

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課的第二週內容,2.4到2.5的內容以及一些相關知識的補充。
本週為第五課的第二週內容,與 CV 相對應的,這一課所有內容的中心只有一個:自然語言處理(Natural Language Processing,NLP)。
應用在深度學習裏,它是專門用來進行文本與序列信息建模的模型和技術,本質上是在全連接網絡與統計語言模型基礎上的一次“結構化特化”,也是人工智能中最貼近人類思維表達方式的重要研究方向之一。
這一整節課同樣涉及大量需要反覆消化的內容,橫跨機器學習、概率統計、線性代數以及語言學直覺。
語言不像圖像那樣“直觀可見”,更多是抽象符號與上下文關係的組合,因此理解門檻反而更高。
因此,我同樣會儘量補足必要的背景知識,儘可能用比喻和實例降低理解難度。
本週的內容關於詞嵌入,是一種相對於獨熱編碼,更能保留語義信息的文本編碼方式。通過詞嵌入,模型不再只是“記住”詞本身,而是能夠基於語義關係進行泛化,在一定程度上實現類似“舉一反三”的效果。詞嵌入是 NLP 領域中最重要的基礎技術之一。
本篇的內容關於詞嵌入模型原理,是瞭解基礎內容後的下一步引入。
1. 詞嵌入矩陣
在上一篇中,我們知道通過詞嵌入可以實現詞彙的特徵化表示,這種序列信息編碼方式相比獨熱編碼不僅節約了存儲和時間成本,而且可以量化詞彙的語義來提升模型性能。
那麼要如何訓練一個可以輸出對詞彙合適編碼的詞嵌入模型呢?
實際上,詞嵌入模型的原理和我們之前介紹過的圖像風格轉換有些類似,就像其首先要隨機初始化目標圖像一樣,詞嵌入模型的第一步,並不是“理解語義”,而是先給每個詞一個可以被學習的數值載體。
具體來説是這樣的:
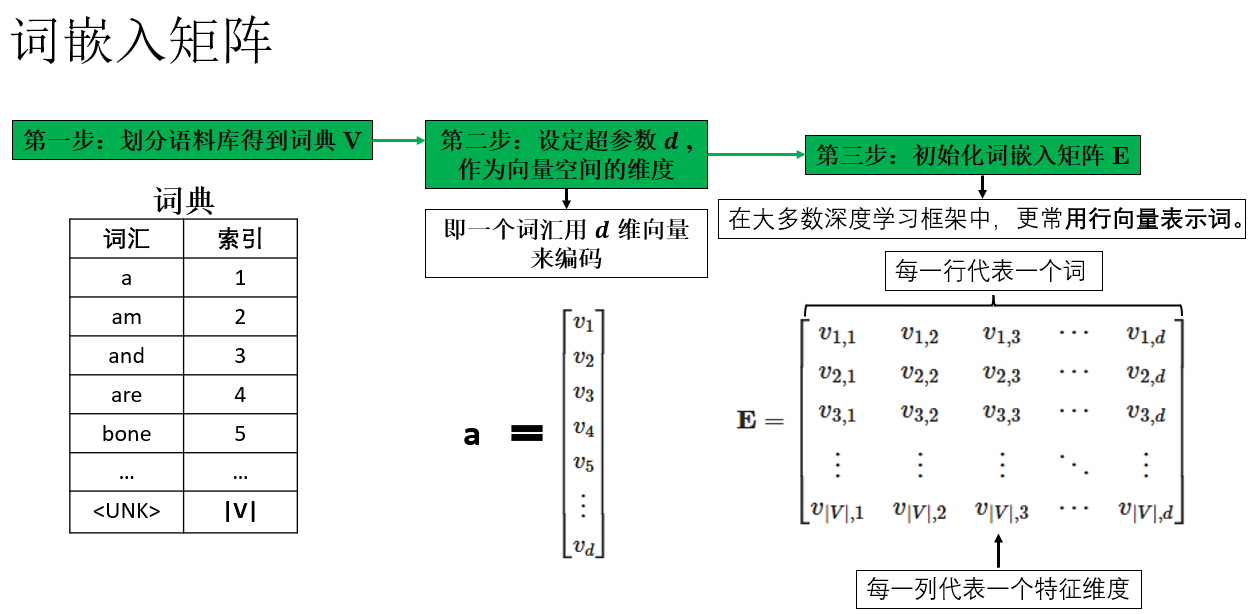
如圖所示,假設我們的詞表大小為 \(|V|\),詞向量維度設為 \(d\),那麼詞嵌入本質上就是一個矩陣,每一行對應詞表中的一個詞,我們稱之為詞嵌入矩陣。
這裏需要強調的是,在課程中,吳恩達老師常在詞嵌入矩陣中使用列向量來表示詞向量,以匹配矩陣乘法的約定。但在實際工程代碼中,通常視作行向量(矩陣行對應詞向量)。這只是約定問題,取決於實現方式:教學中列向量便於公式推導,代碼中行向量更高效。瞭解後,根據場景選擇即可。
回到正題,在模型初始化階段,詞嵌入矩陣並不包含任何語義信息,通常採用隨機初始化,或者服從均值為 0 的正態分佈。
我們之前就説過,詞向量並不是我們手工設定的,而是在模型學習得到的,在我們完成詞嵌入矩陣的初始化後,詞嵌入模型的目的就是不斷傳播和優化詞嵌入矩陣,得到對語義編碼合理的詞向量,從而進行下一步應用。
到這裏就會發現,學習詞嵌入矩陣的過程和圖像風格轉換的過程非常相似:一開始是隨機噪聲,但在損失函數的約束下,逐步學習得到結構化、有意義的結果。
在完成詞嵌入矩陣的初始化後,模型訓練的核心任務就是設計合理的上下文預測目標,讓矩陣中每一行(詞向量)逐步調整位置,從而攜帶語義信息。
2. 早期詞嵌入模型
在 2003 年,一篇論文 A Neural Probabilistic Language Model,首次展示了一個神經網絡語言模型,它不僅預測下一個詞的概率分佈,還通過一個嵌入層將詞索引映射為實值向量。這些向量成為了詞的稠密表示,也就是我們今天所説的詞嵌入(word embeddings)。
儘管當時論文中並沒有直接使用“word embedding”這個術語,但其核心思想:通過神經網絡學習詞的分佈式向量表示——正是現代詞嵌入模型的理論源頭。
2.1 詞嵌入模型原理
這一部分我們展開一下,用早期的模型介紹一下最經典的一類詞嵌入模型:預測型詞嵌入模型的基本邏輯:
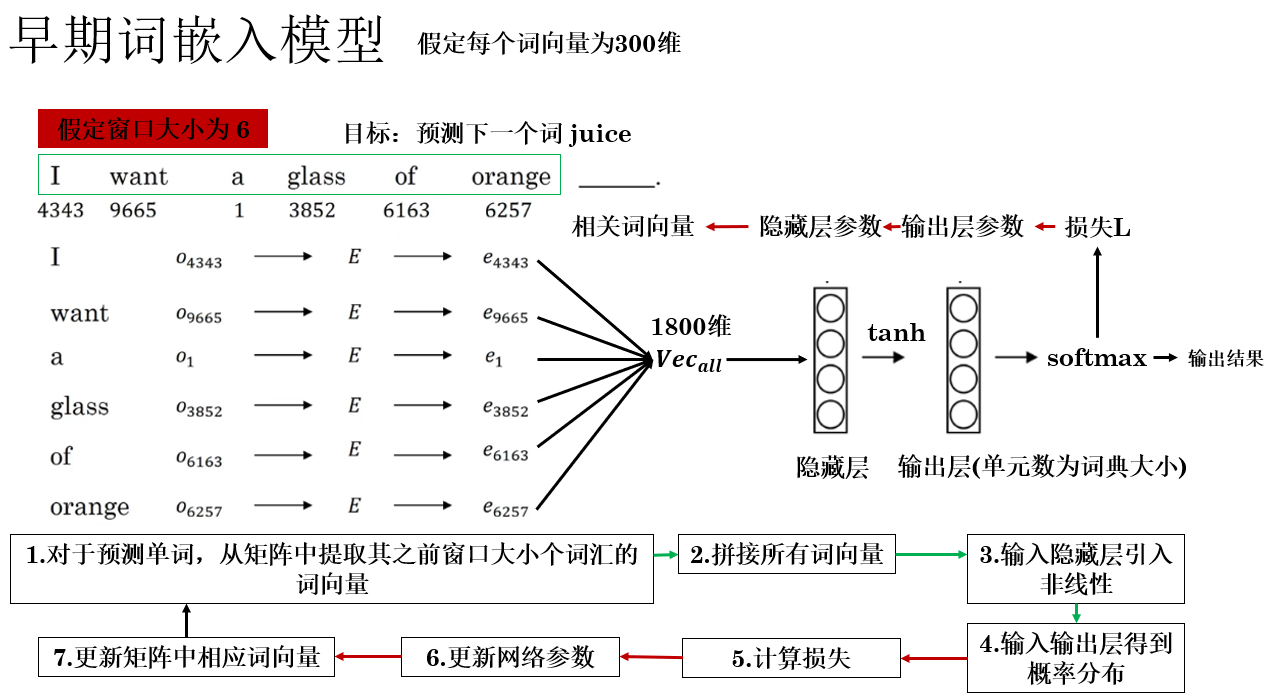
圖中簡要描述了該模型的傳播邏輯,補充一些細節如下:
- 嵌入層(Embedding Layer):在圖中的左半部分,完成的是存儲詞嵌入矩陣和根據索引查找機制提取詞向量的工作,我們稱完成這部分內容的結構為嵌入層。
- 窗口大小 \(t\):這是一個超參數,當預測序列中第 \(n\) 個詞彙時,我們使用其之前 \(t\) 個詞彙作為序列信息。在現代,前文如果不足 \(t\) 個,則會使用特殊符號填充。
- 聯合更新:在反向傳播過程中,嵌入層和網絡的其他參數同時更新。這意味着每次看到訓練樣本,嵌入矩陣中涉及的詞向量會和網絡參數一起沿梯度方向調整,使其更有利於下一個詞的預測。
那詞向量具體是怎麼更新來學習語義的呢?我們展開説説:
2.2 詞向量的語義學習
舉個例子來理解一下詞向量的更新邏輯:
假設訓練語料中出現了許多關於水果的句子,比如:
I like to eat apple.
She bought a banana yesterday.
Orange juice is tasty.
現在,模型的任務是根據上下文預測下一個詞。當看到句子 "I like to eat apple" 時,模型會預測下一個詞可能是 "apple"。
這時,反向傳播時,模型會調整 “apple”對應的詞向量以及上下文中其他詞的向量,使得網絡更容易正確預測 "apple"。
同理,當訓練樣本中出現 "banana" 或 "orange" 時,這些詞的向量也會因為相似的上下文而被調整到相互靠近的位置:"apple", "banana", "orange" 這些同類型的詞常出現在類似的上下文(如 eat、juice、like 等)
最終模型通過梯度更新,讓這些詞向量在向量空間中彼此靠近,從而自然捕捉到語義相似性。
這樣的效果就是:即使模型從未顯式告知“它們都是水果”,詞向量也會因為上下文模式相似而自動聚集在一起,形成語義簇(semantic cluster),即向量空間中,語義相近的詞自然聚在一起形成的羣體。
這時,面對下面這兩句話:
訓練:I like orange juice.
測試:I love apple _____.
模型即使沒見過測試語句,也可以通過"love 和 like"、"apple 和 orange" 在向量空間的距離相近得到更可靠的答案,從而提高模型性能。
用一句話總結一下:同類型的詞彙往往出現在相似的上下文中,因此在更新後更加相似,最終在向量空間中形成語義簇,極大增強了模型的泛化能力。
你會發現,在詞嵌入模型中,詞向量的語義結構並不是顯式教給模型的,而是在上下文預測任務中自然而然學到的,模型並沒有專門去“訓練合適編碼”,而是在預測中讓相似的詞不斷靠近。
同樣是對數據進行編碼,詞嵌入和我們之前介紹的人臉識別又有所不同。
當然,既然是早期模型,自然有值得優化的地方,我們繼續:
2.3 早期詞嵌入模型的侷限
儘管 A Neural Probabilistic Language Model 成功提出了通過神經網絡學習詞向量的思路,但作為早期模型,它在實際應用和理論上存在一些明顯的侷限性:
| 侷限類別 | 具體説明 | 影響 |
|---|---|---|
| 計算開銷大 | 輸入是 \(t\) 個詞獨熱向量拼接,輸出是詞表大小 \(V\) 的 softmax | 詞表大時計算量高,訓練預測速度慢 |
| 上下文窗口固定 | 每次預測只使用前 \(t\) 個詞 | 無法捕捉長距離依賴,語義建模受限 |
| 梯度更新效率低 | 嵌入矩陣和網絡參數同時更新,每個樣本只涉及部分詞向量 | 收斂慢,低頻詞向量質量不穩定 |
| 沒有顯式建模語義規律 | 語義相似性完全依賴上下文共現 | 稀有詞或低頻詞向量質量差,泛化能力有限,無法處理多義詞 |
因此,為了解決這些問題,自然有人發明新的技術和模型,我們在之後幾篇就來詳細介紹這些內容。
3. 總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 詞嵌入矩陣(Embedding Matrix) | 將詞表中每個詞映射為可學習的稠密向量,矩陣行(或列)對應詞向量。初始化隨機或正態分佈,通過梯度更新學習語義信息。 | 類似圖像風格轉換中的“隨機噪聲圖像”,逐步在訓練中形成結構化圖像。 |
| 嵌入層(Embedding Layer) | 存儲詞嵌入矩陣並提供索引查找功能,將詞索引映射為詞向量。 | 就像一本“詞向量字典”,根據索引直接查到對應的向量。 |
| 上下文預測訓練 | 利用前 \(t\) 個詞預測下一個詞,通過反向傳播更新嵌入矩陣和網絡參數,使語義相似的詞向量靠近。 | 好比讓水果類詞(apple, banana, orange)在向量空間裏自然聚成一簇,通過相似上下文學習它們的關係。 |
| 語義簇(Semantic Cluster) | 在向量空間中,語義相近的詞自然聚集,捕捉詞彙之間的語義關係。 | 詞向量像朋友一樣,常在同一圈子(上下文)出現就靠近在一起。 |
| 早期詞嵌入模型侷限 | 計算開銷大(softmax over 大詞表)上下文窗口固定、 梯度更新效率低 、無顯式語義建模(如多義詞)。 | 模型像老式拼字遊戲,效率低且只能看到局部信息,難以捕捉遠距離或複雜規律。 |