

作者:vivo 互聯網服務器團隊- Lei Zezheng
本文探討了分佈式架構下可觀測體系的建設實踐,提出了基於業務視角的可觀測體系建設框架:明確業務核心邊界、建立指標體系(業務指標+SLO指標)、構建多維度觀測(業務觀測、鏈路觀測、異常觀測、變更觀測)和固化排障路徑,以遊戲中心項目為例,介紹了項目在問題發現與問題定位上的實踐,有效提升了問題發現與故障處理的效率。
1分鐘看圖掌握核心觀點👇
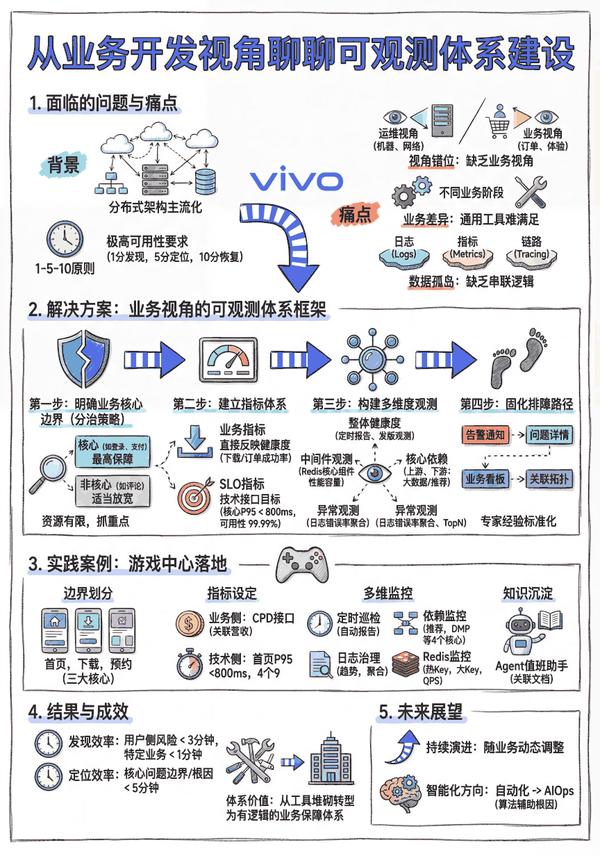
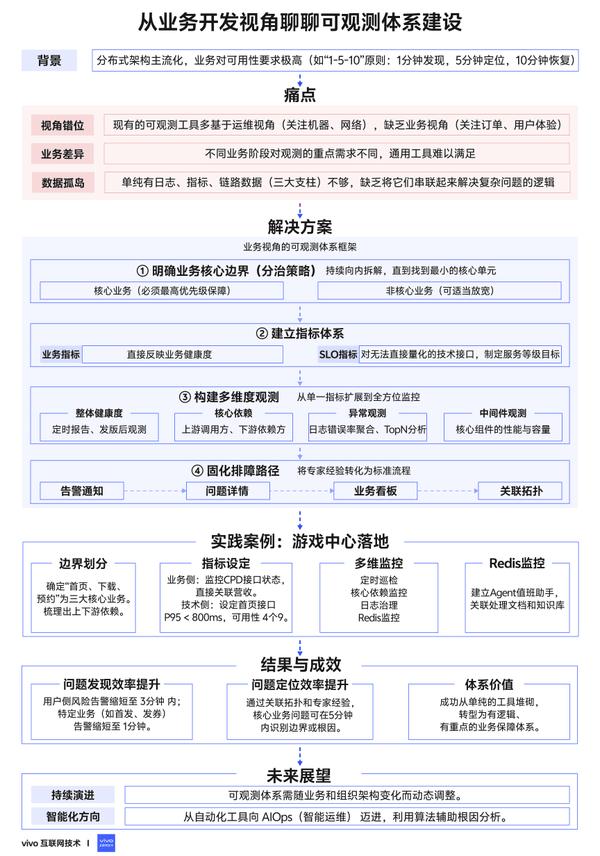
圖 1 VS 圖 2,您更傾向於哪張圖來輔助理解全文呢?歡迎在評論區留言
一、背景介紹與痛點分析
當分佈式架構漸成主流,可觀測性(Observability)在行業內也越來越受到重視。可觀測性是指系統可以由其外部輸出,來推斷其內部狀態,系統的可觀測性越強,我們對系統的可控制性就越強。現如今如何提升整體系統的可觀測性,應用可觀測工具達成業務保障可用性目標,成為了每個SRE與業務開發都必須思考的課題。但是隨着業務複雜度與”1-5-10"(1分鐘內發現問題,5分鐘內定位問題原因,10分鐘內恢復故障)可用性保障目標等的日益提升,我們也發現了可觀測體系在我們業務落地上的一些問題。
- 觀測視角的差異。可觀測工具建設與落地方向大多處於運維視角,而非業務視角。
- 業務的差異。不同的業務、業務發展的不同階段,對於觀測的建設重點差異很大。
這些差異,為平台側提供觀測工具與業務開發使用工具之間帶來了不少痛點。遊戲中心作為toC的分發類業務的一個典型項目,可觀測體系的建設過程可圈可點,現總結其中一些經驗,希望對於其他業務項目有所幫助。
二、可觀測體系的數據基座
對於可觀測,大家或多或少都聽過可觀測性的”三大支柱“:指標、日誌和鏈路,2017 年Peter Bourgon 撰寫的文章《Metrics, Tracing, and Logging》 系統地闡述了這三者的定義:
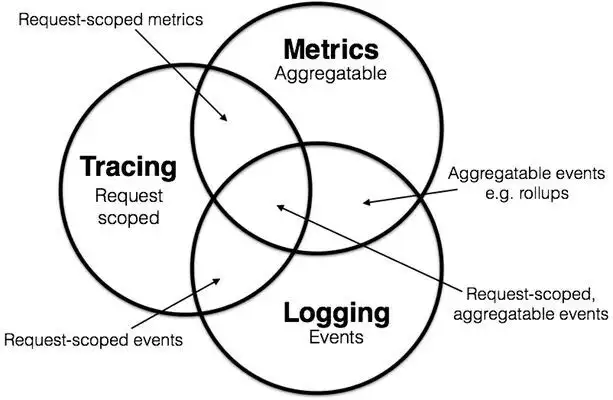
那麼我們監控團隊已經基本很完備的採集好了這些數據,並且呈現了諸如日誌中心,應用監控,調用鏈指標監控等工具,是否就代表了能保證我們系統的可觀測性?答案當然是否定的,有了西紅柿、雞蛋、鹽,並不能代表我們就已經能吃到西紅柿炒雞蛋了,三大指標都有着自己的明顯特徵與使用場景:
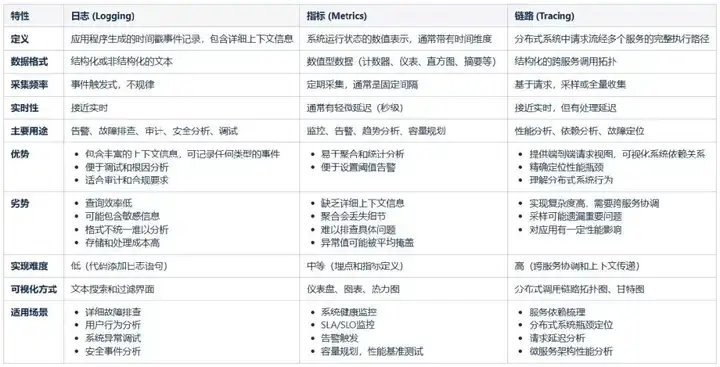
獨立的使用各種指標,永遠只適用於部分場景,雖不能説完全無效,但想系統化達成目標一定會比較吃力,且無條理。面對較為簡單的問題,比如日誌突然打印了空指針異常、數組越界的錯誤,我們看下日誌中心就很快能定位到具體代碼行上,進而分析上層參數的情況,並去迅速排除故障。但是當問題複雜度略微提升,比如:
- 我們依賴的服務耗時緩慢上升,直至導致我們服務的可用性下降;
- 服務調用者缺陷導致對我們某個服務的調用流量異常上漲,進而影響redis、mysql等基礎組件,最終導致同樣依賴該組件的核心服務受損。
出現這類問題時,日誌中心、應用指標,超時鏈路都會有異常反應。除此以外,絕大多數系統問題其實都是由於變更導致或觸發的,所以除了以上三個核心數據外,還需要結合一些變更系統事件來做輔助根因定位。我們無法24小時時刻關注各項指標,必須通過配置檢測與告警來主動通知。
日誌、指標、鏈路、變更事件以及告警,共同構成了我們可觀測的數據基座。
三、業務視角的可觀測體系建設框架
3.1 業務核心分治
對於大多數系統來説,我們建設可觀測體系都是為了及時發現系統中出現的各類故障,但是作為業務開發,實踐中我們會發現在這個標準下:都是故障,亦有差距。“遊戲中心首頁白屏”、“登錄失敗”、“下載失敗” 這類問題出現即是致命傷,等故障爆發後再發現是不可接受的。但是對於“遊戲評論刷新延遲”,“我的頁成就刷新延遲”之類的故障,在資源有限時,可能慢一點處理也無妨。
所以基於分治的思路,首先要做的就是“明確業務核心邊界”。如果拆解出的核心業務依然很複雜,那麼應當持續視角向內,將業務拆解至最小的核心單元后,再分部進行觀測。
3.2 指標體系的建立
對於業務系統,首要的觀測指標當然是業務指標,能夠直接反應業務的健康度,比如:“遊戲下載成功率”,“遊戲登錄成功率”,“遊戲訂單成功率”等。不過我們很多業務場景無法直接擬定業務指標,經過實踐,一定程度上可以通過SLO指標進行替代。
SLO指標是我們觀測可用性的重要手段,但不是越多越好,SLO的意義在於通過告警幫助我們快速發現影響服務SLI的異常,配置過多會帶來告警過多的困擾。上文已經提及到核心業務的拆分,對於微服務架構我們大部分服務是以接口調用的形式去對外提供的,那麼抽離出一組或多組的核心服務接口,並對於這一批接口的SLI指標進行度量,就可以制定自己系統的SLO目標。
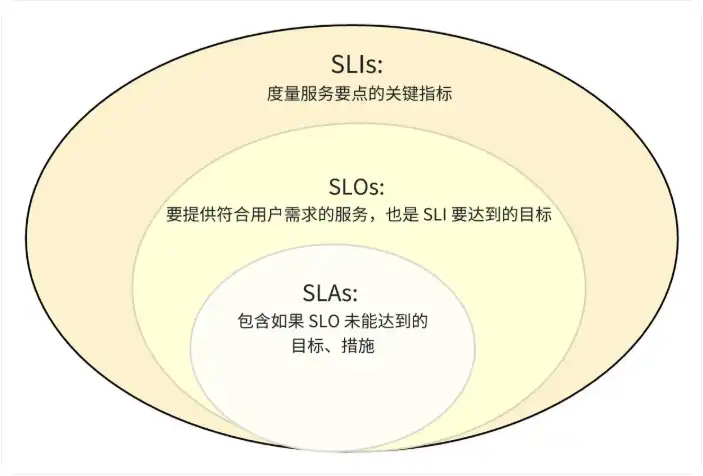
3.3 明確數據觀測目的與意義
通過建立指標體系,我們就能夠識別出系統中包含各式各樣的指標數據,通過對數據進行分類,我們也能夠進一步理解其對於系統的價值所在。
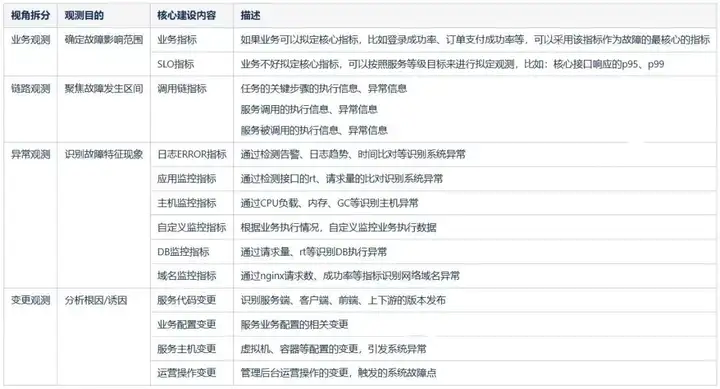
分象限觀測
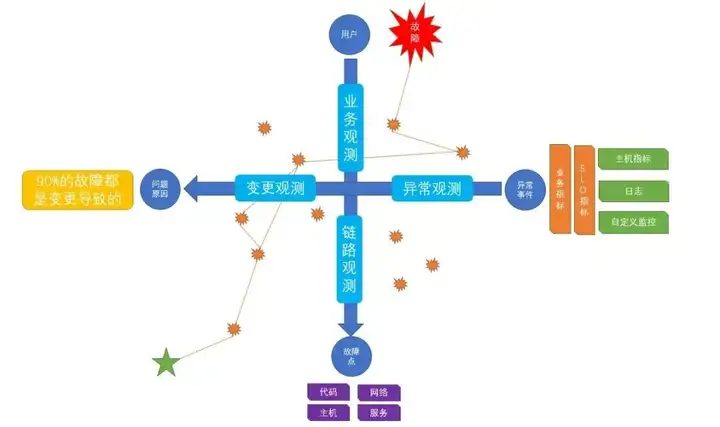
四、遊戲中心可觀測體系實踐
4.1 明確核心邊界
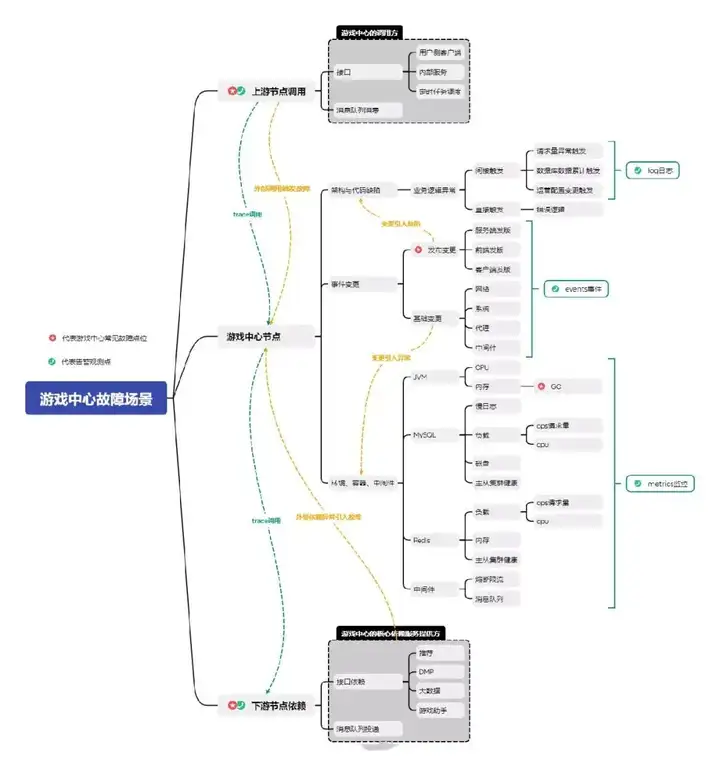
首先我們對遊戲中心進行了核心業務的劃分:遊戲中心首頁、遊戲下載、遊戲預約,對這三塊業務進行最高優先級的保障。由於可觀測體系的搭建必須依賴平台能力,相關能力最終也必須沉澱回平台,所以在邊界劃分上需要結合整體微服務架構設計:
公司的微服務拓撲視角
- 上游節點調用,重要調用方
- 下游節點調用,核心依賴方
遊戲中心服務架構視角
- 客户端
- 網絡環境
- 容器環境
- 代碼
- 中間件、核心依賴組件
- 運營後台
4.2 指標體系建立
(1)業務指標的觀測
對於遊戲中心下載業務,下載CPD指標是很核心的業務指標,且直接與收入數據掛鈎,可以通過檢測cpd接口的狀態來反映業務情況。

(2)SLO指標的觀測
對於首頁上游客户端調用,無法簡單與日活、營收等數據相關聯,為了達成“1-5”的目標,對於遊戲中心的SLO指標的制定我們選取了核心接口的P95耗時與可用性指標,並配置相關監控。首頁接口的pageData/home p95範圍大概在200-300ms,根據akamai研究用户體驗能明顯感知到慢的程度大概是加載2秒以上,附帶算上網絡傳輸與客户端渲染時間,我們的服務目標定為P95<800ms,在可用性上全年項目SLA可用性級別為4個9,在接口服務上也保持一致。
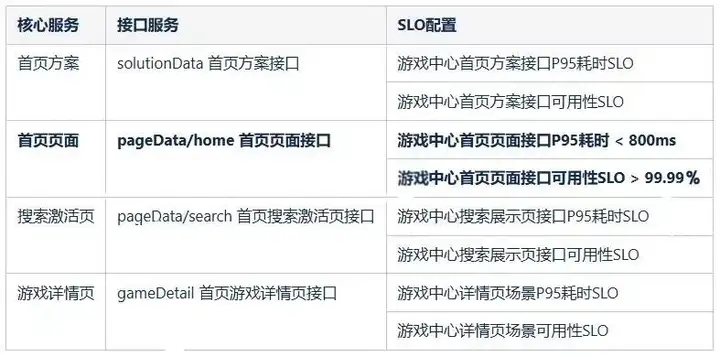
4.3 多維度的觀測
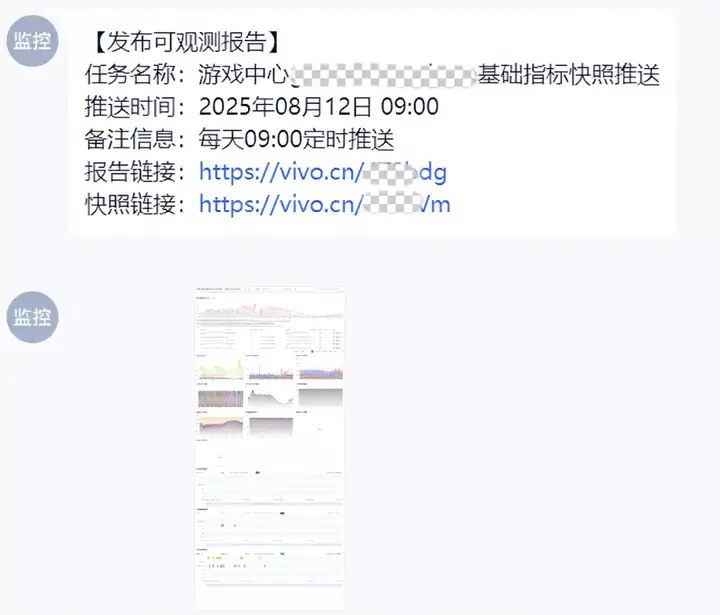
(1)整體健康度的定時觀測與發版後觀測
抽離核心觀測數據來快速實現整體核心SLI指標的觀測,是發現一些全局影響故障最直接的手段。如果一段時間所有接口的rt都緩慢上漲,那麼一定代表着系統出現了影響面最大的故障。通過定時報告的配置,既防範了個人的觀測習慣風險,也提升了移動端的觀測能力。版本發佈後的定期報告觀測,也是我們當前觀測版本變更後可用性的主要手段。
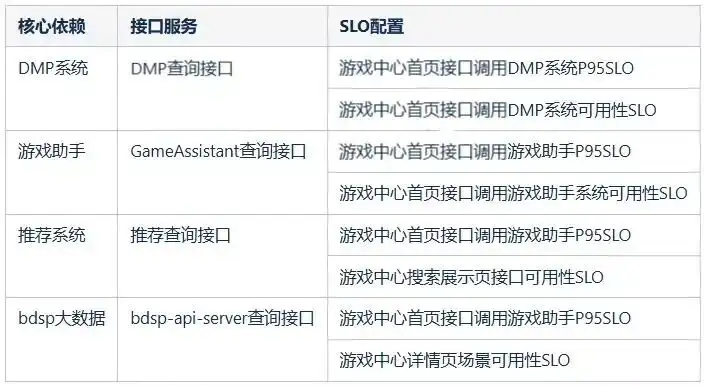
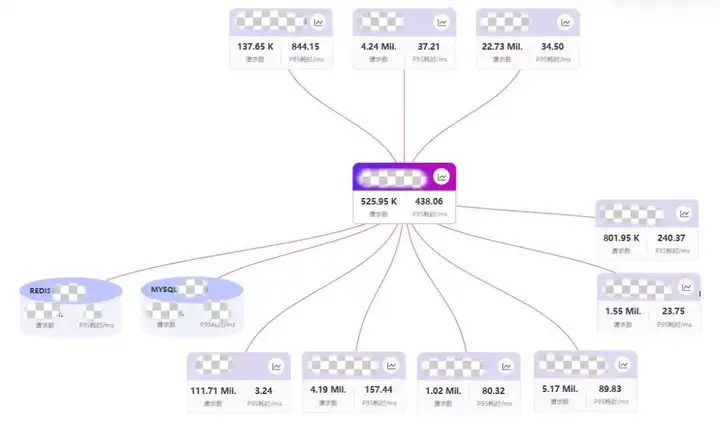
(2)服務的核心依賴觀測
在遊戲中心業務中,需要從推薦、dmp標籤、遊戲資訊、大數據四個業務方獲取核心數據,那麼這四個服務相關接口的SLO就需要作為核心依賴觀測項。
(3)服務的日誌觀測
- 通過錯誤日誌治理,降低error數量,來有效呈現異常error數據。
- 除了進行閾值數量監控外,對ERROR日誌聚合1分鐘級別的趨勢分析,聚合topN,有效識別異常error的變化。
(4)中間件的觀測
對於遊戲中心業務,redis是最為核心的中間件,redis的穩定直接影響首頁各個業務的健康度。對於redis的ops、實例cpu都進行檢測,結合熱key、大key分析,能夠有效識別問題和風險。
4.4 固化排障路徑
通過告警入口的下鑽串聯,搭建了 “告警通知→問題詳情→業務看板→關聯拓撲” 的通用問題排障路徑。
在專家經驗的沉澱上,對於業務、SLO等相關告警,通過處理流程建議文檔、文檔知識庫、日誌知識庫,構建agent值班助手來共享團隊知識。

五、總結與展望
- 在問題發現上:對於遊戲中心的三大核心業務場景明確了業務邊界之後,用户側接口訪問變慢、出錯的風險告警可以在3分鐘內完成告警推送;通過與監控團隊合作提升自定義監控數據採集,對於遊戲預約首發、遊戲禮券發放等業務,可以做到1分鐘的問題告警推送。
- 在問題定位上:通過關聯到下游依賴、服務基礎指標與專家經驗,遊戲核心業務的組件、服務異常等問題,基本可以5分鐘內做到識別風險和問題邊界或原因。
可觀測體系建設並非一勞永逸的事情,隨着業務變化而變化,也隨着團隊組織架構變化而變化。對於監控平台,構建統一可觀測體系的難點,一方面在於技術本身的制約,如何應對大規模數據的存儲、性能挑戰;另一方面則在於如何與千差萬別的業務進行溝通、合作,融合業務專家經驗,抽象出共性的問題。那麼作為業務開發,持續提升可觀測理解水平,深入挖掘沉澱業務專家經驗,才能協同好平台一起做好這件事。現如今,行業AIOPS的發展日新月異,我們系統化的構建可觀測體系也是融入該浪潮中,在實現的工具自動化的目標之後,我們也希望朝着智能化的建設邁出一步。