

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課第一週的課後習題和代碼實踐部分。
1.理論習題
【中英】【吳恩達課後測驗】Course 5 - 序列模型 - 第一週測驗
本週的理論習題中有一道較為巧妙,我們來看看:
這裏有一些GRU的更新方程:
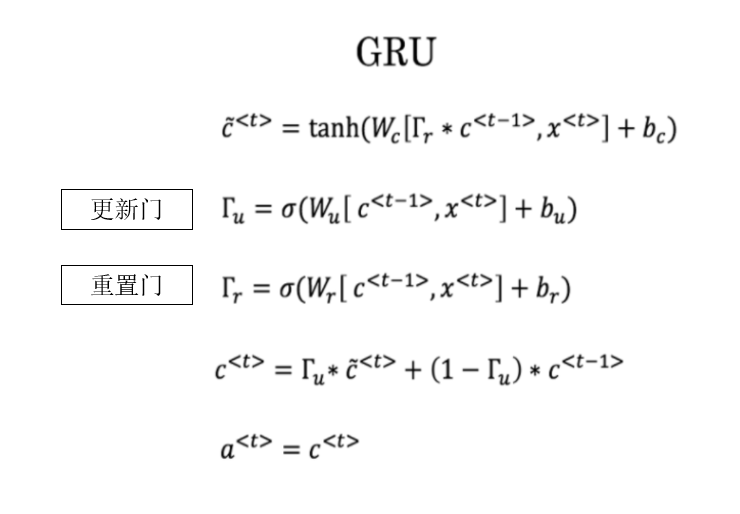
愛麗絲建議通過移除 \(Γ_u\) 來簡化GRU,即設置 \(Γ_u=1\)。貝蒂提出通過移除 \(Γ_r\) 來簡化GRU,即設置 \(Γ_r=1\)。哪種模型更容易在梯度不消失問題的情況下訓練,即使在很長的輸入序列上也可以進行訓練?
答案: 貝蒂的模型(即移除\(Γ_r\)),因為對於一個時間步而言,如果\(Γ_u≈0\),梯度可以通過時間步反向傳播而不會衰減。
我們先回顧一下GRU中兩道門的語義:
- 重置門:控制在計算當前候選隱藏狀態時,上一時刻隱藏狀態是否被抑制。
- 更新門:控制當前隱藏狀態中,上一時刻隱藏狀態與當前候選隱藏狀態的融合比例。
現在再來看一下題中的兩種簡化邏輯:
- 移除 \(Γ_u\):令更新門恆為 1,此時當前隱藏狀態完全由候選隱藏狀態決定。
- 移除 \(Γ_r\):令重置門恆為 1,使候選隱藏狀態在計算時不再抑制上一時刻的隱藏狀態。
看到這裏,我們可能看不出什麼問題,因為只看語義,二者都是一種簡化,無法直觀看出對訓練效果影響的程度。
這道題的關鍵在於題目中的:更容易在梯度不消失問題的情況下訓練。
也就是説,我們要看的應該是兩種簡化對梯度傳遞的影響。
這就要回到公式了,我們來看看兩種簡化後的傳播公式:

這裏就可以很明顯的發現:如果刪去更新門,就是刪去了時間步間的梯度直連通道。而刪去重置門則不會造成這一點。
顯然,刪除更新門會讓梯度在時間步間的傳播路徑更長,梯度只能通過非線性變換反向傳播,更容易衰減,自然就更容易造成梯度消失,由此得到答案。
2.代碼實踐
吳恩達課程5 RNN搭建與應用
依舊還是先擺上這位博主的鏈接,這篇博客非常詳細地展示了手動搭建 RNN、LSTM 等本週理論內容的過程。
我們依舊還是用成熟框架來演示本週所瞭解的內容,任務類型為命名實體識別,涉及模型列舉如下:
- 單層單向 RNN
- 單層雙向 RNN
- 單層雙向 GRU
- 單層雙向 LSTM
- 多層雙向 LSTM
2.1 數據集:CoNLL-2003
在本節的代碼實踐中,我們選用 CoNLL-2003 命名實體識別數據集 作為數據集。
它是序列標註任務中最經典、也最常用的數據集之一,是一個詞級別的序列標註數據集。
需要補充的是,關於命名實體識別任務,我們在之前的理論部分裏僅使用 0/1 來進行人名的識別,但實際上的命名實體識別顯然內容更豐富,並且對於各類實體的標籤標註,也有一套主流的成熟標註體系,被稱為 BIO 標註體系。
並不複雜,BIO 的三個核心符號含義如下:
- B-類型(Begin):表示這個詞是一個實體的開頭(第一個詞)。
- I-類型(Inside):表示這個詞是實體的內部(非第一個詞)。
- O(Outside):表示這個詞不屬於任何實體。
其中,B、I 後會接任務定義的實體命名。
來看一個實例:河北 2026 年 1 月 14 日 天氣 很好
| 詞 | 標籤 | 解釋 |
|---|---|---|
| 河北 | B-LOC | 地名的開頭 |
| 2026 | B-TIME | 時間表達的開頭 |
| 年 | I-TIME | 時間的內部 |
| 1 | I-TIME | 時間的內部 |
| 月 | I-TIME | 時間的內部 |
| 14 | I-TIME | 時間的內部 |
| 日 | I-TIME | 時間的內部 |
| 天氣 | O | 非實體 |
| 很 | O | 非實體 |
| 好 | O | 非實體 |
CoNLL-2003 同樣採用 BIO 標註體系,並定義了四類命名實體如下:
| 實體類型 | 含義 | BIO 標籤示例 | 説明 |
|---|---|---|---|
| PER | 人名(Person) | B-PER, I-PER |
表示人物姓名及其組成部分 |
| ORG | 組織機構(Organization) | B-ORG, I-ORG |
公司、政府機構、學校等 |
| LOC | 地名(Location) | B-LOC, I-LOC |
國家、城市、地區等地理名稱 |
| MISC | 其他專有名詞(Miscellaneous) | B-MISC, I-MISC |
其他不屬於上述類別的專名 |
| O | 非實體 | O |
不屬於任何命名實體的普通詞 |
瞭解了 CoNLL-2003 這類數據集的序列標註邏輯後,回到數據本身:
CoNLL-2003 數據集已經被官方劃分為訓練集、驗證集和測試集三部分,其中:
- 訓練集:約 14,000 句。
- 驗證集:約 3,000 句。
- 測試集:約 3,500 句。
總計包含 20,000+ 條標註句子,詞級樣本數量在 20 萬級別。
CoNLL-2003 的下載接口同樣在被封裝在 python 的許多第三方庫中,其中一個選擇是 PyTorch 官方維護的一個 NLP 工具庫:torchtext :
pip install torchtext
安裝後,便可以這樣導入CoNLL-2003 的下載接口:
from torchtext.datasets import CoNLL2003
但是,由於torchtext並非torch 的子模塊,需要單獨安裝,且高度依賴和torch間的版本匹配,因此在實際安裝中可能出現很多兼容性問題。
因此,我們選擇另一個兼容性更好且實際上在這類使用上也更流行的庫:HuggingFace 的 datasets:
pip install datasets
安裝後,便可以這樣導入:
from datasets import load_dataset
這樣,我們就完成了數據集本身的準備,打印幾條示例數據如下:

2.2 數據預處理
完成數據集準備後,自然下一步就要開始讓數據輸入模型,但序列數據不同於我們之前的圖像,統一預處理後就可以輸入網絡,在 RNN 中,我們需要在數據預處理中花更多功夫,具體如下:
(1)導入相關庫
開局當然還是先導庫,在 NLP 相關任務中,這些相關庫都很常見,尤其是python內置的collections庫,我們常用它來統計語料庫,構建詞典。
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence # 用於對不同長度的序列進行填充,使得批次張量對齊。
from datasets import load_dataset # 導入 CoNLL-2003 數據集。
from collections import Counter # 用於統計詞頻和標籤頻率,便於構建詞表和標籤表。
from torch.utils.data import DataLoader # 標配,提供批次化處理和打亂數據集功能。
(2)加載數據集
這步很簡單,就不多解釋了:
# 使用 HuggingFace datasets 加載數據
dataset = load_dataset("conll2003")
# 分別獲取訓練集、驗證集、測試集
train_data = dataset['train']
valid_data = dataset['validation']
test_data = dataset['test']
(3)構建詞表和標籤表
就像我們在理論部分介紹的,在做序列任務中,我們需要把文本和標籤都轉成索引形式,即計算機能理解的詞典。
這裏我們先用 Counter 統計詞頻和標籤頻率,然後構建詞表和標籤表。
在這裏需要補充的內容是填充符<PAD>,因為模型需要固定維度的輸入,而序列往往長度不同,因此我們需要對不同長度的序列進行填充來適配模型輸入。
舉個簡單的例子:
| 填充前 | 填充後 |
|---|---|
| Hello my firend | Hello my firend |
| Hi | Hi <PAD>``<PAD> |
同樣,當輸入序列中出現<PAD>時,其對應的標籤也是<PAD>。
在代碼中,我們一般設置輸入序列中的<PAD>的 ID 為 0,但在標籤序列中則不同,我們一般設定為一個特殊值,比如下面的 -100,這個特殊值會被特殊記錄,在計算損失時會忽略該位置的損失計算。
因為它本身的作用就是填充序列長度,模型不需要在這裏浪費計算性能,也無法從這裏學習信息。
編碼如下:
# 統計詞頻和標籤頻率
# Counter():用來統計元素出現次數的字典
word_counter = Counter()
tag_counter = Counter()
for item in train_data:
words = item['tokens'] # 單詞列表
tags = item['ner_tags'] # 標籤索引
tag_counter.update(tags) # 統計標籤
word_counter.update(words) # 統計詞頻
# 構建詞表
word_vocab = {w: i + 2 for i, (w, _) in enumerate(word_counter.most_common())}
# word_counter.most_common() :返回按詞頻從高到低排列的 (單詞, 出現次數) 列表。
# i + 2 我們給單詞分配整數 ID,從 2 開始。
# {w: i + 2 for i, (w, _) in ...} :通過字典推導式,把每個單詞 w 映射為對應的整數 ID。
# 最終 word_vocab = {'I':2, 'love':3, 'Python':4, ...}
word_vocab["<PAD>"] = 0 # 填充符
word_vocab["<UNK>"] = 1 # 未知詞
# 構建標籤表
tag_vocab = {t: t for t in tag_counter.keys()} # 標籤索引直接映射自己
pad_tag_id = -100 # 定義 PAD 標籤索引,在後續損失函數參數中使用。
num_classes = len(tag_vocab) # 預測類別,定義輸出層
vocab_size = len(word_vocab) # 用於獨熱編碼
(4)定義編碼函數
定義好好詞表和標籤表本身後,我們還需要定義第一個編碼函數,它的作用就是把文本信息對照詞典轉換為計算機能理解的編碼。 我們下一步就會通過這個函數來處理數據集。
同時,這一步還像是之前卷積網絡中的 transform 方法,把在輸入模型前,把數據轉換成 PyTorch 要求的Tensor 張量。
不過和圖像不同的是,這裏處理的是文本序列。而 transform 針對的是圖像數據,且處理邏輯也不同,因此並不能在這裏直接使用。
# 將單條樣本的單詞和標籤編碼為 Tensor
def encode(item):
words = item['tokens']
tags = item['ner_tags']
x = torch.tensor([word_vocab.get(w, 1) for w in words], dtype=torch.long)
# 這段邏輯是,對於每個詞:如果在詞表裏找到就返回其索引,如果沒找到,就返回 1,即 <UNK> 的索引
y = torch.tensor(tags, dtype=torch.long)
# 標籤索引
return x, y
(4)數據填充和構建迭代器
到這一步,我們已經擁有了詞典和相應的編碼函數,自然,我們可以使用它們對數據進行預處理了,這一步的工作分為三部分:
- 定義填充函數。
- 使用編碼函數對劃分好的數據進行編碼。
- 使用編碼好的數據與填充函數,完成最終的批次迭代器定義。
# 自定義填充函數
def collate_fn(batch): # 參數為一批次數據
xs, ys = zip(*batch) # 把(樣本,標籤)拆成(樣本,樣本)和(標籤,標籤)
xs_pad = pad_sequence(xs, batch_first=True, padding_value=word_vocab["<PAD>"]) # pad_sequence 方法會自動找到最長序列並補充填充同一批次中其他序列到該長度。
# 不同批次的填充長度可以不同。
ys_pad = pad_sequence(ys, batch_first=True, padding_value=pad_tag_id)
return xs_pad.to(device), ys_pad.to(device)
# 對所有數據進行編碼
train_dataset = [encode(item) for item in train_data]
valid_dataset = [encode(item) for item in valid_data]
test_dataset = [encode(item) for item in test_data]
# 使用編碼好的數據劃分批次,進行填充
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
至此,我們才完成了在數據集在輸入模型前的預處理工作,下一步,自然就是要定義模型了。
2.3 定義 RNN 模型
同樣,對於 RNN ,PyTorch 也有封裝好的方法,我們定義要用的 RNN 模型如下:
class RNNTagger(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
rnn_type='RNN', bidirectional=False, num_layers=1):
# 使用多個參數,方便我們調用不同模型,默認為單層單向 RNN
super().__init__()
self.vocab_size = vocab_size # 詞表
self.bidirectional = bidirectional # 是否雙向
self.rnn_type = rnn_type.upper() # 使用的循環單元
input_size = vocab_size # 使用獨熱編碼,獨熱編碼輸入維度 = 詞表大小
# 使用普通 RNN
if self.rnn_type == 'RNN':
self.rnn = nn.RNN(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
# 使用 LSTM
elif self.rnn_type == 'LSTM':
self.rnn = nn.LSTM(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers) # 使用 GRU
elif self.rnn_type == 'GRU':
self.rnn = nn.GRU(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
# 輸出層
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
# x: [batch, seq_len], 轉獨熱
x_onehot = torch.nn.functional.one_hot(x, num_classes=self.vocab_size).float()
out, _ = self.rnn(x_onehot) #在這裏就封裝了按時間步傳播的邏輯
out = self.fc(out)
return out
在這裏,你會發現,RNN、LSTM、GRU 都被封裝成了單獨的模型,我們只需要更改其參數,即可修改其深度和是否雙向等。
最後,就是定義相應訓練和驗證邏輯了。
2.4 訓練與驗證
我們這次把整個訓練與驗證邏輯也定義為函數,方便之後使用不同的模型調用:
def train_validate(model, train_loader, valid_loader, epochs=5, lr=0.001):
model.to(device)
# 在損失函數種使用ignore_index參數來忽略對<PAD>的損失計算
criterion = nn.CrossEntropyLoss(ignore_index=pad_tag_id)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_f1_history = []
epoch_times = []
total_start_time = time.time()
for epoch in range(epochs):
epoch_start_time = time.time()
# ========= 訓練 =========
model.train()
total_loss = 0
total_correct = 0
total_tokens = 0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(x_batch)
outputs_reshape = outputs.view(-1, num_classes)
y_batch_reshape = y_batch.view(-1)
loss = criterion(outputs_reshape, y_batch_reshape)
loss.backward()
optimizer.step()
total_loss += loss.item()
preds = outputs.argmax(dim=-1)
for i in range(y_batch.size(0)):
mask = y_batch[i] != pad_tag_id
total_correct += (preds[i][mask] == y_batch[i][mask]).sum().item()
total_tokens += mask.sum().item()
avg_train_loss = total_loss / len(train_loader)
train_acc = total_correct / total_tokens
train_loss_history.append(avg_train_loss)
train_acc_history.append(train_acc)
# ========= 驗證 =========
model.eval()
val_total_correct = 0
val_total_tokens = 0
all_preds = []
all_labels = []
with torch.no_grad():
for x_val, y_val in valid_loader:
outputs = model(x_val)
preds = outputs.argmax(dim=-1)
for i in range(y_val.size(0)):
mask = y_val[i] != pad_tag_id
val_total_correct += (preds[i][mask] == y_val[i][mask]).sum().item()
val_total_tokens += mask.sum().item()
all_preds.extend(preds[i][mask].cpu().tolist())
all_labels.extend(y_val[i][mask].cpu().tolist())
val_acc = val_total_correct / val_total_tokens
# ⭐ token-level F1(macro)
val_f1 = f1_score(all_labels, all_preds, average='macro')
val_acc_history.append(val_acc)
val_f1_history.append(val_f1)
epoch_time = time.time() - epoch_start_time
epoch_times.append(epoch_time)
print(
f"輪次 {epoch+1}: "
f"訓練損失={avg_train_loss:.4f}, "
f"訓練準確率={train_acc:.4f}, "
f"驗證準確率={val_acc:.4f}, "
f"驗證F1={val_f1:.4f}, "
f"本輪用時={epoch_time:.2f} 秒"
)
total_time = time.time() - total_start_time
avg_epoch_time = sum(epoch_times) / len(epoch_times)
print("\n======== 訓練時間統計 ========")
print(f"總訓練時間:{total_time:.2f} 秒")
print(f"平均每輪用時:{avg_epoch_time:.2f} 秒")
history = {
'train_loss': train_loss_history,
'train_acc': train_acc_history,
'val_acc': val_acc_history,
'val_f1': val_f1_history
}
return model, history
自此,我們終於完成了主要的代碼工作,下面就來運行看看吧。
2.5 運行結果
(1) 單層單向 RNN
首先,先試試最基礎的單層單向 RNN,我們在主函數裏這樣調用它:
if __name__ == '__main__':
# 定義參數
cfg = {'rnn_type':'RNN','bidirectional':False,'num_layers':1}
# 傳入模型
model = RNNTagger(vocab_size=len(word_vocab),
hidden_dim=128,
num_classes=num_classes,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
# 進行訓練
model, history = train_validate(model, train_loader, valid_loader, epochs=5) # 可視化
plot_training_curves(history)
需要強調的是:RNN 通常不需要設置過多的訓練輪次,這是因為其訓練採用時間反向傳播,梯度需要沿時間維度逐步傳遞,時間步一長就容易出現梯度消失或爆炸的問題,使得後期訓練收益迅速降低。
實踐中,RNN 往往在前幾輪就學到主要的序列模式,繼續增加 epoch 不僅提升有限,還可能導致驗證性能波動甚至過擬合,因此相比其他模型,RNN 的訓練輪次通常設置得相對較少。
現在來看看運行結果:
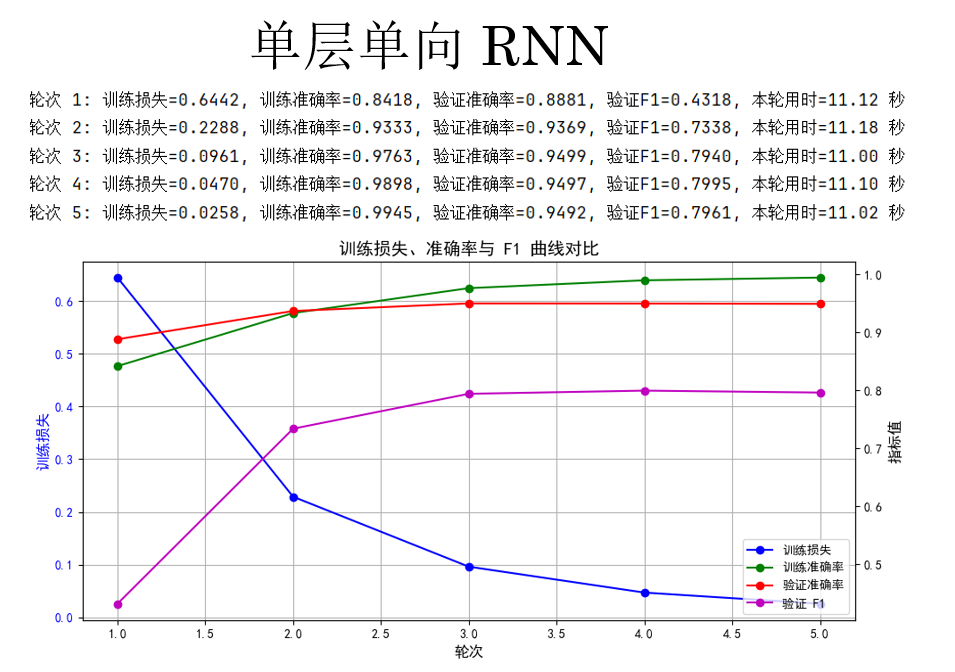
這裏有一個問題,你會發現:F1 分數明顯要比準確率低一截。
原因在於,序列標註任務中的類別分佈通常是極度不均衡的。以命名實體識別為例,大部分詞實際上都屬於非實體類別(如 O),模型即使只是“保守地”把絕大多數位置預測為 O,也能獲得相當可觀的準確率。這種情況下,準確率更多反映的是模型對“多數類”的擬合能力,而非對實體邊界和類別的真實識別能力。
相比之下,F1 分數同時考慮了精確率和召回率,只有當模型既能正確識別實體、又不過度漏掉實體時,F1 才會提高。因此,在命名實體識別這類關注“少數但關鍵結構”的任務中,F1 能更真實地刻畫模型的實際效果。
也正因如此,在序列標註任務中,準確率往往具有較強的迷惑性,而 F1 才是更具判別力、也更被廣泛採用的核心評價指標。
我們繼續,看看其他模型的表現。
(2)單層雙向 RNN
第二個實驗對象,單層雙向 RNN,我們只需要更改一個參數:
if __name__ == '__main__':
# 定義參數: 'bidirectional':True
cfg = {'rnn_type':'RNN','bidirectional':True,'num_layers':1}
# 傳入模型
model = RNNTagger(vocab_size=len(word_vocab),
hidden_dim=128,
num_classes=num_classes,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
# 進行訓練
model, history = train_validate(model, train_loader, valid_loader, epochs=5) # 可視化
plot_training_curves(history)
來看結果:
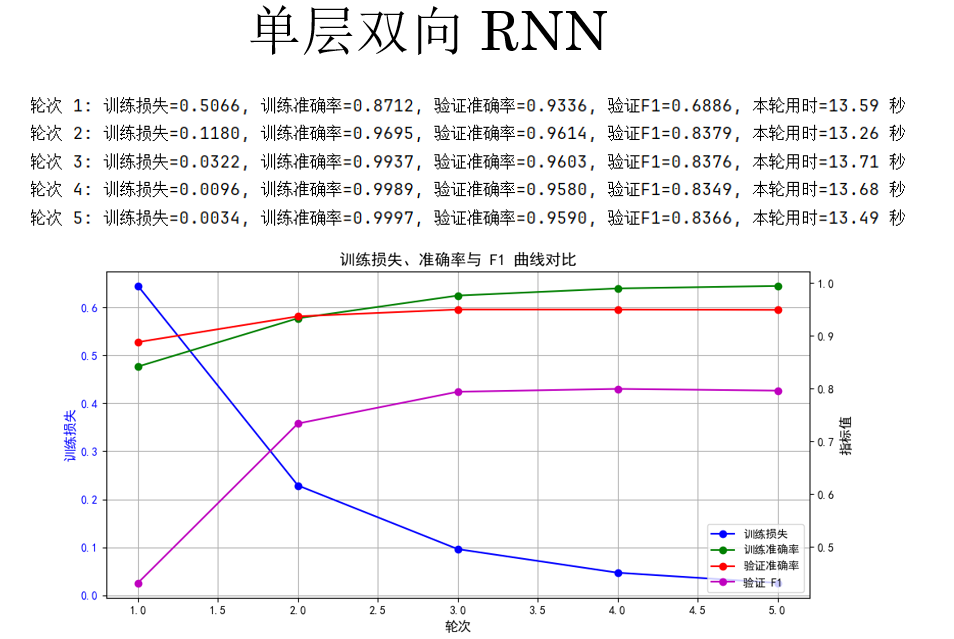
很明顯,驗證集上的 F1 分數有所提升從之前的 79% 左右到了 83% 左右,但隨着計算量的增加,訓練用時也相應的增加了約 20%。
我們繼續。
(3)單層雙向 GRU
第三個實驗對象,單層雙向 GRU,同樣修改參數如下:
cfg = {'rnn_type': 'GRU', 'bidirectional': True, 'num_layers': 1}
來看結果:
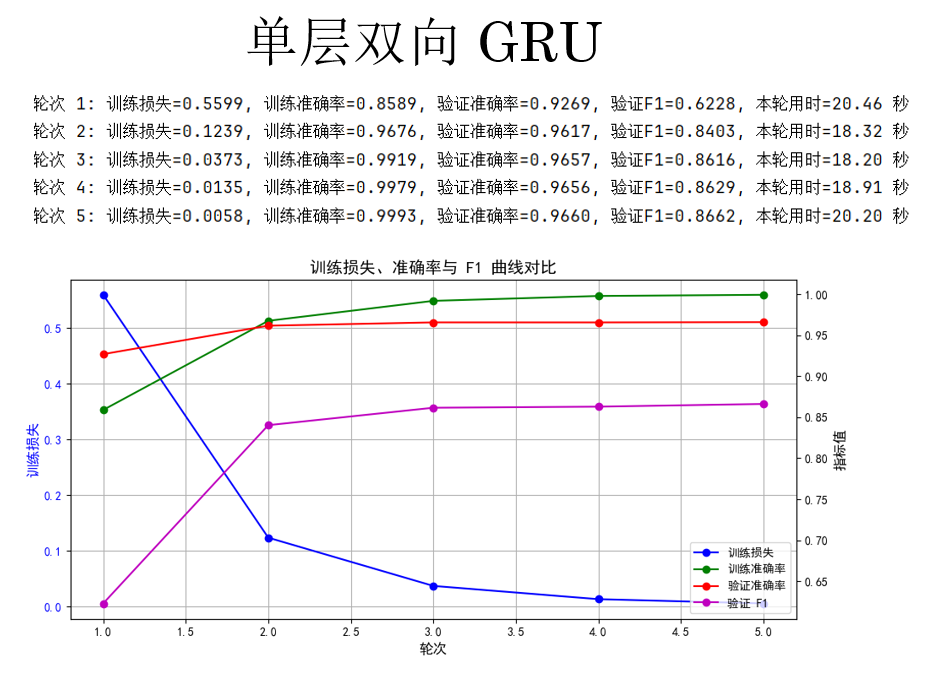
觀察結果,你會發現,GRU 再次實現了 F1 分數的提升,但同時,更加複雜的循環單元也讓其運行時間大幅提升。
(4)單層雙向 LSTM
繼續,來看看LSTM 的表現:
cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 1}
結果如下:
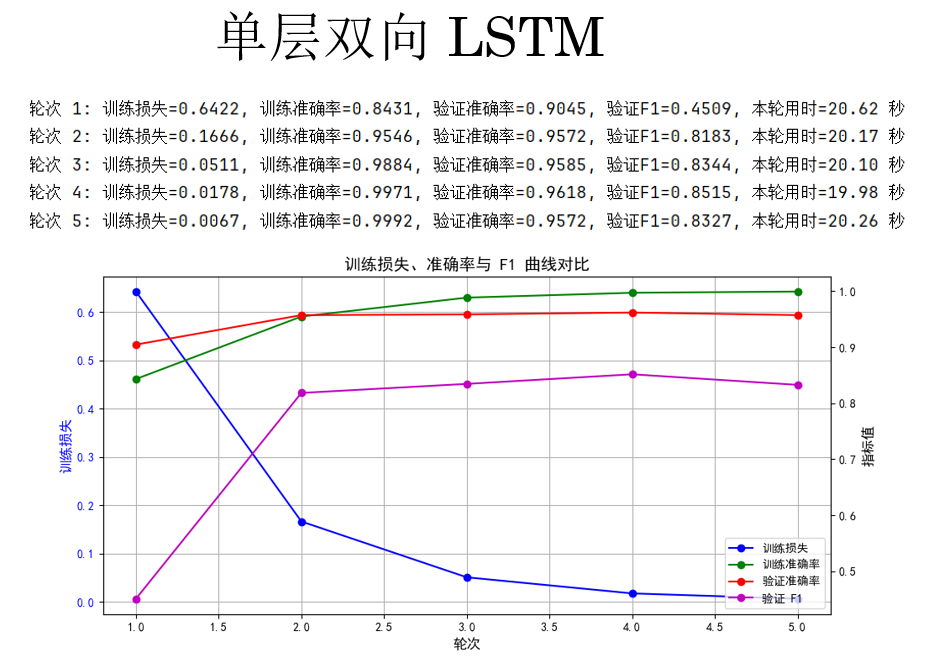
結果顯示:在當前設置下, LSTM 並不如 GRU。
其實原因也比較直觀,LSTM 並不是一定比 GRU 好,它只是“上限更高、成本也更高”,同時也更難訓練,我們繼續下一步來看看:
(5)多層雙向 LSTM
最後一次,我們選擇增加 LSTM 的深度,同時增加輪次為10。
cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 3}
結果如下:
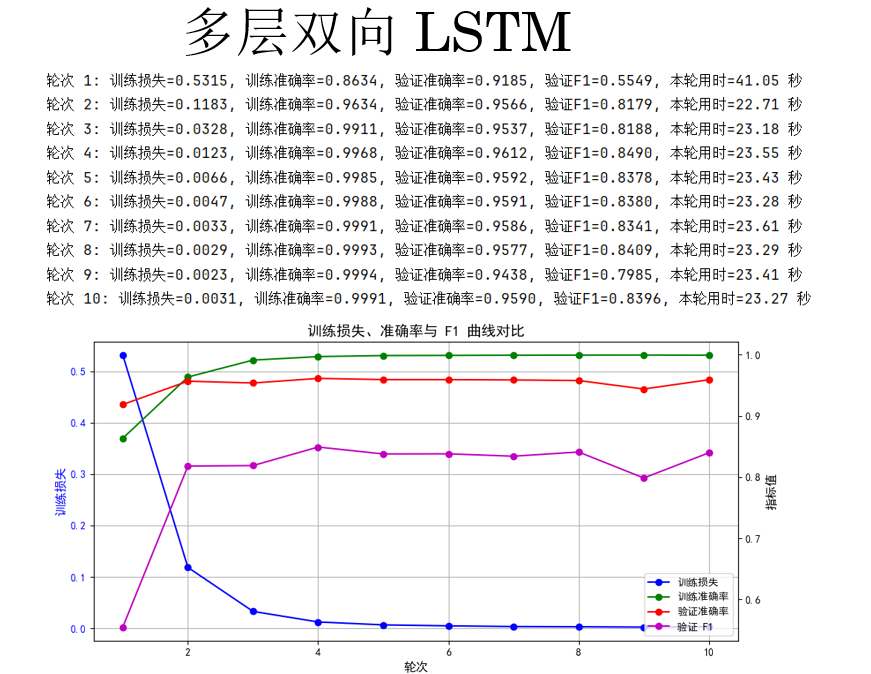
結果好像也並沒有像我們所想一樣有所提升,這也確實説明了,更復雜的模型,需要更多的訓練技巧。
我們的演示部分就到這裏。
你會發現,單層單向 RNN 訓練快、準確率高但 F1 偏低,説明對少數類識別有限。
單層雙向 RNN 利用前後文信息提升了 F1,但訓練時間也有所提升。
單層雙向 GRU 在保持訓練穩定的同時進一步提升了 F1,性價比最好。
單層雙向 LSTM 參數多、訓練難度高,在當前設置下不如 GRU,多層雙向 LSTM 即便增加輪次和深度,F1 仍未顯著提升,説明覆雜模型需要更精細的訓練策略。
總體來看,對於中等規模的序列標註任務,淺層 GRU 是最穩健的選擇。
當然,這只是針對我們現在所介紹的技術而言,下一週的內容關於詞嵌入,是相比獨熱編碼而言,更加合適的文本編碼技術,到時我們再來看看各個模型的性能如何。
3. 附錄
3.1 RNN 模型訓練代碼-PyTorch版
import time
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
from datasets import load_dataset
from collections import Counter
from torch.utils.data import DataLoader
from sklearn.metrics import f1_score
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = load_dataset("conll2003")
train_data = dataset['train']
valid_data = dataset['validation']
test_data = dataset['test']
word_counter = Counter()
tag_counter = Counter()
for item in train_data:
word_counter.update(item['tokens'])
tag_counter.update(item['ner_tags'])
# 詞表
word_vocab = {w:i+2 for i,(w,_) in enumerate(word_counter.most_common())}
word_vocab["<PAD>"] = 0
word_vocab["<UNK>"] = 1
# 標籤表
tag_vocab = {t:t for t in tag_counter.keys()}
pad_tag_id = -100
num_classes = len(tag_vocab)
vocab_size = len(word_vocab) # 用於獨熱編碼
# 編碼函數
def encode(item):
x = torch.tensor([word_vocab.get(w,1) for w in item['tokens']], dtype=torch.long)
y = torch.tensor(item['ner_tags'], dtype=torch.long)
return x, y
# DataLoader + 填充函數
def collate_fn(batch):
xs, ys = zip(*batch)
xs_pad = pad_sequence(xs, batch_first=True, padding_value=word_vocab["<PAD>"])
ys_pad = pad_sequence(ys, batch_first=True, padding_value=pad_tag_id)
return xs_pad.to(device), ys_pad.to(device)
train_dataset = [encode(item) for item in train_data]
valid_dataset = [encode(item) for item in valid_data]
test_dataset = [encode(item) for item in test_data]
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, collate_fn=collate_fn)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, collate_fn=collate_fn)
# RNN 模型
class RNNTagger(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
rnn_type='RNN', bidirectional=False, num_layers=1):
super().__init__()
self.vocab_size = vocab_size
self.bidirectional = bidirectional
self.rnn_type = rnn_type.upper()
input_size = vocab_size # 獨熱編碼輸入維度 = 詞表大小
if self.rnn_type == 'RNN':
self.rnn = nn.RNN(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
elif self.rnn_type == 'LSTM':
self.rnn = nn.LSTM(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
elif self.rnn_type == 'GRU':
self.rnn = nn.GRU(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
# x: [batch, seq_len], 轉獨熱
x_onehot = torch.nn.functional.one_hot(x, num_classes=self.vocab_size).float()
out, _ = self.rnn(x_onehot) # 過RNN
out = self.fc(out) #過輸出層
return out
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False
# 訓練 + 驗證函數
def train_validate(model, train_loader, valid_loader, epochs=5, lr=0.001):
model.to(device)
criterion = nn.CrossEntropyLoss(ignore_index=pad_tag_id)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_f1_history = []
epoch_times = []
total_start_time = time.time()
for epoch in range(epochs):
epoch_start_time = time.time()
# ========= 訓練 =========
model.train()
total_loss = 0
total_correct = 0
total_tokens = 0
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(x_batch)
outputs_reshape = outputs.view(-1, num_classes)
y_batch_reshape = y_batch.view(-1)
loss = criterion(outputs_reshape, y_batch_reshape)
loss.backward()
optimizer.step()
total_loss += loss.item()
preds = outputs.argmax(dim=-1)
for i in range(y_batch.size(0)):
mask = y_batch[i] != pad_tag_id
total_correct += (preds[i][mask] == y_batch[i][mask]).sum().item()
total_tokens += mask.sum().item()
avg_train_loss = total_loss / len(train_loader)
train_acc = total_correct / total_tokens
train_loss_history.append(avg_train_loss)
train_acc_history.append(train_acc)
# ========= 驗證 =========
model.eval()
val_total_correct = 0
val_total_tokens = 0
all_preds = []
all_labels = []
with torch.no_grad():
for x_val, y_val in valid_loader:
outputs = model(x_val)
preds = outputs.argmax(dim=-1)
for i in range(y_val.size(0)):
mask = y_val[i] != pad_tag_id
val_total_correct += (preds[i][mask] == y_val[i][mask]).sum().item()
val_total_tokens += mask.sum().item()
all_preds.extend(preds[i][mask].cpu().tolist())
all_labels.extend(y_val[i][mask].cpu().tolist())
val_acc = val_total_correct / val_total_tokens
val_f1 = f1_score(all_labels, all_preds, average='macro')
val_acc_history.append(val_acc)
val_f1_history.append(val_f1)
epoch_time = time.time() - epoch_start_time
epoch_times.append(epoch_time)
print(
f"輪次 {epoch+1}: "
f"訓練損失={avg_train_loss:.4f}, "
f"訓練準確率={train_acc:.4f}, "
f"驗證準確率={val_acc:.4f}, "
f"驗證F1={val_f1:.4f}, "
f"本輪用時={epoch_time:.2f} 秒"
)
total_time = time.time() - total_start_time
avg_epoch_time = sum(epoch_times) / len(epoch_times)
print("\n======== 訓練時間統計 ========")
print(f"總訓練時間:{total_time:.2f} 秒")
print(f"平均每輪用時:{avg_epoch_time:.2f} 秒")
history = {
'train_loss': train_loss_history,
'train_acc': train_acc_history,
'val_acc': val_acc_history,
'val_f1': val_f1_history
}
return model, history
def plot_training_curves(history):
epochs = range(1, len(history['train_loss']) + 1)
fig, ax1 = plt.subplots(figsize=(10, 5))
ax1.plot(epochs, history['train_loss'], 'b-o', label='訓練損失')
ax1.set_xlabel("輪次", fontsize=12)
ax1.set_ylabel("訓練損失", color='b', fontsize=12)
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(True)
ax2 = ax1.twinx()
ax2.plot(epochs, history['train_acc'], 'g-o', label='訓練準確率')
ax2.plot(epochs, history['val_acc'], 'r-o', label='驗證準確率')
ax2.plot(epochs, history['val_f1'], 'm-o', label='驗證 F1')
ax2.set_ylabel("指標值", fontsize=12)
ax2.tick_params(axis='y')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines1 + lines2, labels1 + labels2, loc='lower right')
plt.title("訓練損失、準確率與 F1 曲線對比", fontsize=14)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
# cfg = {'rnn_type': 'RNN', 'bidirectional': False, 'num_layers': 1}
# cfg = {'rnn_type':'RNN','bidirectional':True,'num_layers':1} # cfg = {'rnn_type': 'GRU', 'bidirectional': True, 'num_layers': 1} # cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 1} cfg = {'rnn_type': 'LSTM', 'bidirectional': True, 'num_layers': 3}
model = RNNTagger(vocab_size=len(word_vocab),
hidden_dim=128,
num_classes=num_classes,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
model, history = train_validate(model, train_loader, valid_loader, epochs=10)
plot_training_curves(history)
3.2 RNN 模型訓練代碼-TF版
import time
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Layer, SimpleRNN, GRU, LSTM, Dense, Bidirectional, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from datasets import load_dataset
from collections import Counter
from sklearn.metrics import f1_score
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False
dataset = load_dataset("conll2003")
train_data = dataset['train']
valid_data = dataset['validation']
test_data = dataset['test']
word_counter = Counter()
tag_counter = Counter()
for item in train_data:
word_counter.update(item['tokens'])
tag_counter.update(item['ner_tags'])
# 詞表
word_vocab = {w:i+2 for i,(w,_) in enumerate(word_counter.most_common())}
word_vocab["<PAD>"] = 0
word_vocab["<UNK>"] = 1
vocab_size = len(word_vocab)
# 標籤表
tag_vocab = {t:t for t in tag_counter.keys()}
num_classes = len(tag_vocab)
pad_tag_id = -100 # 訓練時忽略
# 編碼函數
def encode(item):
x = [word_vocab.get(w, 1) for w in item['tokens']]
y = item['ner_tags']
return x, y
train_dataset = [encode(item) for item in train_data]
valid_dataset = [encode(item) for item in valid_data]
test_dataset = [encode(item) for item in test_data]
# 填充函數
def pad_sequences(seqs, pad_value=0):
max_len = max(len(s) for s in seqs)
padded = [s + [pad_value]*(max_len - len(s)) for s in seqs]
return np.array(padded)
def prepare_batch(dataset):
X = pad_sequences([x for x, y in dataset], pad_value=0)
y = pad_sequences([y for x, y in dataset], pad_value=pad_tag_id)
return X, y
X_train, y_train = prepare_batch(train_dataset)
X_valid, y_valid = prepare_batch(valid_dataset)
X_test, y_test = prepare_batch(test_dataset)
class OneHotLayer(Layer):
def __init__(self, depth, **kwargs):
super().__init__(**kwargs)
self.depth = depth
def call(self, inputs):
return tf.one_hot(inputs, depth=self.depth, dtype=tf.float32)
def build_rnn_model(vocab_size, num_classes, hidden_dim=128, rnn_type='RNN', bidirectional=False, num_layers=1):
inputs = Input(shape=(None,), dtype=tf.int32)
x = OneHotLayer(depth=vocab_size)(inputs)
for i in range(num_layers):
return_seq = True
rnn_layer = None
if rnn_type.upper() == 'RNN':
rnn_layer = SimpleRNN(hidden_dim, return_sequences=return_seq)
elif rnn_type.upper() == 'GRU':
rnn_layer = GRU(hidden_dim, return_sequences=return_seq)
elif rnn_type.upper() == 'LSTM':
rnn_layer = LSTM(hidden_dim, return_sequences=return_seq)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
if bidirectional:
rnn_layer = Bidirectional(rnn_layer)
x = rnn_layer(x)
outputs = Dense(num_classes, activation='softmax')(x)
model = Model(inputs, outputs)
return model
def train_validate(model, X_train, y_train, X_valid, y_valid, batch_size=32, epochs=5, lr=0.001):
optimizer = Adam(learning_rate=lr)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(ignore_class=pad_tag_id)
train_loss_history = []
train_acc_history = []
val_acc_history = []
val_f1_history = []
train_data = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(1000).batch(batch_size)
valid_data = tf.data.Dataset.from_tensor_slices((X_valid, y_valid)).batch(batch_size)
for epoch in range(epochs):
start_time = time.time()
total_loss = 0
total_correct = 0
total_tokens = 0
# ========= 訓練 =========
for step, (x_batch, y_batch) in enumerate(train_data):
with tf.GradientTape() as tape:
logits = model(x_batch, training=True)
loss = loss_fn(y_batch, logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
total_loss += loss.numpy()
preds = tf.argmax(logits, axis=-1,output_type=tf.int32)
mask = y_batch != pad_tag_id
total_correct += tf.reduce_sum(tf.cast(preds[mask] == y_batch[mask], tf.float32)).numpy()
total_tokens += tf.reduce_sum(tf.cast(mask, tf.float32)).numpy()
train_loss_history.append(total_loss / len(train_data))
train_acc_history.append(total_correct / total_tokens)
# ========= 驗證 =========
all_preds = []
all_labels = []
total_correct_val = 0
total_tokens_val = 0
for x_batch, y_batch in valid_data:
logits = model(x_batch, training=False)
preds = tf.argmax(logits, axis=-1,output_type=tf.int32)
mask = y_batch != pad_tag_id
total_correct_val += tf.reduce_sum(tf.cast(preds[mask] == y_batch[mask], tf.float32)).numpy()
total_tokens_val += tf.reduce_sum(tf.cast(mask, tf.float32)).numpy()
all_preds.extend(preds[mask].numpy())
all_labels.extend(y_batch[mask].numpy())
val_acc = total_correct_val / total_tokens_val
val_f1 = f1_score(all_labels, all_preds, average='macro')
val_acc_history.append(val_acc)
val_f1_history.append(val_f1)
epoch_time = time.time() - start_time
print(f"輪次 {epoch+1}: 訓練損失={train_loss_history[-1]:.4f}, "
f"訓練準確率={train_acc_history[-1]:.4f}, "
f"驗證準確率={val_acc:.4f}, 驗證 F1={val_f1:.4f}, "
f"本輪用時={epoch_time:.2f} 秒")
history = {
'train_loss': train_loss_history,
'train_acc': train_acc_history,
'val_acc': val_acc_history,
'val_f1': val_f1_history
}
return history
def plot_training_curves(history):
epochs = range(1, len(history['train_loss']) + 1)
fig, ax1 = plt.subplots(figsize=(10, 5))
ax1.plot(epochs, history['train_loss'], 'b-o', label='訓練損失')
ax1.set_xlabel("輪次", fontsize=12)
ax1.set_ylabel("訓練損失", color='b', fontsize=12)
ax1.tick_params(axis='y', labelcolor='b')
ax1.grid(True)
ax2 = ax1.twinx()
ax2.plot(epochs, history['train_acc'], 'g-o', label='訓練準確率')
ax2.plot(epochs, history['val_acc'], 'r-o', label='驗證準確率')
ax2.plot(epochs, history['val_f1'], 'm-o', label='驗證 F1')
ax2.set_ylabel("指標值", fontsize=12)
ax2.tick_params(axis='y')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(lines1 + lines2, labels1 + labels2, loc='lower right')
plt.title("訓練損失、準確率與 F1 曲線對比", fontsize=14)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
cfg = {'rnn_type':'RNN','bidirectional':True,'num_layers':1}
model = build_rnn_model(vocab_size=vocab_size,
num_classes=num_classes,
hidden_dim=128,
rnn_type=cfg['rnn_type'],
bidirectional=cfg['bidirectional'],
num_layers=cfg['num_layers'])
history = train_validate(model, X_train, y_train, X_valid, y_valid, batch_size=32, epochs=10, lr=0.001)
plot_training_curves(history)