

這個故事以一個自白開始:我在很長一段時間都害怕Unicode。每當一個編程任務需要Unicode知識時,我正在尋找一個可破解的解決方案,而沒有詳細瞭解我在做什麼。
我的迴避一直持續到我遇到了一個需要詳細Unicode知識的問題,再也沒法迴避。
經過一些努力,讀了一堆文章——令人驚訝的是,理解它並不難。嗯……有些文章至少需要讀3遍。
事實證明,Unicode是一種通用而優雅的標準。這可能很難,因為有一大堆難以堅持的抽象術語。
如果您在理解Unicode方面有差距,那麼現在正是面對它的時候!沒那麼難。給自己沏杯美味的茶或咖啡☕. 讓我們深入到抽象奇妙的世界。
這篇文章解釋了Unicode的基本概念。這就創造了必要的基礎。
然後闡明JavaScript如何與Unicode協同工作,以及可能遇到的陷阱。
您還將學習如何應用新的ECMAScript 2015特性來解決部分困難。
準備好了嗎?讓我們嗨起來!
1. Unicode背後的理念
讓我們從一個基本問題開始。你如何閲讀和理解當前的文章?簡單地説:因為你知道字母和單詞作為一組字母的含義。
為什麼你能理解字母的意思?簡單地説:因為你(讀者)和我(作者)在圖形符號(屏幕上看到的東西)和英語字母(意思)之間的關聯上達成了一致。
計算機也是如此。不同之處在於計算機不理解字母的含義:它們認為這些只是一些字節。
設想一個場景,當用户1通過網絡向用户2發送消息“hello”。
用户1的計算機不知道字母的含義。因此,它將“hello”轉換為一個數字序列0x68 0x65 0x6C 0x6C 0x6F,其中每個字母唯一地對應一個數字:h是0x68,e是0x65,等等。這些數字被髮送到用户2的計算機。
當用户2的計算機接收到數字序列0x68 0x65 0x6C 0x6C 0x6F時,它將使用數字對應的字母並還原消息。然後它會顯示正確的消息:“hello”。
這兩台計算機之間關於字母和數字之間對應關係的協議是Unicode標準化的。
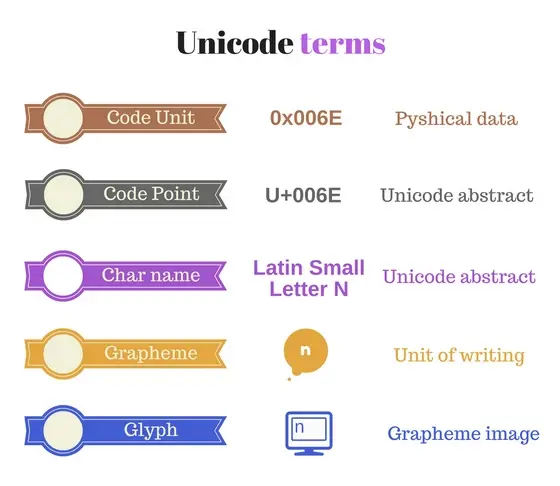
依據Unicode,h是一個名為拉丁小寫字母h的抽象字符。該字符具有相應的數字0x68,代碼點表示為U+0068。
Unicode的作用是提供一個抽象字符列表(字符集),併為每個字符分配一個唯一的標識符代碼點(編碼字符集)。
2.Unicode的基本術語
www.unicode.org提到:“Unicode為每個字符提供唯一的數字,”,與平台、編程和語言無關。
Unicode是一種通用字符集,用於定義大多數書寫系統中的字符列表,併為每個字符關聯一個唯一的數字(代碼點)。

Unicode包括來自當今大多數語言的字符、標點符號、變音符號、數學符號、技術符號、箭頭、表情符號等等。
第一個Unicode版本1.0於1991年10月發佈,共有7161個字符。最新版本9.0(於2016年6月發佈)提供了128172個字符的代碼。
Unicode的通用性和包容性解決了以前存在的一個主要問題,當時供應商實現了許多難以處理的字符集和編碼。
創建一個支持所有字符集和編碼的應用程序非常複雜。
如果您認為Unicode很難,那麼沒有Unicode的編程將更加困難。
我仍然記得我讀着文件內容中的亂碼,就跟買彩票一樣!
2.1字符和代碼點
“抽象字符(或字符)是用於組織、控制或表示文本數據的信息單元。”
Unicode將字符作為抽象術語處理。每個抽象字符都有一個相關的名稱,例如拉丁字母(LATIN SMALL LETTER)A。該字符的呈現形式(字形)為a。
“代碼點是一個分配給單個字符的數字。”
代碼點的範圍是U+0000到U+10FFFF。
U+<hex>是代碼點的格式,其中U+是表示Unicode的前綴,<hex>是十六進制的數字。例如,U+0041和U+2603。
請記住,代碼點就是一個簡單的數字。你應該這樣想,代碼點是元素在數組中的一個索引。
因為Unicode將一個代碼點與一個字符相關聯,所以產生了神奇的效果。例如,U+0041對應於名為拉丁大寫字母(LATIN CAPITAL LETTER)A的字符(渲染為A),或者U+2603對應於名為雪人(SNOWMAN)的字符(渲染為☃).
並非所有代碼點都具有相應的字符。1114112個代碼點可用(範圍從U+0000到U+10FFFF),但只有137929個代碼點分配了字符(截至2019年5月)。
2.2 Unicode平面
“平面(Plane)是一個從U+n0000到U+nFFFF,總共有65536個持續的Unicode代碼點的範圍,其中n取值範圍是0x0~0x10”
平面將Unicode代碼點分成17個相等的組:
- 平面0包含從
U+0000到U+FFFF的代碼點, - 平面1包含從
U+10000到U+1FFFF的代碼點 - ...
- 平面16包含從
U+100000到U+10FFFF的代碼點

基本多文種平面
平面0是一個特殊的平面,稱為基本多文種平面( Basic Multilingual Plane)或簡稱BMP。它包含來自大多數現代語言(基本拉丁語)、西里爾語)、希臘語等)的字符和大量符號。
如上所述,基本多文種平面的代碼點在U+0000到U+FFFF之間,最多可以有4個十六進制數字。
開發人員通常處理BMP中的字符。它包含大多數必需的字符。
BMP中的某些字符:
e是U+0065,命名為拉丁文小寫字母e|是U+007C,命名為豎線■是U+25A0,命名為黑色正方形☂是U+2602,命名為傘
星形平面
其他16個超過BMP的平面(平面1、平面2、...平面16)被稱為星形平面(astral planes)或者輔助平面(supplementary planes)。
星形平面裏的代碼點被稱為星形代碼點,它的範圍從U+10000到U+10FFFF。
星形代碼點可以有5到6個十六進制數字,如 U+ddddd、U+dddddd。
例子如下:
𝄞是U+1D11E,命名為音樂符號G譜號𝐁是U+1D401,命名為數學黑體大寫字母B🀵是U+1F035,命名為多米諾水平標題-00-04😀是U+1F600,命名為笑臉
2.3 代碼單元
計算機在內存中不使用代碼點或抽象字符。它需要一種物理方式來表示Unicode代碼點:代碼單元(code units)。
“代碼單元是一個位序列,用於對給定編碼形式中的每個字符進行編碼。”
字符編碼將抽象代碼點轉換為物理位:代碼單元。
換句話説,字符編碼將Unicode代碼點轉換為唯一的代碼單元序列。
流行的編碼有UTF-8、UTF-16和UTF-32。
大多數JavaScript引擎使用UTF-16編碼。這會影響JavaScript使用Unicode的方式。從現在開始,讓我們專注於UTF-16。
UTF-16(長名稱:16位Unicode轉換格式)是一種可變長度編碼:
- BMP中的代碼點使用16位的單個代碼單元進行編碼
- 星形代碼點使用兩個16位的編碼單元進行編碼。
我們來舉幾個例子。
假設你想將拉丁小寫字母 a 保存到硬盤驅動器。 Unicode 告訴你 丁小寫字母 a 映射到 U+0061 代碼點。
現在讓我們詢問UTF-16編碼U+0061應該如何轉換。編碼規範規定,對於BMP代碼點,取其十六進制數U+0061,並將其存儲到一個16位的代碼單元中:0x0061。
如你所見,BMP中的代碼點適合於單個16位代碼單元。
2.4 代理對
現在讓我們研究一個複雜的案例。假設你要保存一個星形代碼點(來自星形平面): 笑臉😀 。此字符映射到 U+1F600 代碼點。
由於星形代碼點需要 21 位來保存信息,因此 UTF-16 表示你需要兩個 16 位的代碼單元。代碼點 U+1F600 被分成所謂的代理對:0xD83D(高代理代碼單元,high-surrogate code unit)和 0xDE00(低代理代碼單元,low-surrogate code unit)。
引用
“代理對(Surrogate pair)是單個抽象字符的表示,它由兩個 16 位代碼單元的代碼單元序列組成,其中該對的第一個值是高代理代碼單元,第二個值是低代理代碼單元。”
星形代碼點需要兩個代碼單元:代理對。正如您在前面的示例中看到的那樣,要在 UTF-16 中對 U+1F600 (😀) 進行編碼,將使用代理對:0xD83D 0xDE00。
console.log('\uD83D\uDE00'); // => '😀'
高代理項代碼單元取值範圍為0xD800到0xDBFF。低代理代碼單元取值範圍為0xDC00到0xDFFF。
將代理對轉換為星形代碼點的算法如下所示,反之亦然:
function getSurrogatePair(astralCodePoint) {
let highSurrogate =
Math.floor((astralCodePoint - 0x10000) / 0x400) + 0xD800;
let lowSurrogate = (astralCodePoint - 0x10000) % 0x400 + 0xDC00;
return [highSurrogate, lowSurrogate];
}
getSurrogatePair(0x1F600); // => [0xD83D, 0xDE00]
function getAstralCodePoint(highSurrogate, lowSurrogate) {
return (highSurrogate - 0xD800) * 0x400
+ lowSurrogate - 0xDC00 + 0x10000;
}
getAstralCodePoint(0xD83D, 0xDE00); // => 0x1F600處理代理對並不舒服。在 JavaScript 中處理字符串時,您必須將它們作為特殊情況處理,如下文所述。
但是,UTF-16 在內存中是高效的。 99%的字符來自BMP,這些字符只需要一個代碼單元。
組合標記
在一個特定的書寫系統的上下文中,一個字形(grapheme)或符號(symbol)是一個最小的獨特的書寫單位。
字形是從用户的角度看待字符。屏幕上顯示的一個圖形的具體圖像稱為字形(glyph)。
在大多數情況下,單個Unicode字符表示單個圖形。例如,U+0066 拉丁文小寫字母表示英文字母 f 。
在某些情況下,字形包含一系列字符。
例如,å 是丹麥書寫系統中的一個原子字形。它使用U+0061拉丁文小寫字母A(呈現為A)和特殊字符U+030A(呈現為 ◌̊)COMBINING RING ABOVE).
U+030A 修飾前置字符,命名為組合標記(combining mark)。
console.log('\u0061\u030A'); // => 'å'
console.log('\u0061'); // => 'a'“組合標記是一個應用於前一個基本字符的字符,用於創建字形。”
組合標記包括重音符號、變音符號、希伯來文點、阿拉伯元音符號和印度語字母等字符。
組合標記通常在沒有基本字符的情況下不單獨使用。您應該避免單獨顯示它們。
與代理對一樣,組合標記在 JavaScript 中也很難處理。
組合字符序列(基本字符 + 組合標記)被用户區分為單個符號(例如 '\u0061\u030A' 是 'å')。但是開發者必須確定使用U+0061 和 U+030A 這2個代碼點來構造 å 。
3. JavaScript 中的 Unicode
ES2015 規範提到源代碼文本使用 Unicode(5.1 及更高版本)表示。源文本是從 U+0000 到 U+10FFFF 的代碼點序列。源代碼的存儲或交換方式與 ECMAScript 規範無關,但通常以 UTF-8(web首選編碼方式)編碼。
我建議使用Basic Latin Unicode block) (或ASCII)中的字符保留源代碼文本。ASCII以外的字符應轉義。這將確保編碼方面的問題更少。
在內部,在語言層面,ECMAScript 2015 提供了一個明確的定義,JavaScript 中的字符串是什麼:
字符串類型是零或多個16位無符號整數值(“元素”)的所有有序序列的集合,最大長度為(2的53次方減1)個元素。字符串類型通常用於表示正在運行的ECMAScript程序中的文本數據,在這種情況下,字符串中的每個元素都被視為UTF-16代碼單位值。
字符串的每個元素都被引擎解釋為一個代碼單元。字符串的呈現方式不能確定它包含哪些代碼單元(代表代碼點)。請參閲以下示例:
console.log('cafe\u0301'); // => 'café'
console.log('café'); // => 'café''cafe\u0301'和'café'文字的代碼單元稍有不同,但它們都呈現為相同的符號序列café。
字符串的長度是其中的元素(16位的代碼單元)的數目。[...]當ECMAScript操作解釋字符串值時,每個元素被解釋為單個UTF-16代碼單元。
正如你從上述章節的代理對和組合標記中知道的那樣,某些符號需要 2 個或更多代碼單元來表示。所以在統計字符數或按索引訪問字符時要注意:
const smile = '\uD83D\uDE00';
console.log(smile); // => '😀'
console.log(smile.length); // => 2
const letter = 'e\u0301';
console.log(letter); // => 'é'
console.log(letter.length); // => 2smile 字符串包含 2 個代碼單元:\uD83D(高代理)和 \uDE00(低代理)。由於字符串是一系列代碼單元,smile.length 的計算結果為 2。即使渲染的 smile 僅有一個符號 '😀'。
letter字符串也是相同的情況。組合標記 U+0301 應用在前一個字符e上,渲染結果為符號'é'。但是 letter 包含 2 個代碼單元,因此 letter.length 為 2。
我的建議:始終將 JavaScript 中的字符串視為一系列代碼單元。字符串的呈現方式無法清楚説明它包含哪些代碼單元。
星形平面的符號和組合字符序列需要編碼2個或更多的代碼單元。但它們被視為一個單一的字形(grapheme)。
如果字符串具有代理對或組合標記,開發人員在沒有記住這一要點的情況下去計算字符串的長度或者按索引訪問字符時會感覺到困惑。
大多數JavaScript字符串方法都不支持Unicode。如果字符串包含複合Unicode字符,請在調用myString.slice()、myString.substring()等時採取預防措施。
3.1 轉義序列
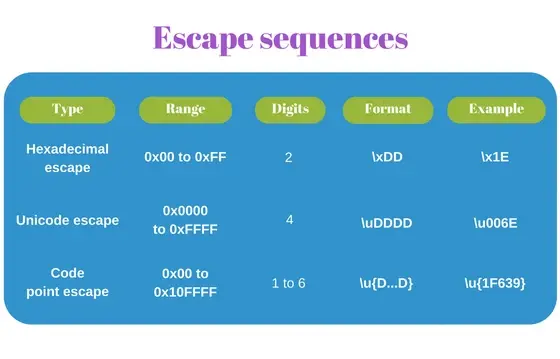
JavaScript 字符串中的轉義序列用於表示基於代碼點編號的代碼單元。 JavaScript 有 3 種轉義類型,一種是在 ECMAScript 2015 中引入的。
讓我們更詳細地瞭解它們。
十六進制轉義序列
最短的形式被命名為十六進制轉義序列:\x<hex>,其中 \x 是一個前綴,後跟一個固定長度為 2 位的十六進制數字 <hex>。
例如'\x30'(符號'0')或'\x5B'(符號'[')。
字符串文字或正則表達式中的十六進制轉義序列如下所示:
const str = '\x4A\x61vaScript';
console.log(str); // => 'JavaScript'
const reg = /\x4A\x61va.*/;
console.log(reg.test('JavaScript')); // => true十六進制轉義序列可以轉義有限範圍內的代碼點:從 U+00 到 U+FF,因為只允許使用 2 位數字。但是十六進制轉義很好,因為它很短。
Unicode 轉義序列
如果你想轉義整個BMP中的代碼點,請使用 unicode 轉義序列。轉義格式為 \u<hex>,其中 \u 是前綴後跟一個固定長度為 4 位的十六進制數 <hex>。例如'\u0051'(符號'Q')或'\u222B'(積分符號'∫')。
讓我們使用 unicode 轉義序列:
const str = 'I\u0020learn \u0055nicode';
console.log(str); // => 'I learn Unicode'
const reg = /\u0055ni.*/;
console.log(reg.test('Unicode')); // => trueUnicode 轉義序列可以轉義有限範圍內的代碼點:從 U+0000 到 U+FFFF(所有 BMP 代碼點),因為只允許使用 4 位數字。大多數情況下,這足以表示常用的符號。
要在 JavaScript 文字中指示星形平面的符號,請使用兩個連接的 unicode 轉義序列(高代理和低代理),這將創建代理對:
const str = 'My face \uD83D\uDE00';
console.log(str); // => 'My face 😀'代碼點轉義序列
ECMAScript 2015 提供了表示整個Unicode空間的代碼點的轉義序列:U+0000 到 U+10FFFF,即BMP 和星形平面。
新格式稱為代碼點轉義序列:\u{<hex>},其中 <hex> 是一個長度為 1 到 6 位的十六進制數。
例如'\u{7A}'(符號'z')或'\u{1F639}'(笑臉貓符😹)。
const str = 'Funny cat \u{1F639}';
console.log(str); // => 'Funny cat 😹'
const reg = /\u{1F639}/u;
console.log(reg.test('Funny cat 😹')); // => true請注意,正則表達式 /\u{1F639}/u 有一個特殊標誌u,它啓用額外的 Unicode 功能。(有關詳細信息,請參見3.5正則表達式匹配。)
我喜歡代碼點轉義序列來表示星形符號,而不是代理對。
讓我們來轉義帶光環的笑臉符號😇U+1F607代碼點。
const niceEmoticon = '\u{1F607}';
console.log(niceEmoticon); // => '😇'
const spNiceEmoticon = '\uD83D\uDE07'
console.log(spNiceEmoticon); // => '😇'
console.log(niceEmoticon === spNiceEmoticon); // => true分配給變量 niceEmoticon 的字符串文字有一個代碼點轉義符 '\u{1F607}' ,表示一個星體代碼點 U+1F607。接着,創建了一個代理對(2 個代碼單元)。如您所見,spNiceEmoticon 是使用一對 unicode 轉義符 '\uD83D\uDE07' 的代理對
創建的,它等於 niceEmoticon。
當使用 RegExp 構造函數創建正則表達式時,在字符串文字中,您必須將每個 \ 替換為 \\ ,表示這是unicode 轉義。以下正則表達式對象是等效的:
const reg1 = /\x4A \u0020 \u{1F639}/;
const reg2 = new RegExp('\\x4A \\u0020 \\u{1F639}');
console.log(reg1.source === reg2.source); // => true字符串比較
JavaScript中的字符串是代碼單元序列。可以合理地預期,字符串比較涉及對匹配的代碼單元進行求值。
這種方法快速有效。它可以很好地處理“簡單”字符串:
const firstStr = 'hello';
const secondStr = '\u0068ell\u006F';
console.log(firstStr === secondStr); // => truefirstStr和secondStr字符串具有相同的代碼單元序列。它們是相等的。
假設您要比較呈現的兩個字符串,它們看起來相同但包含不同的代碼單元序列。那麼你可能會得到一個意想不到的結果,因為在比較中看起來相同的字符串並不相等:
渲染時 str1 和 str2 看起來相同,但具有不同的代碼單元。
發生這種情況是因為 ç 字形可以通過兩種方式構建:
- 使用
U+00E7,帶有變音符的拉丁小寫字母c - 或者使用組合字符序列:
U+0063拉丁小寫字母c,加上組合標記U+0327組合變音符。
如何處理這種情況並正確比較字符串?答案是字符串規範化。
規範化
規範化(Normalization)是將字符串轉換為規範表示,以確保規範等效(和/或兼容性等效)字符串具有唯一表示。
換句話説,當字符串具有組合字符序列或其他複合結構的複雜結構時,您可以將其規範化為規範形式。規範化的字符串可以輕鬆比較或執行文本搜索等字符串操作。
Unicode標準附錄#15提供了有關規範化過程的有趣細節。
在JavaScript中,要規範化字符串,請調用myString.normalize([normForm])方法,該方法在ES2015中提供。normForm是一個可選參數(默認為“NFC”),可以採用以下規範化形式之一:
'NFC'作為規範化形式的標準組合'NFD'作為規範化形式規範分解'NFKC'作為規範化形式兼容性組合'NFKD'作為規範化形式兼容性分解
讓我們通過應用字符串規範化來改進前面的示例,這將允許正確比較字符串:
const str1 = 'ça va bien';
const str2 = 'c\u0327a va bien';
console.log(str1 === str2.normalize()); // => true
console.log(str1 === str2); // => false'ç' 和 'c\u0327' 在規範上是等價的。
當調用 str2.normalize() 時,將返回 str2 的規範版本('c\u0327' 被替換為 'ç')。所以比較 str1 === str2.normalize() 按預期返回 true 。
str1 不受規範化的影響,因為它已經是規範形式了。
規範化兩個比較的字符串,以獲得兩個操作數上的規範表示似乎是合理的。
3.3 字符串長度
確定字符串長度的常用方法當然是訪myString.length屬性。此屬性表示字符串具有的代碼單元數。
屬於BMP的代碼點的字符串長度的計算通常按預期得到:
const color = 'Green';
console.log(color.length); // => 5color字符串中的每個代碼單元對應着一個單獨的字素。字符串的預期長度為5。
長度和代理對
當字符串包含代理對來表示星形代碼點時,情況變得棘手。由於每個代理對包含 2 個代碼單元(高代理和低代理),因此長度屬性大於預期。
看一個例子:
const str = 'cat\u{1F639}';
console.log(str); // => 'cat😹'
console.log(str.length); // => 5當 str 字符串被渲染時,它包含 4 個符號 cat😹。然而,str.length 的計算結果為 5,因為 U+1F639 是用 2個代碼單元(代理對)編碼的星形代碼點。
不幸的是,目前還沒有解決該問題的原生的和高性能的方法。
至少 ECMAScript 2015 引入了識別星形符號的算法。星形符號被視為單個字符,即使使用 2 個代碼單元進行編碼。
字符串迭代器 String.prototype[@@iterator]()是支持Unicode的。您可以將字符串與擴展運算符 [...str] 或 Array.from(str) 函數結合使用(兩者都使用字符串迭代器)。然後計算返回數組中的符號數。
請注意,此解決方案在廣泛使用時可能會造成輕微的性能問題。
讓我們用擴展運算符改進上面的例子:
const str = 'cat\u{1F639}';
console.log(str); // => 'cat😹'
console.log([...str]); // => ['c', 'a', 't', '😹']
console.log([...str].length); // => 4長度和組合標記
那麼組合字符序列呢?因為每個組合標記都是一個代碼單元,所以您可能會遇到相同的困難。
該問題在規範化字符串時得到解決。如果幸運的話,組合字符序列將規範化為單個字符。讓我們試試:
const drink = 'cafe\u0301';
console.log(drink); // => 'café'
console.log(drink.length); // => 5
console.log(drink.normalize()) // => 'café'
console.log(drink.normalize().length); // => 4Drink 字符串包含 5 個代碼單元(因此drink.length 為 5),即使渲染它也顯示 4 個符號。
不幸的是,規範化不是一個通用的解決方案。長組合字符序列在一個符號中並不總是具有規範的等價物。讓我們看看這樣的案例:
const drink = 'cafe\u0327\u0301';
console.log(drink); // => 'cafȩ́'
console.log(drink.length); // => 6
console.log(drink.normalize()); // => 'cafȩ́'
console.log(drink.normalize().length); // => 5Drink 有 6 個代碼單元,drink.length 的計算結果為 6。但是,drink 有 4個符號。
規範化 Drink.normalize() 將組合序列 'e\u0327\u0301' 轉換為兩個字符 'ȩ\u0301' 的規範形式(通過僅刪除一個組合標記)。遺憾的是,drink.normalize().length 的計算結果為 5,但仍然沒有表示正確的符號數。
字符定位
由於字符串是一系列代碼單元,因此通過索引訪問字符串中的字符也存在困難。
當字符串僅包含 BMP 字符時(不包括從 U+D800 到 U+DBFF 的高代理和從 U+DC00 到 U+DFFF 的低代理),字符定位沒有什麼問題。
const str = 'hello';
console.log(str[0]); // => 'h'
console.log(str[4]); // => 'o'每個符號都使用單個代碼單元進行編碼,因此通過索引訪問字符串字符是正確的。
字符定位和代理對
當字符串包含星形符號時,情況會發生變化。
星形符號使用 2 個代碼單元(代理對)進行編碼。因此通過索引訪問字符串字符可能會返回一個分隔的高代理或低代理,它們是無效符號。
以下示例訪問星形符號中的字符:
const omega = '\u{1D6C0} is omega';
console.log(omega); // => '𝛀 is omega'
console.log(omega[0]); // => '' (unprintable symbol)
console.log(omega[1]); // => '' (unprintable symbol)因為U+1D6C0大寫字母OMEGA(MATHEMATICAL BOLD CAPITAL OMEGA)是一個星形字符,所以它使用2個代碼單元的代理對進行編碼。omega[0]訪問高代理項代碼單元,omega[1]訪問低代理項,從而分離代理對。
在一個字符串中存在2種正確訪問星形符號的可能性:
- 使用字符串迭代器並生成符號數組
[…str][index] - 使用
number = myString.codePointAt(index)獲取代碼點編號,然後使用String.fromCodePoint(number)(推薦選項)將數字轉換為符號。
讓我們同時應用這兩個選項:
const omega = '\u{1D6C0} is omega';
console.log(omega); // => '𝛀 is omega'
// Option 1
console.log([...omega][0]); // => '𝛀'
// Option 2
const number = omega.codePointAt(0);
console.log(number.toString(16)); // => '1d6c0'
console.log(String.fromCodePoint(number)); // => '𝛀'[…omega]返回omega字符串包含的符號數組。代理對的計算是正確的,因此訪問第一個字符的效果與預期的一樣。[...smile][0] 是'𝛀'。
omega.codePointAt(0) 方法調用是支持Unicode的,因此它返回 omega 字符串中第一個字符的星形代碼點編號0x1D6C0。函數 String.fromCodePoint(number) 返回基於代碼點編號的符號:'𝛀'。
字符定位和組合標記
帶有組合標記的字符串中的字符定位與上述字符串長度存在相同的問題。
通過字符串中的索引訪問字符就是訪問代碼單元。然而,組合標記序列應該作為一個整體來訪問,而不是分成單獨的代碼單元。
下面的例子演示了這個問題:
const drink = 'cafe\u0301';
console.log(drink); // => 'café'
console.log(drink.length); // => 5
console.log(drink[3]); // => 'e'
console.log(drink[4]); // => ◌́Drink[3] 只訪問基本字符 e,沒有組合標記 U+0301 COMBINING ACUTE ACCENT(呈現為 ◌́ )。
Drink[4] 訪問孤立的組合標記 ◌́ 。
在這種情況下,應用字符串規範化。組合字符序列 U+0065 LATIN SMALL LETTER e 和 U+0301 COMBINING ACUTE ACCENT ◌́ 具有標準等價物 U+00E9 LATIN SMALL LETTER E WITH ACUTE é。讓我們改進前面的代碼示例:
const drink = 'cafe\u0301';
console.log(drink.normalize()); // => 'café'
console.log(drink.normalize().length); // => 4
console.log(drink.normalize()[3]); // => 'é'請注意,並非所有組合字符序列都具有作為單個符號的標準等價物。所以規範化字符串方案並不通用。
幸運的是,它應該適用於歐洲/北美語言的大多數情況。
正則表達式匹配
正則表達式和字符串一樣,都是按照代碼單元運行的。與之前描述的場景類似,這在處理代理對和使用正則表達式組合字符序列時會產生困難。
BMP 字符按預期匹配,因為單個代碼單元表示一個符號:
const greetings = 'Hi!';
const regex = /.{3}/;
console.log(regex.test(greetings)); // => truegreetings有3個字符,即3個代碼單元。正則表達式 /.{3}/表達式能成功匹配。
在匹配星形符號(用 2 個代碼單元的代理對編碼)時,您可能會遇到困難:
const smile = '😀';
const regex = /^.$/;
console.log(regex.test(smile)); // => falsesmile字符串包含星形符號 U+1F600 GRINNING FACE。 U+1F600 使用代理對 0xD83D 0xDE00 進行編碼。
然而,正則表達式 /^.$/期望匹配一個代碼單元,所以失敗了。
用星形符號定義字符類時情況更糟。 JavaScript 拋出一個錯誤:
const regex = /[😀-😎]/;
// => SyntaxError: Invalid regular expression: /[😀-😎]/:
// Range out of order in character class星形代碼點被編碼為代理對。因此 JavaScript 使用代碼單元 /[\uD83D\uDE00-\uD83D\uDE0E]/ 來表示正則表達式。每個代碼單元都被視為模式中的一個單獨元素,因此正則表達式忽略了代理對的概念。
字符類的 \uDE00-\uD83D 部分無效,因為 \uDE00 大於 \uD83D。結果,正則表達式產生錯誤。
正則表達式 u 標誌
幸運的是,ECMAScript 2015 引入了一個有用的 u 標誌,使正則表達式能夠識別 Unicode。該標誌可以正確處理星形符號。
您可以在正則表達式 /u{1F600}/u 中使用 unicode 轉義序列。此轉義比指示高代理和低代理對 /\uD83D\uDE00/ 更短。
讓我們應用 u 標誌,看看.運算符(包括量詞 ?, +, * 和 {3}, {3,}, {2,3})如何匹配星形符號:
const smile = '😀';
const regex = /^.$/u;
console.log(regex.test(smile)); // => true/^.$/u 正則表達式,由於u標誌,支持匹配Unicode,現在就能匹配星形字符 😀 。
u 標誌也可以正確處理字符類中的星形符號:
const smile = '😀';
const regex = /[😀-😎]/u;
const regexEscape = /[\u{1F600}-\u{1F60E}]/u;
const regexSpEscape = /[\uD83D\uDE00-\uD83D\uDE0E]/u;
console.log(regex.test(smile)); // => true
console.log(regexEscape.test(smile)); // => true
console.log(regexSpEscape.test(smile)); // => true[😀-😎]匹配一個範圍內的星形字符,可以匹配'😀'。
正則表達式和組合標記
不幸的是,無論有沒有 u 標誌,正則表達式都會將組合標記視為單獨的代碼單元。
如果需要匹配組合字符序列,則必須分別匹配基字符和組合標記。
看看下面的例子:
const drink = 'cafe\u0301';
const regex1 = /^.{4}$/;
const regex2 = /^.{5}$/;
console.log(drink); // => 'café'
console.log(regex1.test(drink)); // => false
console.log(regex2.test(drink)); // => true字符串被渲染成4個字符café。
然而,正則表達式匹配 'cafe\u0301' 作為 5 個元素的序列 /^.{5}$/.
4.總結
在JavaScript中,關於Unicode最重要的概念可能是將字符串視為代碼單元序列,因為它們實際上是這樣的。
當開發者認為字符串是由字素(或符號)組成,而忽略了代碼單元序列概念時,就會出現混淆。
它在處理包含代理對或組合字符序列的字符串時會產生誤解:
- 獲取字符串長度
- 字符定位
- 正則表達式匹配
請注意,JavaScript 中的大多數字符串方法並不完全支持 Unicode:如 myString.indexOf()、myString.slice() 等。
ECMAScript 2015 引入了一些不錯的功能,例如字符串和正則表達式中的代碼點轉義序列 \u{1F600}。
新的正則表達式標誌 u 支持識別 Unicode 的字符串匹配。它使匹配星形符號變得更簡單。
字符串迭代器 String.prototype[@@iterator]() 是 支持Unicode。您可以使用擴展運算符 [...str] 或 Array.from(str) 創建符號數組,並在不破壞代理對的情況下計算字符串長度或按索引訪問字符。請注意,這些操作會對性能產生一些影響。
如果您需要更好的方法來處理 Unicode 字符,您可以使用 punycode 庫或generate庫生成專門的正則表達式。
希望這篇文章對你掌握Unicode有幫助!