

在數據分析中,我們常説:“一張好的圖表勝過千言萬語。”
但很多時候,我們做出來的圖表卻是“千言萬語堵在心口難開”。讀者看了半天,抓不住重點。
這是為什麼?
因為人類的視覺感知遵循一套被稱為 格式塔(Gestalt) 的心理學原理。
簡單來説,當我們看到一組物體時,大腦會自動將它們視為一個整體或一種模式,而不是孤立的碎片。
下面我們用 Python 的 Matplotlib 庫,來演示 格式塔(Gestalt) 心理學中的 6 個核心原理,看看如何利用這些原理“控制”讀者的注意力。
1. 鄰近原理:距離產生“關係”
鄰近原理就是距離越近,關係越親,我們的大腦會自動把靠得近的物體歸為一類。
就像在一個派對上,站在一起聊天的幾個人,你會下意識覺得他們是一夥的。
# 鄰近原理
# 創建測試數據
np.random.seed(42)
data_a = np.random.normal(5, 1.5, 30)
data_b = np.random.normal(10, 1.5, 30)
data_c = np.random.normal(15, 1.5, 30)
# 不使用鄰近原理
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 左側:未應用鄰近原理(所有點均勻分佈)
all_data = np.concatenate([data_a, data_b, data_c])
x_positions = np.arange(90)
ax1.scatter(x_positions, all_data, alpha=0.7)
ax1.grid(True, alpha=0.3)
# 右側:應用鄰近原理(按組聚集)
for i, (data, x_offset) in enumerate(zip([data_a, data_b, data_c], [0, 30, 60])):
x_positions = np.arange(len(data)) + x_offset
ax2.scatter(x_positions, data, alpha=0.7, label=f'組{i+1}')
plt.tight_layout()
plt.show()
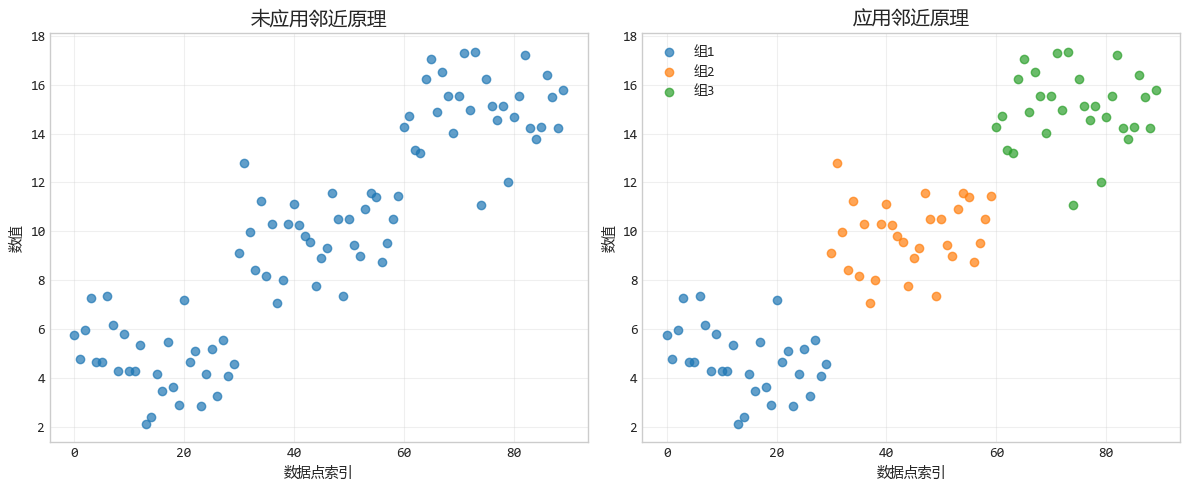
設計要點:將相關的數據點或元素放在靠近的位置,可以讓觀眾自然地理解它們屬於同一類別或具有某種關聯。
2. 相似原理:相似的“性格”吸引
相似原理就是長得像的,就是一家人,當物體在顏色、形狀或大小上相似時,大腦會將它們分為一組。
比如在足球場上,穿着相同顏色球衣的人,你不需要看清他們的臉,就知道他們是隊友。
# 相似原理
# 創建測試數據
categories = ["A", "B", "C", "D", "E"]
values1 = [12, 16, 14, 18, 15]
values2 = [8, 11, 9, 12, 10]
x_pos = np.arange(len(categories))
# 相似原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 左側:未應用相似原理(隨機顏色和樣式)
bars1 = ax1.bar(x_pos - 0.2, values1, 0.4, color=colors1, edgecolor="black")
bars2 = ax1.bar(
x_pos + 0.2, values2, 0.4, color=colors2, edgecolor="black", hatch=hatches[0]
)
# 為每組條形添加不同圖案
for i, bar in enumerate(bars2):
bar.set_hatch(hatches[i % len(hatches)])
# 右側:應用相似原理(一致的顏色和樣式)
ax2.bar(x_pos - 0.2, values1, 0.4, color="skyblue", edgecolor="black", label="數據集1")
ax2.bar(
x_pos + 0.2, values2, 0.4, color="lightcoral", edgecolor="black", label="數據集2"
)
plt.tight_layout()
plt.show()
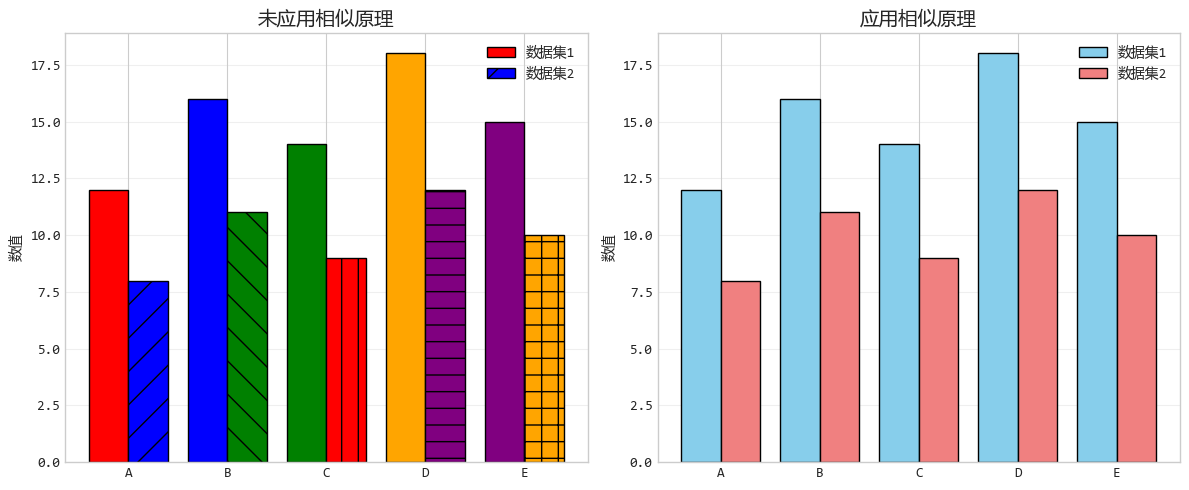
設計要點:使用一致的顏色、形狀或樣式來表示相同類型的數據,可以大大降低觀眾的認知負擔。
3. 包圍原理:邊界創造"歸屬感"
包圍原理就是有圍牆的地方就是家。如果在某些物體周圍加上邊界或背景色,它們就被視為一個獨立的羣體。
這個原理甚至比 “鄰近” 和 “相似” 更強大。
比如,草地上散落着羊羣,一旦你用柵欄圈住其中幾隻,大家就會認為這幾隻是被特別選中的。
# 包圍原理
# 創建測試數據
np.random.seed(42)
x1 = np.random.normal(2, 0.8, 50)
y1 = np.random.normal(3, 0.8, 50)
x2 = np.random.normal(5, 0.8, 50)
y2 = np.random.normal(5, 0.8, 50)
# 包圍原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 左側:未應用包圍原理
ax1.scatter(x1, y1, alpha=0.7, color="blue")
ax1.scatter(x2, y2, alpha=0.7, color="red")
# 右側:應用包圍原理
from matplotlib.patches import Ellipse
ax2.scatter(x1, y1, alpha=0.7, color="blue", label="組A")
ax2.scatter(x2, y2, alpha=0.7, color="red", label="組B")
# 添加包圍區域
ellipse1 = Ellipse((2, 3), width=4, height=3, edgecolor="blue")
ellipse2 = Ellipse((5, 5), width=4, height=3, edgecolor="red")
ax2.add_patch(ellipse1)
ax2.add_patch(ellipse2)
plt.tight_layout()
plt.show()
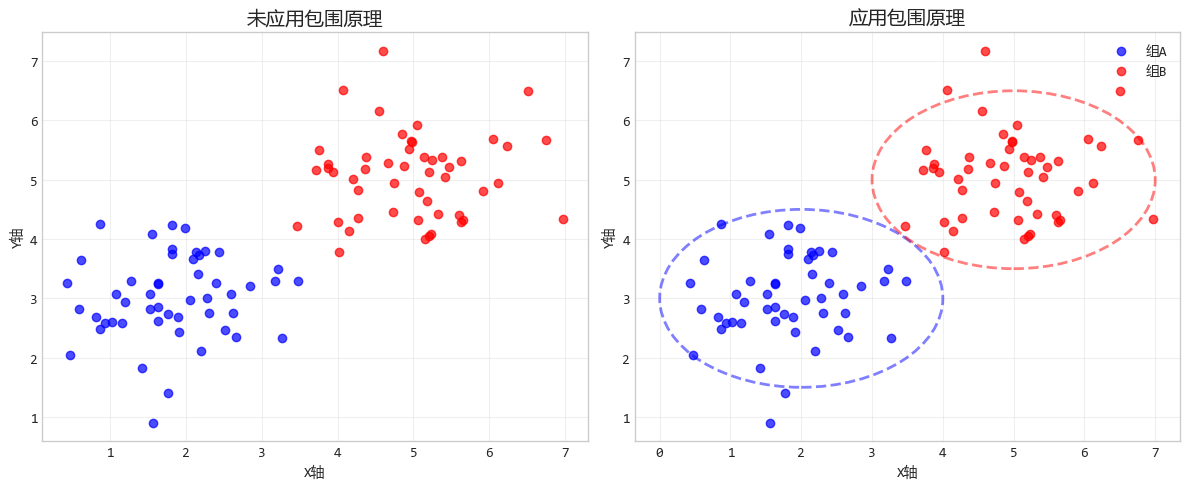
設計要點:使用邊界、背景色或容器將相關的數據元素包圍起來,可以明確地告訴觀眾這些元素屬於同一組。
4. 閉合原理:大腦的"自動補全"
閉合原理就是大腦是天生的“補圖高手”。即使圖形不完整,只要有足夠的提示,大腦也會自動腦補出缺失的部分。
比如看到一個虛線畫圓,你不會覺得那是斷斷續續的線段,你會直接説:“這是一個圓”。
# 閉合原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 創建一些不完整的數據點
np.random.seed(42)
angles = np.linspace(0, 2*np.pi, 7)[:-1] # 故意少一個點形成不閉合
radii = np.random.uniform(3, 5, 6)
x = radii * np.cos(angles)
y = radii * np.sin(angles)
# 左側:不完整的形狀(未利用閉合原理)
ax1.plot(x, y, 'o-', linewidth=2, markersize=8)
# 右側:閉合的形狀(應用閉合原理)
# 添加缺失的點使形狀閉合
angles_closed = np.linspace(0, 2*np.pi, 7)
radii_closed = np.append(radii, radii[0]) # 回到起點
x_closed = radii_closed * np.cos(angles_closed)
y_closed = radii_closed * np.sin(angles_closed)
ax2.plot(x_closed, y_closed, 'o-', linewidth=2, markersize=8)
ax2.fill(x_closed, y_closed, alpha=0.3) # 填充增強閉合感
plt.tight_layout()
plt.show()
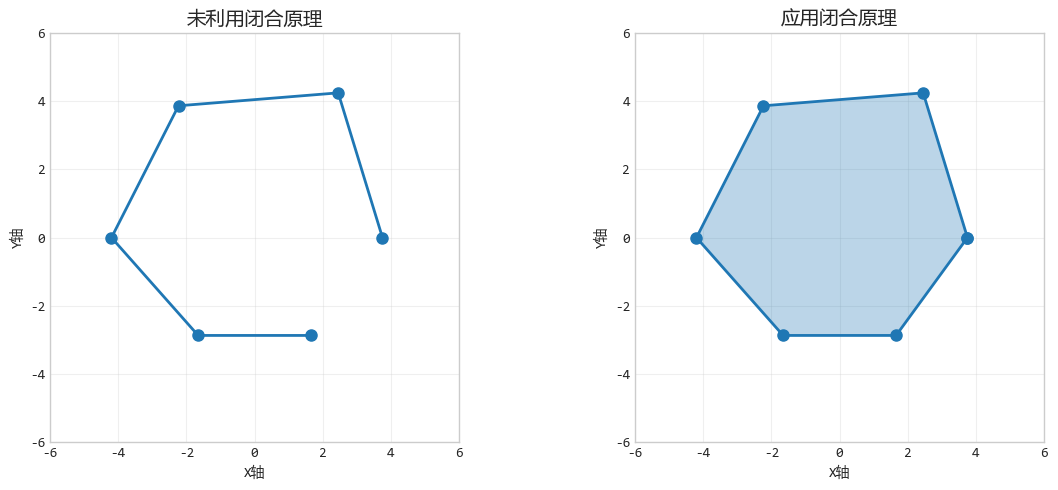
設計要點:我們不需要展示每一個細節,可以利用觀眾的自動補全能力來簡化圖表。
但要注意,過於不完整的圖形可能導致誤解。
5. 連續原理:流暢的"視覺路徑"
連續原理就是順藤摸瓜。我們的視線傾向於跟隨平滑、連續的路徑,而不是劇烈折線或不規則的排列。
比如排隊時,如果隊伍彎彎曲曲但每個人都看着前一個人的後腦勺,你知道這還是一條隊。
# 連續原理示例
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 創建數據
np.random.seed(42)
time = np.arange(0, 10, 0.1)
signal1 = np.sin(time) + np.random.normal(0, 0.1, len(time))
signal2 = np.cos(time) + np.random.normal(0, 0.1, len(time))
# 左側:不連續的展示
ax1.plot(time[:50], signal1[:50], 'b-', linewidth=2, label='信號A (第一部分)')
ax1.plot(time[70:], signal1[70:], 'b--', linewidth=2, label='信號A (第二部分)')
ax1.plot(time[:40], signal2[:40], 'r-', linewidth=2, label='信號B (第一部分)')
ax1.plot(time[60:], signal2[60:], 'r--', linewidth=2, label='信號B (第二部分)')
# 右側:連續的展示
ax2.plot(time, signal1, 'b-', linewidth=2, label='信號A')
ax2.plot(time, signal2, 'r-', linewidth=2, label='信號B')
plt.tight_layout()
plt.show()
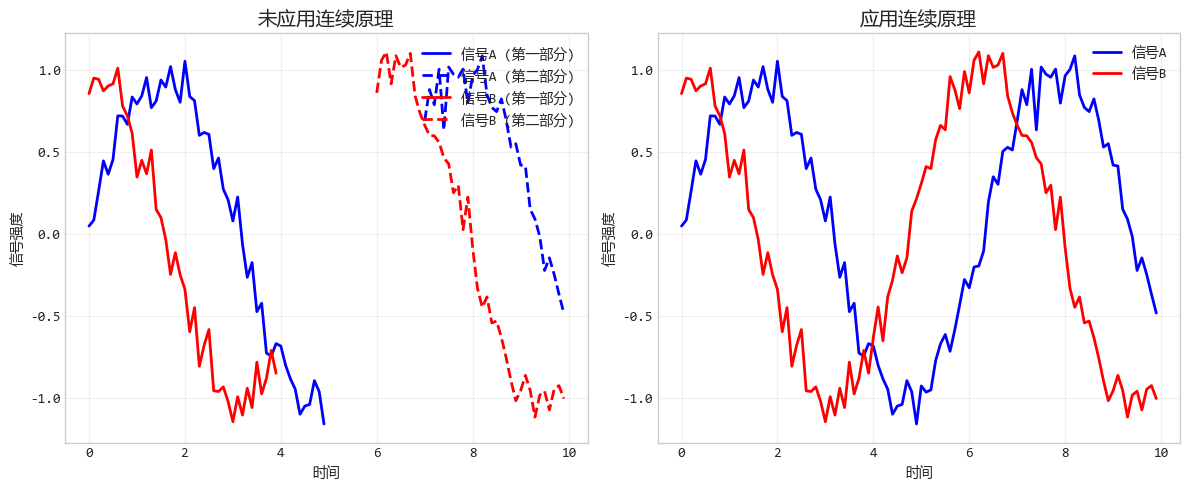
設計要點:保持線條、形狀或元素的連續性可以幫助觀眾追蹤數據的變化趨勢。在折線圖、面積圖中尤其重要。
6. 連接原理:看得見的"關係線"
連接原理就是藕斷絲連。被線連接的物體,被視為強關聯。這個視覺信號比顏色和距離都要強。
比如,兩個人站得再遠,如果手裏牽着一根繩子,你也會覺得他們倆在互動。
# 連接原理示例 - 散點圖版本
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 創建散點數據:4個相關點集,每個點集有5個點
np.random.seed(42)
n_points = 5
n_groups = 4
# 為每組生成相關點
groups = []
for i in range(n_groups):
center_x = np.random.uniform(2, 8)
center_y = np.random.uniform(2, 8)
# 生成圍繞中心的相關點
x_points = center_x + np.random.normal(0, 0.8, n_points)
y_points = center_y + np.random.normal(0, 0.8, n_points)
# 添加一些趨勢
trend = np.random.uniform(-1, 1)
y_points = y_points + trend * (x_points - center_x)
groups.append((x_points, y_points))
# 左側:未應用連接原理(獨立的散點)
colors = ["blue", "red", "green", "orange"]
markers = ["o", "s", "^", "D"]
for i, (x_points, y_points) in enumerate(groups):
ax1.scatter(
x_points,
y_points,
color=colors[i],
marker=markers[i],
alpha=0.7,
s=80,
label=f"數據集{i+1}",
)
# 右側:應用連接原理(連接相關散點)
for i, (x_points, y_points) in enumerate(groups):
# 首先繪製連接線
# 按照x值排序,使連接線更有序
sorted_indices = np.argsort(x_points)
sorted_x = x_points[sorted_indices]
sorted_y = y_points[sorted_indices]
ax2.plot(
sorted_x,
sorted_y,
color=colors[i],
linewidth=2,
alpha=0.5,
linestyle="--",
label=f"數據集{i+1}趨勢線",
)
# 然後繪製散點(在線上方,避免被線遮擋)
ax2.scatter(
x_points,
y_points,
color=colors[i],
marker=markers[i],
alpha=0.7,
s=80,
edgecolor="black",
linewidth=1,
)
plt.tight_layout()
plt.show()
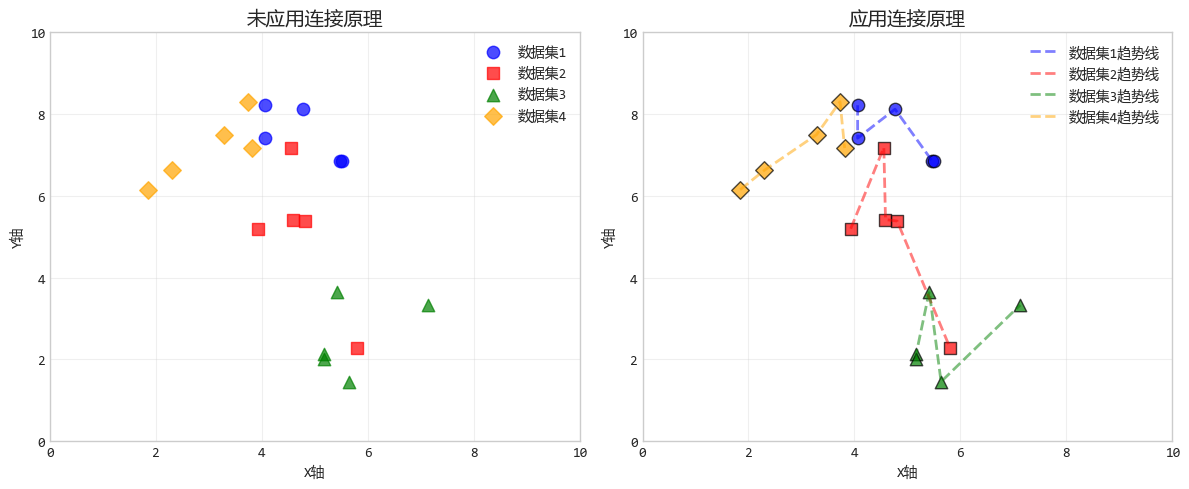
設計要點:在散點圖中,連接相關數據點的線可以幫助觀眾識別出數據的模式、趨勢或分組關係。
這就像在地圖上連接各個城市來顯示旅行路線一樣,使相關的點之間建立了明確的視覺聯繫。
7. 總結
做數據可視化,不僅僅是寫代碼畫圖,更是一場 “注意力爭奪戰”。
通過這 6 個格式塔原理,我們不是在改變數據本身,而是在優化數據的呈現方式,讓讀者的腦力消耗降到最低。
每次我們畫圖時,不妨問自己一句:
- “這些數據應該是一組嗎?它們靠得夠近嗎?”(鄰近)
- “重點數據突出了嗎?”(包圍/相似)
- “視線流動順暢嗎?”(連續)
最好的可視化不是展示所有數據,而是引導觀眾看到最重要的信息。格式塔原理就是我們實現這一目標的強大工具。
希望這篇文章能幫助你在創建數據可視化時,更加有意地引導觀眾的注意力。