
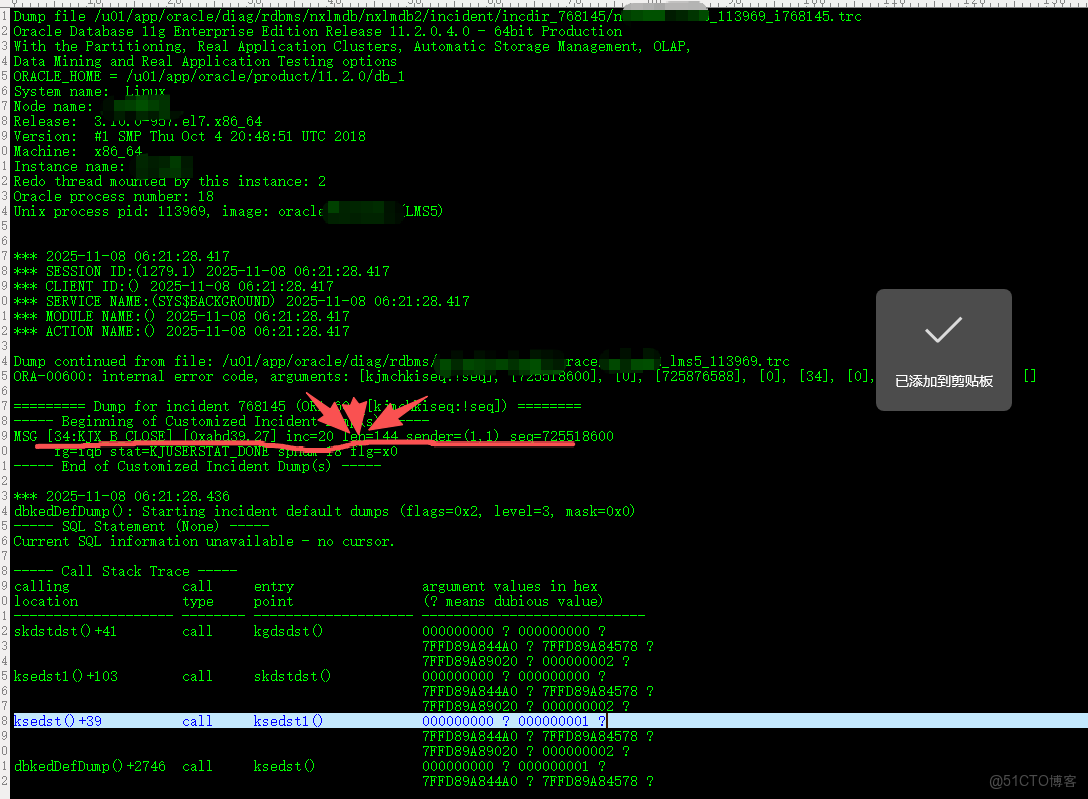
近期某客户現場的數據庫,頻繁重啓。總之差不多都在凌晨重啓。rac1和rac2節點。jdbc配置的鏈接在rac2,客户本地的一些cron在rac1上。每次頻繁重啓都是ORA-600 [ kjctr_pbmsg:badbmsg2] ,lms kill掉進程。
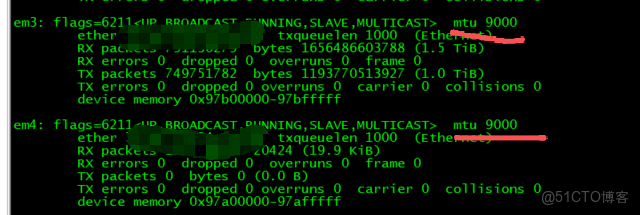
根據MOS相關的解決方案,可以考慮加大私網網卡的MTU,並且交換機支持巨貞協議。
沒有得到解決,還是反覆重啓。
alter system set "_lm_send_queue_batching"=FALSE scope=spfile;
alter system set "_lm_process_batching"=FALSE scope=spfile;
alter system set "_side_channel_batch_size"=57 scope=spfile;
_lm_send_queue_batching: 控制 LMS 發送消息時的批處理,設為 FALSE 禁用批量發送,確保每個消息單獨處理_lm_process_batching: 控制 LMS 接收消息時的批處理,設為 FALSE 禁用批量處理,確保每個消息單獨驗證_side_channel_batch_size: 設置輔助通道消息的最大批處理大小為 57 字節,確保不超過標準 MTU (1500) 的分片限制
那麼有人可能會想。這個在MTU已經在9000的情況下,會不會設定的有點小。默認是200,與mtu 1500 設定的計算關係是怎麼來的。一、_side_channel_batch_size 的作用
- LMS 進程:是 RAC 中負責 Cache Fusion(緩存融合)的核心進程,它在節點間傳遞數據塊和鎖信息。
- 輔助通道 (Side Channel):LMS 進程使用兩種 “通道” 進行通信。
- 主通道:用於傳遞大塊的數據(比如完整的數據塊)。這部分通信受益於您設置的 MTU 9000,因為更大的 MTU 意味着更少的網絡分片和更高的效率。
- 輔助通道:用於傳遞大量的、小的控制消息(比如鎖請求、鎖釋放、狀態通知等)。這些消息本身很小(可能只有幾十個字節),但數量巨大。
_side_channel_batch_size參數決定了 LMS 會將多少個這樣的小消息 “打包” 在一起,形成一個較大的網絡包進行發送。
你可能會覺得,既然 MTU 已經是 9000 了,完全可以容納更大的批次,為什麼還要設置一個這麼小的 57?
這正是問題的關鍵所在。ORA-00600 [kjmchkiseq:!seq] 錯誤的根源,往往不是因為消息太大導致的分片,而是因為在高併發或網絡壓力下,LMS 進程在處理批量消息時出現了內部的邏輯錯誤或競態條件(Race Condition)。
• 問題本質:這個錯誤通常意味着 LMS 進程在驗證消息序列時,發現收到的消息順序不對,或者預期的消息沒有收到。這可能是由於批處理機制在打包或解包時出現了問題。
• 參數的真實作用:將 _side_channel_batch_size 設置為一個較小的值(如 57),可以降低每個批次的 “複雜度”,減少 LMS 進程在處理大批量消息時出錯的概率。這是一種通過 “降低併發粒度” 來換取 “系統穩定性” 的經典調試和優化手段。
• 與 MTU 9000 的關係:MTU 9000 優化的是數據傳輸的物理層效率,而 _side_channel_batch_size 參數調整的是LMS 進程的邏輯層處理方式。這兩者是正交的,針對的是不同層面的問題。即使物理層效率很高,邏輯層的處理邏輯如果存在脆弱性,依然會導致錯誤。
- 從 Trace 文件細節和 Oracle RAC 消息機制來看,有三個明確依據:
- 依據 1:消息代碼 KJXX_B_XXX 是典型的 “控制類消息標識” Oracle RAC 中,節點間傳遞的消息通過 “KJ 系列代碼” 區分類型,核心規則如下: 控制類消息:代碼以 KJXX_B_ 開頭(B 代表 “Block-related Control”,即資源塊相關控制),或 KJMS_(消息服務控制)、KJBR_(Buffer 資源控制)等,用途是 “傳遞指令、狀態、鎖信息”,而非實際數據。 你看到的 KJXX_B_CLOSE 中,CLOSE 直接表明用途是 “關閉某個資源(如鎖資源、緩存塊資源)的控制指令”,屬於典型的控制類消息(類似 “開關指令”)。 數據類消息:代碼以 KJDS_(Data Segment 數據段)、KJST_(Storage 存儲)開頭,用途是傳遞 “實際數據塊”“大事務元數據” 等,比如 KJDS_SEND_BLOCK(傳遞緩存數據塊)。 簡單記:KJXX_B_XXX 是 “控制指令”,KJDS_XXX 是 “數據傳輸”。
- 依據 2:消息長度 len=144 遠小於 “大消息” 閾值 Trace 文件中明確標註 len=12800(不同場景可能有差異,你當前日誌中是 len=144),這個長度是判斷 “小消息” 的關鍵: 控制類小消息:長度通常在 幾十~幾千字節(一般 <4KB),因為僅需攜帶 “指令標識、發送方 / 接收方 ID、狀態標記” 等少量元數據。 比如 KJXX_B_CLOSE 僅需傳遞 “要關閉的資源 ID(spnum=18)、發送節點(1,1)、序列號(seq=725518600)” 等信息,144 字節完全足夠。 大消息:長度通常 ≥ DB_BLOCK_SIZE(你的環境是 8KB),甚至幾 MB,因為要攜帶 “完整數據塊”“大事務的鎖元數據集合” 等。 比如 Oracle 數據塊默認 8KB,傳遞一個完整數據塊的消息長度至少 8KB + 消息頭部(約 40 字節),遠大於 144 字節。
- 依據 3:消息用途不涉及 “數據傳輸” 結合 Trace 中的 spnum=18(資源編號)、stat=KJUSERSTAT_DONE(狀態為 “處理完成”)等字段,可判斷該消息的用途是:節點 1(sender=(1,1))向節點 2 的 LMS5 進程發送 “資源 18 的關閉指令”,僅用於 “資源狀態同步”,不包含任何用户數據或數據塊內容 —— 這是控制類消息的核心特徵(只傳 “指令”,不傳 “數據”)。 二、什麼是 “大消息”?(定義 + 例子 + 特徵) 在 Oracle RAC 中,“大消息” 特指 用於傳遞 “實際數據” 或 “大量元數據”、長度較大的消息,核心是 “承載數據內容”,而非 “控制指令”。
- 大消息的典型場景 場景 1:Cache Fusion 數據塊傳遞 當節點 1 需要讀取節點 2 已緩存的數據塊時,LMS 進程會發送 KJDS_SEND_BLOCK 消息,攜帶完整的 8KB/16KB 數據塊(取決於 DB_BLOCK_SIZE),這類消息長度通常是 “數據塊大小 + 消息頭部(約 40~100 字節)”,屬於典型大消息。 場景 2:大事務的鎖元數據同步 當執行跨節點的大事務(如更新百萬行數據)時,會產生大量鎖信息,LMS 進程會發送 KJBR_SEND_LOCK_METADATA 消息,攜帶成百上千個鎖的元數據,長度可能達到幾十 KB~ 幾 MB。 場景 3:RMAN 跨節點備份數據傳輸 跨節點備份時,數據文件塊通過 RAC 內部消息傳遞,消息長度通常是 “多個數據塊打包”(比如 16 個 8KB 塊,總長度 128KB)。
比如 KJXX_B_CLOSE/KJXX_B_OPEN 這類消息每秒可能產生上千條,批處理(把多個消息打包成一個網絡包)會增加 “消息解包時的序列校驗複雜度”,在公網不穩定環境下極易觸發 kjmchkiseq:!seq 序列錯誤;
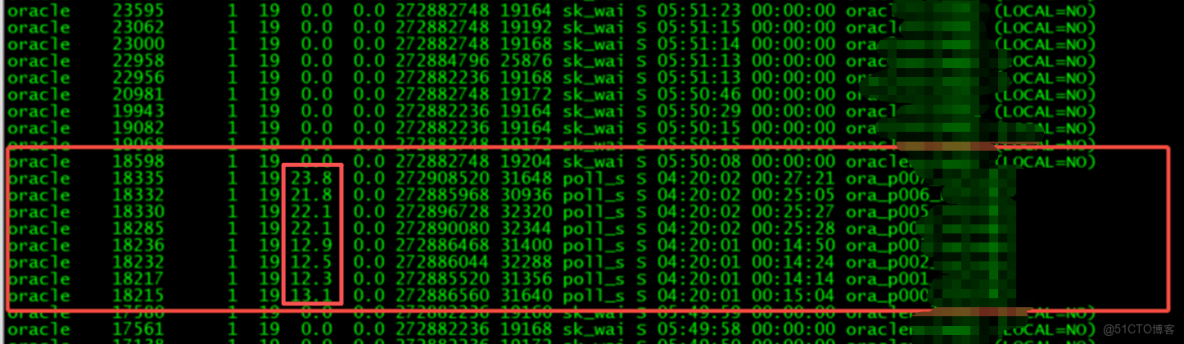
梳理osw監控發現ps進程有p00進程以及cpu某個core使用100%的情況
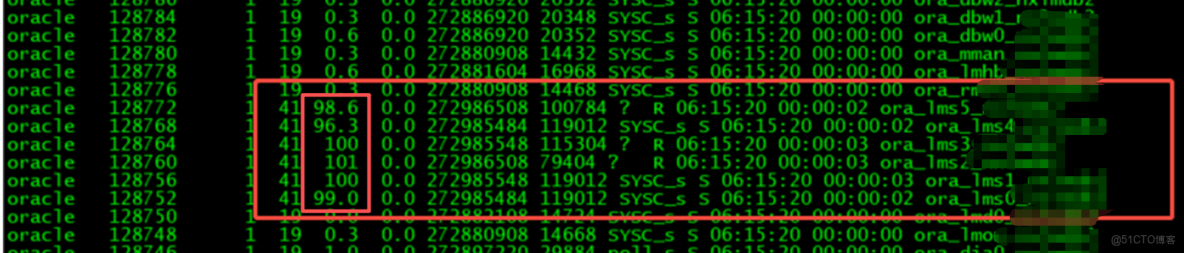
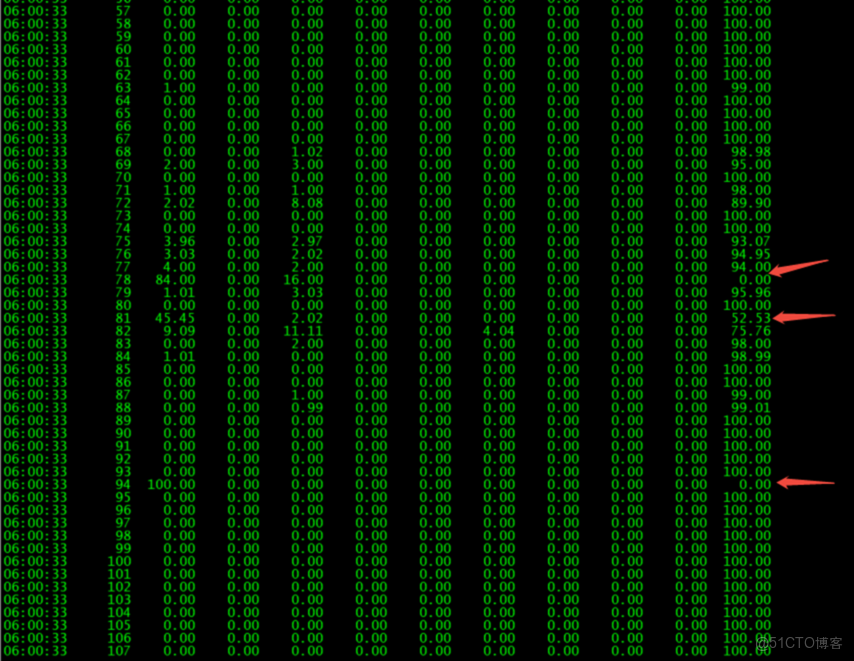
然後檢索了系統與之高度重合的job為DBA自己弄的按用户收集統計信息的job
04:30:01 SYS@db1(db1)> 04:30:01 2 04:30:01 3 04:30:01 4 04:30:01 5 04:30:01 6 04:30:01 7 04:30:01 8 04:30:01 9 04:30:01 10 04:30:01 11 04:30:01 12 04:30:01 13 04:30:01 14 04:30:01 15 04:30:0
1 16 04:30:01 17 04:30:01 18 04:30:01 19 04:30:01 20 04:30:01 21 04:30:01 22 04:30:01 23 04:30:01 24 04:30:01 25 04:30:01 26 04:30:01 27 04:30:01 28 04:30:01 29 04:30:01 30 04:30:01 31 04:30:01 32 04:
30:01 33 04:30:01 34 04:30:01 35 04:30:01 36 04:30:01 37 04:30:01 38 04:30:01 39 04:30:01 40 04:30:01 41 04:30:01 42 DECLARE
*
ERROR at line 1:
ORA-12805: parallel query server died unexpectedly
ORA-06512: at "SYS.DBMS_STATS", line 24281
ORA-06512: at "SYS.DBMS_STATS", line 24332
ORA-06512: at line 33
這個在節點一,然後不斷重啓的是業務節點db2RAC 環境中節點間的通信不穩定。 錯誤原因分析
- 並行查詢的執行機制:當你執行一個並行操作時,協調進程(Query Coordinator)會在當前實例或其他 RAC 實例上啓動多個並行服務器進程(PX Server)。這些 PX Server 進程需要通過集羣 interconnect(私網)進行通信,以交換數據和執行計劃。
- 與 RAC 通信問題的關聯:你之前遇到的 ORA-00600 錯誤根源在於 LMS 進程在處理節點間消息時發現序列錯誤,這説明私網通信存在丟包、亂序或延遲過高的問題。在並行查詢場景下,PX Server 進程之間的通信對網絡穩定性要求很高。如果私網通信不穩定: ◦ PX Server 進程可能無法及時收到來自協調進程或其他 PX Server 的消息。 ◦ 消息的丟失或亂序會導致 PX Server 進程內部狀態不一致。 ◦ 當數據庫檢測到一個 PX Server 進程沒有響應或狀態異常時,為了保護整個實例的穩定性,會主動終止該進程,從而觸發 ORA-12805 錯誤。
- 為什麼在收集統計信息時出現:DBMS_STATS 是一個 I/O 和 CPU 密集型操作,尤其是在對大型表進行並行統計信息收集時: ◦ 它會產生大量的並行查詢。 ◦ 這些查詢需要掃描大量數據塊,可能會引發頻繁的 Cache Fusion 操作(跨節點的數據塊請求)。 ◦ 這使得 DBMS_STATS 成為了暴露 RAC 通信問題的一個 “放大器”。在高負載和頻繁的節點間數據交換下,原本可能不明顯的網絡問題會被放大,導致錯誤發生。

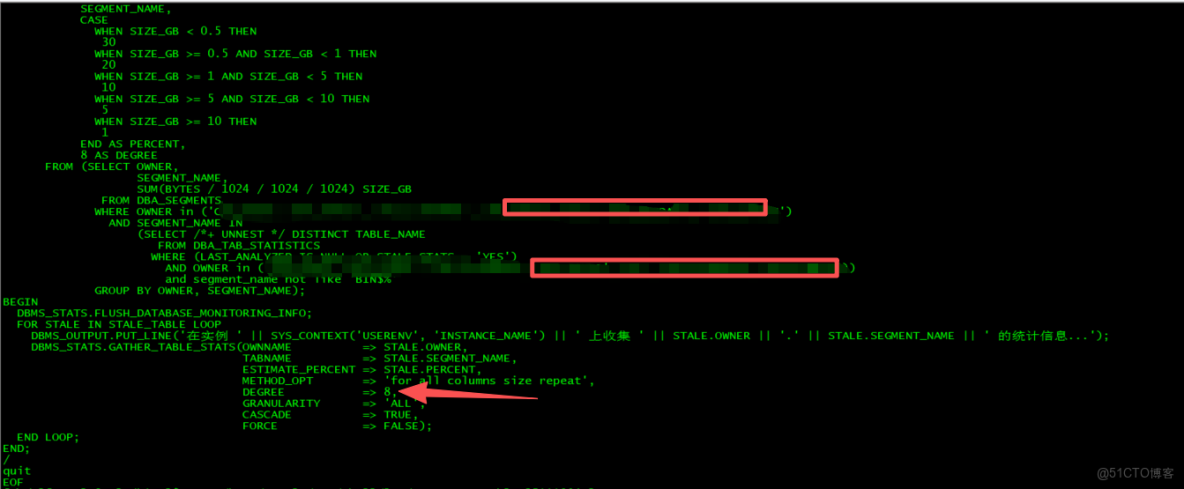
從按用户收集統計信息的job中,去除了大用户。僅保留小用户進行觀察,看看後期還會不會繼續重啓。