

一、前言
有人丟給你下面這張圖,如果你能清楚地説明它們之間的關係以及用途,那麼你對字符編碼的理解肯定過關了。
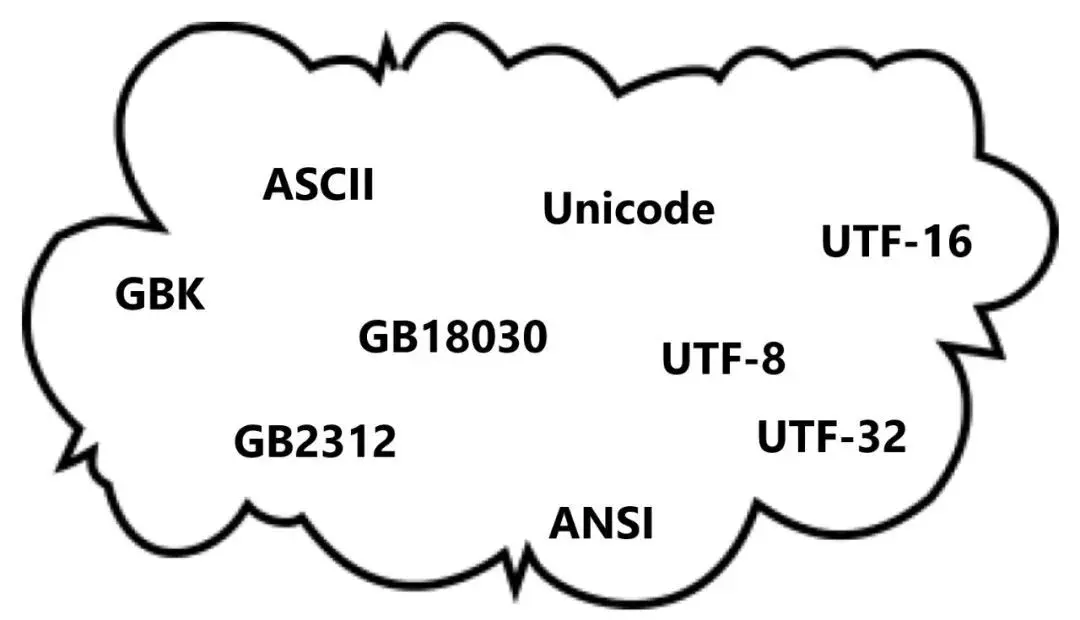
不知道看了上面這張圖,是否有混亂的感覺,本文試着給你梳理、講透這些孤立的幾個單詞之間聯繫......
二、關於字符編碼,你所需要知道的
2.1 ASCII(寡頭壟斷時期)
計算機內部,所有信息最終都是一個二進制值。每一個二進制位(bit)有0和1兩種狀態,8個二進制位稱之為1個字節。把鍵盤上(如下圖)所有按鍵的狀態。

用8位二進制共256種表示綽綽有餘。把所有的空格、標點符號、數字、大小寫字母分別用連續的字節狀態表示,一直編到了第127號,這樣計算機利用8位二進制位(1個字節)就可以用來存儲英語的文字了,這就是大名鼎鼎的ASCII(美國信息互換標準代碼)。當時世界上所有的計算機都用同樣的ASCII方案來保存英文文字。
2.2 非 ASCII 編碼(漢字編碼的發展)
伴隨着互聯網的興起,計算機技術的發展,世界各地都開始使用計算機,但是很多國家用的不是英文,所適用的字母裏有許多是ASCII裏沒有的。
為了可以在計算機保存他們的文字,決定採用 127號之後的空位來表示這些新的字母、符號,還加入了很多畫表格時需要用下到的橫線、豎線、交叉等形狀,一直把序號編到了最後一個狀態255。
從128 到255這一頁的字符集被稱“擴展字符集”。此之後,貪婪的人類再沒有新的狀態可以用了。
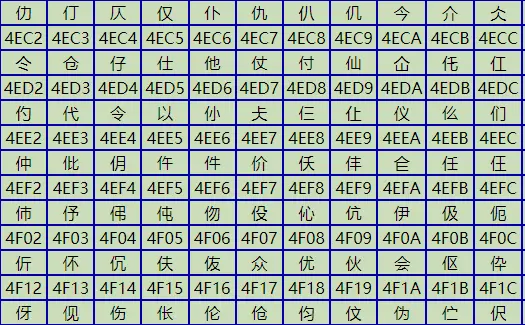
隨着計算機在中國流行時,已經沒有可以利用的字節狀態來表示漢字,況且有6000多個常用漢字需要保存。但這難不倒智慧的中國人民,我們就把那些127號之後的奇異符號們直接取消掉,並規定:一個小於127的字符的意義與原來相同,但兩個大於127的字符連在一起時,就表示一個漢字,前面的一個字節(他稱之為高字節)從0xA1用到0xF7,後面一個字節(低字節)從0xA1到0xFE,這樣我們就可以組合出大約7000多個簡體漢字了。
在這些編碼裏,我們還把數學符號、羅馬希臘的字母都編進去了,連在 ASCII 裏本來就有的數字、標點、字母都統統重新編了兩個字節長的編碼,這就是常説的”全角”字符。而原來在127號以下的那些就叫”半角”字符了。中國人民看到這樣很不錯,於是就把這種漢字方案叫做 “GB2312”。GB2312 是對 ASCII 的中文擴展。
(圖片來源於網絡)
但是中國的漢字太多了,我們很快就就發現有許多人的人名沒有辦法在這裏打出來。我們不得不繼續把GB2312 沒有用到的碼位找出來老實不客氣地用上。後來還是不夠用,於是乾脆不再要求低字節一定是127號之後的內碼,只要第一個字節是大於127就固定表示這是一個漢字的開始,不管後面跟的是不是擴展字符集裏的內容。
結果擴展之後的編碼方案被稱為 GBK 標準,GBK包括了**GB2312 **的所有內容,同時又增加了近20000個新的漢字(包括繁體字)和符號。後來少數民族也要用電腦了,於是我們再擴展,又加了幾千個新的少數民族的字,GBK擴成了 GB18030。
2.3 非 ASCII 編碼
百花齊放,各自編碼標準帶來的問題
當時各個國家都像中國這樣搞出一套自己的編碼標準,結果互相之間誰也不懂誰的編碼,誰也不支持別人的編碼,就連大陸和台灣這樣只相隔了150海里,使用着同一種語言,也分別採用了不同的 DBCS 編碼方案。
當時的中國人想讓電腦顯示漢字,就必須裝上一個“漢字系統”,專門用來處理漢字的顯示、輸入的問題,像是那個台灣的愚昧封建人士寫的算命程序就必須加裝另一套支持 BIG5。
編碼的什麼“倚天漢字系統”才可以用,裝錯了字符系統,顯示就會亂了套!這怎麼辦?
而且世界民族之林中還有那些一時用不上電腦的窮苦人民,他們的文字又怎麼辦?
(圖片來源於維基百科)
2.4 Unicode
世界這麼亂,得我來管管,大一統時期
ISO(國際標誰化組織)的國際組織決定着手解決這個問題。採用的方法很簡單:廢了所有的地區性編碼方案,重新搞一個包括了地球上所有文化、所有字母和符號的編碼!
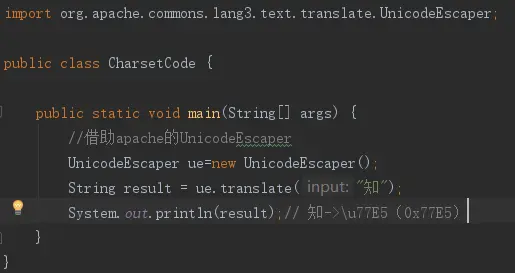
他們打算叫它“Universal Multiple-Octet Coded Character Set”,簡稱UCS, 俗稱 “Unicode”。Unicode相當於一個抽象層,給每個字符一個唯一的碼點(code point)。
用 0x000000 - 0x10FFFF 這麼多的數字去對應全世界所有的語言、公式、符號。然後把這些數字分成 17 部分,把常用的放到 0x0000 - 0xFFFF,也就是 2 個字節,叫做基本平面 (BMP);從 0x010000 - 0x10FFFF 再劃分為其他平面。
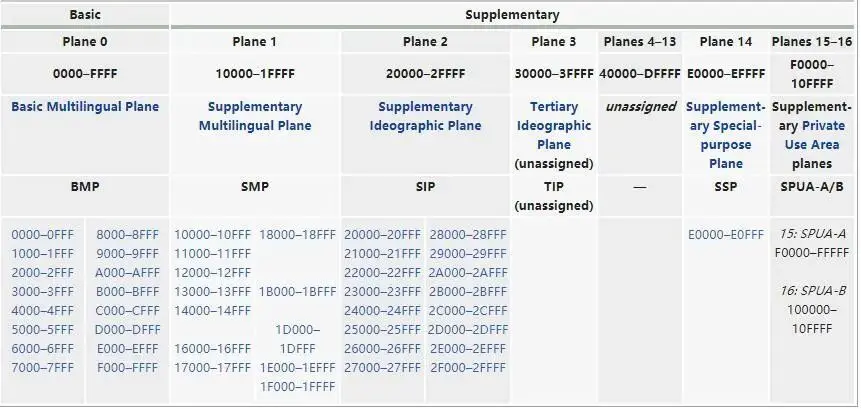
(圖片來源於維基百科)
栗子:「v維」
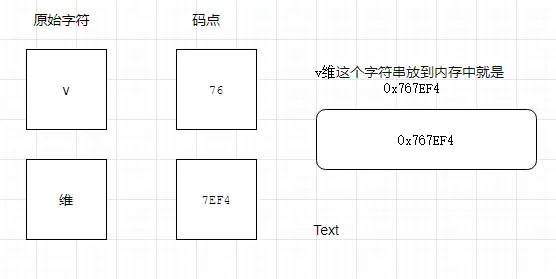
如果 「v維」 這個字符串放到內存中就是 0x767ef4。問題來了,計算機怎麼知道,幾個字節代表一個字符呢?是 0x76呢?還是 0x7ef4 呢?還是 0x767ef4?
Unicode只是對信源編碼,對字符集數字化,解決了字符到數字化的映射。接下來面臨如何解決存儲和傳輸的問題。
三、傳輸和存儲
用通信理論的思路可以理解為:
Unicode是信源編碼,對字符集數字化;
UTF-32、UTF-16、UTF-8是信道編碼,為更好的存儲和傳輸。
3.1 UTF-32
UTF-32 編碼,簡單明瞭,碼點值是多少,內存中就存多少,UTF-32 缺點很明顯了,字母 A 原本只需要 1 個字節去存儲,而現在卻用了 4 個字節去存,大部分位置都是 0。
提問:我們為什麼要多存那麼多零呢?
3.2 UTF-16
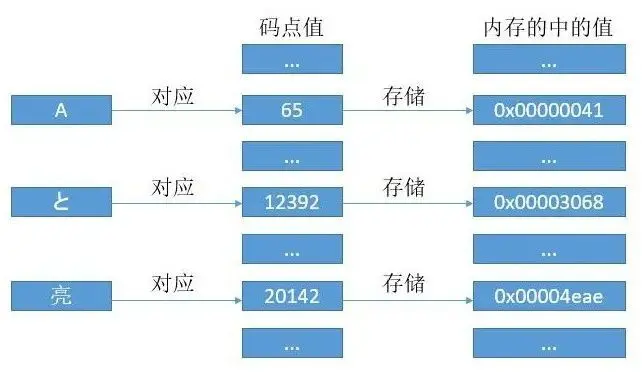
問題:「亮」 碼點值是 20142,換成 16 進制就是 0x4eae,內存中是按字節進行編址的。所以我們是先存4e呢?還是ae?
一個 Unicode 的碼點值會對應一個數字,對於Basic平面的字符,我們直接把這個數字存到內存中。
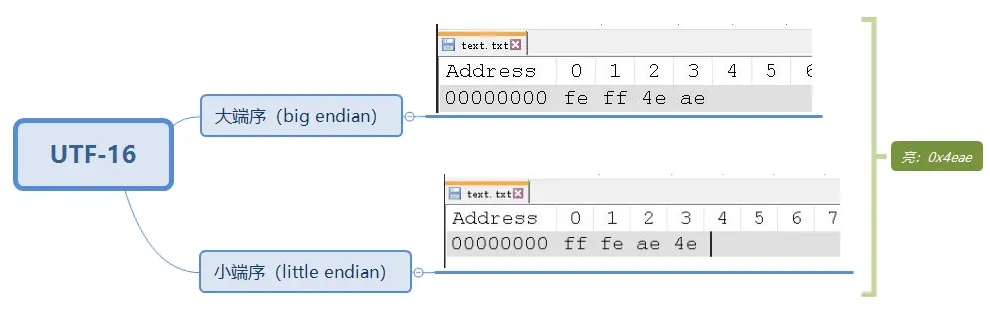
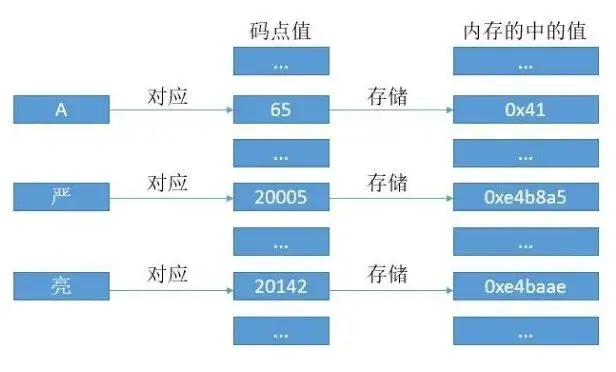
UTF - 16 編碼的時候,除本身的字節,為了區分大端序和小端序,最開頭還多了兩個字節,ff和fe。feff代表大端序,fffe代表小端序。

(Notepad中的BOM)
小知識:feff和fffe也叫做 BOM,它可以區分不同編碼。UTF-16 編碼最小單位是兩個字節,所以有字節序的問題,從而加了 BOM 來區分是大端序還是小端序。
3.3 UTF-8
UTF-8 顧名思義,是一套以 8 位為一個編碼單位的可變長編碼。會將一個碼位編碼為 1 到 4 個字節。一個碼點值會生成 1 個或多個字節,然後把這些字節按順序存就可以了。
小知識:UTF-8 無 BOM 或者 UTF-8 BOM。UTF - 8 的 BOM 是 EF BB BF ,UTF-8 並不存在字節序的問題,因為它的最小編碼單位就是字節。
UTF-8 並不需要區分大端序還是小端序,所以可以不需要 BOM。如果加了 BOM,對於一些讀取操作,它可能會把讀取到的 BOM 認為是字符,從而造成一些錯誤。所以我們保存 UTF - 8 編碼的文件時,最好選擇無 BOM。
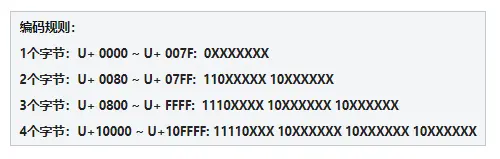
栗子:「知」
根據上表中的編碼規則,「知」字的碼位 U+77E5 屬於第三行的範圍:

這就是將U+77E5 按照 UTF-8 編碼為字節序列E79FA5 的過程,反之亦然。
3.4 ANSI
「ANSI」指的是對應當前系統 locale 的遺留(legacy)編碼。
Windows 裏説的「ANSI」其實是 Windows code pages,這個模式根據當前 locale 選定具體的編碼,比如簡中 locale 下是 GBK。把自己這些 code page 稱作「ANSI」是 Windows 的臭毛病。在 ASCII 範圍內它們應該是和 ASCII 一致的。
3.1 擴展思考
問:在java中char 型變量中能不能存貯一箇中文漢字,為什麼?
答:java中使用的編碼符號集是Unicode(不涉及特定的編碼方式,給每個符號分配一個二進制編碼,目前已容納容納100多萬個符號),而漢字已納入Unicode字符集, 而char類型佔兩個字節,用來表示Unicode編碼,所以是可以存儲漢字的
問:tomcat的中默認ISO-8859-1編碼,如何解決web項目中的亂碼問題?
答:
方式一:修改tomcat下的conf/server.xml文件
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8 useBodyEncodingForURI="true"/>
- URIEncoding=”UTF-8“:即可讓Tomcat(默認ISO-8859-1編碼)以UTF-8的編碼處理請求參數。
- useBodyEncodingForURI="true":是指請求參數的編碼方式採用請求體的編碼方式。
方式二:
1)當使用字符流向瀏覽器發送頁面信息時,默認查詢的是ISO-8859-1碼錶
- 設置1:response.setCharacterEncoding("UTF-8")
- 設置2:response.setContentType("text/html;charset=UTF-8")
2)客户端請求服務器出現的中文亂碼解決方式
-
POST請求方式:瀏覽器當前使用什麼編碼,表單提交的參數就是什麼編碼,
服務端處理:
request.setCharacterEncoding("utf-8")。
- GET請求方式:
String name=request.getParameter("name");//首先拿到參數的值
//得到的byte[] 再重新用utf-8去編碼,即可得到正常的值
name=new String(name.getBytes("iso-8859-1")/**用參數的值用iso-8859-1來解碼**/,"utf-8");String name=request.getParameter("name");//首先拿到參數的值//得到的byte[] 再重新用utf-8去編碼,即可得到正常的值name=new String(name.getBytes("iso-8859-1")/**用參數的值用iso-8859-1來解碼**/,"utf-8");
説明:tomcat的 j2ee實現對錶單提交即 post方式提示時處理參數採用缺省的 iso-8859-1來處理,tomcat對 get方式提交的請求對 query-string 處理時採用了和 post方法不一樣的處理方式。
四、總結
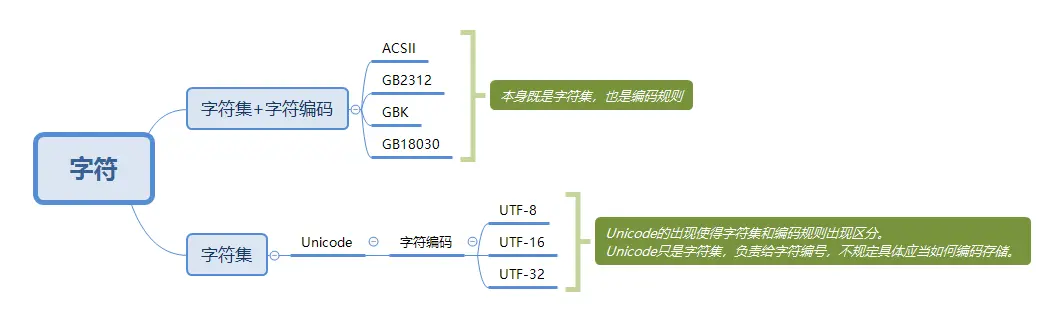
回到前言中的那個問題,整理了下面這張圖,不知現在的你是否對字符編碼有了更清楚的認識......
用通信理論的思路可以理解為:
Unicode是信源編碼,對字符集數字化;
UTF-32、UTF-16、UTF-8是信道編碼,為更好的存儲和傳輸。
參考資料
1、《深入理解計算機系統》
作者:vivo互聯網服務器團隊-Zhu Wenjin



