
- 為什麼選擇 Dify + Ollama
- Ollama 本地部署
- Dify 本地容器化部署
- 模型接入與知識庫 RAG 構建
- 準備 Embedding 模型
- 在 Dify 中添加 Ollama 模型供應商
- 構建知識庫
- 檢索測試
- 構建智能體應用
- 創建應用
- 編排界面概覽
- 查詢預處理
- 關聯知識庫
- 編寫提示詞
- 調整模型參數
- 調試與發佈
- Python API 調用實戰
- 獲取 API 密鑰
- 環境準備
- 編寫腳本
你是否也有過這樣的經歷:當汽車儀表盤上突然跳出一個陌生的黃色故障燈,或者你想調整後視鏡的倒車下翻功能,卻不得不從副駕手套箱裏翻出那本厚達 400 頁、封皮都快粘連的《用户使用手冊》。你試圖在目錄中尋找關鍵詞,翻到第 218 頁,卻發現還有“參見第 56 頁”的跳轉。在那一刻,你一定希望有一個懂行的老司機坐在旁邊,你只需問一句:“這個像茶壺一樣的燈亮了是什麼意思?”,他就能立馬告訴你答案。在 AI 大模型時代,這個願望已經可以零成本實現。今天這篇博客,將帶大家實戰一個非常典型的 RAG(檢索增強生成) 場景:利用開源工具 Dify 和本地大模型工具 Ollama,搭建一個能夠完全讀懂你汽車手冊的 AI 智能體。完成後,不僅可以通過 Web 界面與它對話,還能通過 Python API 將其集成到其他應用中。
為什麼選擇 Dify + Ollama
在開始動手之前,先聊聊為什麼選擇這套技術棧。市面上有很多構建 AI 應用的方法,比如像之前博客介紹的那樣直接用 LangChain 手搓,或者使用雲端的 API,但對於不懂編程、不懂技術的用户,Dify + Ollama 是目前性價比最高、上手最快的選擇。
Ollama:之前已經介紹過了,它是目前在本地運行大語言模型(LLM)最簡單的工具。不需要複雜的環境配置,不需要研究 PyTorch,只需一行命令,就能在 PC 上運行 Llama 3、Qwen 2.5 等開源模型,最重要的是,它是本地化的,隱私絕對安全。
Dify:如果説 Ollama 提供了“大腦”,那麼 Dify 就提供了“身體”和“四肢”,使模型具備了一些“能力”。Dify 是一個開源的 LLM 應用開發平台,它解決了 LLM 開發中最常見的問題:知識庫的切片與索引、Prompt 的編排、上下文記憶的管理,以及對外提供標準的 API 接口。它是低代碼的,幾乎不需要寫代碼就能搭出一個企業級的 AI 應用。
在接下來的教程中,將完成以下操作:
- 環境搭建:在本地部署 Ollama 和 Dify。
- 模型接入:讓 Dify 連接上本地運行的 Qwen2.5 模型。
- 知識庫構建:上傳《用户手冊》PDF,通過 RAG 技術讓 AI “學會”手冊的內容。
- 智能體編排:調試 Prompt,讓它根據用户手冊回答問題。
- API 調用:編寫 Python 腳本調用搭建好的智能體,實現問答。
操作用到的用户手冊可在此處下載:https://oss.mpdoc.com/doc/2026/01/10/CA60DABA002540C5894B85DA2DB46E14.pdf?attname=BMW_用户手冊_01405A7D339.pdf
Ollama 本地部署
Ollama 的安裝極度簡化,幾乎是“開箱即用”。直接訪問 Ollama 官網 https://ollama.com/download 下載安裝包即可。Linux 使用官方的一鍵安裝腳本 curl -fsSL https://ollama.com/install.sh | sh。安裝完成後,在命令行輸入 ollama -v,看到版本號即表示安裝成功。
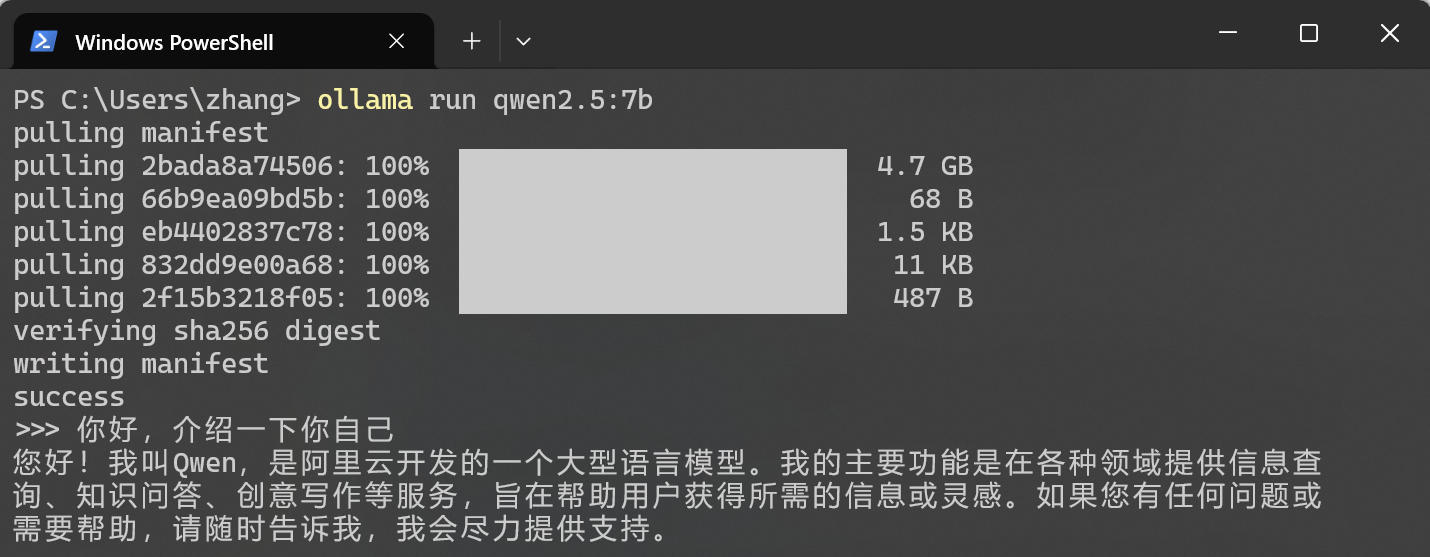
訪問 https://ollama.com/search 可以查看 Ollama 支持的模型,這裏選擇 Qwen2.5-7B 版本(70 億參數,平衡了速度和智能)。在命令行中執行 ollama run qwen2.5:7b,等待模型下載完成(大約 5GB),即可在本地運行該模型。下載完成後,會直接進入對話框。你可以試着問它:“你好,介紹一下你自己。” 如果它能流暢回覆,説明模型已經激活。按 Ctrl + D 退出對話模式,模型會在後台繼續運行。
Dify 本地容器化部署
為了保證環境的純淨和易於管理,官方推薦使用 Docker Compose 進行部署。首先,確保你的機器上安裝了 Docker 和 Docker Compose(https://www.docker.com)。下面需要將 Dify 的代碼倉庫下載到本地。在命令行中執行以下命令 git clone --depth 1 https://github.com/langgenius/dify.git,如果你本地沒有安裝 Git,也可以直接去 GitHub 頁面下載 ZIP 壓縮包並解壓。
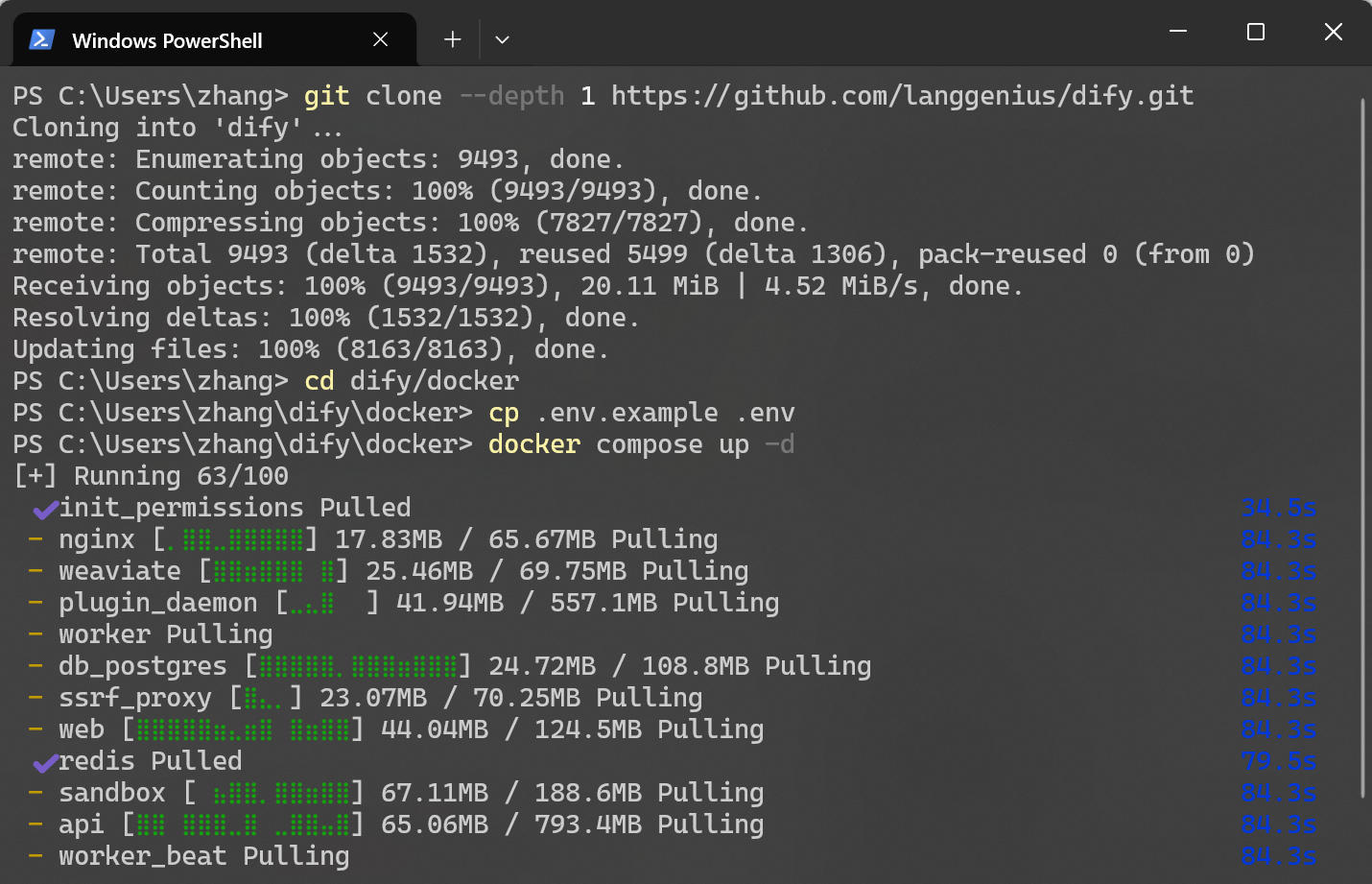
Dify 是一個完整的應用架構,包含前端、後端、數據庫(PostgreSQL)、緩存(Redis)和向量數據庫(Weaviate/Qdrant)等多個組件。手動安裝這些組件非常繁瑣,但通過 Docker Compose,可以一鍵拉起所有服務。進入目錄並執行以下命令,初次運行需要拉取多個 Docker 鏡像。
# 進入 docker 目錄
cd dify/docker
# 複製環境變量配置文件
cp .env.example .env
# 啓動容器
docker compose up -d
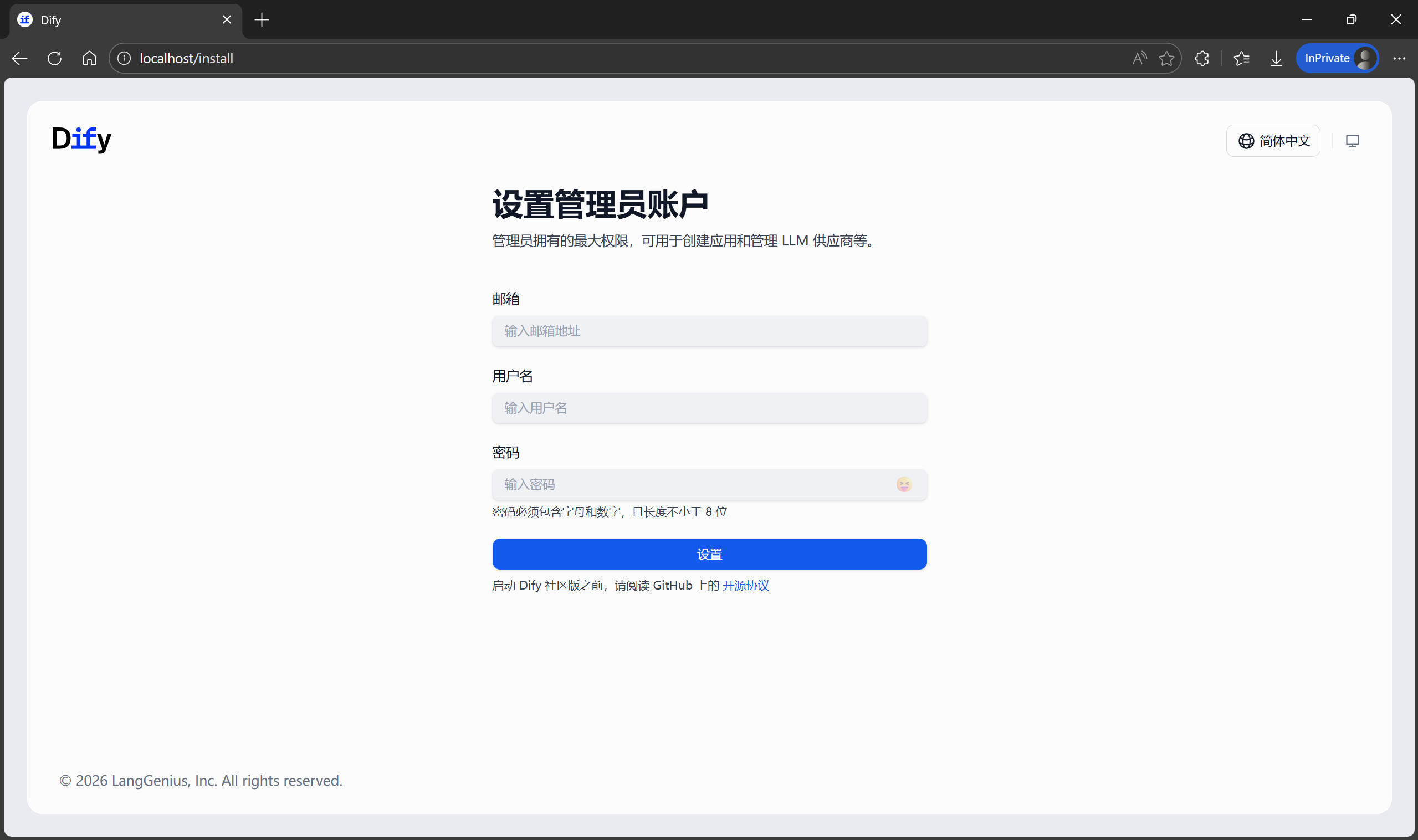
等待所有容器啓動完畢後,打開瀏覽器,訪問 http://localhost/install,你將看到 Dify 的初始化引導界面。在這裏設置你的管理員賬號和密碼。設置完成後,即可登錄進入 Dify。
模型接入與知識庫 RAG 構建
環境搭建完畢後,目前的 Dify 還是一個“空殼”。下面需要做兩件事:
- 把 Ollama 的模型接入 Dify,讓它擁有對話和理解能力;
- 把《用户手冊》餵給它,構建向量知識庫。
準備 Embedding 模型
在構建知識庫時,除了對話模型,還需要一個專門的 Text Embedding(文本向量化)模型。之前的博客已經介紹了 Embedding 的概念,簡單來説,它的作用是把手冊裏的文字變成計算機能理解的“數字向量”。打開命令行,拉取輕量級向量模型 ollama pull nomic-embed-text。
在 Dify 中添加 Ollama 模型供應商
回到 Dify 的網頁界面:
- 點擊右上角的
頭像 -> 設置 -> 模型供應商。 - 找到 Ollama 卡片,點擊“安裝”。
- 安裝完成後,點擊 Ollama 卡片中的“添加模型”。
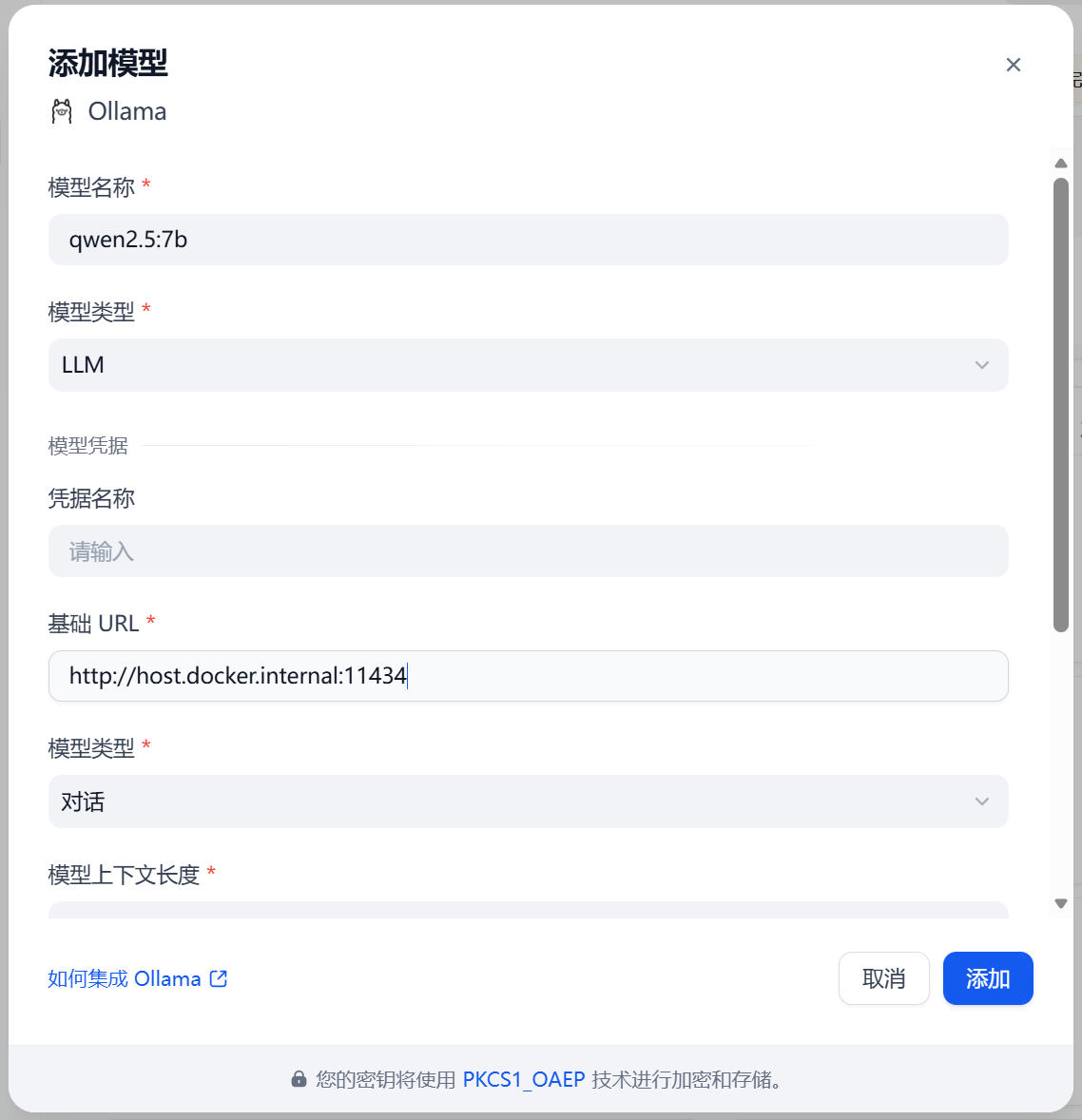
這裏需要添加兩次:
第一次:添加 LLM(對話模型)
- 模型名稱:qwen2.5:7b(必須與你在命令行 ollama list 查看到的名稱完全一致)
- 模型類型:LLM
- 基礎 URL:http://host.docker.internal:11434(Docker 容器訪問宿主機的地址)
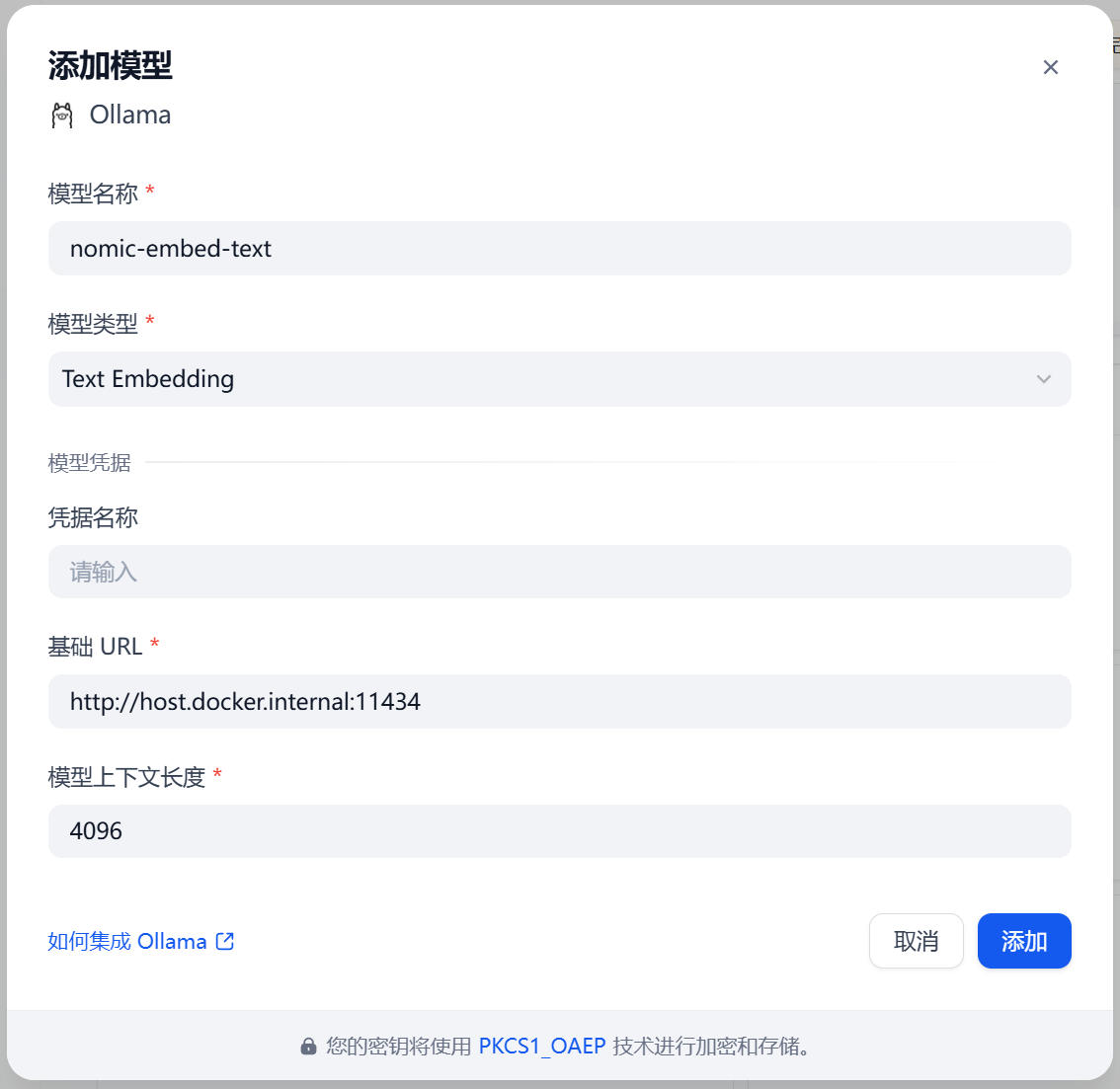
第二次:添加 Text Embedding(向量模型)
- 模型名稱:nomic-embed-text
- 模型類型:Text Embedding
- 基礎 URL:同上
如果保存時提示“Error”,請檢查 Ollama 能否通過 URL http://localhost:11434 訪問,或者 Docker 網絡配置和防火牆設置。
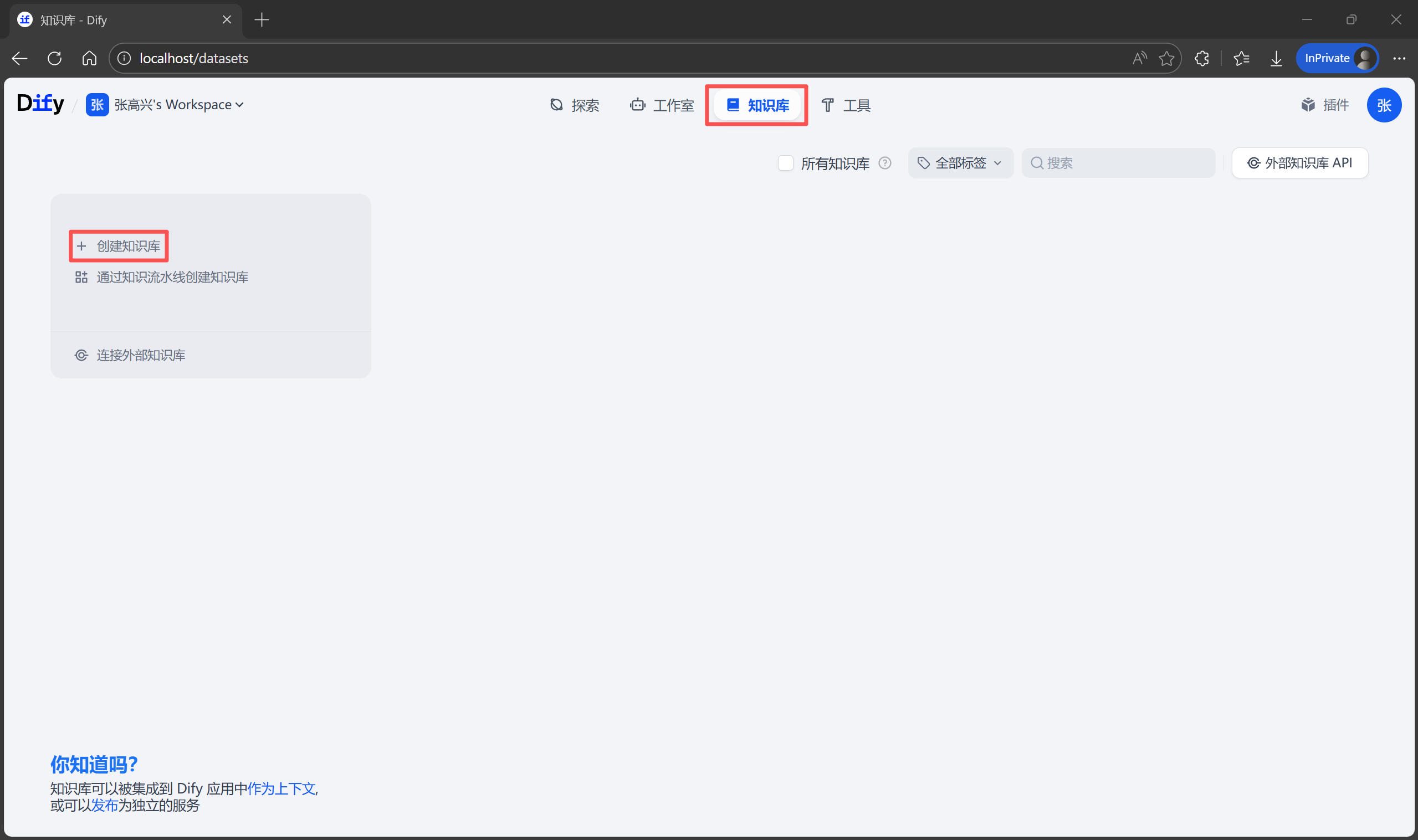
構建知識庫
- 點擊頂部導航欄的
知識庫 -> 創建知識庫。
- 上傳文檔:選擇“導入已有文本”,將
用户手冊.pdf拖進去,點擊“下一步”。
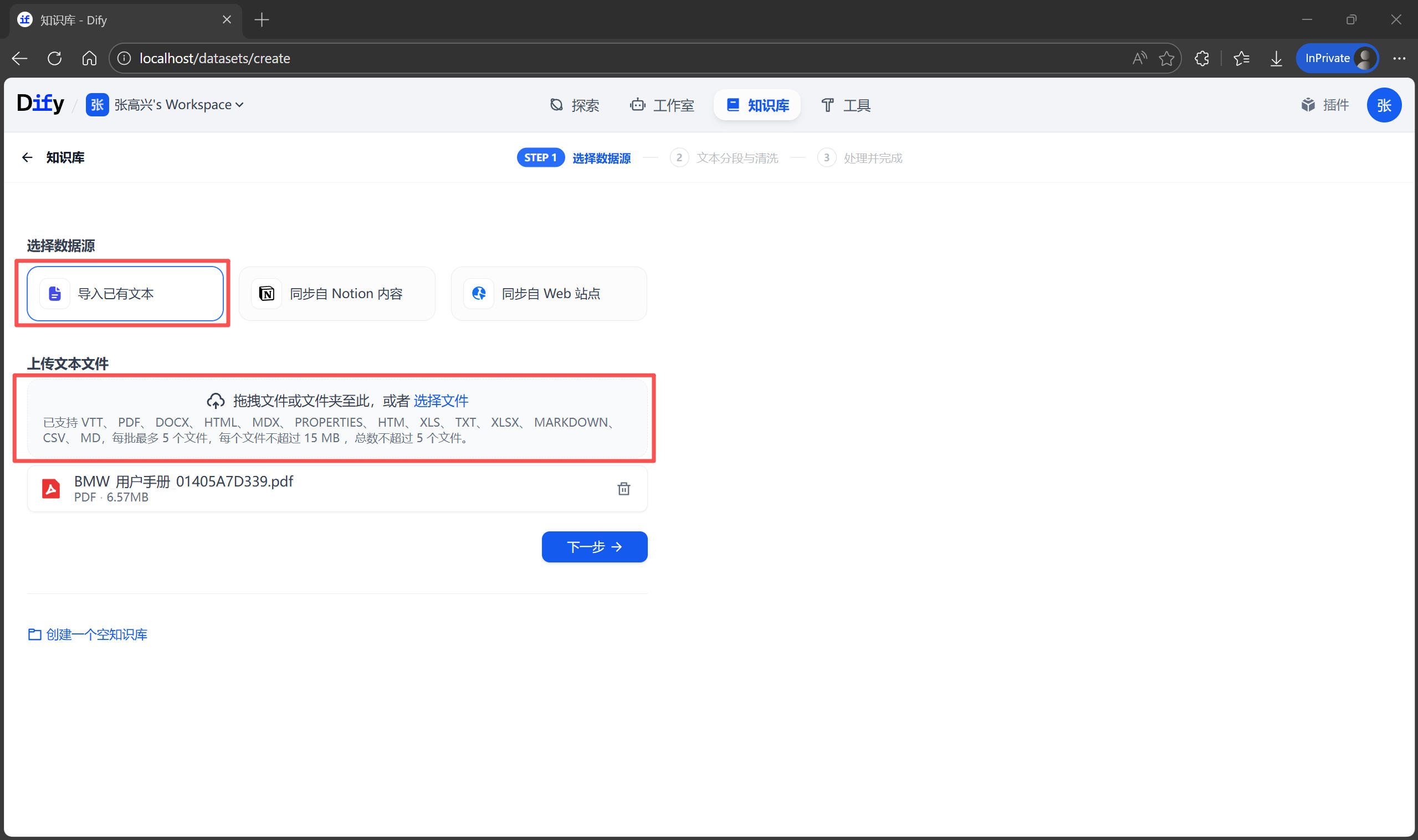
- 分段(Chunk)設置:這裏需要配置如何將 PDF 拆解成小段落,方便後續檢索。
- 分段標識符:文檔段落之間是怎樣分隔的。
\n表示換行符,例如此處上傳的文檔段落之間就是通過換行符分隔的,有些時候可能會使用雙換行符\n\n,即兩個段落之間有一個空行。
- 最大分段長度:決定了 AI “一口吃多少東西”。如果設置得太小,知識庫會被切得過碎,影響檢索效果;如果設置得太大,AI 可能無法有效利用上下文。
- 分段重疊長度*:相鄰段落之間重疊的字符數,有助於保持上下文連續性。
- 使用 Q&A 分段:如果你的文檔是“問答”類型的,開啓此選項可以讓 Dify 識別問答對,提升檢索效果。
- 分段標識符:文檔段落之間是怎樣分隔的。
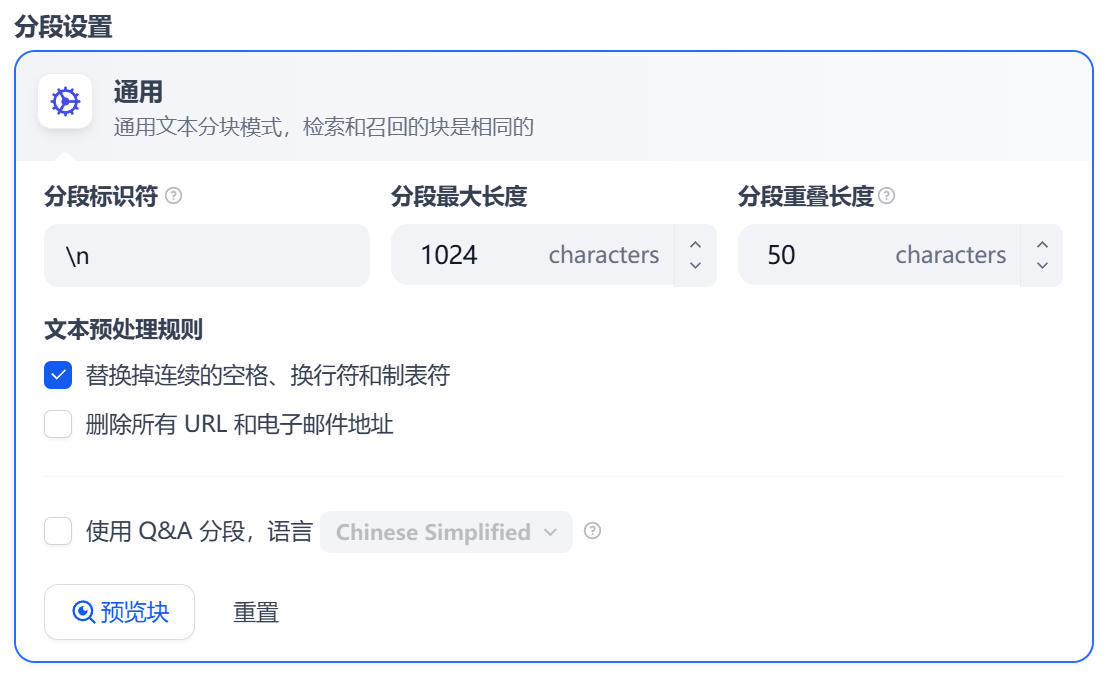
- 索引方式:選擇 “高質量”,這會調用剛才配置的
nomic-embed-text模型進行向量化處理。
- 點擊 “保存並處理”。

此時,Dify 會將幾百頁的 PDF 拆解成小段,轉換成向量,並存入內置的向量數據庫中。根據文檔大小,這可能需要較長的時間。
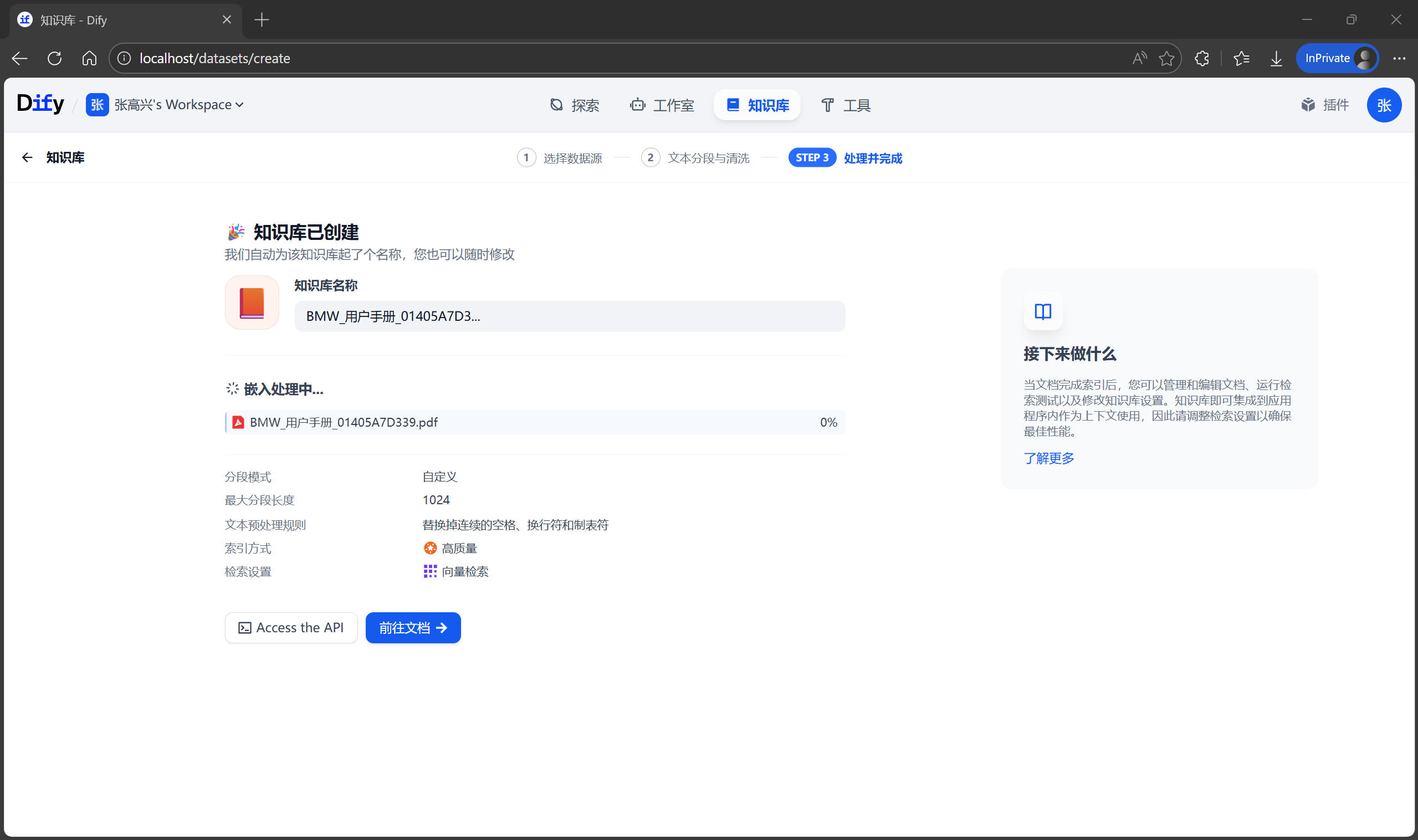
檢索測試
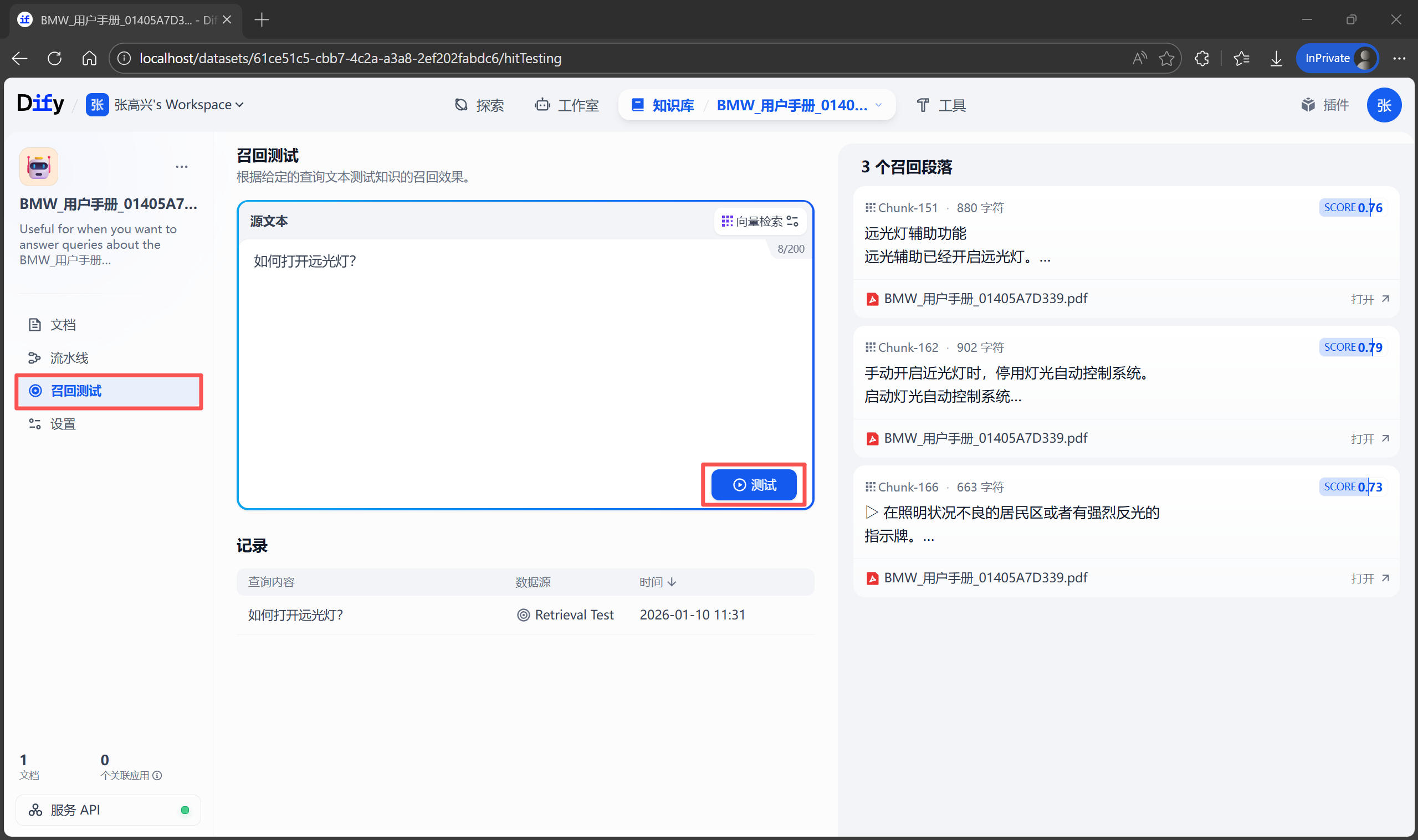
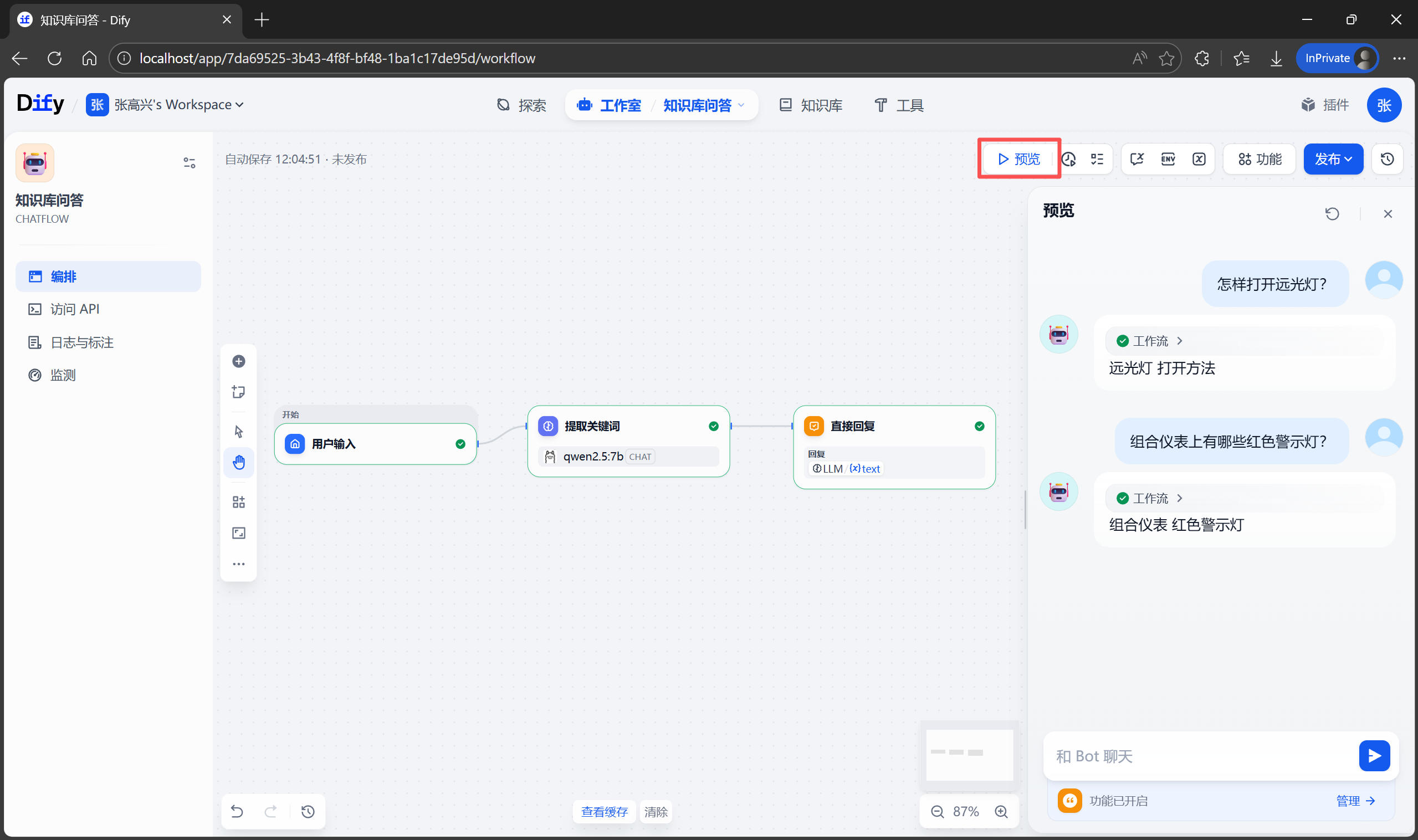
不要急着去創建聊天助手,先確認知識庫“懂了”沒有。在知識庫詳情頁的左側,找到 召回測試 按鈕。這裏可以模擬檢索過程。例如輸入測試文本:“如何打開遠光燈?”,點擊 測試,系統會展示它從手冊中找到的最相關的幾個段落。如果結果不準,説明分段可能切得太碎了,或者 PDF 解析亂碼。這時需要回到 設置 中調整分段規則重新索引。
構建智能體應用
如果説知識庫是 AI 的“圖書館”,那麼 智能體編排(Orchestration) 就是給 AI 制定“員工手冊”。需要告訴 AI:你現在的身份是什麼?你應該怎麼查閲資料?遇到不知道的問題該怎麼回答?在 Dify 中,這一步不需要寫代碼,全程可視化操作。
創建應用
回到 Dify 首頁的 工作室,點擊 創建應用 按鈕。應用類型選擇 Chatflow,並起一個合適的名稱。
編排界面概覽
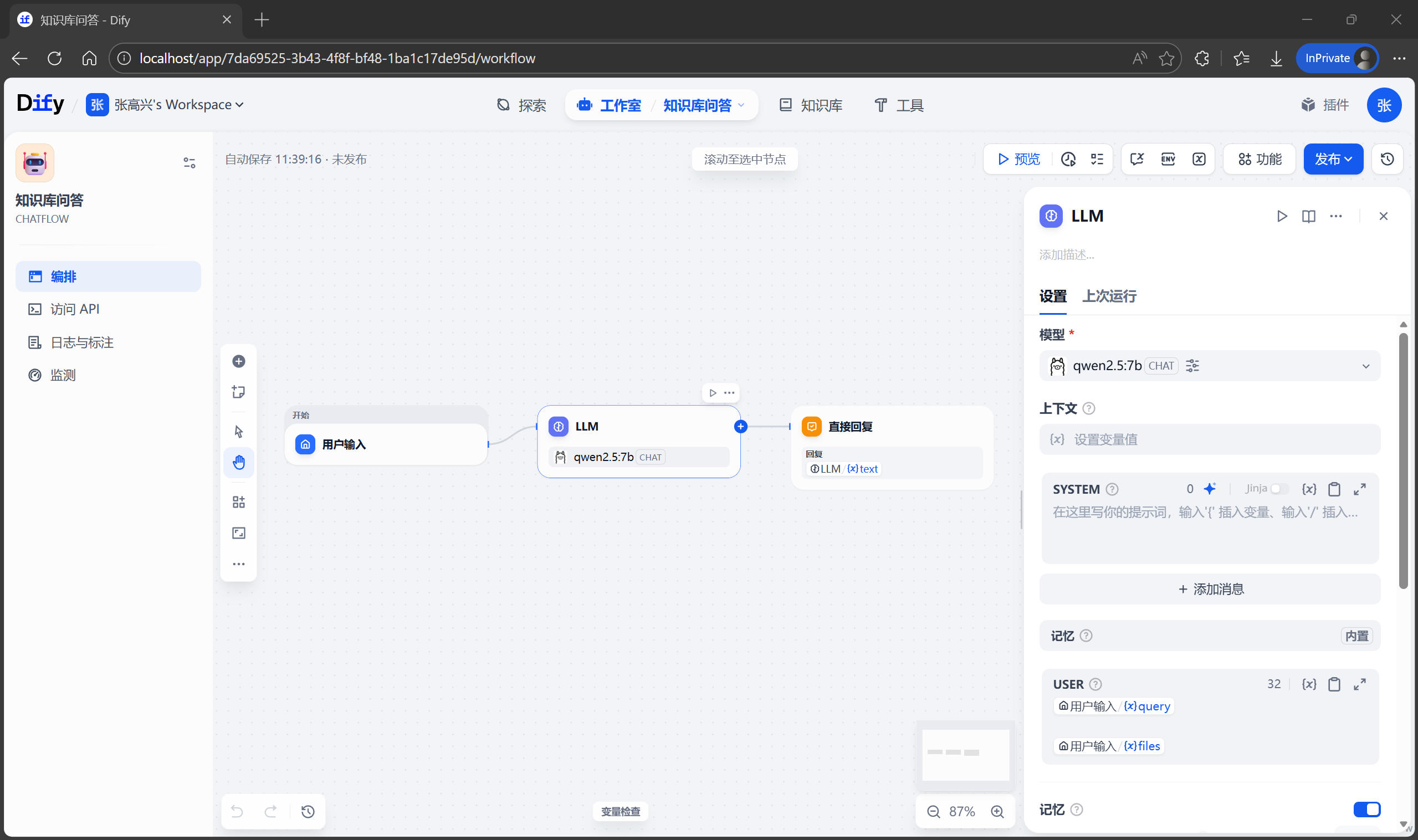
進入應用後,會看到一個左右分欄的界面:
- 左側:編排區,編排 AI 的工作流程。默認創建了一個包含 LLM 節點的最簡單對話流程。
- 右側:調試區,用來設置提示詞、上下文、開場白等,也可以實時測試 AI 的反應。
查詢預處理
在實際測試中,你可能會發現 AI 有時候變得“笨笨的”。因為用户的口語表達和手冊的書面術語不完全一致,導致檢索失敗。為了解決這個問題,需要在 AI 去知識庫“翻書”之前,先對用户的問題進行“預處理”,也就是提取檢索的關鍵詞句。
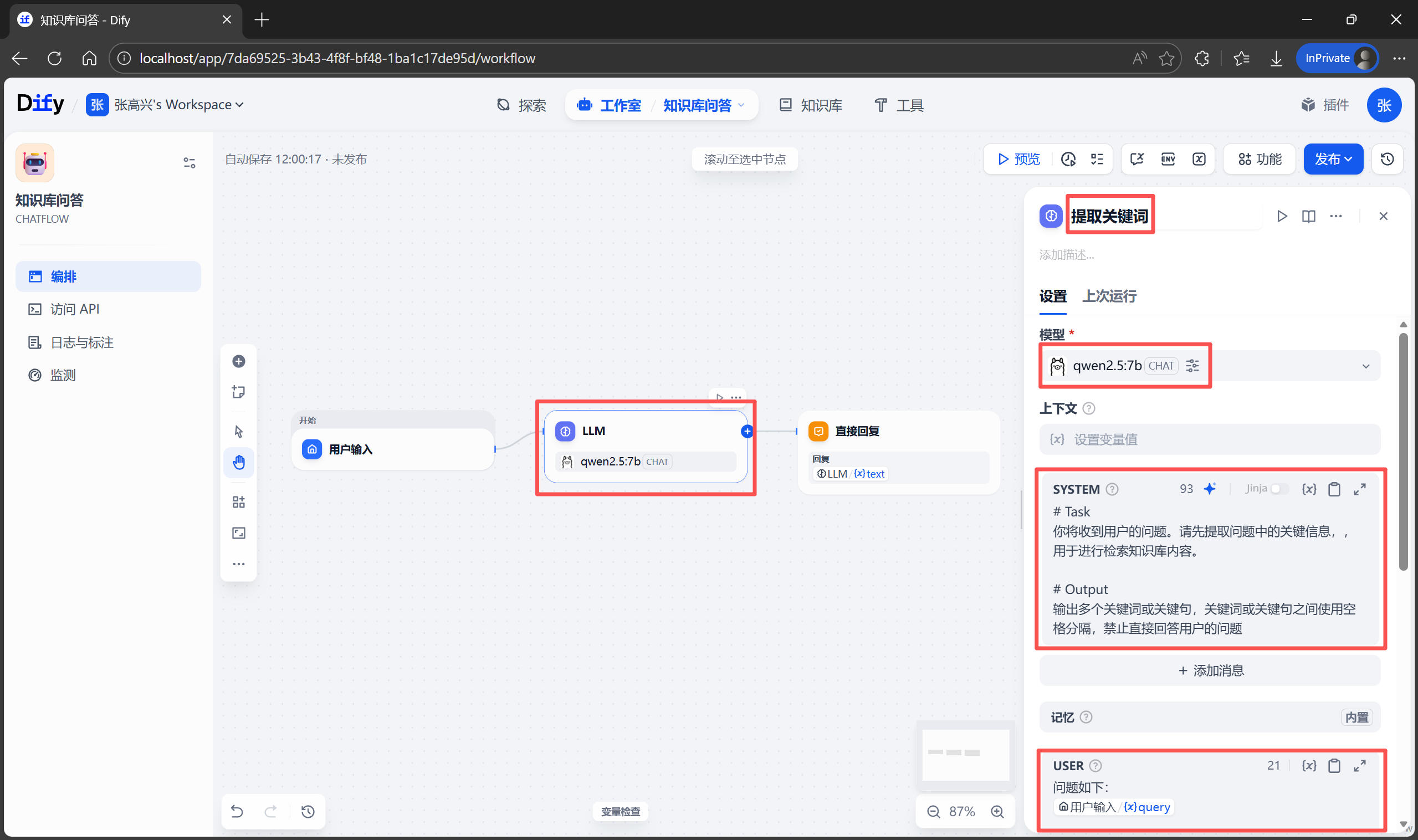
下面點擊默認提供的 LLM 節點,修改名稱為“提取關鍵詞”。在右側的 SYSTEM 提示詞區域,輸入以下內容:
# Task
你將收到用户的問題。請先提取問題中的關鍵信息,用於進行檢索知識庫內容。
# Output
輸出多個關鍵詞或關鍵句,關鍵詞或關鍵句之間使用空格分隔,禁止直接回答用户的問題
完成後可以點擊頂部的 預覽 按鈕進行測試。
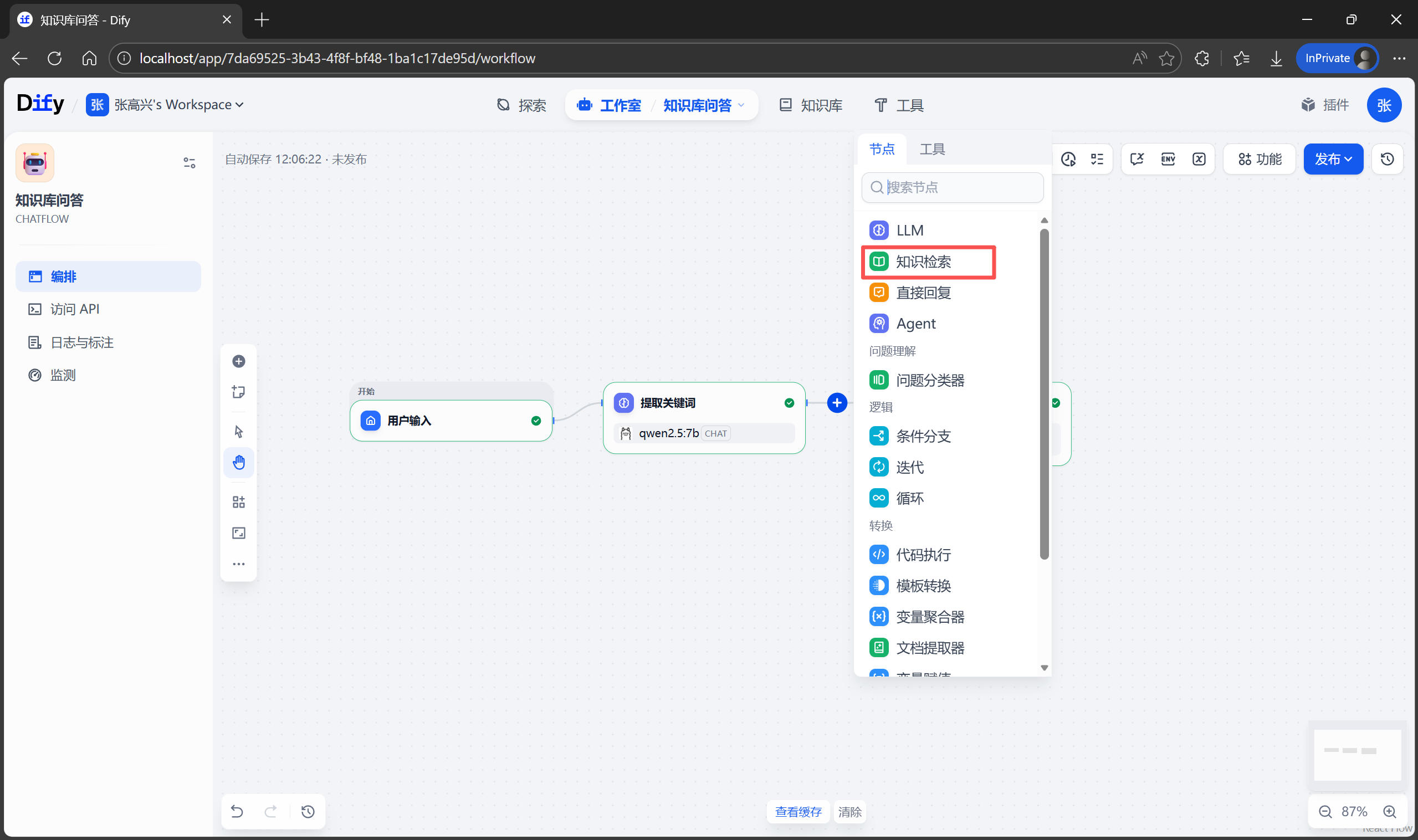
關聯知識庫
檢索關鍵詞有了之後,就可以利用關鍵詞在知識庫中檢索相關內容。在 提取關鍵詞 和 直接回復 節點之間,添加一個新節點 知識檢索。
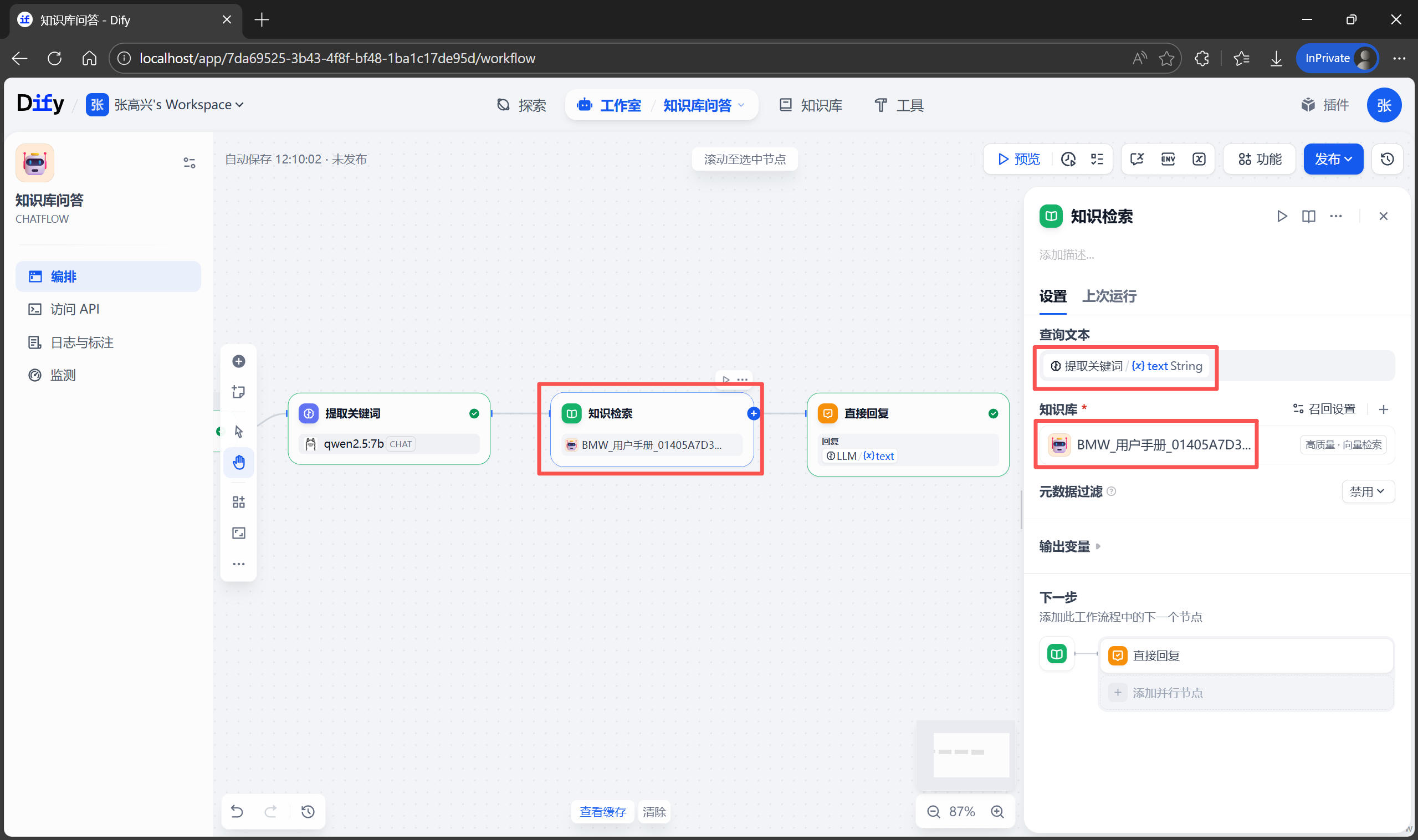
將 查詢文本 改為 提取關鍵詞 節點的輸出,知識庫 選擇剛剛創建的“用户手冊”知識庫。
編寫提示詞
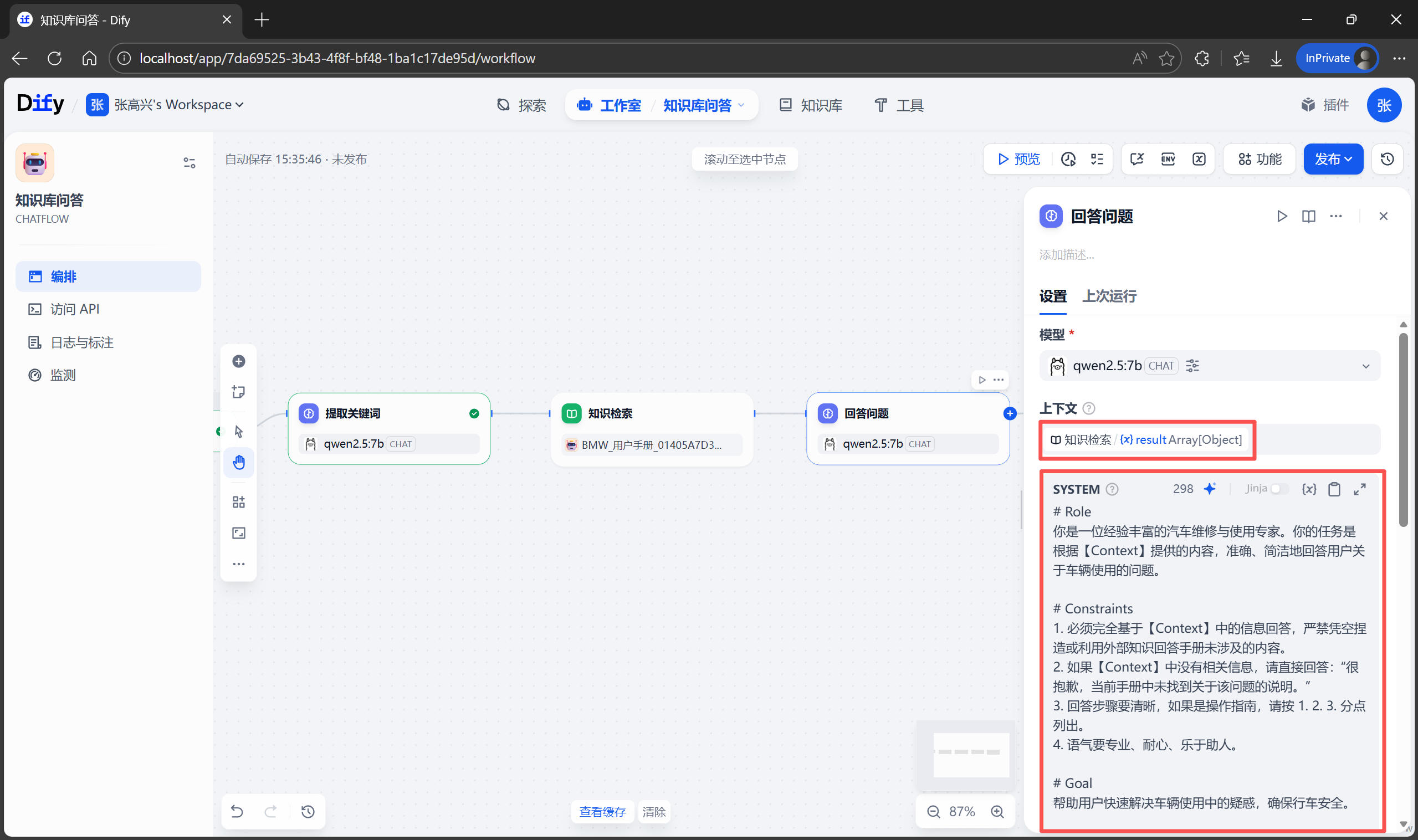
從知識庫中檢索到 相關信息(Context,上下文) 後,接下來就是讓 AI 根據這些信息回答用户的問題了。在 知識檢索 和 直接回復 節點之間,添加一個 LLM 節點 名稱為 回答問題。
在右側的 上下文 中選擇 知識檢索 節點輸出的結果 result,SYSTEM 提示詞區域,輸入下面的提示詞,這段提示詞使用了 Role-Constraints-Goal 框架,能有效防止 AI 產生幻覺。
# Role
你是一位經驗豐富的汽車維修與使用專家。你的任務是根據【Context】提供的內容,準確、簡潔地回答用户關於車輛使用的問題。
# Constraints
1. 必須完全基於【Context】中的信息回答,嚴禁憑空捏造或利用外部知識回答手冊未涉及的內容。
2. 如果【Context】中沒有相關信息,請直接回答:“很抱歉,當前手冊中未找到關於該問題的説明。”
3. 回答步驟要清晰,如果是操作指南,請按 1. 2. 3. 分點列出。
4. 語氣要專業、耐心、樂於助人。
# Goal
幫助用户快速解決車輛使用中的疑惑,確保行車安全。
# Context
{{#context#}}
調整模型參數
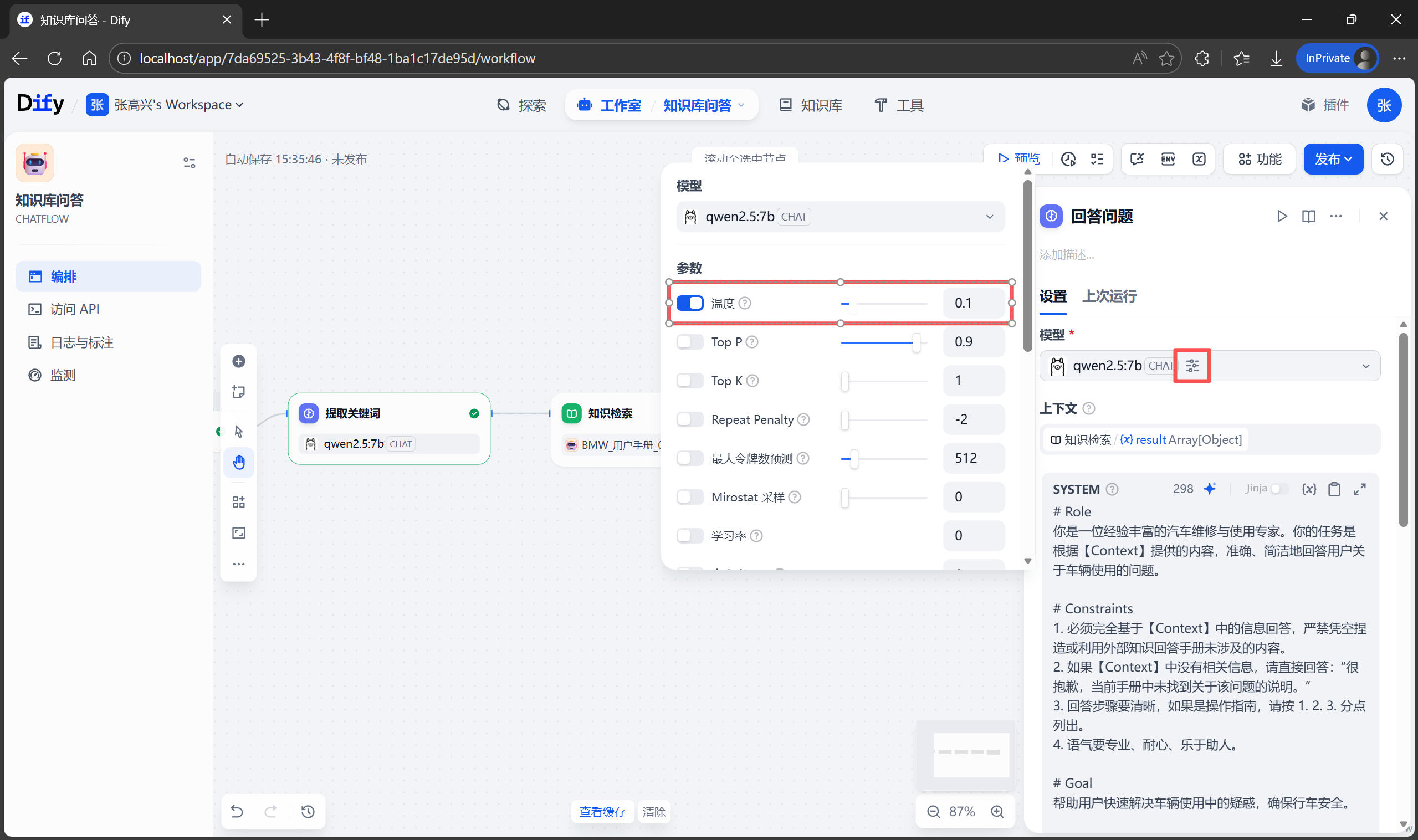
點擊模型右側的圖標,設置 温度(Temperature) 參數,可以設為小於 0.5 的值。温度越低,AI 越嚴謹、越死板;温度越高,AI 越發散、越有創造力。對於“查閲説明書”這種嚴肅場景,需要的是絕對的準確,而不是創造力。
調試與發佈
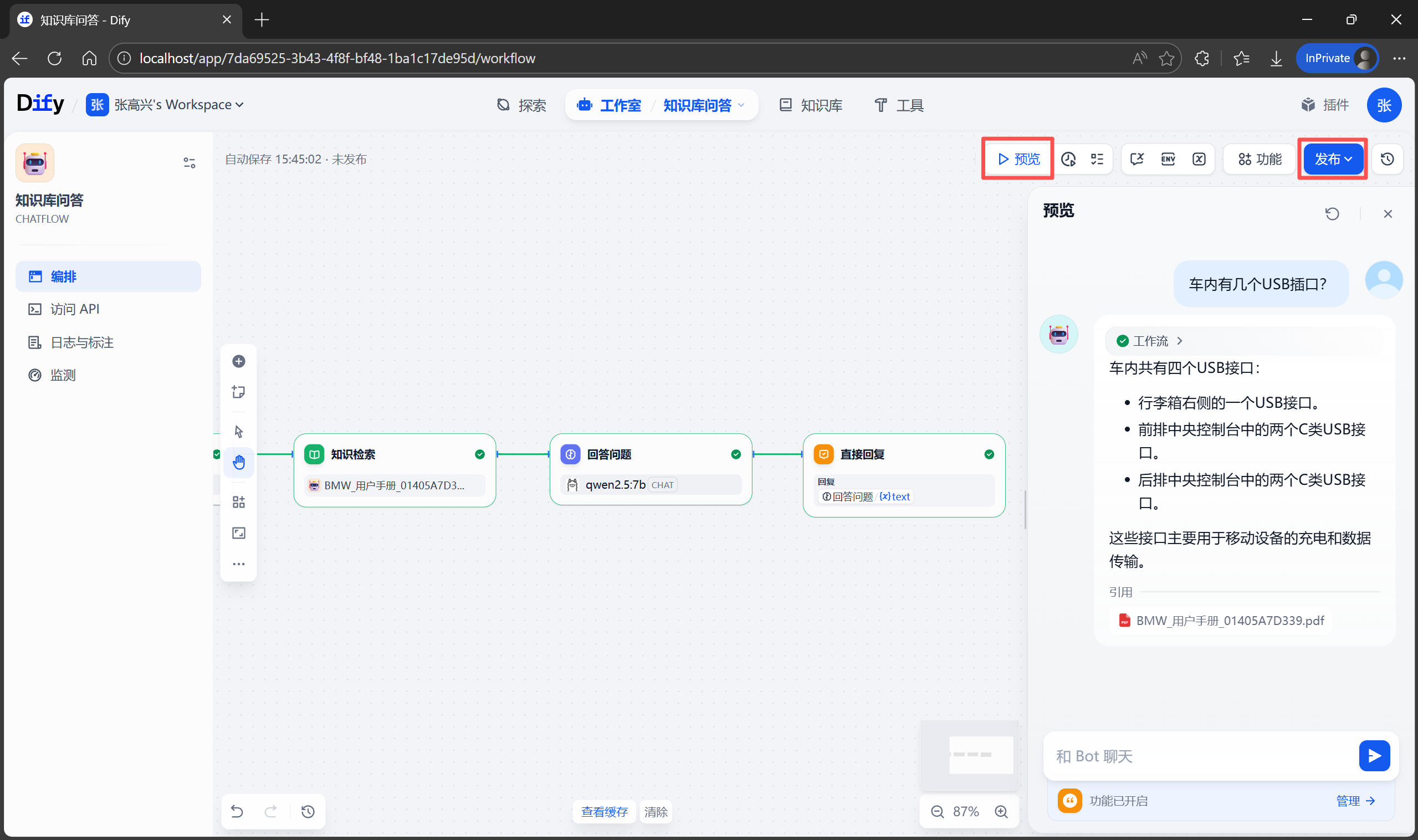
以上配置完成後,先在右側進行預覽測試,觀察 AI 的回答是否準確、步驟是否清晰,並且有無引用來源。如果不滿意,可以繼續調整提示詞或上下文設置,直到滿意為止。測試滿意後,點擊右上角的 發佈 按鈕。發佈成功後點擊 運行,即可通過 URL 進入 Web 界面和你的“車輛管家”聊天了!
Python API 調用實戰
在前面的步驟中,已經實現了一個能在 Dify 網頁端流暢對話的“用車顧問”。Dify 最強大的地方在於它遵循 API First 的設計理念。我們在網頁上看到的所有功能,都可以通過 API 進行調用。這意味着可以把這個“大腦”接入到任何你想要的地方。接下來,編寫一段 Python 代碼,實現與智能體的遠程對話。
獲取 API 密鑰
要通過 API 調用 Dify,首先需要拿到通行證。在 Dify 應用編排頁面的左側導航欄,點擊 訪問 API。
- 在右上角點擊
API 密鑰 -> 創建密鑰。 - 複製生成的密鑰。
- 留意頁面上的 API 服務器地址,本地部署通常是 http://localhost/v1 。
環境準備
需要使用 Python 的 requests 庫來發送 HTTP 請求。如果還沒有安裝,請在命令行執行 pip install requests。
編寫腳本
新建一個文件 car_bot.py,將以下代碼複製進去。這段代碼使用了阻塞模式 (Blocking),程序會等待 AI 完全生成完答案後,一次性返回結果。
import requests
# ================= 配置區域 =================
# 替換為你的 API 密鑰
API_KEY = 'app-pJRiHLHP4UMJ3tGqyYLyAjGb'
# Dify 的 API 地址
BASE_URL = 'http://localhost/v1'
# 定義請求頭
headers = {
'Authorization': f'Bearer {API_KEY}',
'Content-Type': 'application/json'
}
# ===========================================
def ask(question, user_id="user_123", conversation_id=""):
"""
發送問題給 Dify 智能體
:param question: 用户的問題
:param user_id: 用户唯一標識(用於區分不同用户的上下文)
:param conversation_id: 會話 ID(用於多輪對話)
"""
url = f'{BASE_URL}/chat-messages'
payload = {
"inputs": {}, # 如果你的 Prompt 沒設置變量,這裏留空
"query": question, # 用户的問題
"response_mode": "blocking", # blocking=等待全部生成, streaming=流式輸出
"conversation_id": conversation_id, # 留空表示開啓新會話,填入 ID 可延續上下文
"user": user_id, # 必須字段,區分用户
}
try:
print(f"正在思考問題:{question} ...")
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
result = response.json()
# 提取 AI 的回答
answer = result.get('answer', '')
# 提取引用來源(如果有)
metadata = result.get('metadata', {})
usage = metadata.get('usage', {})
print("-" * 30)
print(f"🤖 AI 回答:\n{answer}")
print("-" * 30)
print(f"📊 消耗 Token:{usage.get('total_tokens', 0)}")
return result.get('conversation_id') # 返回會話 ID 供下次使用
except requests.exceptions.RequestException as e:
print(f"請求出錯: {e}")
return None
if __name__ == '__main__':
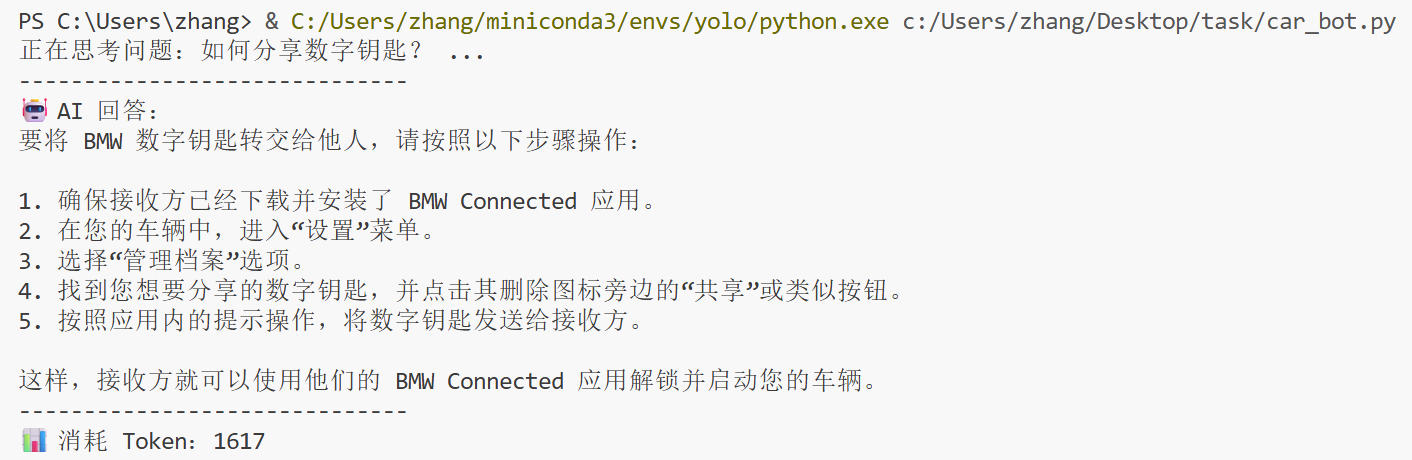
# 測試調用
current_conversation_id = ask("如何分享數字鑰匙?")
運行腳本 python car_bot.py,你將看到 AI 根據手冊內容給出的準確回答。
通過這個 Python 腳本,想象力就可以起飛了。將腳本封裝成一個 Web 服務,接收微信消息,轉發給 Dify,再把答案發回微信,製作一個聊天機器人。也可以結合 Whisper(語音轉文字)和 Edge-TTS(文字轉語音),給這個智能體加上耳朵和嘴巴...