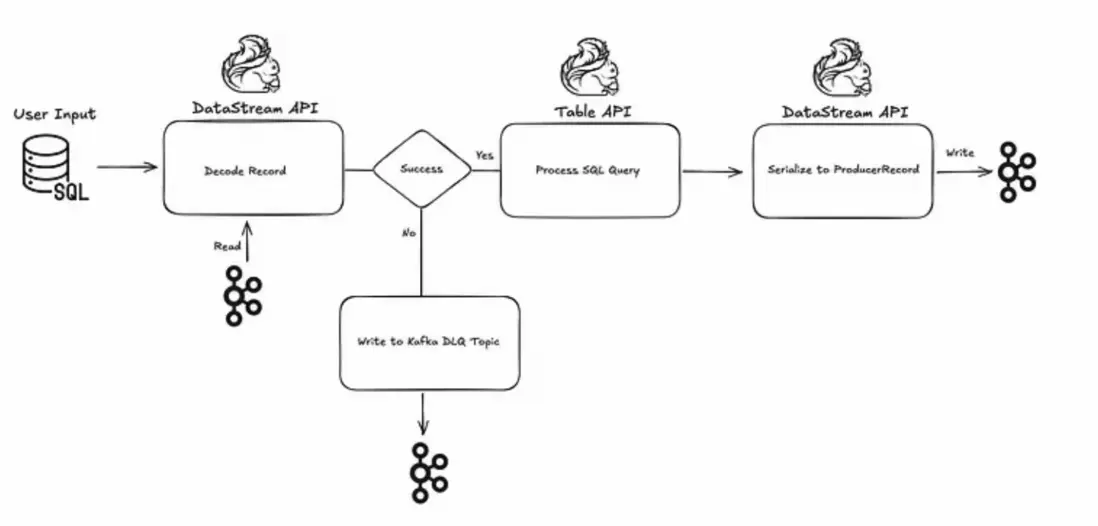
在Flink SQL之前驗證模式:DLQ的底層API方法
Flink SQL 允許用户以聲明方式處理數據。雖然運行時數據處理錯誤不是典型場景,但在 SQL 處理步驟之前的模式反序列化階段經常會遇到格式錯誤的記錄。初步的 Kafka 源流將確保正確編碼數據的已驗證流,其中壞記錄不會被跳過,而是被轉移到側 Kafka 主題,這是流應用程序中眾所周知的錯誤處理模式。正確編碼記錄的已驗證流將被轉換為 Table API 進行 SQL 處理。同時,DLQ Kafka 主題將用於存放不兼容或故障記錄,而不會對主處理流造成任何運行時異常。
第一步是為驗證流設置 Kafka 源連接器。它應該以最原始的形式接收記錄,即字節數組,無需事先反序列化。
package com.example.flink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class KafkaSourceFactory {
public static KafkaSource<ConsumerRecord<byte[], byte[]>> createRawBytesSource(
String bootstrapServers, String topic, String groupId) {
return KafkaSource.<ConsumerRecord<byte[], byte[]>>builder()
.setBootstrapServers(bootstrapServers)
.setTopics(topic)
.setGroupId(groupId)
.setDeserializer(new RawBytesDeserializer())
.build();
}
}RawBytesDeserializer 的實現非常簡單,如下所示:
public class RawBytesDeserializer implements KafkaRecordDeserializationSchema<ConsumerRecord<byte[], byte[]>> {
@Override
public void deserialize(org.apache.kafka.clients.consumer.ConsumerRecord<byte[], byte[]> record, Collector<ConsumerRecord<byte[], byte[]>> out) {
out.collect(record);
}
@Override
public TypeInformation<ConsumerRecord<byte[], byte[]>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<byte[], byte[]>>(){});
}
}此外,必須為壞記錄的 DLQ 輸出設置 Kafka 接收器連接器。
package com.example.flink;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class DLQKafkaSinkFactory {
public static KafkaSink<ConsumerRecord<byte[], byte[]>> createDLQSink(
String bootstrapServers, String dlqTopic) {
return KafkaSink.<ConsumerRecord<byte[], byte[]>>builder()
.setBootstrapServers(bootstrapServers)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setRecordSerializer(new DlqRecordSerializer(dlqTopic))
.build();
}
}DlqRecordSerializer 是一個簡單的 Kafka 記錄序列化器,它將壞記錄作為原始字節數組生成到 DLQ 主題。
public class DlqRecordSerializer implements KafkaRecordSerializationSchema<ConsumerRecord<byte[], byte[]>> {
private final String topic;
public DlqRecordSerializer(String topic) {
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(ConsumerRecord<byte[], byte[]> element, KafkaSinkContext context, Long timestamp) {
return new ProducerRecord<>(topic, null, null, element.key(), element.value(), element.headers());
}
}ProcessFunction 將確定記錄是否正確編碼。如果驗證失敗,故障記錄將被標記並轉移到 DLQ 輸出接收器。
package com.example.flink;
import org.apache.avro.generic.GenericRecord;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.formats.avro.registry.confluent.ConfluentRegistryAvroDeserializationSchema;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SchemaValidationFunction extends ProcessFunction<ConsumerRecord<byte[], byte[]>, Tuple2<String, GenericRecord>> {
private static final OutputTag<ConsumerRecord<byte[], byte[]>> DLQ_TAG = new OutputTag<>("dlq-output") {};
private final boolean dlqEnabled;
private final ConfluentRegistryAvroDeserializationSchema<GenericRecord> deserializer;
public SchemaValidationFunction(
boolean dlqEnabled,
ConfluentRegistryAvroDeserializationSchema<GenericRecord> deserializer) {
this.dlqEnabled = dlqEnabled;
this.deserializer = deserializer;
}
@Override
public void processElement(
ConsumerRecord<byte[], byte[]> record,
Context ctx,
Collector<Tuple2<String, GenericRecord>> out) throws Exception {
try {
GenericRecord value = deserializer.deserialize(record.value());
if (value == null) throw new RuntimeException("null after deserialization");
String key = record.key() == null ? null : new String(record.key());
out.collect(Tuple2.of(key, value));
} catch (Exception e) {
if (dlqEnabled) {
ctx.output(DLQ_TAG, record);
} else {
throw e;
}
}
}
public static OutputTag<ConsumerRecord<byte[], byte[]>> getDlqTag() {
return DLQ_TAG;
}
}上述資源將在主流作業中初始化。下面是一個示例應用程序,它使用 DataStream 讀取 Kafka 主題,驗證 Avro 編碼,然後將已驗證的記錄發送到下游進行進一步的 SQL 處理。故障記錄將生成到 DLQ 主題。
// 獲取輸入Avro模式並設置反序列化器和轉換器
org.apache.avro.Schema avroSchema = schemaManager.fetchSchema(subject, version);
ConfluentRegistryAvroDeserializationSchema<GenericRecord> deserializer =
ConfluentRegistryAvroDeserializationSchema.forGeneric(avroSchema, registryUrl);
RowType rowType = (RowType) AvroSchemaConverter.convertToDataType(avroSchema.toString()).getLogicalType();
AvroToRowDataConverters.AvroToRowDataConverter converter = AvroToRowDataConverters.createRowConverter(rowType);
// 使用DataStream API讀取原始消息
KafkaSource<ConsumerRecord<byte[], byte[]>> kafkaSource = KafkaSourceFactory.createRawBytesSource(props);
DataStream<ConsumerRecord<byte[], byte[]>> rawStream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source");
TypeInformation<Tuple2<String, GenericRecord>> sourceTupleTypeInfo =
new TupleTypeInfo<>(TypeInformation.of(String.class), new GenericRecordAvroTypeInfo(avroSchema));
// 為已驗證記錄設置已驗證流
SingleOutputStreamOperator<Tuple2<String, GenericRecord>> validatedRecordStream = rawStream
.process(new SchemaValidationFunction(dlqEnabled, deserializer))
.returns(sourceTupleTypeInfo);
// 如果啓用,則創建DLQ接收器
if (dlqEnabled && !dlqTopic.isEmpty()) {
DataStream<ConsumerRecord<byte[], byte[]>> dlqStream = validatedRecordStream.getSideOutput(SchemaValidationFunction.getDlqTag());
KafkaSink<ConsumerRecord<byte[], byte[]>> dlqSink = DLQKafkaSinkFactory.createDLQSink(props, dlqTopic);
dlqStream.sinkTo(dlqSink);
}
// 準備表環境基礎表結構
RowType originalRowType = (RowType) AvroSchemaConverter.convertToDataType(avroSchema.toString()).getLogicalType();
// 操作已驗證流以包含元數據,保留鍵以供上下文使用(當前未使用)
DataStream<RowData> rowStreamWithMetadata = validatedRecordStream
.map(tuple -> (RowData) converter.convert(tuple.f1))
.returns(InternalTypeInfo.of(originalRowType));
// 定義表的模式
Schema.Builder schemaBuilder = Schema.newBuilder();
schemaBuilder.fromRowDataType(AvroSchemaConverter.convertToDataType(inputAvroSchema.toString()));
// 將DataStream註冊為具有avro模式的表
Table t = tableEnv.fromDataStream(rowStreamWithMetadata, schemaBuilder.build());
tableEnv.createTemporaryView("InputTable", t);
// 處理SQL查詢
tableEnv.sqlQuery(sqlQuery);提供的代碼片段展示瞭如何有效地結合底層 API 進行強大的模式驗證和 DLQ 錯誤處理,以及 Flink SQL 的聲明式優勢進行後續數據處理。
未來工作
使用 DataStream API 克服 Flink SQL 數據類型映射限制
Table API 可以實現用户的 Flink SQL 查詢並將其接收到底層各種接收器連接器中,包括 Apache Kafka。然而,如上所述,它在數據類型映射方面有一些限制:
- Enum 類型被轉換為 String
- Flink SQL 不支持精度高於3(毫秒)的 TIMESTAMP
這可能會非常令人沮喪。通常,用户的意圖是讓 Apache Flink 使用現有模式,而不是讓它自己註冊模式。如果有技術要求阻止 Apache Flink 註冊模式,那麼所有帶有 TimestampMicros 或 Enum 的模式都無法寫入 Apache Kafka 接收器主題,這使得它們在 Flink SQL 中實際上不受支持。
雖然 Enum 數據類型和 TimestampMicros Avro 類型在 Flink SQL 中不受支持,但它們在 DataStream API 中完全受支持,當將 GenericRecord 或 SpecificRecord 寫回 Kafka 時。
之前展示了一個如何將 DataStream 轉換為 Flink Table 以確保有效數據在 Flink SQL 中處理的示例。要克服這個問題,必須進行相反的轉換——將 Flink Table 轉換回 DataStream<GenericRecord> 並將其接收至 Kafka。
從 TableAPI 切換到 DataStream 很簡單,可以通過 toDataStream 完成。然而,這種轉換將產生 DataStream<Row>,這是一種與將 Avro 編碼記錄寫入 Kafka 不兼容的格式。需要應用用户定義函數來執行從 DataStream<Row> 到 DataStream<GenericRecord> 的轉換。在該函數中,將應用自定義代碼將數據寫回 Kafka,包括 Flink SQL 不支持的字段,如 Enum 或 TimestampMicros。
下面是如何為原始類型、Enum 和 Timestamp 編寫從 Row 到 GenericRecord 的映射器的示例(擴展映射器以支持您的模式選擇;下面的示例處理特定情況和一般基本原語)。
class AvroRowMapper extends RichMapFunction<Row, GenericRecord> {
private final String schemaString;
AvroRowMapper(String schemaString) {
this.schemaString = schemaString;
}
@Override
public GenericRecord map(Row row) {
org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(schemaString);
GenericRecord rec = new GenericData.Record(schema);
for (org.apache.avro.Schema.Field f : schema.getFields()) {
String name = f.name();
Object v = row.getField(name);
org.apache.avro.Schema fs = unwrapNullable(f.schema());
if (v == null) {
rec.put(name, null);
continue;
}
String logical = fs.getProp("logicalType");
if ("timestamp-micros".equals(logical)) {
rec.put(name, toEpochMicros(v));
continue;
} else if ("timestamp-millis".equals(logical)) {
rec.put(name, toEpochMillis(v));
continue;
}
switch (fs.getType()) {
case STRING:
rec.put(name, v.toString());
break;
case BOOLEAN:
rec.put(name, (Boolean) v);
break;
case INT:
rec.put(name, ((Number) v).intValue());
break;
case LONG:
rec.put(name, ((Number) v).longValue());
break;
case FLOAT:
rec.put(name, ((Number) v).floatValue());
break;
case DOUBLE:
rec.put(name, ((Number) v).doubleValue());
break;
case BYTES:
if (v instanceof byte[])
rec.put(name, java.nio.ByteBuffer.wrap((byte[]) v));
else
rec.put(name, v);
break;
case ENUM:
rec.put(name, new GenericData.EnumSymbol(fs, v.toString()));
break;
default:
rec.put(name, v);
}
}
return rec;
}
private static long toEpochMillis(Object v) {
if (v instanceof java.time.LocalDateTime) {
return ((java.time.LocalDateTime) v).toInstant(java.time.ZoneOffset.UTC).toEpochMilli();
} else if (v instanceof java.time.Instant) {
return ((java.time.Instant) v).toEpochMilli();
} else if (v instanceof Number) {
return ((Number) v).longValue();
}
throw new IllegalArgumentException("Unsupported timestamp-millis value: " + v);
}
private static long toEpochMicros(Object v) {
if (v instanceof java.time.LocalDateTime) {
long millis = ((java.time.LocalDateTime) v).toInstant(java.time.ZoneOffset.UTC).toEpochMilli();
return millis * 1_000L;
} else if (v instanceof java.time.Instant) {
long millis = ((java.time.Instant) v).toEpochMilli();
return millis * 1_000L;
} else if (v instanceof Number) {
return ((Number) v).longValue();
}
throw new IllegalArgumentException("Unsupported timestamp-micros value: " + v);
}
private static org.apache.avro.Schema unwrapNullable(org.apache.avro.Schema s) {
if (s.getType() == org.apache.avro.Schema.Type.UNION) {
for (org.apache.avro.Schema t : s.getTypes()) {
if (t.getType() != org.apache.avro.Schema.Type.NULL)
return t;
}
}
return s;
}
}創建一個 Kafka 接收器,將記錄作為 Avro 編碼消息返回到 Kafka。
package com.example.flink.sink;
import org.apache.avro.generic.GenericRecord;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.formats.avro.registry.confluent.ConfluentRegistryAvroSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
public class KafkaSinkFactory {
public static KafkaSink<GenericRecord> createKafkaSink(
String bootstrapServers,
String topic,
String subject,
org.apache.avro.Schema schema,
String schemaRegistryUrl) {
return KafkaSink.<GenericRecord>builder()
.setBootstrapServers(bootstrapServers)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setRecordSerializer(
KafkaRecordSerializationSchema.builder()
.setTopic(topic)
.setValueSerializationSchema(
ConfluentRegistryAvroSerializationSchema.forGeneric(
subject, schema, schemaRegistryUrl
)
)
.build()
)
.build();
}
}預定義的映射函數可在主應用程序中如下使用:
// 將Table轉換為Row流
DataStream<Row> rows = tableEnv.toDataStream(result);
// 使用上面的最小映射器將行映射到GenericRecord
String avroSchemaString = /* your Avro schema JSON */;
DataStream<GenericRecord> records = rows.map(new AvroRowMapper(avroSchemaString))
.returns(new GenericRecordAvroTypeInfo(outputSchema));
// 構建一個將GenericRecord與Confluent Avro一起寫入的Kafka接收器
KafkaSink<GenericRecord> sink = KafkaSinkFactory(bootstrapServers,topic,subject,outputSchema,registryUrl)
// 發送它
records.sinkTo(sink);