

想象一下,你走進一個擠滿人的房間,朋友向你招手--你幾乎立刻就能看到他。
這是因為“招手”這個動作在你的大腦進行深入思考之前,就已經被注意到了。
再比如當你走在熙熙攘攘的大街上,如果所有人穿的都是黑灰色的大衣,而此時有一個人穿着鮮紅色的風衣,你會看哪裏?
毫無疑問,你的目光會瞬間被那抹紅色吸引。
這就是前注意加工:我們的大腦能在極短時間內(約200-250毫秒)自動檢測到某些視覺特徵,而無需我們有意識地去尋找。
在數據可視化中,前注意加工就是我們用來引導讀者注意力的“視覺魔術”。
通過巧妙地改變顏色、大小、形狀等視覺屬性,我們可以讓圖表中的關鍵信息(如最大值、最小值、異常值)像朋友招手一樣“跳出來”,第一時間抓住讀者的眼球。
1. 前注意加工的實用技巧
- 少即是多:不要過度使用突出效果,否則會失去焦點
- 一致性原則:在整個報告或儀表板中使用相同的突出顏色編碼
- 考慮色盲用户:避免僅依靠顏色區分,可結合形狀、紋理等
- 上下文相關:根據數據特點和觀眾背景選擇合適的突出方式
- 測試效果:讓其他人查看你的圖表,確認突出效果是否達到預期
2. 前注意加工實例
概念介紹完了,下面直接看代碼,看看實際情況下如何使用前注意加工來提高我們的可視化效果。
2.1. 突出最大值和最小值
# 示例1:突出最大值和最小值
# 創建數據
np.random.seed(42)
categories = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
values = np.random.randint(10, 100, size=8)
# 找出最大值和最小值的索引
max_idx = np.argmax(values)
min_idx = np.argmin(values)
# 創建圖表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 左圖:沒有前注意加工
bars1 = ax1.bar(categories, values, color='lightblue', edgecolor='black')
# 右圖:有前注意加工(突出最大最小值)
colors = ['lightblue'] * len(values)
colors[max_idx] = '#FF6B6B' # 紅色突出最大值
colors[min_idx] = '#4ECDC4' # 青色突出最小值
bars2 = ax2.bar(categories, values, color=colors, edgecolor='black')
# 在最大值和最小值上添加標籤
ax2.text(max_idx, values[max_idx] + 2, f'最大: {values[max_idx]}',
ha='center', fontweight='bold', color='#FF6B6B')
ax2.text(min_idx, values[min_idx] + 2, f'最小: {values[min_idx]}',
ha='center', fontweight='bold', color='#4ECDC4')
plt.tight_layout()
plt.show()
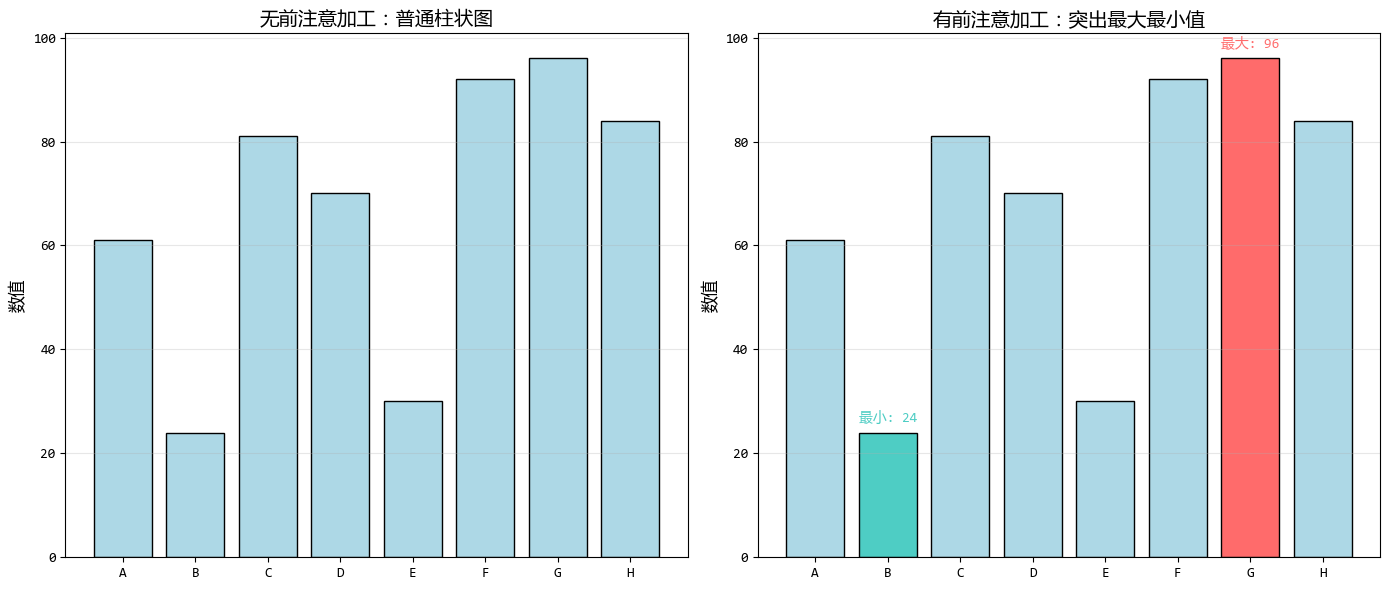
左圖中,所有柱子都是相同的藍色,讀者需要逐個比較才能找出最大值和最小值。
右圖中,最大值用醒目的紅色標出,最小值用青色標出,讀者一眼就能看到關鍵數據點。
前注意加工的好處:就像在人羣中為重要人物戴上特別的帽子,讀者無需費力尋找就能立即識別關鍵數據點。
2.2. 突出異常值
# 示例2:突出異常值
# 創建包含異常值的數據
np.random.seed(42)
data_normal = np.random.normal(50, 10, 100)
data_outliers = np.array([5, 125, 130]) # 異常值
all_data = np.concatenate([data_normal, data_outliers])
# 識別異常值(簡單方法:超出平均值±2倍標準差)
mean_val = np.mean(all_data)
std_val = np.std(all_data)
outlier_indices = np.where((all_data < mean_val - 2*std_val) | (all_data > mean_val + 2*std_val))[0]
# 創建圖表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 左圖:沒有前注意加工
scatter1 = ax1.scatter(range(len(all_data)), all_data, alpha=0.7, c='gray', s=50)
ax1.axhline(y=mean_val, color='black', linestyle='--', alpha=0.5, label=f'平均值: {mean_val:.1f}')
ax1.axhline(y=mean_val + 2*std_val, color='red', linestyle=':', alpha=0.5, label='±2標準差')
ax1.axhline(y=mean_val - 2*std_val, color='red', linestyle=':', alpha=0.5)
# 右圖:有前注意加工(突出異常值)
colors = ['gray'] * len(all_data)
sizes = [50] * len(all_data)
# 突出異常值
for idx in outlier_indices:
colors[idx] = '#FF6B6B' # 紅色
sizes[idx] = 150 # 更大
scatter2 = ax2.scatter(range(len(all_data)), all_data, alpha=0.7, c=colors, s=sizes)
ax2.axhline(y=mean_val, color='black', linestyle='--', alpha=0.5, label=f'平均值: {mean_val:.1f}')
ax2.axhline(y=mean_val + 2*std_val, color='red', linestyle=':', alpha=0.5, label='±2標準差')
ax2.axhline(y=mean_val - 2*std_val, color='red', linestyle=':', alpha=0.5)
plt.tight_layout()
plt.show()
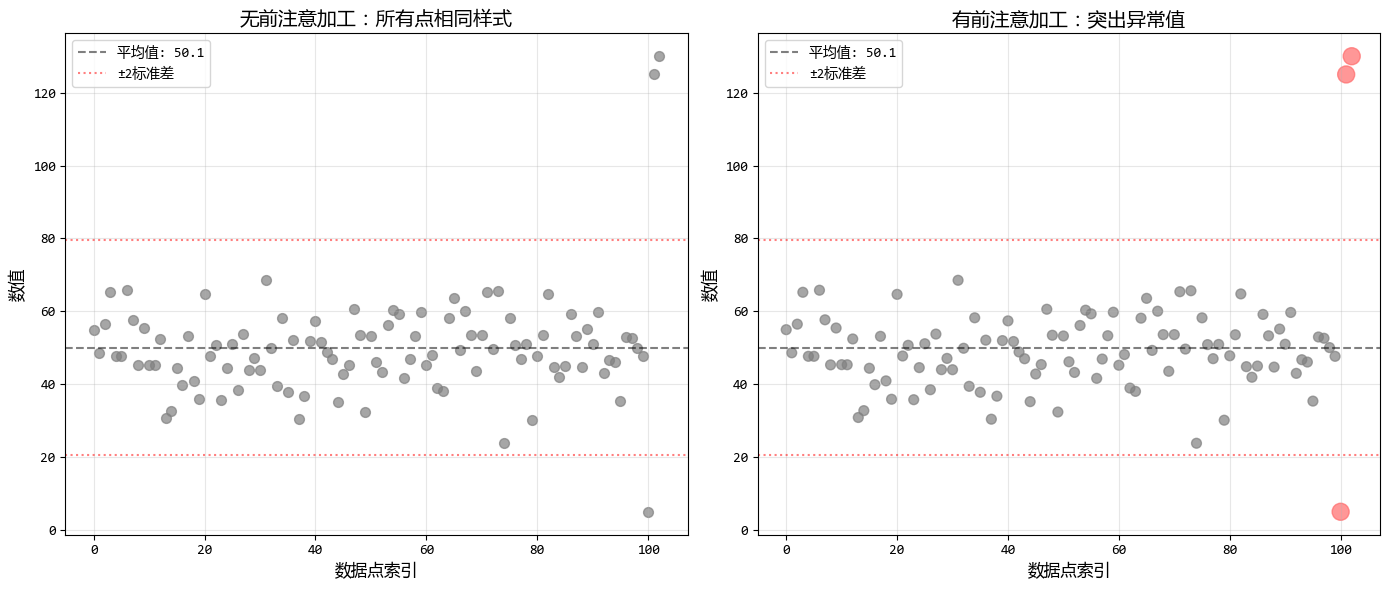
左圖中,異常值混在普通數據點中,難以立即識別。
右圖中,異常值用更大的紅色點突出顯示,即使數據量很大,讀者也能立即注意到這些特殊點。
前注意加工的好處:就像在平靜湖面上標記出漣漪的起源,異常值不再隱藏在數據海洋中,而是成為分析的重點。
2.3. 突出趨勢變化點
# 示例3:突出趨勢變化點
# 創建包含趨勢變化的時間序列數據
np.random.seed(42)
time_points = np.arange(0, 100)
trend_change_point = 45
# 分段創建趨勢數據
trend1 = 30 + 0.5 * np.arange(0, trend_change_point) + np.random.normal(0, 2, trend_change_point)
trend2 = trend1[-1] - 0.8 * np.arange(0, 100 - trend_change_point) + np.random.normal(0, 2, 100 - trend_change_point)
data = np.concatenate([trend1, trend2])
# 創建圖表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 左圖:沒有前注意加工
line1 = ax1.plot(time_points, data, color='gray', alpha=0.8, linewidth=2)
# 右圖:有前注意加工(突出趨勢變化點)
line2 = ax2.plot(time_points, data, color='gray', alpha=0.6, linewidth=2)
# 突出趨勢變化區域
ax2.axvspan(trend_change_point-5, trend_change_point+5, alpha=0.3, color='#FF6B6B', label='趨勢變化區域')
ax2.scatter(trend_change_point, data[trend_change_point], color='#FF6B6B', s=200, zorder=5, label='變化點')
ax2.plot(time_points[:trend_change_point+1], data[:trend_change_point+1], color='#4ECDC4', linewidth=3, alpha=0.8, label='上升趨勢')
ax2.plot(time_points[trend_change_point:], data[trend_change_point:], color='#45B7D1', linewidth=3, alpha=0.8, label='下降趨勢')
plt.tight_layout()
plt.show()
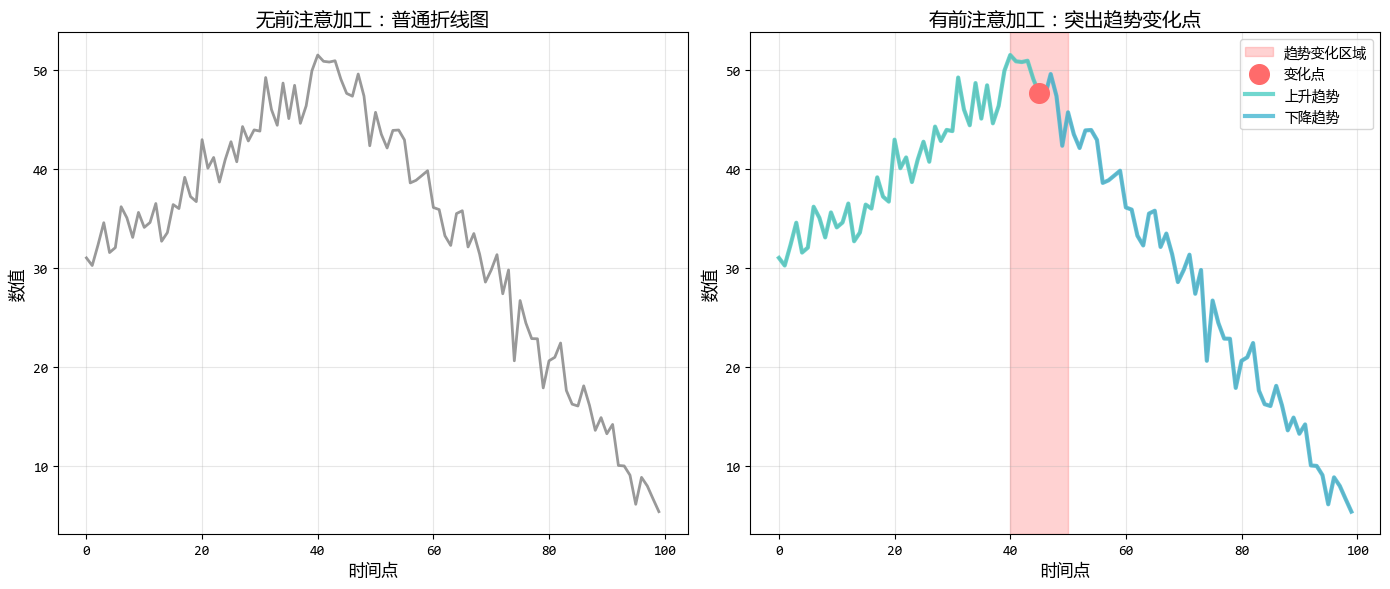
左圖展示了一個完整的趨勢線,但變化點不明顯。
右圖使用不同顏色區分趨勢段,並用陰影區域和突出點標記變化區域,使趨勢轉折一目瞭然。
前注意加工的好處:就像在道路地圖上標記出轉彎處,讀者能立即看到趨勢變化的關鍵時刻。
2.4. 突出特定類別
# 示例4:突出特定類別
# 創建餅圖數據
categories = ["電子產品", "服裝", "食品", "家居", "書籍", "其他"]
values = [25, 18, 22, 15, 10, 10]
highlight_category = "食品" # 要突出的類別
highlight_idx = categories.index(highlight_category)
# 創建圖表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 左圖:沒有前注意加工
colors1 = ["#FF9AA2", "#FFB7B2", "#FFDAC1", "#E2F0CB", "#B5EAD7", "#C7CEEA"]
wedges1, texts1, autotexts1 = ax1.pie(
values, labels=categories, autopct="%1.1f%%", colors=colors1, startangle=90
)
# 右圖:有前注意加工(突出特定類別)
# 將突出類別的顏色改為醒目的顏色,其他類別用灰度
colors2 = ["lightgray"] * len(categories)
colors2[highlight_idx] = "#FF6B6B" # 突出類別用紅色
# 突出顯示:將特定類別"拉出"
explode = [0] * len(categories)
explode[highlight_idx] = 0.1
wedges2, texts2, autotexts2 = ax2.pie(
values,
labels=categories,
autopct="%1.1f%%",
colors=colors2,
explode=explode,
startangle=90,
)
plt.tight_layout()
plt.show()
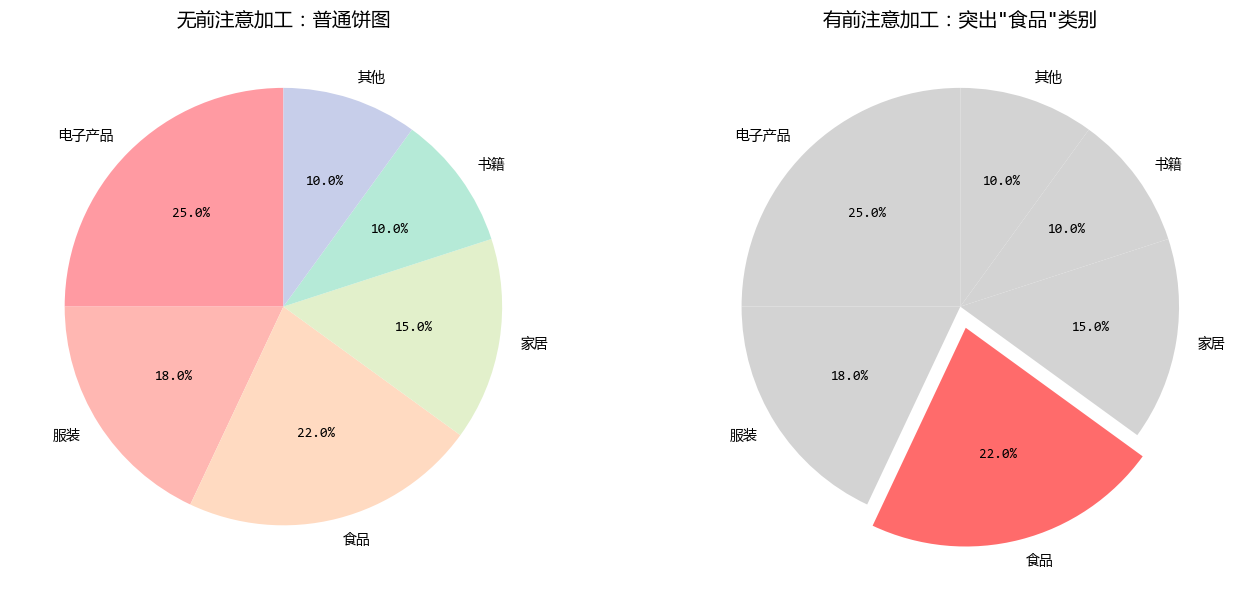
左圖中,所有類別視覺權重相同,讀者需要閲讀標籤或百分比才能找到特定類別。
右圖中,目標類別被"拉出"並用醒目的紅色顯示,其他類別則用灰色淡化,讀者一眼就能看到重點。
前注意加工的好處:就像在合唱團中為獨唱者打上聚光燈,特定類別立即成為視覺焦點。
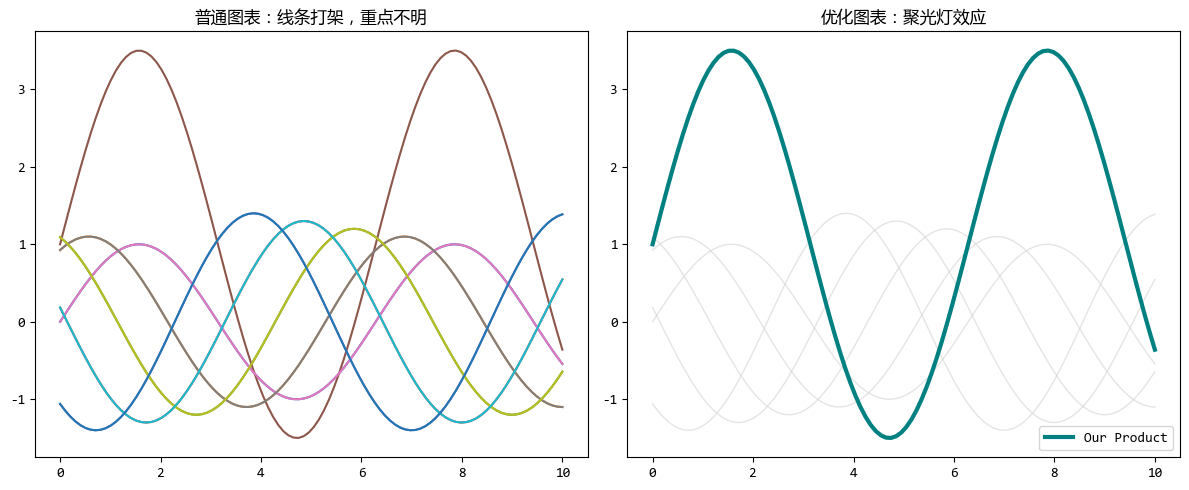
同樣,在繪製多條折線圖(也就是俗稱的“麪條圖”)時,如果每條線都用高飽和度的顏色,畫面會非常混亂,讀者不知道該看哪一條。
也可以用上面餅圖類似的思路,降低非重點數據的不透明度(Alpha)和線寬(Linewidth),只保留重點數據的鮮明樣式。
這就像舞台上的聚光燈,燈光打在哪裏,觀眾就看哪裏。
# 模擬時間序列數據
x = np.linspace(0, 10, 100)
# 生成5條幹擾線
lines = [np.sin(x + i) * (1 + i/10) for i in range(5)]
# 生成1條重點線(比如這是我們公司的產品)
main_line = np.sin(x) * 2.5 + 1
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# --- 圖1:沒有前注意加工 ---
# 典型的麪條圖,所有線都在爭奪注意力
for i, line in enumerate(lines):
ax1.plot(x, line, label=f'Competitor {i}')
ax1.plot(x, main_line, label='Our Product')
# --- 圖2:有前注意加工 ---
# 策略:弱化背景,突出前景
for line in lines:
ax1.plot(x, line) # 左圖邏輯
# 右圖邏輯:灰色、細線、半透明
ax2.plot(x, line, color='lightgray', linewidth=1, alpha=0.6)
# 重點線:深青色、加粗、不透明
ax2.plot(x, main_line, color='teal', linewidth=3, label='Our Product')
plt.tight_layout()
plt.show()
3. 總結
前注意加工是數據可視化中的"視覺語法",它通過預認知的視覺特徵引導讀者的注意力。
就像熟練的導遊會指出風景中的亮點,有效的數據可視化應該引導讀者立即看到數據故事中最關鍵的部分。
數據可視化不僅僅是把數據畫出來,更是一場注意力的管理藝術。
- 不要讓讀者的眼睛去“工作”:如果他們需要花好幾秒鐘去找最大值,那是我們設計者的失職。
- 利用對比:顏色(亮/暗)、大小(大/小)、位置(前/後),這些物理屬性的對比能瞬間觸發大腦的“系統1”(直覺系統)。
下次使用 Matplotlib 繪圖時,在 plt.show() 之前,請停下來問自己一個問題:“我這張圖裏,最想讓讀者第一眼看到的是什麼?”
一旦確定了答案,就請大膽地使用上述技巧,把它“推”到讀者眼前吧!