

本文介紹了 Twilio Segment 團隊將服務端事件轉發基礎設施從微服務架構遷移為單體架構的實踐,介紹了遷移的背景、權衡和需要考慮的方面。原文:Goodbye Microservices: From 100s of problem children to 1 superstar
微服務是一種面向服務的軟件架構,通過結合多種單一用途、低佔用的網絡服務構建服務端應用,其宣稱的好處包括改進模塊化、降低測試負擔、更好的功能組合、環境隔離以及開發團隊自主性。相反,單體架構將大量功能集中在單一服務中,作為整體進行測試、部署和擴展。
Twilio Segment 早期就採納了這一做法,這在某些情況下很有幫助,但我們很快發現,在另一些情況下則不那麼理想。
在 Twilio Segment 早期,產品的核心部分達到了臨界點,感覺就像是從微服務的大樹上掉了下來,撞上了每一根樹枝。小團隊不僅沒有讓我們加快速度,反而陷入了爆炸式增長的複雜性中,微服務架構的優勢變成了負擔。隨着速度驟降,缺陷率爆炸式增長。
團隊最終發現無法取得進展,三名全職工程師大部分時間都在維持系統的運轉。必須做出改變,本文講述了團隊如何後退一步,採納了一種產品需求和團隊需求高度契合的方法。
微服務為何有效
Twilio Segment 的客户數據基礎設施每秒接收數十萬事件,並將其轉發到合作伙伴 API,也就是 服務器端目的地。這些目的地有一百多種類型,比如 Google Analytics、Optimizely,或自定義 Webhook。
多年前這款產品剛推出時,架構非常簡單,有一個可以導入事件並將其轉發到分佈式消息隊列的 API,事件是由網頁或移動應用生成的 JSON 對象,包含用户及其操作信息。
消費隊列中的事件時,會檢查客户設置以決定哪些目的地應接收該事件,隨後將其依次發送到每個目的地 API。這很方便,因為開發者只需將事件發送到單個端點 —— Twilio Segment 的 API,而無需對每一個都構建集成,Twilio Segment 會負責向每個目標端點發送請求。
如果某個請求失敗,有時會在稍後嘗試再次發送該事件。有些失敗可以安全重試,而有些則不行。可重試錯誤是指目標方可能接受的錯誤,並且不需要更改請求。例如,HTTP 500、速率限制和超時。不可重試錯誤是指我們可以確定目的地永遠不會接受的請求。例如,無效憑證或缺少必填字段的請求。
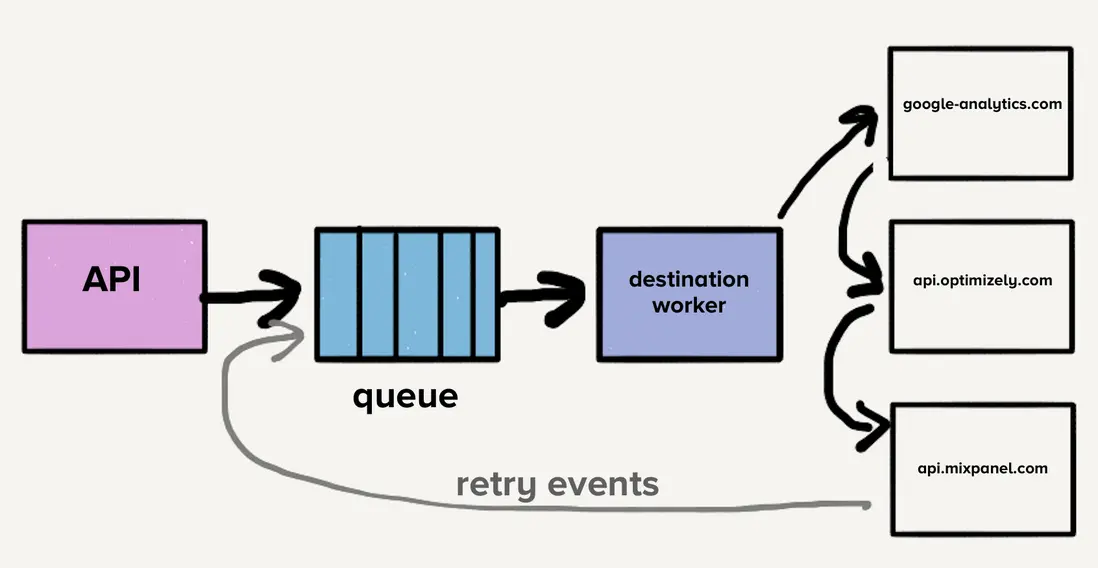
上圖展示了隊列包含最新事件以及可能的多次重試事件,涵蓋所有目的地,導致 隊列頭阻塞(head-of-line blocking)。也就是説,在這種情況下,如果某個目的地變慢或宕機,重試會淹沒隊列,導致所有目的地都出現延遲。
想象一下,目的地 X 出現了臨時問題,每個請求都會出錯並超時。這不僅會造成大量尚未到達目的地 X 的請求積壓,而且每個失敗事件都會被重新放回隊列中重試。雖然系統會根據負載自動擴容,但隊列深度的突然增加會超過擴容能力,導致最新事件延遲。由於目的地 X 發生了短暫停機,造成所有目的地的發送時間都會增加。客户依賴交付的及時性,因此我們不能承受流水線中任何等待時間的增加。
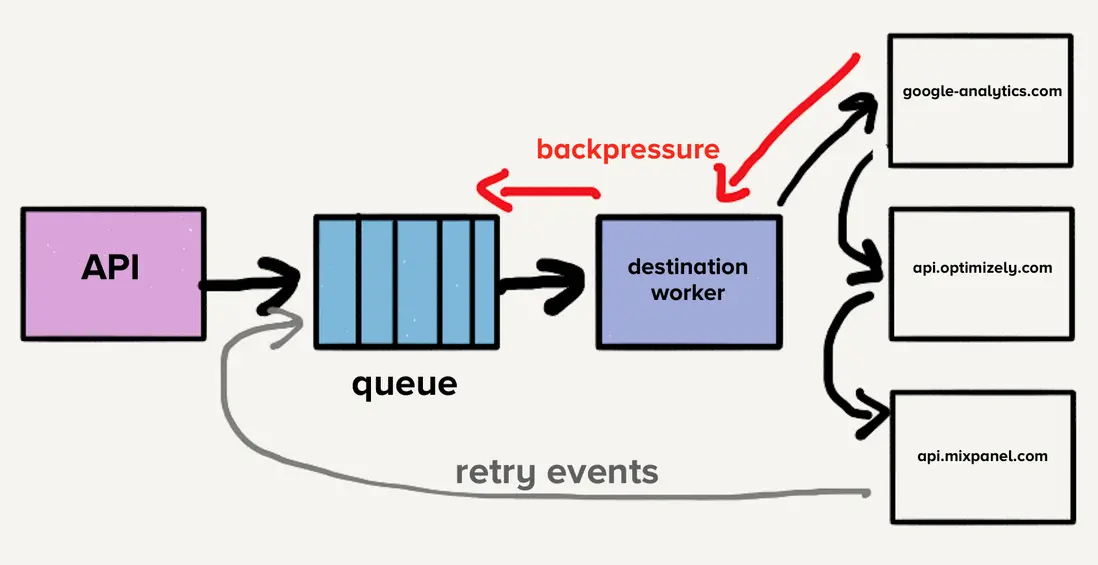
為了解決隊列頭阻塞問題,團隊為每個目的地創建了獨立的服務和隊列。該新架構包含一個額外的路由進程,接收入站事件並將事件副本分發到每個選定的目的地。如果一個目的地出現問題,只有對應隊列會積壓,其他目的地不會受到影響。這種微服務式架構將目的地彼此隔離開來,這在某個目的地出現問題時至關重要。
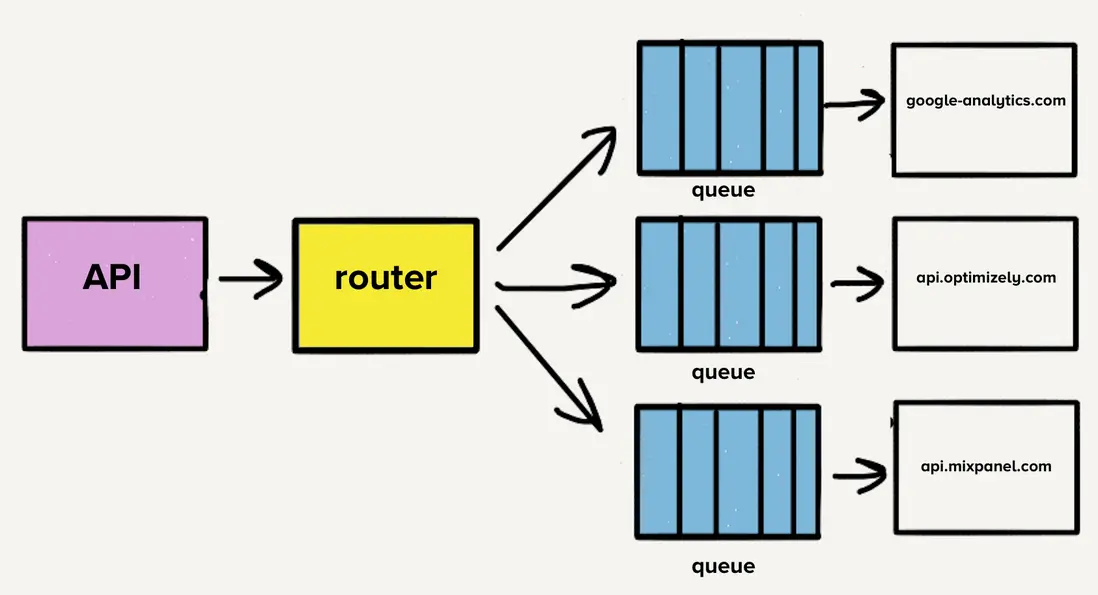
獨立倉庫的理由
每個目標 API 使用不同請求格式,需要自定義事件轉換代碼以匹配該格式,例如目的地 X 需要在負載中發送 birthday 作為 traits.dob,而我們的 API 則接受 traits.birthday。
許多現代目標端點採用了 Twilio Segment 的請求格式,使得某些轉換相對簡單。然而,轉換也可能非常複雜,完全取決於目標 API 結構。例如,對於一些較老且規模很大的目的地,需要將數值塞入手工拼接的 XML 負載中。
最初,當目的地被劃分為獨立服務時,所有代碼都存放在同一個倉庫中。一個很大的問題是,如果某個測試失誤導致所有目的地的測試都失敗,當我們想部署變更時,即使這些失敗與變更無關,我們也得花時間修復那個壞掉的測試。針對這一問題,團隊決定將每個目的地的代碼拆分到各自倉庫中。由於所有目的地都已劃分為獨立的服務,因此這一過渡相當自然。
拆分到不同倉庫讓團隊能夠輕鬆隔離目標測試套件,這種隔離性使開發團隊能夠快速維護目的地。
擴展微服務和倉庫
隨着時間推移,我們新增了 50 多個目的地,也就是新增了 50 多個倉庫。為了減輕開發和維護代碼庫的負擔,我們創建了共享庫,讓通用轉換和功能(如 HTTP 請求處理)可以在各目的地之間更簡單、更統一的共享。
例如,如果我們想獲取某個事件中的用户名,可以在任意目的地的代碼中調用 event.name()。共享庫會檢查事件中的屬性鍵名和名稱,如果沒有,就會檢查 firstName、first_name 和 FirstName 這些屬性。對姓氏的檢查也一樣,然後將兩者合併成全名。
共享庫讓新目標的構建變得更快,統一的共享功能帶來的熟悉感讓維護工作不再那麼麻煩。
然而新問題開始出現。對共享庫的測試和部署變更影響了所有的目的地,維護起來需要大量時間和精力。為了改進庫而做出的變更,必須測試和部署數十項服務,是一項風險極高的舉動。在時間緊迫時,工程師只會將這些庫的更新版本納入單一目標代碼庫。
隨着時間推移,共享庫的版本開始在不同目標代碼庫中出現分裂,曾經的巨大好處開始逆轉,最終不同服務都使用了共享庫的不同版本。我們本可以開發自動化推送變更的工具,但此時不僅開發者生產力下降,我們還開始遇到微服務架構的其他問題。
另一個問題是,每個服務都有獨特的負載模式。有些服務每天處理少量事件,而另一些則每秒處理數千事件。對於處理少量事件的目的地,在遇到意外負載激增時,運維人員必須手動擴大服務規模以滿足需求。
雖然實現了自動擴展,但每個服務對 CPU 和內存資源的需求差異很大,使得調整自動擴展配置更像是藝術而非科學。
目的地數量持續快速增長,團隊平均每月新增三個目的地,這意味着更多的倉庫、更多的隊列以及更多的服務。由於微服務架構,運維開銷隨着每個目的地的增加而線性增長。因此,我們決定後退一步,重新思考整個流程。
放棄微服務和隊列
首先考慮的是將現已超過 140 個的微服務整合為單一服務。管理所有這些服務的開銷對團隊來説是巨大的負擔。我們甚至無法睡覺,值班工程師經常被叫起來處理負載激增。
然而,當時的架構使得遷移到單一服務變得具有挑戰性。如果每個目的地有獨立隊列,每個員工都必須檢查每個隊列的工作,這會給目的地服務增加複雜性,我們對此感到不放心。這正是 Centrifuge 的主要靈感來源,Centrifuge 將替換所有單獨隊列,負責將事件發送到單一服務。(注意,Centrifuge 成為了 Connections 的後端基礎設施。)
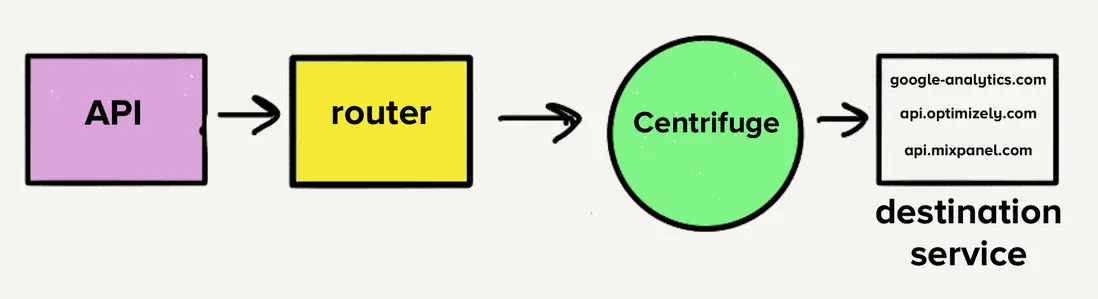
單體倉庫遷移
鑑於只有一個服務,將所有目標代碼遷移到一個倉庫中是合理的,這意味着將所有不同的依賴和測試合併到一個倉庫中。
對於 120 個獨特依賴,我們承諾為所有目的地提供一個版本。當我們遷移目的地時,會檢查它使用的依賴,並更新到最新版本,並修復出現問題的目的地。
通過這次遷移,我們不再需要追蹤依賴版本之間的差異,所有的目的地都使用同一個版本,大大降低了整個代碼庫的複雜性。維護目的地變得更省時、風險更低。
我們還希望有一個測試套件,能夠快速輕鬆的運行所有目的地測試,而運行所有測試是之前更新共享庫時的主要障礙之一。
幸運的是,目的地測試的結構都比較相似,有基本的單元測試來驗證自定義轉換邏輯是否正確,並會向合作伙伴端點執行 HTTP 請求,以驗證事件是否如預期出現在目的地。
回想一下,最初將每個目標代碼庫分開到獨立倉庫的動機是為了隔離測試失敗。然而,事實證明這是一種虛假的優勢,發送 HTTP 請求的測試仍然經常失敗。目的地被分開到各自的倉庫,幾乎沒有動力去清理失敗的測試。這種糟糕的習慣導致技術債務持續堆積,通常本應只需一兩個小時的小變更,最終卻需要幾天到一週時間才能完成。
構建強韌的測試套件
測試運行期間向目標端點發出的 HTTP 請求是測試失敗的主要原因。像過期證書這樣無關的問題不應該讓測試失敗。我們也從經驗中知道,有些目的地端點比其他端點要慢得多。有些目的地的測試時間長達 5 分鐘。我們的測試套件覆蓋 140 多個目的地,運行時間可能長達一小時。
為了解決這兩個問題,我們基於 yakbak 創建了 Traffic Recorder,負責記錄和保存目的地的測試流量。每個測試首次運行時,所有請求及其對應的響應都會被記錄到文件中。在後續測試中,文件中的請求和響應會被回放,而不用請求目標端點。這些文件會被記錄在倉庫中,確保每次變更的測試保持一致。現在測試套件不再依賴互聯網上的 HTTP 請求,使得測試更有彈性,成為遷移到單一倉庫的必備條件。
在集成 Traffic Recorder 後,完成所有 140 多個目的地的測試只需要幾毫秒。而以前單單完成一個目的地的測試可能都需要幾分鐘時間。
為什麼單體有效
一旦所有目的地代碼都集中在一個倉庫中,就可以合併成一個服務。隨着每個目的地都集中在同一服務中,開發者生產力大幅提升。我們不再需要為某個共享庫的變更部署 140 多個服務,一名工程師可以在幾分鐘內就完成部署。
變更速度也證明了這一點。在微服務架構時期,我們對共享庫進行了 32 項改進。而在遷移為單體架構一年後,我們已經做了 46 項改進。
這一變化也優化了我們的運維。由於每個目的地都集中在一個服務中,使得 CPU 和內存密集型的目的地被良好組合在一起,從而讓服務擴展更加容易。龐大的算力池能吸收負載峯值,因此團隊不需要半夜被叫起來處理問題。
權衡
從微服務架構轉向單體架構帶來了巨大進步,但也需權衡利弊:
- 錯誤隔離很難。由於所有功能都運行在單體中,如果某個目的地出現了導致服務崩潰的 bug,所有目的地的服務都會崩潰。我們有全面的自動化測試,但測試只能做到一定程度。我們目前正在研發一種更為強大的方法,防止一個目的地造成整個服務癱瘓,同時保持所有目的地的整體狀態。
- 內存緩存效果較差。此前,每個目的地只提供一項服務,低流量目的地只有少數進程,意味着它們的內存緩存會保持控制平面數據的活躍狀態。現在緩存分散在 3000 多個進程中,被命中的可能性大大降低。我們可以用 Redis 之類的工具來解決這個問題,但那又是另一個需要考慮的擴展點。最終,鑑於運維帶來的顯著收益,我們接受了效率的損失。
- 更新依賴版本可能會導致多個目的地被破壞。雖然把所有東西遷移到一個倉庫解決了之前的依賴問題,但意味着如果我們想使用最新版本的庫,可能需要更新其他目的地以配合新版本。不過我們認為,值得為這一簡單性付出代價。藉助全面的自動化測試套件,我們可以快速查看新版本依賴中存在的問題。
結論
最初的微服務架構曾經有效,通過隔離目的地解決了當時流水線的性能問題。但是隨着規模擴大,當需要批量更新時,缺乏合適的工具來測試和部署微服務。結果,我們的開發者生產力迅速下降。
轉向單體架構讓我們擺脱了流程中的運維問題,同時顯著提升了開發者生產力。不過這個轉變絕非輕率,如果想要成功,必須考慮一些因素。
- 需要堅實可靠的測試套件,把所有東西放進一個倉庫。沒有這些,我們會陷入當初決定分開他們時同樣的境地。過去不斷的測試失敗影響了工作效率,我們不希望這種情況再次發生。
- 接受單體架構固有的利弊,並確保權衡了兩者的優劣,我們必須接受變化帶來的一些犧牲。
在選擇微服務還是單體架構時,需要考慮不同的因素。在我們基礎設施的某些部分,微服務運行良好,但我們的服務器端目的地恰好説明了這一流行趨勢實際上會損害生產力和性能。事實證明,適合我們的解決方案是單體架構。
Hi,我是俞凡,一名兼具技術深度與管理視野的技術管理者。曾就職於 Motorola,現任職於 Mavenir,多年帶領技術團隊,聚焦後端架構與雲原生,持續關注 AI 等前沿方向,也關注人的成長,篤信持續學習的力量。在這裏,我會分享技術實踐與思考。歡迎關注公眾號「DeepNoMind」,星標不迷路。也歡迎訪問獨立站 www.DeepNoMind.com,一起交流成長。
本文由mdnice多平台發佈